超级简单的机器学习入门
Posted 叫我胡萝北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超级简单的机器学习入门相关的知识,希望对你有一定的参考价值。
超级简单的机器学习入门
文章目录
0.写在前面
本文大多数内容来自《神经网络与深度学习》(邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.)周志华-机器学习,也参考了很多其他笔记博客。仅作为学习记录。
1.机器学习基本概念
① 机器学习是什么?
机器学习就是让计算机从数据中进行自动学习,得到某种知识或规律。
② 样本和数据集
我们可以将一个标记好特征以及标签看作一个样本。
一组样本构成的集合称为数据集。一般将数据集分为两部分:训练集和测试集。
训练集中的样本是用来训练模型的,而测试集中的样本是用来检验模型好坏的。
③ 学习与训练
我们通常用一个𝐷 维向量
𝒙
=
[
𝑥
1
,
𝑥
2
,
⋯
,
𝑥
𝐷
]
T
𝒙 = [𝑥_1 , 𝑥_2 , ⋯ , 𝑥_𝐷] ^T
x=[x1,x2,⋯,xD]T 表示所有特征构成的向量,称为特征向量,其中每一维表示一个特征。
假设训练集 𝒟 由 𝑁 个样本组成,其中每个样本都是独立同分布的,计为: 𝒟 = ( 𝒙 ( 1 ) , 𝑦 ( 1 ) ) , ( 𝒙 ( 2 ) , 𝑦 ( 2 ) ) , ⋯ , ( 𝒙 ( 𝑁 ) , 𝑦 ( 𝑁 ) ) . 𝒟 = (𝒙^(1), 𝑦^(1)), (𝒙^(2), 𝑦^(2)), ⋯ , (𝒙^(𝑁), 𝑦^(𝑁)). D=(x(1),y(1)),(x(2),y(2)),⋯,(x(N),y(N)).
我们希望让计算机从一个函数集合
F
=
𝑓
1
(
𝒙
)
,
𝑓
2
(
𝒙
)
,
⋯
ℱ = 𝑓_1 (𝒙), 𝑓_2 (𝒙), ⋯
F=f1(x),f2(x),⋯ 中自动寻找一个“最优”的函数𝑓∗(𝒙) 来近似每个样本的特征向量 𝒙 和标签 𝑦 之间的真实映射关系,找到这个最优函数的过程就叫做学习或训练。
以下给出一个学习的基本流程:
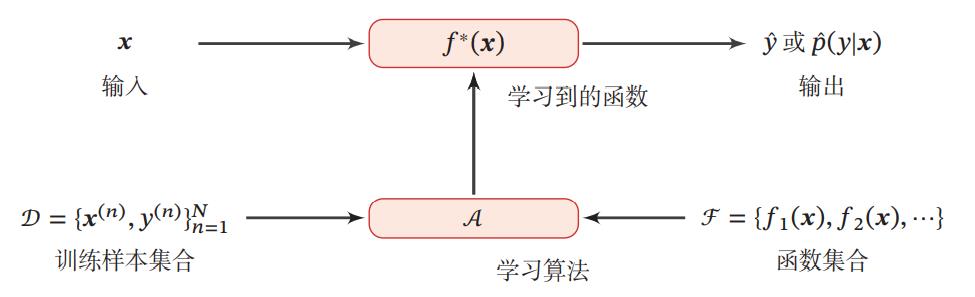
通过训练集,不断识别特征,不断建模,最后形成有效的模型,这个过程就叫“机器学习”!
2.机器学习算法的类型
2.1 监督学习
如果机器学习的目标是建模样本的特征 𝒙 和标签 𝑦 之间的关系,并且训练集中每个样本都有标签,那么这类机器学习称为监督学习。
根据标签类型的不同,监督学习又可以分为回归问题、分类问题和结构化学习问题。
(1) 回归问题中的标签 𝑦 是连续值, 𝑓(𝒙; 𝜃)的输出也是连续值。比如未来几年预测房屋价格的走势,价格是一个连续的值。最后会按照顺序把输出值串接起来,构成一个曲线。
一元线性回归
一元线性回归是最简单,最基础的一种模型,是探究两个变量之间关系的一种统计分析方法。其模型为为:
y = a x + b y=ax+b y=ax+b其中 x x x为自变量, y y y为因变量, a a a和 b b b为回归系数
求解方法为最小二乘法
a = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 n ( x i − x ˉ ) 2 b = y ˉ − a x ˉ \\left\\\\beginarrayl a=\\frac\\sum_i=1^n\\left(x_i-\\barx\\right)\\left(y_i-\\bary\\right)\\sum_i=1^n\\left(x_i-\\barx\\right)^2 \\\\ b=\\bary-a \\barx \\endarray\\right. a=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)b=yˉ−axˉ
多元线性回归
探究一个因变量和多个自变量之间关系的一种统计分析方法,其模型为:
y = a l x 1 + a 2 x 2 + … + a n x n + b y=a_l x_1+a_2 x_2+\\ldots+a_n x_n+b y=alx1+a2x2+…+anxn+b其中 y y y为因变量, x 1 , x 2 , … , x n 为自变量 x_1,x_2,…,x_n为自变量 x1,x2,…,xn为自变量, a 1 , a 2 , a 3 … , a n , b a_1,a_2,a_3…,a_n,b a1,a2,a3…,an,b 为回归系数
求解方法类似一元线性回归,使用最小二乘法
利用线性代数的形式,对多元线性回归的误差公式求导为:
∂ R ( w ) ∂ w = 1 2 ∂ ∥ y − X ⊤ w ∥ 2 ∂ w = − X ( y − X ⊤ w ) \\beginaligned \\frac\\partial \\mathcalR(\\boldsymbolw)\\partial \\boldsymbolw &=\\frac12 \\frac\\partial\\left\\|\\boldsymboly-\\boldsymbolX^\\top \\boldsymbolw\\right\\|^2\\partial \\boldsymbolw \\\\ &=-\\boldsymbolX\\left(\\boldsymboly-\\boldsymbolX^\\top \\boldsymbolw\\right) \\endaligned ∂w∂R(w)=21∂w∂∥ ∥y−X⊤w∥ ∥2=−X(y−X⊤w)令 ∂ ∂ w R ( w ) = 0 \\frac\\partial\\partial \\boldsymbolw \\mathcalR(\\boldsymbolw)=0 ∂w∂R(w)=0 , 得到最优的参数 w ∗ \\boldsymbolw^* w∗ 为: w ∗ = ( X X ⊤ ) − 1以上是关于超级简单的机器学习入门的主要内容,如果未能解决你的问题,请参考以下文章