分布式MySQL架构
Posted gonghaiyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式MySQL架构相关的知识,希望对你有一定的参考价值。
分布式数据库一般是以下的这种结构,计算层获取元数据层信息进行路由。下面说下各个层级的目的:

(1)计算层就是单机时的SQL层,用来对数据访问进行权限检查、路由访问,以及对计算结果等操作。
(2)元数据层记录了分布式数据库集群下有多少个存储节点,对应IP、端口等元数据信息是多少。当分布式数据库的计算层启动时,会优先访问元数据层,获取所有集群信息,才能正确进行SQL解析和SQL执行路由。
(3)存储层用来存放数据,但存储层要和计算层在同一台服务器上,甚至不求在同一个进程中。
从可用性的角度看,如果存储层发生宕机,那么只会影响 1/N 的数据,N 取决于数据被打散到多少台服务器上。所以,分布式数据库的可用性对比单机会有很大提升,单机数据库要实现99.999% 的可用性或许很难,但是分布式数据库就容易多了。
其引入了新的分布式服务的几大问题,包括自增实现、索引设计、分布式事务、分片副本等。
在分布式mysql架构下,客户端不再是访问MySQL数据库本身,而是访问一个分布式中间件。
关于分片键的选择
选择分片的算法,比较常见的有 RANGE 和 HASH 算法。
-
RANGE算法。
缺点:该算法不能解决传输数据库的两个痛点。
(1)性能可扩展,通过增加分片节点,性能可以线性提升;
(2)存储容量可扩展,通过增加分片节点,解决单点存储容量的数据瓶颈。
优点:方便将数据在不同节点之间进行迁移。 -
Hash分区算法。对于海量并发的OLTP业务来说,建议采用这种方式。这种方式在NG上也比较常用。
分布式数据库架构设计的原则是:选择一个适合的分片键和分片算法,把数据打散,并且业务(角度)的绝大部分查询都是根据分片键进行访问。
互联网业务的分片键就是用户的ID,业务的大部分访问都是根据用户ID进行查询,比如:
- 查看某个用户下的微博/短视频;
- 查看某个用户的商品信息/购买记录。
分库分表
分库分表的目前是确定数据流。即通过以下方式可以确定。
分片 = 实例 + 库 + 表 = ip@port:db_name:table_name
很多情况下一般都采用既分库又分表的方式。有以下两个优点:
- 不同分片的数据可以在同一MySQL数据库实例上,便于做容量的规划和后期的扩展;
- 同一分片键的表都在同一个库下,方便做整体数据迁移和扩容。
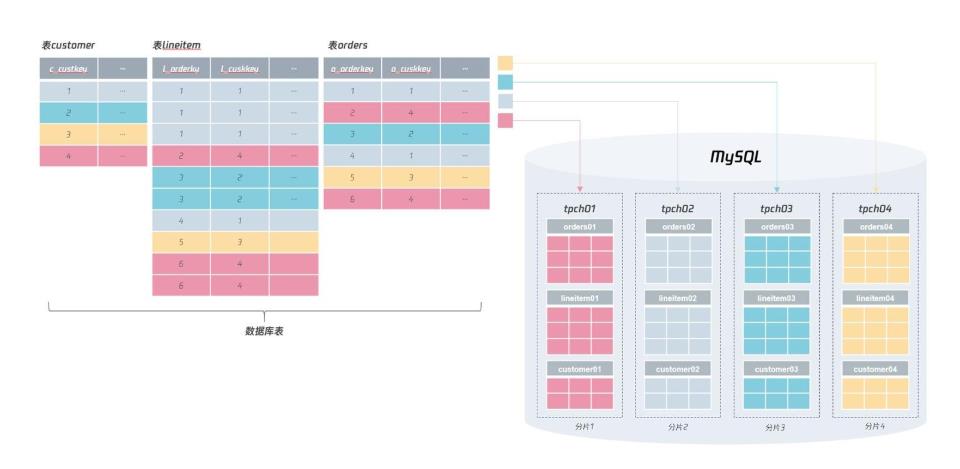
按上面这样的分布式设计,数据分片完成后,所有的库表依然是在同一个 MySQL实例上!!!
扩缩容
在 HASH 分片的例子中,我们把数据分片到了 4 个节点,然而在生产环境中,为了方便之后的扩缩容操作,推荐一开始就把分片的数量设置为不少于 1000 个。
不用担心分片数量太多,因为分片 1 个还是 1000 个,管理方式都是一样的,但是 1000 个,意味着可以扩容到 1000 个实例上,对于一般业务来说,1000 个实例足够满足业务的需求了(BTW,网传阿里某核心业务的分布式数据库分片数量为 10000个)。
一般公司建议分片数后能满足最近5年以上的业务发展,并且是2的指数倍数,便于后期的扩容或缩容。
主键选择
自增并不能在插入前就获得值,而是要通过填 NULL 值,然后再通过函数 last_insert_id()获得自增的值。所以,如果在每个分片上通过自增去实现主键,可能会出现同样的自增值存在于不同的分片上。所以,在分布式数据库架构下,尽量不要用自增作为表的主键。可以采用MySQL自带的有序UUID,或者是开源的UUID生成算法,比如雪花算法(存在时间回溯问题)。
索引设计
在分布式数据服务中,最优雅的索引设计不是创建一个索引表,而是将分片键的信息保存在想要的查询列中,这样通过查询的列就能知道所在的分片信息。比如查询的列保存为:
o_orderkey = string(o_orderkey + o_custkey)
此时的查询:SELECT * FROM Orders WHERE o_orderkey = ‘1000-1’;
对于非唯一的二级索引查询,依然需要扫描的分片才能得到最终的结果。
SELECT * FROM Orders WHERE o_orderate >= ? o_orderdate < ?
分布式数据库架构设计的要求是业务的绝大部分请求能够根据分片键定位到1个分片上。
对于唯一索引,需要采用类似UUID的机制实现全局唯一。即使是单机版的MySQL,也推荐最开始就采用全局唯一设计,因为你的业务不一定哪天就要升级为全局唯一的方式。
全局表
关于全局表的设计,有很多种方式。第一种方式是采用每个分片上都存储该全局表信息,这样就可以防止跨分片查询,第二种方式是只存到一个公共的分片上,该分片数据通过服务启动后动态加载到缓存中。每次需要时从缓存中获取。且维护成本少。
分库分表中间件
之前的京东时,采用的sharding-jdbc。目前如果继续在互联网或者金融领域使用,还是建议采用sharding-jdbc。有以下原因。
- sharding-jdbc已经成为apache的顶级项目。社区活跃度尤其是中国社区活跃度很高,并且很多互联网巨头也在使用,遇到问题容易解决。
- sharding-jdbc在使用是不需要搭建代理层,而是直接集成在应用中,中间链路少,集成方便。
- sharding-jdbc升级为代理方式时,转化更加灵活。只需要将jar引入去掉,将配置信息加入到代理中间件(如mysql-proxy:mycat)中即可。
分库分表的存储
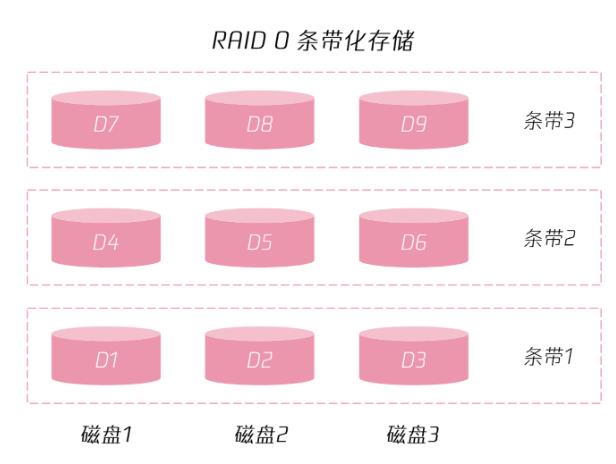
条带化
条带化是一种数据存储方案,将磁盘进行条带化后,相同的数据可以写入到不同的条带,可以提高数据的查询性能和写入性能。
如下所示的RAID 0条带化存储。
多活架构
与单活架构不同,多活架构是指不同地理位置上的系统,都能够提供业务读/写服务。这里的“活”是指实时提供读/写服务的意思,而不仅仅只是读服务。多活架构主要是为了提升系统的容灾能力,提高系统的可用性,保障业务持续可用。
在高可用架构中,需要做到跨机房部署,实现的方式是无损半同步复制,以及最新的MySQL Group Replication技术。数据库实例通过三园区进行部署。当一个机房发生宕机时,可以快速切到另外一个机房部署,当一个机房的数据存储出现问题时,可以通过另外机房的数据存储提供服务。

要实现多活架构,首先要进行分布式数据库的改造,然后是将不同数据分片的主服务器放到不同机房,最后是实现业务条带化的部署。如下面的这张图:
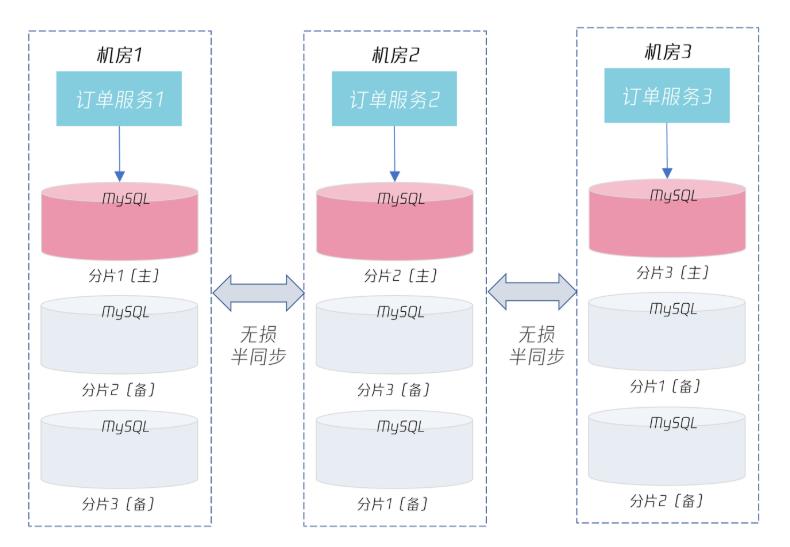
可以看到,对于上一节的订单服务和订单数据分片,通过将其部署在不同的机房,使得订单服务1 部署在机房 1,可以对分片1进行读写;订单服务 2 部署在机房 1,可以对分片 2 进行读写;订单服务 3 部署在机房 3,可以对分片 3 进行读写。
这样每个机房都可以有写入流量,每个机房都是“活”的,这就是多活架构设计。
若一个机房发生宕机,如机房 1 宕机,则切换到另一个机房,上层服务和数据库跟着一起切换,切换后上层服务和数据库依然还是在一个机房,访问不用跨机房访问,依然能提供最好的性能和可用性保障。
分布式架构下的事务处理
以上是关于分布式MySQL架构的主要内容,如果未能解决你的问题,请参考以下文章