zset如何解决内部链表查找效率低下
Posted 烟花散尽13141
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zset如何解决内部链表查找效率低下相关的知识,希望对你有一定的参考价值。
zset作为有序集合,内部基于跳表或者说索引的方式实现了数据的快速查找。解决了链表查询效率低下的痛点
前言
- 紧接前文我们学习了
Redis中Hash结构。在里面我们梳理了字典这个重要的内部结构并分析了hash结构rehash的流程从而解释了为什么redis单线程还是那么快 - 本章节我们将视角下推,继续学习
Redis五大天王中的zset数据结构 ;zset是有序不重复集合其内部元素唯一且是有序的,他的排序标准是根据其内部score维度进行排序的。
zset结构
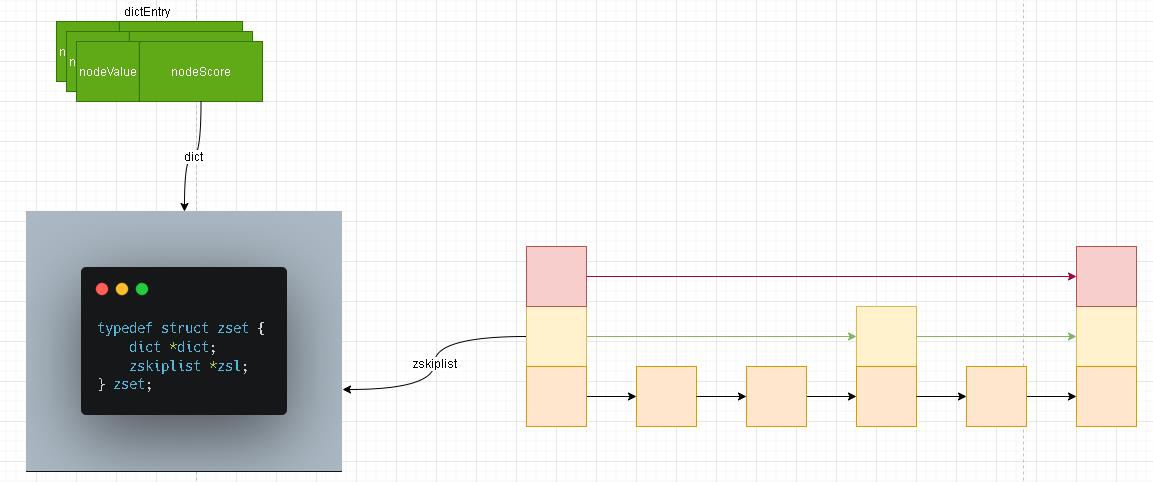
基本单元
- 关于zset结构很简单,一个是我们之前学习的字典结构(简单理解成Hash结构),另外一个是跳跃表结构 ; 关于字典我们上一章节已经详细解说了其内部的构造及其如何进行数据扩容等操作!剩下的且符合今天我们学习主旨的自然就是这个熟悉又陌生的
zskiplist。 - 我们根据上面zset的结构图也能够看出来,zskiplist实际上就是一个链表。
zskiplist

- 我们查看源码不难看出其内部结构是对zset中链表的一个抽象描述。zskiplist首先会对这个链表记录其头结点、尾结点方便通过zskiplist进行遍历操作。剩下的length自然就是对内部的这个链表数量的统计。比较抽象的是这个level的理解。在上面我们也看到了zskiplist那个链表实际上会有分层的概念。笔者这里通过不同的颜色进行表述不同层级的概念。
- 笔者这里针对上述描述的跳跃表内部的zskiplist绘画了一张内部数据图

- 在对zskiplist结构描述和数据描述中我将他们拆开理解,觉得这样更容易理解结构关系。下面是整个图示

- 细心的读者应该能够发现,我好想漏掉了链表重要组成部分
zskiplistNode这个重要的节点说明。实际上他就是我们右侧那个链表中节点。换句话说链表中每个点就是zskiplistNode 。
level
- 跳跃表的重要特性类型与树结构可以避免逐个遍历的苦恼。那么他是如何实现这种跳跃性质的访问的呢?还有一点为什么redis会这么设计。首先我们先回答下为什么这么设计。在链表中插入、删除等操作是很快速的只需要改变指针指向就可以完成。但是对于查询来说他需要遍历整个链表才能完成操作。针对链表的这个弊端redis设计了跳表的数据结构。
- 下面就是针对如何实现来简单梳理下。上述zskiplistNode节点对象结构中我们也可以看到有个level属性。redis就是通过这个属性来实现跳跃的特性。在每个节点生成的时候回随机生成这个level值。他就表示这个节点所在层的范围。
- 关于这个level为什么说是随机。这有牵涉到其内部的幂等性算法。这个算法保证数字越大生成的概览越小。在redis内部level最大值32.
- 比如说level随机生成5 。 表示当前节点node在level1~level5这五层中。上面的图示中所示的三个节点生成的level值分别是level3、level2、level7。注意在实际存储中level索引时从0开始。
forward
- 在level中还有两个属性分别是前进指针、跨越长度。根据字面意思我们能够理解前进指针是想链表后端方向推进的指针。其跨度就是表示当前节点距离前进指针处节点的距离。这个距离的是参考最底层的距离的。
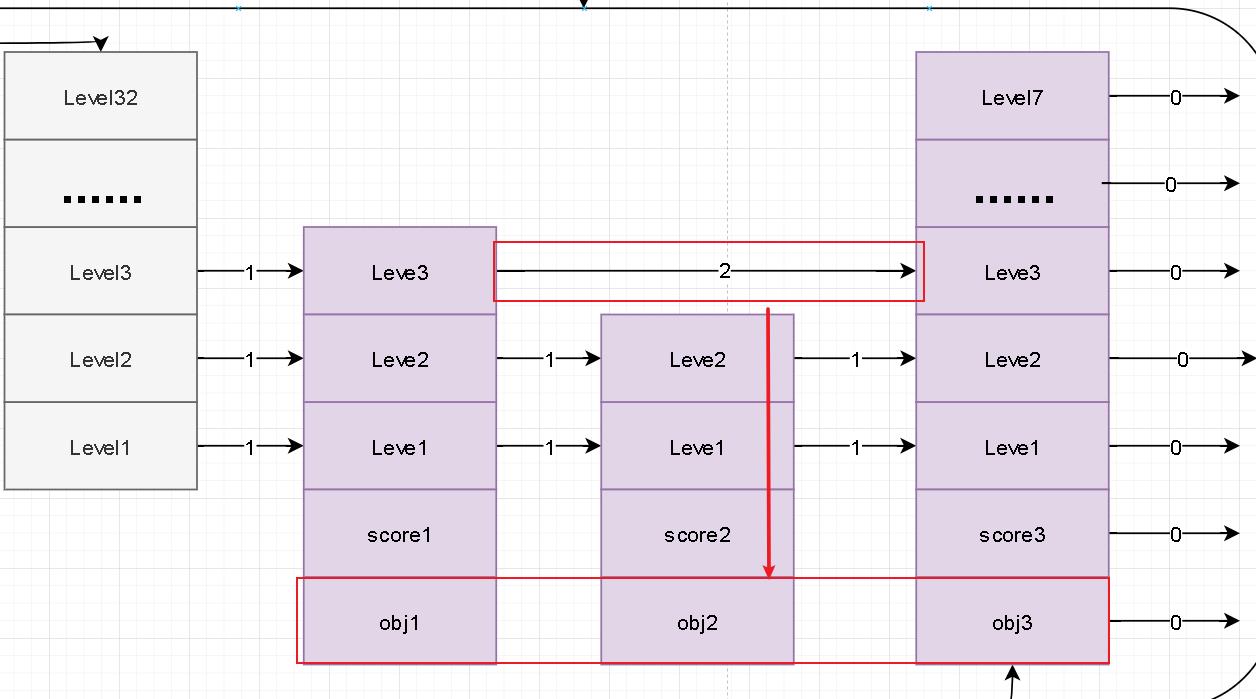
双链表
- 在zskiplist中每一层都是一个单向链表。在level中通过forwar指针指向我们表尾。那么为什么我说是双链表呢?这里的双链表不是严格意义的双链表。但是我们可以借助这些层级的单链表实现我们双向自由路由。

随机层

-
上面我们已经解释过level的定义了。那么为什么这里还有再提一遍呢?因为上面我们简单提到了幂等性算法。这里我们就详细解释下什么是幂等性。
-
首先根据level的定义我们可以总结如下几点关于level的特性。
-
①、一个节点如果在level[i]中,那么他一定在level[i]以下的层中
-
②、越高层元素跨度越大,这个跨度是不定的。取决于生成节点时的随机算法
-
③、每一层都是一个链表

- 这是redis中源码部分。关于这个随机level的算法其实不是很难理解。笔者这里将上述代码进行流程化梳理

- 就是一个不断重试的机制。其中p和maxLevel都是代码中的固定值。在这个算法机制下我们就可以尽可能的保证在数据量小的情况下保证level不会特别的高。
- 换句话说我们的level就不会显得特别的突兀。如果是纯粹的随机生成的话就有可能有的节点level很低,有的level很高。这样会造成资源不必要的浪费。
查找
- 好了,同学们到了这里我们已经学习了关于zset的基本结构。 简单回顾下内部就是字典+跳表的结合。下面我们针对这两种数据结构来简单梳理下关于zset的常用的一些操作!
- 首先就是我们的查找。上面说了那么多内部结构。纸上谈兵终觉浅,我们还需要实战操作一下。
分数定位

- 上述的命令基本都是通过分数定位然后在做自己的业务处理。

- 图示中已经说明了我们过程。首先是在最高层中寻找因为高层最稀疏。当高层没有发现时我们就会下推层级。此时我们来到level中的节点1.然后在通过forwar指针进行前移。最终定位节点5。
- 还有一点补充说明:节点中通过obj指针指向实际内容,score存储分支;笔者这里为什么演示方便直接在节点中标注了分数。其他部分并未进行标注!!!
成员定位
- 笔者在整理相关逻辑的时候也是经过百度、视频、书籍等方式翻阅后作出的结论。原谅我的能力无法直接阅读源码!但是在查阅资料的过程中。发现很少有说明是如何进行成员定位的。因为zset中除了分数的相关命令以外还有不少是基于成员定位的。

- 上述命令部分是基于成员进行定位的。在zset结构中实际节点是有基于score进行排序的。在obj中没有顺序可言。我们无法按照我们上述通过分数进行逐层定位元素!这就牵扯到我们另外一个重要的角色【字典(hash)】了。

- 上图是我们上一章节的关于字典的说明。在通过成员定位的时候我们就是多了一步先从字典中定位到分数,然后在重复上面的步骤进行定位!
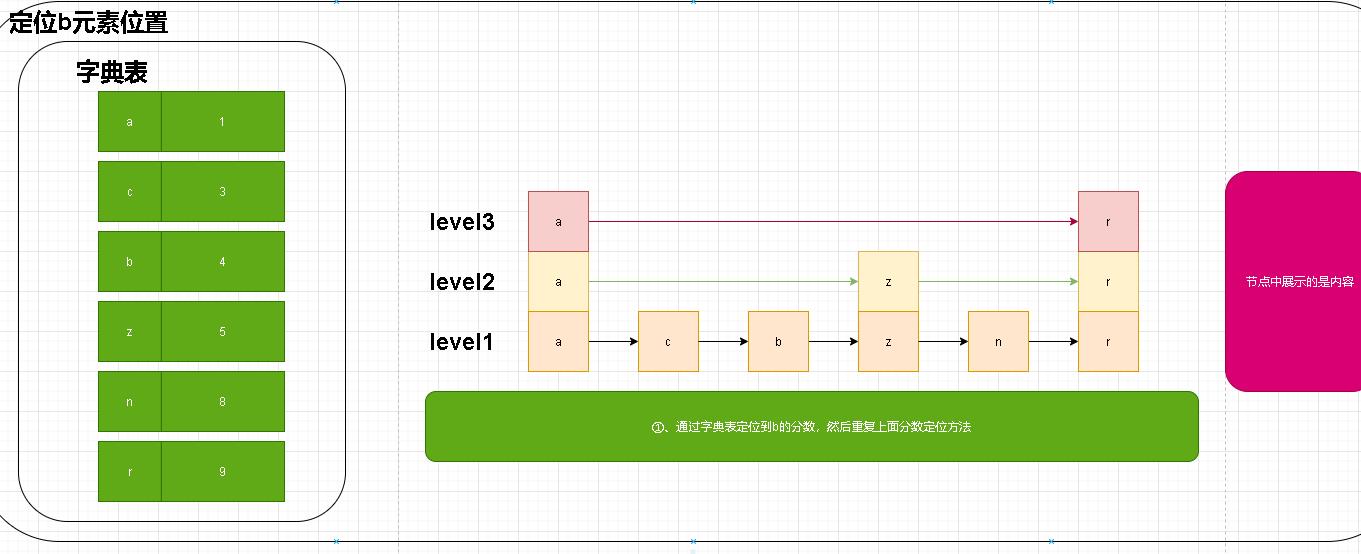
- 了解结构自然就能很容易理解相关的操作。站在巨人的肩膀我们虽然不需要在重复的造轮子了。但是我们得知道当初前辈们造轮子的过程!吃水不忘挖井人!
命令内部理解
- 了解结构就能快速掌握命令,否则就算死记硬背命令过一阵子又会忘记了。但是牢记结构后我们就会知道有命令可以实现我们的需求然后根据手册就可以得心应手。下面我们看看一下四个命令是如何实现的吧。
zcard
- 通过zskiplist中length属性
zcount
- 通过分数定位边界,然后遍历底层链表最终得到统计数量
zlecount
- 通过字典定位分数,在执行zcount操作
zrank
- 返回有序集合中指定成员的索引 , 先定位成员,定位过程中通过span可以确定排名
总结
- zset是一种有序链表。为了解决链表查询低下从而redis构建了跳表的数据结构。大大提高了效率!
- 关于zset的数据结构我们实际好多案例可以通过它来实现;延时队列、内部LRU、热点数据等等
点赞、关注不迷路哦
以上是关于zset如何解决内部链表查找效率低下的主要内容,如果未能解决你的问题,请参考以下文章