:时间序列模型
Posted Sonhhxg_柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:时间序列模型相关的知识,希望对你有一定的参考价值。
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
有许多数据集是按时间间隔的顺序自然生成的,例如每隔几分钟到达岸边的海浪或每隔几微秒发生一次的股票市场交易。通过分析以前发生的历史,预测下一波何时会到来或下一次股票交易的价格可能是多少的模型是一种称为时间序列模型的数据科学算法。虽然传统的时间序列方法长期以来一直用于预测,但使用深度学习,我们可以使用高级方法来获得更好的结果。在本章中,我们将重点介绍如何构建常用的基于深度学习的时间序列模型,例如循环神经网络( RNN ) 和长短期记忆( LSTM ),使用 PyTorch Lightning 执行时间序列预测。
在本章中,我们将从简要介绍时间序列问题开始,然后查看 PyTorch Lightning 中的一个用例。有没有想过您手机上的天气应用程序如何向您显示第二天的温暖或寒冷?它是在使用天气数据历史的时间序列预测模型的帮助下完成的。
我们将看到时间序列预测如何帮助企业预测即将到来的交通量,他们可以使用它来估计下一小时到达目的地所需的时间或全天的变化情况。
在构建、训练、加载和预测阶段将涵盖不同的 PyTorch Lightning 方法和功能。为了您的利益,我们还将使用 PyTorch Lightning 中可用的不同功能,例如以自动方式识别学习率,以更深入地了解框架。
本章将帮助您为使用 PyTorch Lightning 的高级类型的时间序列模型做好准备,同时让您熟悉隐藏的功能和特性。
在本章中,我们将介绍以下主题:
- 时间序列简介
- 时间序列模型入门
- 使用 LSTM 时间序列模型的交通量预测
技术要求
本章的代码已经在 macOS 上使用 Anaconda 或在 Google Colab 中使用 Python 3.6 开发和测试。如果您使用的是其他环境,请对您的环境变量进行适当的更改。
在本章中,我们将主要使用以下 Python 模块,并在其版本中提及:
- PyTorch Lightning (version 1.5.2)
- Seaborn (version 0.11.2)
- NumPy (version 1.21.5)
- Torch (version 1.10.0)
- pandas (version 1.3.5)
为了确保这些模块一起工作并且不会不同步,我们使用了特定版本的torch、torchvision、torchtext、torchaudio 和PyTorch Lightning 1.5.2。您还可以使用相互兼容的最新版 PyTorch Lightning 和torch compatible。
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet
!pip install pytorch-lightning==1.5.2 --quiet源数据集可在 Metro Interstate Traffic Volume 数据集中找到:https ://archive.ics.uci.edu/ml/datasets/Metro+Interstate+Traffic+Volume 。
这是从 UCI 机器学习存储库获得的捐赠数据集。该数据集由 Dua, D. 和 Graff, C. (2019), UCI Machine Learning Repository ( http://archive.ics.uci.edu/ml ), Irvine, CA: University of California, School of Information 提供和计算机科学。
时间序列简介
在典型的机器学习用例中,数据集是特征 ( x ) 和目标变量 ( y ) 的集合。这模型使用特征来学习和预测目标变量。
举个例子。为了预测房价,特征可以是卧室数量、浴室数量和平方英尺,目标变量是房价。在这里,目标可以是使用所有特征 ( x ) 来训练模型并预测房子的价格 ( y )。我们在这样的用例中观察到的一件事是,在预测目标变量时,数据集中的所有记录都被平等对待,在我们的例子中是房子的价格,数据的顺序并不重要。结果 ( y ) 仅取决于x的值。
另一方面,在时间序列预测中,数据的顺序在捕捉一些特征方面起着重要作用,例如趋势和季节。时间序列数据集是通常是涉及时间测量的数据集——例如,每小时记录温度的气候数据集。时间序列中的预测并不总是在特征 ( x ) 和变量 ( y ) 之间很好地划分,但我们根据 x 的先前值预测 x 的下一个值(例如根据今天的温度预测明天的温度)。
时间序列数据集可以具有一个或多个特征。如果只有一个特征,那就是称为单变量时间序列,如果有多个特征,则称为多变量时间序列。这个可以是任何量子的时间,无论是微秒、小时、天,甚至是年。
虽然使用传统机器学习方法(如 ARIMA)解决时间序列问题有多种方法,但深度学习方法提供了更简单、更好的方法。我们将了解如何使用深度学习方法处理时间序列问题,以及 PyTorch Lightning 如何借助示例帮助其实现。
使用深度学习进行时间序列预测
技术上时间序列预测是一种利用历史时间序列数据构建回归模型来预测预期结果的形式。简单来说,时间序列预测使用历史数据来训练模型并预测未来值。
虽然时间序列的传统方法很有用,但深度学习在时间序列预测克服了传统机器学习的缺点,例如:
- 识别复杂的模式、趋势和季节
- 长期预测
- 处理缺失值
- 循环神经网络
- 长短期记忆体
- 门控循环单元
- 编码器-解码器模型
在下一节中,我们将看到 LSTM 使用用例的实际应用。
时间序列模型入门
在本章的下一部分中,我们将通过时间序列预测的真实示例进行详细解释。每个时间序列模型通常遵循以下结构体:
让我们从下一节开始。
使用 LSTM 时间序列模型的交通量预测
时间序列模型还有其他各种业务应用,例如例如预测股票价格、预测产品需求或预测机场每小时的乘客数量。
这种模型最常用的应用之一(您必须在驾驶时不知不觉地使用它)是交通预测。在本节中,我们将尝试预测 94 号州际公路的交通量,Uber、Lyft 和/或谷歌地图等拼车公司可以使用它来预测两个司机的交通量和到达目的地所需的时间和拼车客户。交通量因小时而异(取决于一天中的时间、办公时间、通勤时间等),时间序列模型有助于进行此类预测。
在这个用例中,我们将使用 Metro Interstate Traffic Volume 数据集来构建多层堆叠 LSTM 模型并预测交通量。我们还将关注一些用于处理模型内部验证数据集的 PyTorch Lightning 技术,以及使用 PyTorch Lightning 自动化技术之一来识别模型学习率值。
在本节中,我们将介绍以下主要主题:
- 数据集分析
- 特征工程
- 创建自定义数据集
- 使用 PyTorch Lightning 配置 LSTM 模型
- 训练模型
- 测量训练损失
- 加载模型
- 对测试数据集的预测
数据集分析
我们将在本章中使用的数据集称为Metro Interstate Traffic Volume数据集,其中包含交通量的历史数据在 UCI 机器学习存储库上提供。从 2012 年 10 月 2 日到 2018 年 9 月 30 日,它每小时记录明尼阿波利斯和明尼苏达州圣保罗之间的 I-94 西行的交通量。该数据集可在 UCI 机器学习存储库中获得,并可从以下 URL 下载:Index of /ml/machine-learning-databases/00492。
ZIP 文件夹包含一个 CSV 文件,其中包含 2012 年 10 月 2 日至 2018 年 9 月 30 日的 8 列和 48,204 行数据。
这是我们训练数据集前五行的屏幕截图:
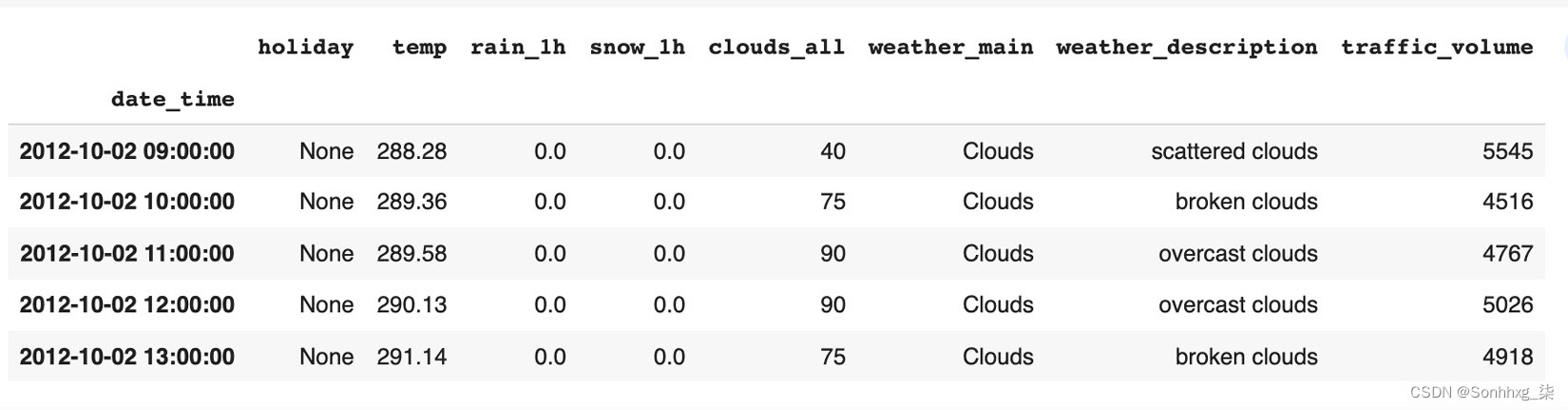
图 5.1 – 显示前五行数据
列如下:
- holiday:美国国定假日,加上地区性假期和明尼苏达州博览会
- temp:数字开尔文的平均温度
- rain_1h:一小时内发生的降雨量,以毫米为单位
- snow_1h:一小时内发生的以毫米为单位的积雪量
- cloud_all : 云量百分比
- weather_main:当前天气的分类简短文本描述
- weather_description:当前天气的分类较长文本描述
- date_time:在本地 CST 时间收集的数据的DateTime小时
- traffic_volume:数字每小时 I-94 ATR 301 报告的西行交通量
我们将首先将 CSV 文件加载到 pandas DataFrame 中,以便在将其输入到我们的自定义数据模块之前执行探索性数据分析( EDA ) 和数据处理。
加载数据集
安装后并导入所需的库,第一步是在 Google Colab 工作区中加载数据集。首先,我们将使用以下 URL 从 UCI 机器学习存储库下载数据集:https ://archive.ics.uci.edu/ml/machine-learning-databases/00492/ 。
然后,我们将提取压缩文件以在提取的文件夹中找到Metro_Interstate_Traffic_Volume.csv文件。我们已经看到了几种将数据集从 Kaggle、Google Drive 等直接下载到 Colab notebook 中的方法。在本节中,我们将使用手动方法将数据直接上传到 Colab 会话存储中。单击左侧的文件图标,如下所示:
图 5.2 – 在 Google Colab 上打开文件菜单
后打开“文件”菜单,通过单击图标选择“上传到会话存储”选项,如下所示:
图 5.3 – 将本地数据上传到 Google Colab 环境
作为如前所示,最后选择您之前从 UCI 机器学习存储库下载的Metro_Interstate_Traffic_Volume.csv文件。
现在,是时候将我们的数据集加载到 pandas DataFrame 中了。由于我们知道我们的数据集有一个名为date_time的列,我们将使用该列来解析日期并将其设置为索引列,如下面的代码片段所示:
df_traffic = pd.read_csv('Metro_Interstate_Traffic_Volume.csv', parse_dates=['date_time'], index_col="date_time")将 CSV 文件加载到 pandas DataFrame 后,如前所示,我们可以使用 DataFrame 上的head方法显示前五行,如下所示:
df_traffic.head()显示以下输出:
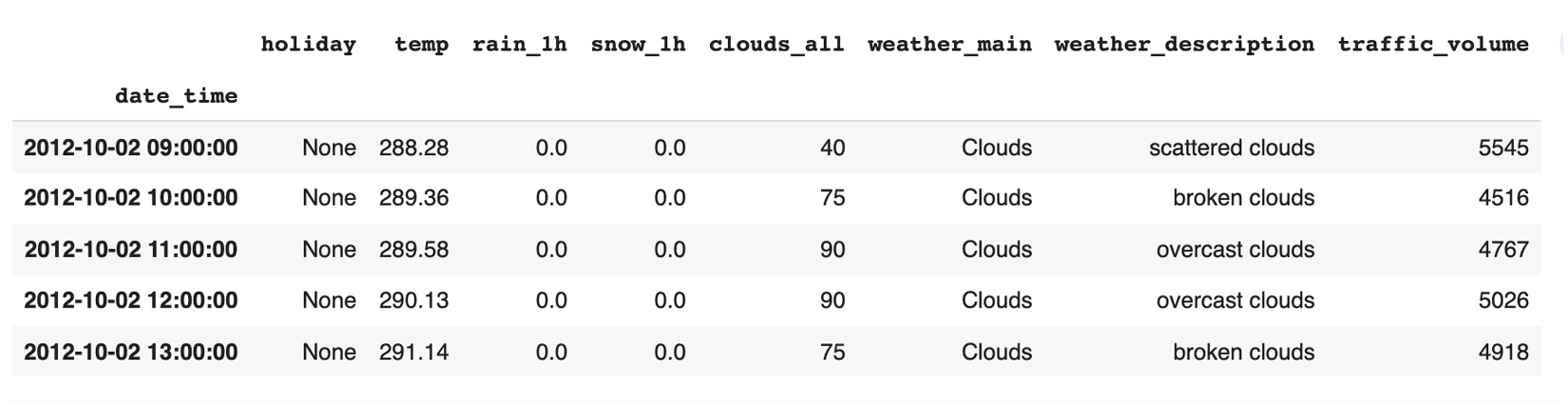
图 5.4 – 索引时间戳
我们现在将使用df_traffic DataFrame 上的shape方法检查数据集中的总行数和列数,如下所示:
print("Total number of row in dataset:", df_traffic.shape[0])
print("Total number of columns in dataset:", df_traffic.shape[1])显示以下输出:

图 5.5 – 数据集大小
探索性数据分析
现在,是时候执行探索性数据分析,以更好地了解数据并检查数据质量问题。我们将首先分析分类列。让我们从weather_main列的频率分布开始,如下所示:
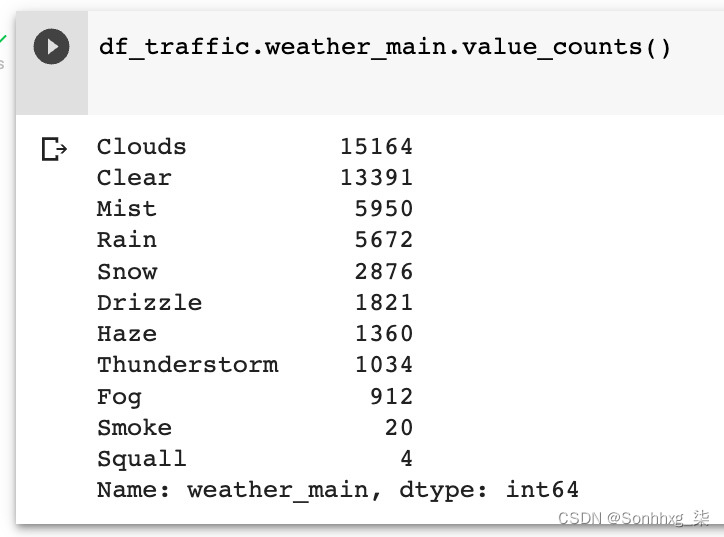
图 5.6 – 天气数据文件的行数
在里面上图中,我们在df_traffic DataFrame 的weather_main列上使用value_counts方法来获取唯一值的计数。可以看出有 11 种不同类型的天气,其中云是最常见的一种。
我们现在将得到假期列的频率分布,如下所示:

图 5.7 – 假期文件的基本数据
有数据集中记录了 12 种不同类型的假期以及 None 值,这意味着只有 11 个假期,并且大多数假期的频率非常小。
检查时间序列中的重复时间戳总是很重要的;我们将使用 pandas 的duplicated()方法来识别重复的时间戳,如下所示:
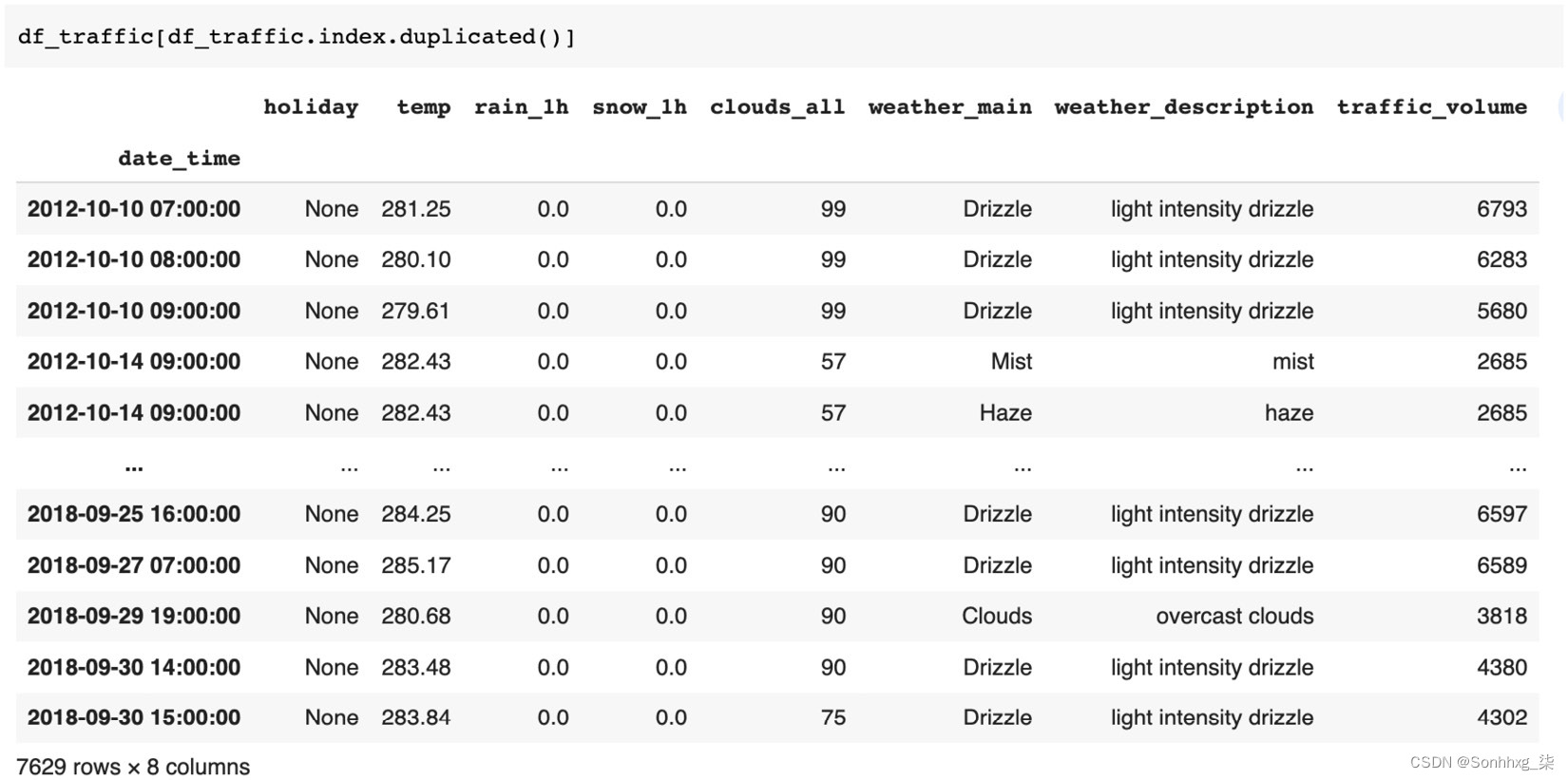
图 5.8 – 检查数据集的重复项
我们可以从上一个屏幕截图中可以看出,有 7,629 行具有重复的时间戳。我们需要删除所有重复的时间戳,这可以使用重复的方法结合 pandas 切片轻松完成,如下所示:
df_traffic = df_traffic[~df_traffic.index.duplicated(keep='last')]在前面的代码中,我们使用 duplicated 方法来保留最后一条记录,并从df_traffic DataFrame 中删除所有其他重复记录。去重后,我们可以使用shape方法检查 DataFrame 中剩余的行数:

图 5.9 – 行数的输出
我们可以看到,删除重复的时间戳后,DataFrame 现在包含 40,575 行,而不是 48,204 行。
现在,让我们使用 Matplotlib 和 Seaborn 库绘制流量的时间序列,如下所示:
plt.xticks(
rotation=90,
horizontalalignment='right',
fontweight='light',
fontsize='x-small'
)
sns.lineplot(df_traffic.index, df_traffic["traffic_volume"]).set_title('Traffic volume time series')在里面在前面的代码中,我们使用时间戳(已经转换为df_traffic DataFrame 的索引)作为x轴,并在y轴上绘制traffic_volume的值,得到如下图:
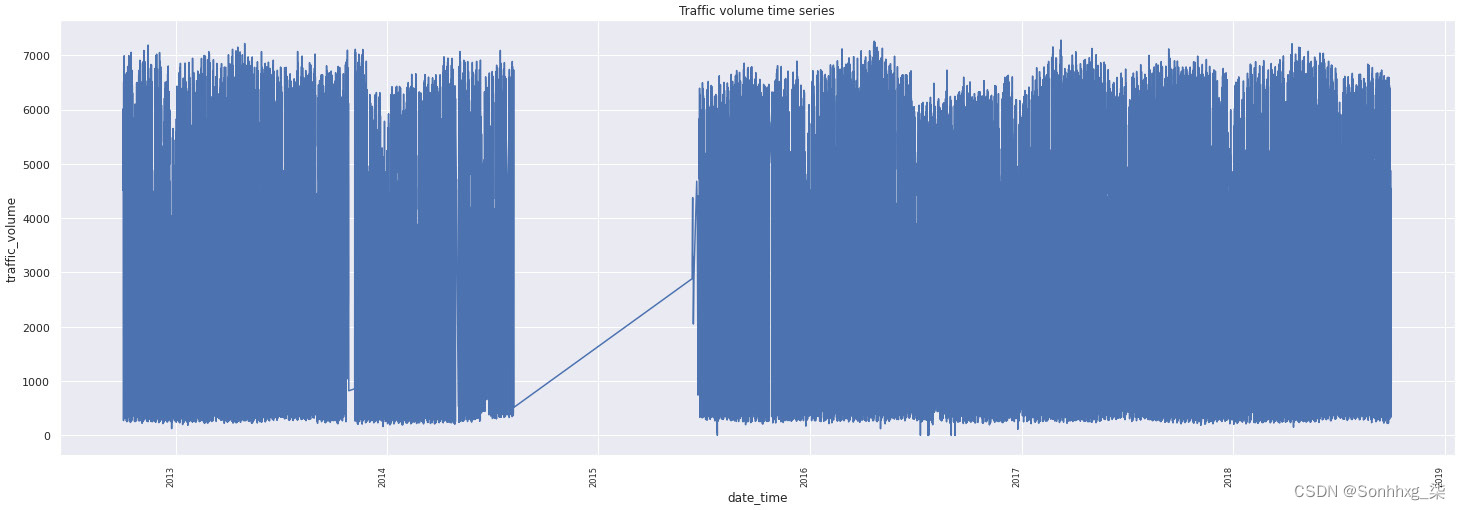
图 5.10 – 交通量时间序列图
从前面的时间序列可以看出,整个数据集中都存在缺失值,但是从 2014 年底到 2015 年底几乎所有的值都缺失了。如果缺失值是间歇性的,则大多数数据插补技术都有效,例如 2013 年至 2014 年或 2016 年至 2018 年的情况,但对于 2014 年至 2015 年的流量,它们将失败。因此,我们将仅考虑最近 3 年数据,因为它似乎足够一致,因为很少存在缺失值,可以使用简单的插值进行估算。
将时间序列可视化以获取缺失值的概览总是一个好主意,但为了获得缺失值的确切数量,我们将创建虚拟数据并将数据集中的时间戳与其进行比较,如此处所示:
date_range = pd.date_range('2012-10-02 09:00:00', '2018-09-30 23:00:00', freq='1H')
df_dummy = pd.DataFrame(np.random.randint(1, 20, (date_range.shape[0], 1)))
df_dummy.index = date_range # 设置索引
df_missing = df_traffic
# 根据参考索引检查缺少的日期时间索引值(所有值)
missing_hours = df_dummy.index[~df_dummy.index.isin(df_missing.index)]
print(missing_hours)在里面在前面的代码中,我们正在创建一个名为date_range的日期范围变量,其开始时间和结束时间等于数据集中记录的开始时间和结束时间。我们将名为df_dummy的虚拟数据的索引设置为date_range,其频率为 1 小时。然后,我们比较这两个索引以找出所有时间戳,这些时间戳本应存在于我们的数据集中但丢失了。前面代码片段的输出如下所示:
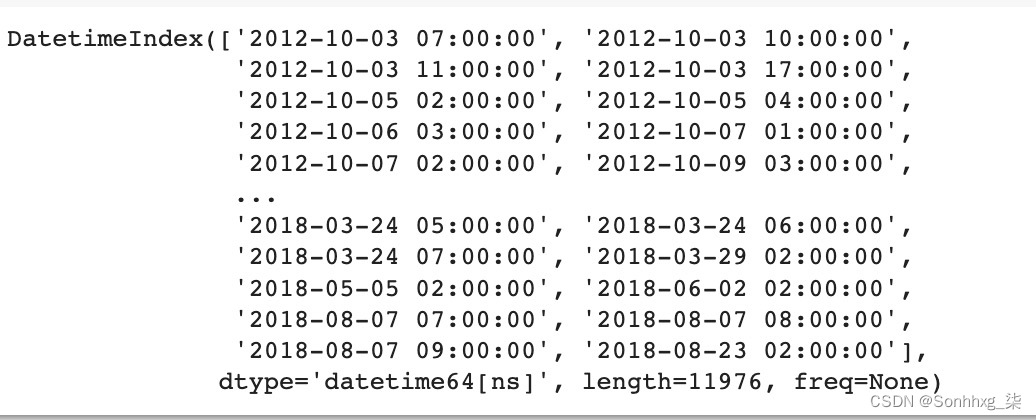
图 5.11 – 缺失数据分析的输出
从前面的输出可以看出,我们的数据集中有 11,976 个缺失的时间戳。
现在,我们将使用 pandas 的describe方法探索区间变量温度,如下所示:
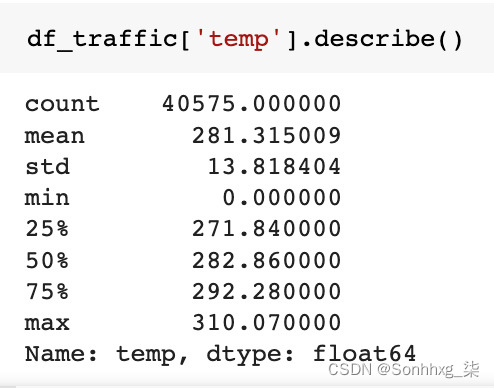
图 5.12 – 探索温度变量
我们可以在温度统计中观察到,我们数据集中的最低温度为 0 开尔文,这是不可能的,因此我们需要处理这些异常值。由于这是时间序列数据,因此我们需要替换它们以保持连续性,而不是删除异常值,如下所示:
df_traffic['temp']=df_traffic['temp'].replace(0,df_traffic['temp'].median())在里面在前面的代码片段中,我们将 0 开尔文温度值替换为数据集中记录的温度中值。(或者,您也可以使用均值进行替换。)
在下一步中,我们将选择最近 3 年的数据,如前所述,因为这与一些间歇性缺失值更一致:
df_traffic = df_traffic[df_traffic.index.year.isin([2016,2017,2018])].copy()
# 使用回填和插值方法填充缺失值
df_traffic = pd.concat([df_traffic.select_dtypes(include=['object']).fillna(method='backfill'),
df_traffic.select_dtypes(include=['float']).interpolate()],axis=1)
df_traffic.shape在前面的代码中,我们首先选择 2016 年、2017 年和 2018 年的数据。然后,我们使用回填和插值方法填充缺失值。最后,我们有一个数据集,其中包含过去 3 年的 24,096 行,没有缺失值,可以检查,如下所示:
图 5.13 – 再次检查数据集的缺失值
现在,是时候将我们的分类变量转换为虚拟/指标变量了。为此,我们将使用 pandas 的get_dummies()方法,如下所示:
df_traffic = pd.get_dummies(df_traffic, columns = ['holiday', 'weather_main'], drop_first=True)
df_traffic.drop('weather_description', axis=1, inplace=True)在前面的代码中,我们首先为holiday和weather_main分类变量创建虚拟变量,然后从数据集中删除原始分类变量。我们还删除了weather_description列,它是 weather_main 列的扩展,它不包含任何对我们的预测模型有用的额外信息:
图 5.14 – 数据集的示例视图
将数据集拆分为训练、测试和验证集
数据集将是分为训练、测试和验证,用于训练模型、评估模型和估计训练阶段的模型性能。
由于这是一个时间序列数据集,我们不会使用标准的 70–30/80–20 拆分;相反,我们将根据时间段拆分数据集。为此,我们需要检查下采样数据的开始和结束时间,这可以使用以下代码片段来实现:

图 5.15 – 下采样数据的结果
训练数据集
我们将考虑 2 年的数据,从 2016 年 1 月 1 日到 2017 年 12 月 31 日,作为训练数据集。以下代码片段在我们要求的日期范围内划分数据集。该训练数据集将用于训练我们的模型:
df_traffic_train = df_traffic.loc[:datetime.datetime(year=2017,month=12,day=31,hour=23)]
print("Total number of row in train dataset:", df_traffic_train.shape[0])
print("Train dataset start date :",df_traffic_train.index.min())
print("Train dataset end date:",df_traffic_train.index.max())显示以下输出:
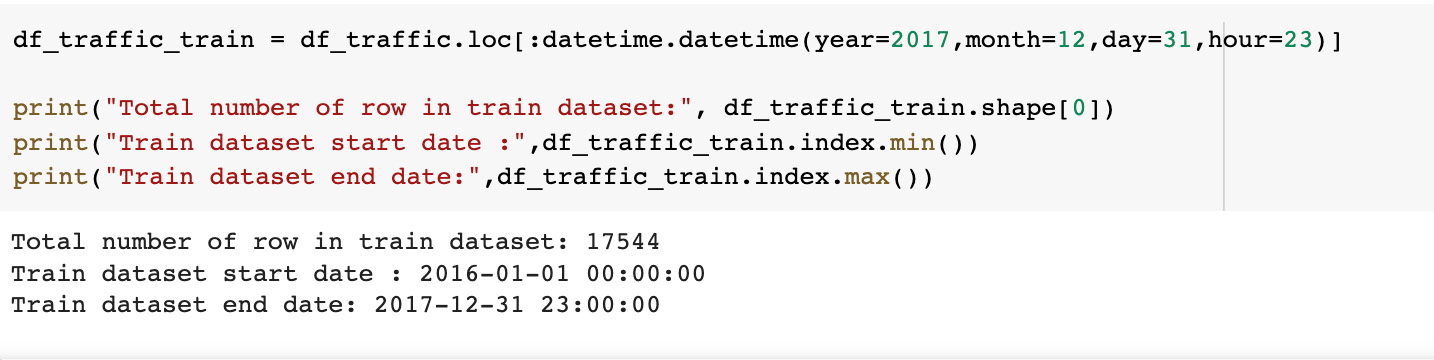
图 5.16 – 训练数据集
显示训练数据集的大小及其开始和结束日期。
验证数据集
现在我们将考虑未来 6 个月的数据以进行验证。以下代码片段在我们要求的日期范围内划分数据集:
df_traffic_val = df_traffic.loc[datetime.datetime(year=2018,month=1,day=1,hour=0):datetime.datetime(year=2018,month=6,day=30,hour=23)]
print("Total number of row in validate dataset:", df_traffic_val.shape[0])
print("Validate dataset start date :",df_traffic_val.index.min())
print("Validate dataset end date:",df_traffic_val.index.max())
图 5.17 – 验证数据集
验证数据集现已准备就绪。
测试数据集
最后,对于测试数据集,我们将考虑从 2018 年 7 月到 2018 年 9 月的剩余时间段,也就是数据集中的结束时间段。以下代码片段在我们要求的日期范围内划分数据集。该测试数据集用于在模型训练后预测我们的结果:
df_traffic_test = df_traffic.loc[datetime.datetime(year=2018,month=7,day=1,hour=0):]
print("Total number of row in test dataset:", df_traffic_test.shape[0])
print("Validate dataset start date :",df_traffic_test.index.min())
print("Validate dataset end date:",df_traffic_test.index.max())到目前为止,我们已经读取了数据,进行了 EDA 和数据预处理,并将其拆分为三个不同的 pandas DataFrames 用于训练、测试和验证:
- df_traffic_train:这是训练数据集,用于训练我们的模型。
- df_traffic_val:这是验证数据集,用于在每个 epoch 之后验证我们的模型。
- df_traffic_test:这是测试当我们的模型被训练并准备好时的数据集。我们将使用这些数据进行预测和比较结果。
特征工程
中的一个关键的特征工程步骤是将分类变量转换为虚拟/指示变量,这是在将数据拆分为训练、测试和验证之前完成的。
下一个也是最重要的特征工程步骤是对区间变量进行归一化的过程。始终建议执行归一化以获得更好的结果并更快地训练模型。有许多可用的标准化技术,我们将使用sklearn 预处理模块中的 min-max 缩放器。我们将缩放器应用于训练、验证和测试数据集中的所有区间变量 - temp、rain_1h、snow_1h、clouds_all和traffic_volume:
#创建缩放器
temp_scaler = MinMaxScaler()
rain_scaler = MinMaxScaler()
snow_scaler = MinMaxScaler(
cloud_scaler = MinMaxScaler()
volume_scaler = MinMaxScaler()
#创建转换器
temp_scaler_transformer = temp_scaler.fit(df_traffic_train[['temp']])
rain_scaler_transformer = rain_scaler.fit(df_traffic_train[['rain_1h']])
snow_scaler_transformer = snow_scaler.fit(df_traffic_train[['snow_1h']])
cloud_scaler_transformer = cloud_scaler.fit(df_traffic_train[['clouds_all']])
volume_scaler_transformer = volume_scaler.fit(df_traffic_train[['traffic_volume']])在前面的代码块中,我们主要执行以下步骤:
- 创建缩放器:我们为每个间隔列创建五个不同的最小-最大缩放器,因为我们有五个间隔列(temp、rain_1h、snow_1h、clouds_all和traffic_volume)。
- 创建转换器:下一步是使用前面步骤中定义的缩放器创建转换器。这可以通过在训练数据集上为五个单独的缩放器调用fit方法来完成。在这里,我们为 Metro Interstate Traffic Volume 数据集的每个间隔列(temp、rain_1h、snow_1h、clouds_all和traffic_volume )创建了五个不同的转换器。
- 现在,我们将将先前定义和拟合的缩放应用于训练数据集,如下所示:
df_traffic_train["temp"] = temp_scaler_transformer.transform(df_traffic_train[['temp']]) df_traffic_train["rain_1h"] = rain_scaler_transformer.transform(df_traffic_train[['rain_1h']]) df_traffic_train["snow_1h"] = snow_scaler_transformer.transform(df_traffic_train[['snow_1h']]) df_traffic_train["clouds_all"] = cloud_scaler_transformer.transform(df_traffic_train[['clouds_all']]) df_traffic_train["traffic_volume"] = volume_scaler_transformer.transform(df_traffic_train[['traffic_volume']])如前面的代码所示,使用定义的缩放器上的变换方法将缩放器应用于训练数据集。
- 我们将使用与训练数据集相同的缩放器来对测试和验证数据集应用缩放,如下所示:
df_traffic_val["temp"] = temp_scaler_transformer.transform(df_traffic_val[['temp']]) df_traffic_val["rain_1h"] = rain_scaler_transformer.transform(df_traffic_val[['rain_1h']]) df_traffic_val["snow_1h"] = snow_scaler_transformer.transform(df_traffic_val[['snow_1h']]) df_traffic_val["clouds_all"] = cloud_scaler_transformer.transform(df_traffic_val[['clouds_all']]) df_traffic_val["traffic_volume"] = volume_scaler_transformer.transform(df_traffic_val[['traffic_volume']]) df_traffic_test["temp"] = temp_scaler_transformer.transform(df_traffic_test[['temp']]) df_traffic_test["rain_1h"] = rain_scaler_transformer.transform(df_traffic_test[['rain_1h']]) df_traffic_test["snow_1h"] = snow_scaler_transformer.transform(df_traffic_test[['snow_1h']]) df_traffic_test["clouds_all"] = cloud_scaler_transformer.transform(df_traffic_test[['clouds_all']]) df_traffic_test["traffic_volume"] = volume_scaler_transformer.transform(df_traffic_test[['traffic_volume']])
在前面代码中,我们再次在训练数据集上安装的缩放器上使用变换方法来缩放测试和验证数据集中的间隔列。
创建自定义数据集
在本节中,我们将创建一个实用程序类从数据集中提取特征和目标。因此,我们将加载我们之前拆分的训练、验证和测试 DataFrame,并从这些 DataFrame 创建要在模型中使用的特征。此自定义数据集类的输出将用于在本节的后面部分创建数据加载器。
加载数据中
让我们从加载数据帧。在特征工程部分的最后,我们准备好了三个不同的 pandas DataFrames 用于训练、验证和测试:
#STEP1:加载数据
self.df_traffic_train = df_traffic_train
self.df_traffic_val = df_traffic_val
self.df_traffic_test = df_traffic_test在前面的代码中,我们复制了三个训练、验证和测试 DataFrame。
创建特征
#STEP2: 创建功能
if train: #process train dataset
features = self.df_traffic_train
target = self.df_traffic_train.traffic_volume
elif validate: #process 验证数据集
features = self.df_traffic_val
target = self.df_traffic_val.traffic_volume
else: #process 测试数据集
features = self.df_traffic_test
target = self.df_traffic_test.traffic_volume在这个代码块中,我们创建了两个变量——一个是由DataFrame和我们的features列组成的特征,它是包含temp、rain_1h、snow_1h、clouds_all、traffic_volume以及从分类变量创建的所有列的 DataFrame。第二个变量是目标,它是一个 pandas 系列的traffic_volume。
这一步也定义了选择DataFrame的条件。如果训练参数为True,则为我们的训练数据集设置特征和目标变量——即使用df_traffic_train数据集;如果验证参数为True,则为验证数据集设置特征和目标变量——即使用df_traffic_val数据帧;同样,如果测试参数为True,则为我们的测试数据集设置特征和目标变量——即使用df_traffic_test DataFrame。
创建窗口/排序
在我们执行窗口化步骤之前,让我们简要讨论一下它是什么以及我们为什么需要这样做。
在时间序列预测中,重要的是给出建模在给定时间可能最完整的信息,时间序列中的历史数据在做出未来预测中起着重要作用。
因此,它期望在具有滚动输出的周期的特定间隔内生成的数据。如果数据集不是这种格式,我们需要先重塑数据集,然后才能将其传递给时间序列模型算法。这样做最常用的过程称为“加窗”或“排序”。固定窗口为模型提供了使用滚动目标的跨度(如上一节所述)。
让我们考虑一个有九行的单变量时间序列数据集:
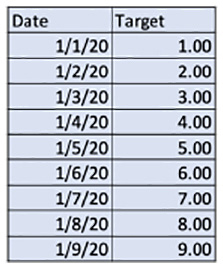
图 5.18 – 包含 Date 和 Target 列的数据集
上表具有以<mm/dd/YY>格式表示的Date列和名为Target的列。让我们对前面的数据集应用窗口,窗口大小为3。下图显示了窗口大小为3的窗口化结果:
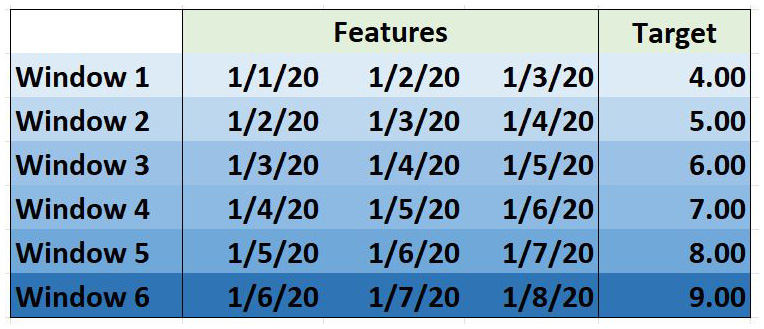
图 5.19 – 窗口大小为 3 的窗口
应用窗口后窗口大小为3,我们可以看到生成了六行数据;Window 1的特征将是1/1/20、1/2/20和1/3/20的所有特征的集合,目标变量将是1/4/20的目标值。
例如,如果我们使用记录的湿度来预测一天的温度,那么对于Window 1,特征将是记录1/1/20、1/2/20和1天的湿度的集合/3/20,目标变量将是1/4/20的温度值。
加窗/排序是其中之一时间序列预测中最常用的技术,它帮助我们提供为我们的模型提供完整的信息,以便更好地进行预测。
现在,到目前为止,我们已经学会了如何为时间序列预测工作准备数据。在下一节中,我们将使用 LSTM 模型使用 PyTorch Lightning 执行预测。
现在,我们将执行窗口化的数据准备步骤:
#STEP3: Create windows/sequencing
self.x, self.y = [], []
for i in range(len(features) - window_size):
v = features.iloc[i:(i + window_size)].values
self.x.append(v)
self.y.append(target.iloc[i + window_size])在这一步中,我们将数据集转换为默认大小为480的窗口,即 20 天的数据。我们将使用 20 天的历史数据来训练我们的 LSTM 模型,以预测第二天的情况。
在前面的代码中,我们有两个 Python 类变量;x将具有过去 20 天的特征序列(temp、rain_1h、snow_1h、clouds_all、traffic_volume以及从分类变量创建的所有列),y类变量将具有下一个目标变量(traffic_volume)连续一天。
计算数据集的长度
在这个自定义数据类中,我们也在计算我们的数据在执行窗口化后的总记录数,稍后将用于 __len__(self) 方法:
#STEP4:计算数据集的长度
self.num_sample = len(self.x)总结一下我们的__init__()方法,它需要三个布尔参数作为输入,根据设置的标志,它选择训练、验证或测试数据集。然后,从数据集中提取特征和目标,并对特征和目标数据执行窗口化,默认窗口大小为480。开窗后,此序列数据存储在名为x和y的类变量中,它们表示特征和目标变量。
返回行数
我们还将定义一个效用函数返回数据集中的行数,该行数存储为num_sample类变量。这是在__init__()中计算和初始化的:
def __len__(self):
#返回数据集的总记录数
return self.num_sample最后,我们定义__getitem__方法来获取索引处的x和y的值,如下所示:
def __getitem__(self, index):
x = self.x[index].astype(np.float32)
y = self.y[index].astype(np.float32)
return x, y在前面的代码中,__getitem__方法将index作为参数,并返回我们的特征和目标变量的记录——也就是说,它从两个类变量x和y中返回index处的值。这是在__init__方法中对我们的数据集执行窗口后完成的。
现在,我们已准备好测试TrafficVolumeDataset,然后继续构建 LSTM 模型的下一部分。测试它的一种快速方法是使用for循环,并在单次迭代后通过调用break语句停止循环:
traffic_volume = TrafficVolumeDataset(test=True)
#let's loop it over single iteration and print the shape and also data
for i, (features,targets) in enumerate(traffic_volume):
print("Size of the features",features.shape)
print("Printing features:\\n", features)
print("Printing targets:\\n", targets)
break以上是关于:时间序列模型的主要内容,如果未能解决你的问题,请参考以下文章