翻译: 网页排名PageRank算法的来龙去脉 以及 Python实现
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译: 网页排名PageRank算法的来龙去脉 以及 Python实现相关的知识,希望对你有一定的参考价值。
PageRank ( PR ) 是Google 搜索用来在其搜索引擎结果中对网页进行排名的算法。它以“网页”一词和联合创始人拉里佩奇的名字命名。PageRank 是衡量网站页面重要性的一种方法。根据谷歌:
PageRank 通过计算页面链接的数量和质量来确定网站重要性的粗略估计。基本假设是更重要的网站可能会收到更多来自其他网站的链接。[1]
目前,PageRank 不是谷歌用来排序搜索结果的唯一算法,但它是该公司使用的第一个算法,也是最知名的。[2] [3]截至 2019 年 9 月 24 日,PageRank 和所有相关专利均已过期。[4]
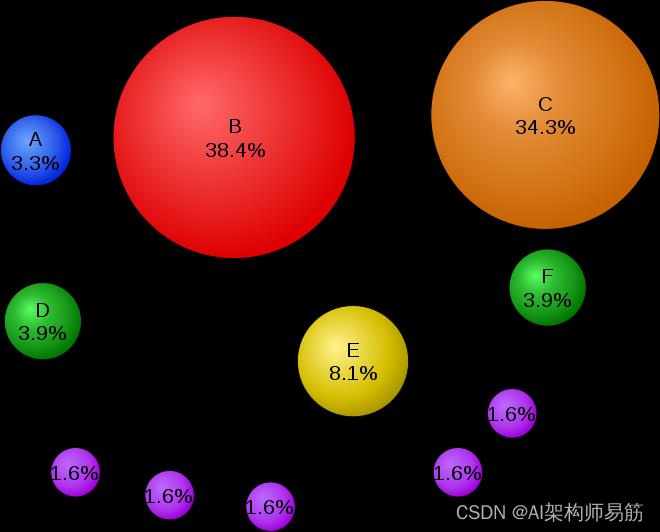
简单网络的数学 PageRank 以百分比表示。(Google 使用对数刻度。)页面 C 的 PageRank 比页面 E 高,即使指向 C 的链接更少;指向 C 的一个链接来自一个重要页面,因此具有很高的价值。如果从随机页面开始的网络冲浪者有 82.5% 的可能性从他们当前访问的页面中选择随机链接,并且有 17.5% 的可能性跳转到从整个网络中随机选择的页面,他们将到达页面 E 8.1% 的时间。(跳转到任意页面的 17.5% 的可能性对应于阻尼因子82.5%。)如果没有阻尼,所有网络冲浪者最终都会出现在页面 A、B 或 C 上,而所有其他页面的 PageRank 将为零。在存在阻尼的情况下,页面 A 有效地链接到网络中的所有页面,即使它没有自己的传出链接。
1. 说明
PageRank 是一种链接分析算法,它为一组超链接文档(如万维网)中的每个元素分配一个数值权重,目的是“测量”其在集合中的相对重要性。该算法可以应用于具有相互引用和引用的任何实体集合。它分配给任何给定元素E的数值权重称为 E 的PageRank并表示为 \\displaystyle PR(E).公关(E)。
PageRank 源自基于webgraph的数学算法,由所有万维网页面作为节点创建,超链接作为边缘创建,同时考虑了cnn.com或mayoclinic.org等权威中心。排名值表示特定页面的重要性。指向页面的超链接算作支持投票。一个页面的 PageRank 是递归定义的,它取决于链接到它的所有页面的数量和 PageRank 度量(“传入链接”)。由许多 PageRank 高的页面链接到的页面本身会获得高排名。
自 Page 和 Brin 的原始论文以来,已经发表了许多关于 PageRank 的学术论文。[5]在实践中,PageRank 概念可能容易受到操纵。已经进行了研究以识别受到错误影响的 PageRank 排名。目标是找到一种有效的方法来忽略具有错误影响 PageRank 的文档中的链接。[6]
其他基于链接的网页排名算法包括Jon Kleinberg发明的HITS 算法(Teoma和现在的Ask.com使用)、IBM CLEVER 项目、TrustRank算法和Hummingbird算法。[7]

说明 PageRank 基本原理的漫画。每个面的大小与指向它的其他面的总大小成正比。
2. 历史
加布里埃尔平斯基和弗朗西斯纳林在 1976年提出了特征值问题,他们在科学计量学排名科学期刊上工作,[8] 1977 年由Thomas Saaty在他的分析层次过程的概念中提出,该概念加权替代选择,[9]和 1995 年由布拉德利提出Love和Steven Sloman作为概念的认知模型,中心性算法。[10] [11]
1996 年由李彦宏设计的 IDD Information Services 的名为“ RankDex ”的搜索引擎制定了网站评分和页面排名策略。[12]李将他的搜索机制称为“链接分析”,它涉及根据链接到该网站的其他网站的数量对网站的受欢迎程度进行排名。[13] RankDex 是第一个具有页面排名和站点评分算法的搜索引擎,于 1996 年推出。[14] Li 于 1997 年在 RankDex 中申请了该技术的专利;它于 1999 年被授予。[15]后来他在 2000 年在中国创立百度时使用了它。 [16] [17]谷歌创始人拉里佩奇在他的一些美国 PageRank 专利中引用了 Li 的工作作为引用。[18] [14] [19]
拉里佩奇和谢尔盖布林于 1996 年在斯坦福大学开发了 PageRank,作为关于一种新型搜索引擎的研究项目的一部分。对Héctor García-Molina的采访:斯坦福计算机科学教授和 Sergey 的顾问[20] 提供了页面排名算法开发的背景。[21] Sergey Brin 的想法是,网络上的信息可以通过“链接流行度”在层次结构中排序:一个页面的排名越高,因为它有更多的链接。[22]该系统是在 Scott Hassan 和 Alan Steremberg 的帮助下开发的,Page 和 Brin 都认为他们对 Google 的发展至关重要。[5] 拉吉夫·莫特瓦尼和Terry Winograd与 Page 和 Brin 共同撰写了关于该项目的第一篇论文,描述了 PageRank 和Google 搜索引擎的初始原型,发表于 1998 年。[5]不久之后,Page 和 Brin 创立了Google Inc.,该公司背后的公司谷歌搜索引擎。虽然只是决定 Google 搜索结果排名的众多因素之一,但 PageRank 继续为 Google 的所有网络搜索工具提供基础。[23]
“PageRank”这个名字来源于开发者拉里佩奇的名字,以及网页的概念。[24] [25]这个词是谷歌的商标,PageRank 过程已获得专利(美国专利 6,285,999)。然而,该专利被转让给斯坦福大学而不是谷歌。谷歌拥有斯坦福大学专利的独家许可权。该大学获得了 180 万股谷歌股票以换取该专利的使用;2005年以3.36亿美元出售股份。[26] [27]
PageRank 受到引文分析的影响,该分析由宾夕法尼亚大学的Eugene Garfield在 1950 年代早期开发,并受到帕多瓦大学的Massimo Marchiori开发的Hyper Search的影响。在 PageRank 推出的同一年(1998 年),Jon Kleinberg发表了他关于HITS的作品。Google 的创始人在他们的原始论文中引用了 Garfield、Marchiori 和 Kleinberg。[5] [28]
3. 算法
PageRank 算法输出一个概率分布,用于表示一个人随机点击链接将到达任何特定页面的可能性。可以为任何大小的文档集合计算 PageRank。在几篇研究论文中假设分布在计算过程开始时在集合中的所有文档中平均分配。PageRank 计算需要多次通过,称为“迭代”,通过集合来调整近似的 PageRank 值以更接近地反映理论真实值。
概率表示为 0 到 1 之间的数值。0.5 的概率通常表示为某事发生的“50% 机会”。因此,PageRank 为 0.5 的文档意味着点击随机链接的人有 50% 的机会被定向到该文档。
3.1 简化算法
假设有四个网页的小宇宙:A、B、C和D。从页面到自身的链接将被忽略。从一个页面到另一个页面的多个出站链接被视为单个链接。PageRank 被初始化为所有页面的相同值。在 PageRank 的原始形式中,所有页面的 PageRank 之和是当时网络上的页面总数,因此本示例中的每个页面的初始值都为 1。但是,更高版本的 PageRank,以及本节的其余部分,假设概率分布在 0 和 1 之间。因此,本示例中每一页的初始值为 0.25。
在下一次迭代中,从给定页面转移到其出站链接目标的 PageRank 在所有出站链接中平均分配。
如果系统中唯一的链接是从页面B、C和D到A,则每个链接将在下一次迭代时将 0.25 PageRank 转移到A,总共 0.75。
PR(A)=PR(B)+PR(C)+PR(D)
假设页面B具有指向页面C和A的链接,页面C具有指向页面A的链接,页面D具有指向所有三个页面的链接。因此,在第一次迭代时,页面B会将其现有值的一半(即 0.125)转移到页面A,而将另一半(即 0.125)转移到页面C。页面C会将其所有现有值 0.25 转移到它链接到的唯一页面A。由于D有 3 个出站链路,它会将其现有值的三分之一(大约 0.083)转移到A. 在此迭代完成时,页面A的 PageRank 大约为 0.458。
PR(A)=PR(B) / 2 + PR(C) / 1 + PR(D) / 3
换句话说,出站链接赋予的 PageRank 等于文档自己的 PageRank 分数除以出站链接的数量L(·)。
PR(A)= PR(B) / L(B) + PR(C) / L(C) + PR(D) / L(D)
在一般情况下,任何页面u的 PageRank 值都可以表示为:
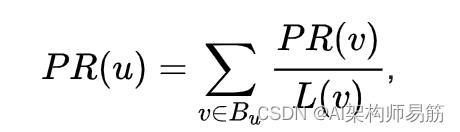
即页面u的 PageRank 值取决于集合B u(包含链接到页面u的所有页面的集合)中包含的每个页面v的 PageRank 值除以来自页面v的链接数L ( v ) 。
3.2 阻尼系数
PageRank 理论认为,一个想象中的随机点击链接的冲浪者最终会停止点击。在任何一步,该人将继续的概率是阻尼因子d。各种研究已经测试了不同的阻尼系数,但通常假设阻尼系数将设置在 0.85 左右。[5]
从 1 中减去阻尼因子(在算法的某些变体中,结果除以集合中的文档数 ( N )),然后将该项添加到阻尼因子和总和的乘积中传入的 PageRank 分数。那是,
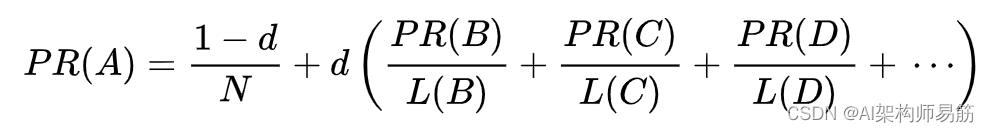
因此,任何页面的 PageRank 很大程度上都来源于其他页面的 PageRank。阻尼因子将导出值向下调整。然而,原始论文给出了以下公式,这导致了一些混乱:
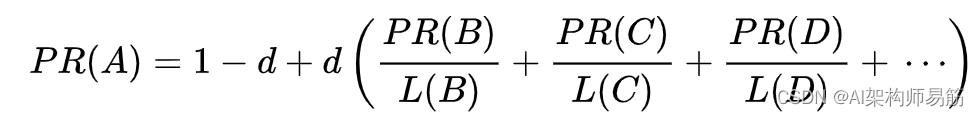
它们之间的区别在于,第一个公式中的 PageRank 值总和为 1,而在第二个公式中,每个 PageRank 乘以N,总和变为N。Page 和 Brin 的论文中声明“所有 PageRank 的总和为 1” [5]以及其他 Google 员工[29]的声明支持上述公式的第一个变体。
Page 和 Brin 在他们最受欢迎的论文“大规模超文本 Web 搜索引擎的剖析”中混淆了这两个公式,他们错误地声称后一个公式形成了网页上的概率分布。[5]
每次爬网并重建其索引时,Google 都会重新计算 PageRank 分数。随着 Google 增加其集合中的文档数量,所有文档的 PageRank 的初始近似值都会降低。
该公式使用随机冲浪者的模型,该模型在几次点击后到达目标站点,然后切换到随机页面。页面的 PageRank 值反映了随机浏览者通过单击链接登陆该页面的机会。可以理解为一个马尔可夫链,其中状态是页面,转换是页面之间的链接——所有这些都是等概率的。
如果一个页面没有指向其他页面的链接,它就会成为一个接收器,因此终止随机冲浪过程。如果随机冲浪者到达接收器页面,它会随机选择另一个URL并继续再次冲浪。
在计算 PageRank 时,假定没有出站链接的页面链接到集合中的所有其他页面。因此,他们的 PageRank 分数在所有其他页面之间平均分配。换句话说,为了公平对待不是接收器的页面,这些随机转换被添加到 Web 中的所有节点。这个残差概率d通常设置为 0.85,根据普通冲浪者使用他或她的浏览器书签功能的频率估计。所以,方程如下:
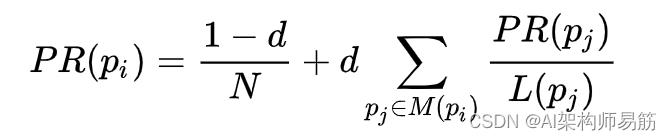
在哪里p1, p2, ..., pn是正在考虑的页面,M§是链接到的一组页面pi, L(pj)是页面上的出站链接数pj, 和N是总页数。
PageRank 值是修改后的邻接矩阵的主要右特征向量的条目,经过重新缩放,每列加起来为 1。这使得 PageRank 成为一个特别优雅的度量:特征向量是

其中R是方程的解
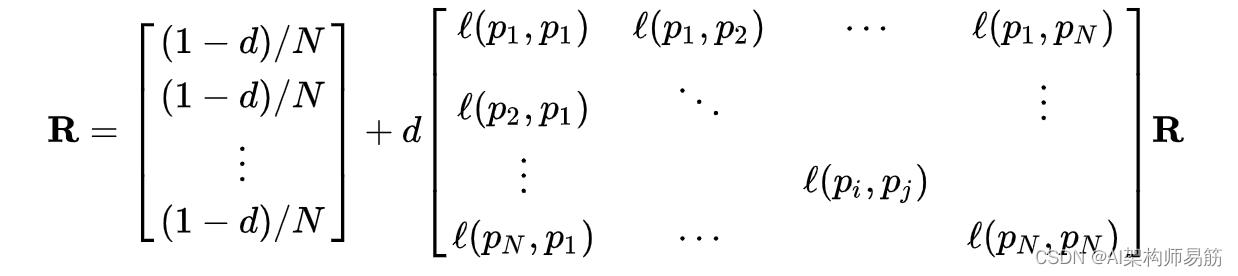
其中邻接函数l(pi,pj)是从页面 j 到页面 i 的出站链接数与页面 j 的出站链接总数的比率。如果页面邻接函数为0pj不链接到pi, 并归一化,使得对于每个j

即每列的元素总和为1,所以矩阵是一个随机矩阵(更多细节见下面的计算部分)。因此,这是网络分析中常用的特征向量中心性度量的变体。
由于上述修改后的邻接矩阵的大特征间隙,[ 30] PageRank 特征向量的值可以在仅几次迭代内以高精度逼近。
Google 的创始人在他们的原始论文[28]中报告说,由 3.22 亿个链接(入边和出边)组成的网络的 PageRank 算法在 52 次迭代中收敛到可容忍的限制内。在上述一半大小的网络中收敛大约需要 45 次迭代。通过这些数据,他们得出结论,该算法可以很好地缩放,并且超大型网络的缩放因子在\\displaystyle \\log n\\日志n,其中 n 是网络的大小。
作为马尔可夫理论的结果,可以证明一个页面的PageRank是经过大量点击后到达该页面的概率。这恰好等于\\displaystyle t-1t-1在哪里\\displaystyle t吨是从页面返回到自身所需的点击次数(或随机跳转) 的期望值。
PageRank 的一个主要缺点是它偏爱旧页面。一个新页面,即使是一个非常好的页面,也不会有很多链接,除非它是现有站点的一部分(一个站点是一组紧密连接的页面,例如Wikipedia)。
已经提出了几种策略来加速 PageRank 的计算。[31]
为了提高搜索结果排名和通过广告链接获利,已经采用了各种操纵 PageRank 的策略。这些策略严重影响了 PageRank 概念的可靠性,[引用需要]旨在确定哪些文档实际上受到 Web 社区的高度重视。
自 2007 年 12 月开始积极惩罚销售付费文本链接的网站以来,Google 一直在打击链接农场和其他旨在人为抬高 PageRank 的计划。Google 如何识别链接农场和其他 PageRank 操纵工具属于 Google 的商业机密。
3.3 python 实现代码
"""PageRank algorithm with explicit number of iterations.
Returns
-------
ranking of nodes (pages) in the adjacency matrix
"""
import numpy as np
def pagerank(M, num_iterations: int = 100, d: float = 0.85):
"""PageRank: The trillion dollar algorithm.
Parameters
----------
M : numpy array
adjacency matrix where M_i,j represents the link from 'j' to 'i', such that for all 'j'
sum(i, M_i,j) = 1
num_iterations : int, optional
number of iterations, by default 100
d : float, optional
damping factor, by default 0.85
Returns
-------
numpy array
a vector of ranks such that v_i is the i-th rank from [0, 1],
v sums to 1
"""
N = M.shape[1]
v = np.ones(N) / N
M_hat = (d * M + (1 - d) / N)
for i in range(num_iterations):
v = v @ M_hat
return v
M = np.array([[0, 0, 0, 0, 1],
[0.5, 0, 0, 0, 0],
[0.5, 0, 0, 0, 0],
[0, 1, 0.5, 0, 0],
[0, 0, 0.5, 1, 0]])
v = pagerank(M, 100, 0.85)
4. 变体
4. 1 无向图的 PageRank
无向图的 PageRank G在统计上接近图的度分布 G, [36]但它们通常不相同:如果R是上面定义的 PageRank 向量,并且D是度分布向量

也就是说,无向图的PageRank等于度分布向量当且仅当图是规则的,即每个顶点具有相同的度。
4. 2 两种排序对象的 PageRank 和特征向量中心性的推广
Daugulis 描述了对两个交互对象组进行排名的情况下的 PageRank 推广。[38]在应用程序中,可能需要对具有两种对象的系统进行建模,其中在对象对上定义了加权关系。这导致考虑二分图。对于这样的图,可以定义对应于顶点划分集的两个相关的正或非负不可约矩阵。可以将两组中对象的排名计算为对应于这些矩阵的最大正特征值的特征向量。根据 Perron 或 Perron-Frobenius 定理,范数特征向量存在并且是唯一的。例如:消费者和产品。关系权重是产品消耗率。
4. 3 PageRank计算的分布式算法
萨尔马等人。描述了两种基于随机游走的分布式算法,用于计算网络中节点的 PageRank。

4. 4 谷歌工具栏
长期以来,Google 工具栏都有一个 PageRank 功能,可以将访问页面的 PageRank 显示为一个介于 0(最不受欢迎)和 10(最受欢迎)之间的整数。谷歌没有透露确定工具栏 PageRank 值的具体方法,这被认为只是网站价值的粗略指示。通过 Google 网站管理员工具界面,经过验证的网站维护者可以使用“工具栏 Pagerank”。然而,在 2009 年 10 月 15 日,一名 Google 员工证实该公司已将 PageRank 从其网站管理员工具部分中删除,称“我们长期以来一直在告诉人们,他们不应该如此关注 PageRank。许多网站业主似乎认为这是最重要的指标让他们跟踪,这根本不是真的。” [40]
“工具栏 Pagerank”很少更新。它最后一次更新是在 2013 年 11 月。2014 年 10 月,Matt Cutts 宣布不会再出现另一个可见的 pagerank 更新。[41] 2016 年 3 月,Google 宣布将不再支持此功能,并且底层 API 将很快停止运行。[42] 2016 年 4 月 15 日,Google 关闭了在 Google 工具栏中显示 PageRank 数据,[43]尽管 PageRank 继续在内部用于对搜索结果中的内容进行排名。
4. 5 SERP 排名
搜索引擎结果页面(SERP)是搜索引擎响应关键字查询返回的实际结果。SERP 包含一个链接到网页的列表以及相关的文本片段。网页的 SERP 排名是指相应链接在 SERP 上的位置,位置越高意味着 SERP 排名越高。网页的 SERP 排名不仅是其 PageRank 的函数,而且是一组相对较大且不断调整的因素(超过 200 个)的函数。[45] [来源不可靠?] 搜索引擎优化(SEO) 旨在影响一个网站或一组网页的 SERP 排名。
网页在 Google SERP 上的关键字定位取决于相关性和声誉,也称为权威和流行度。PageRank 是 Google 对网页声誉评估的指标:它与关键字无关。谷歌使用网页和网站权限的组合来确定竞争关键字的网页的整体权限。[46]网站主页的 PageRank 是谷歌为网站权威提供的最佳指标。[47]
在将Google Places引入主流有机 SERP 之后,除了 PageRank 之外,还有许多其他因素会影响企业在本地业务结果中的排名。[48]当 Google 在 2016 年 3 月的问答环节中详细阐述弃用 PageRank 的原因时,他们宣布链接和内容是排名靠前的因素。RankBrain 在 2015 年 10 月早些时候被宣布为排名第三的因素,因此前 3 名因素已被 Google 正式确认。
4.6 Google 目录 PageRank
Google Directory PageRank 是一个 8 个单位的度量。与将鼠标悬停在绿色栏上时显示数字 PageRank 值的 Google 工具栏不同,Google 目录只显示栏,从不显示数值。Google 目录于 2011 年 7 月 20 日关闭。
4.7 虚假或欺骗的 PageRank
众所周知,工具栏中显示的 PageRank 很容易被 欺骗。通过HTTP 302响应或“刷新”元标记从一个页面重定向到另一个页面,导致源页面获取目标页面的 PageRank。因此,具有 PR 0 且没有传入链接的新页面可以通过重定向到 Google 主页获得 PR 10。欺骗通常可以通过对源 URL 执行 Google 搜索来检测;如果结果中显示的是完全不同站点的 URL,则后一个 URL 可能代表重定向的目标。
4.8 操纵 PageRank
出于搜索引擎优化的目的,一些公司提供向网站管理员出售高 PageRank 链接。[51]由于来自更高公关页面的链接被认为更有价值,它们往往更昂贵。在优质的内容页面和相关网站上购买链接广告以增加流量并增加网站管理员的链接受欢迎程度是一种有效且可行的营销策略。然而,谷歌已公开警告网站管理员,如果他们正在或被发现出售链接以授予 PageRank 和声誉,他们的链接将被贬值(在计算其他页面的 PageRank 时忽略)。买卖[52]的做法在网站管理员社区中引起了激烈的争论。Google 建议网站管理员使用 付费链接上的nofollow html 属性值。根据Matt Cutts的说法,谷歌担心那些试图玩弄系统的网站管理员,从而降低谷歌搜索结果的质量和相关性。[51]
2019 年,Google 提供了一种新型标签,它不传递“链接汁”,因此对 SEO 链接操作没有价值:rel=“ugc” 作为用户生成内容的标签,例如评论;和 rel=“赞助” 标签用于广告或其他类型的赞助内容。[53]
尽管 PageRank 对于 SEO 目的变得不那么重要,但来自更受欢迎网站的反向链接的存在继续推动网页在搜索排名中更高。
4.9 定向冲浪者模型
一个更智能的冲浪者,它可以根据页面内容和冲浪者正在寻找的查询词来概率地从一个页面跳到另一个页面。该模型基于页面的查询相关的 PageRank 分数,顾名思义,它也是查询的函数。当给定一个多词查询时,\\displaystyle Q=q1,q2,\\cdots \\displaystyle Q=q1,q2,\\cdots ,冲浪者选择一个\\displaystyle qq根据某种概率分布,\\displaystyle P(q)P(q),并使用该术语来指导其大量步骤的行为。然后它根据分布选择另一个术语来确定其行为,依此类推。所访问网页上的结果分布是 QD-PageRank。
4.10 社交组件
Katja Mayer 将 PageRank 视为一个社交网络,因为它将不同的观点和想法连接在一个地方。[56] 人们去 PageRank 获取信息,并被其他作者的引用淹没,这些作者也对该主题有意见。这创造了一个社交方面,可以讨论和收集所有内容以激发思考。PageRank 与使用它的人之间存在着一种社会关系,因为它不断适应和改变现代社会的变化。通过社会统计查看 PageRank 与个人之间的关系,可以深入了解产生的联系。
[57] Matteo Pasquinelli 认为,PageRank 具有社会成分的信念的基础在于注意力经济的概念。. 在注意力经济中,人们重视那些获得更多人类关注的产品,并且 PageRank 顶部的结果比后续页面上的结果更受关注。因此,PageRank 较高的结果将更大程度地进入人类意识。这些想法可以影响决策,并且查看者的行为与 PageRank 有直接关系。他们拥有更高的潜力来吸引用户的注意力,因为他们的位置增加了与网站相关的注意力经济。有了这个位置,他们可以获得更多的流量,他们的在线市场将有更多的购买。这些网站的 PageRank 使他们受到信任,并且他们能够利用这种信任来增加业务。
4.11 其他用途
PageRank 的数学是完全通用的,适用于任何领域的任何图形或网络。因此,PageRank 现在经常用于文献计量学、社会和信息网络分析,以及链接预测和推荐。它用于道路网络的系统分析,以及生物学、化学、神经科学和物理学。
5. 科学研究和学术界
PageRank 已被用于量化研究人员的科学影响。底层引用和协作网络与 pagerank 算法结合使用,以便为传播给单个作者的单个出版物提供一个排名系统。在 h-index 表现出的许多缺点的背景下,被称为 pagerank-index (Pi) 的新索引被证明比 h-index 更公平。[59]
对于生物学中的蛋白质网络分析,PageRank 也是一个有用的工具。[60] [61]
在任何生态系统中,PageRank 的修改版本可用于确定对环境持续健康至关重要的物种。[62]
PageRank 的一个类似的新用途是根据他们将毕业生安置在教师职位上的记录对学术博士课程进行排名。在 PageRank 术语中,学术部门通过相互(和他们自己)雇用教师来相互联系。[63]
最近提出了一个 PageRank 版本来替代传统的科学信息研究所(ISI)影响因子[64],并在Eigenfactor和SCImago中实施。不是仅仅计算对期刊的总引用次数,而是以 PageRank 方式确定每次引用的“重要性”。
在神经科学中,已发现神经网络中神经元的 PageRank与其相对放电率相关。
6. 互联网使用
-
Twitter使用个性化 PageRank向用户展示他们可能希望关注的其他帐户。[66]
-
Swiftype的网站搜索产品通过查看每个网站的重要性信号并根据主页链接数量等因素对内容进行优先排序,从而构建“特定于各个网站的 PageRank”。[67]
-
Web 爬虫可以使用PageRank 作为其用于确定在 Web 爬网期间访问哪个 URL 的多个重要性指标之一。用于创建 Google的早期工作论文之一[68]是Efficient crawling through URL ordering,[69]讨论了使用许多不同的重要性指标来确定 Google 网站的深度和多少会爬行。PageRank 被表示为这些重要性指标之一,尽管还列出了其他一些指标,例如 URL 的入站和出站链接的数量,以及从站点上的根目录到 URL 的距离。
-
PageRank 也可以用作衡量像博客圈这样的社区对整个 Web 本身的明显影响的方法。因此,这种方法使用 PageRank 来衡量注意力的分布,以反映无标度网络范式。
7. 其他应用
2005 年,在巴基斯坦的一项试点研究中,结构性深层民主,SD2 [70] [71]被用于一个名为 Contact Youth 的可持续农业组织的领导层选拔。SD2 使用PageRank来处理传递代理投票,附加约束要求每个选民至少有两个初始代理,并且所有选民都是代理候选人。可以在 SD2 之上构建更复杂的变体,例如添加专家代理和对特定问题的直接投票,但 SD2 作为底层的伞式系统,要求始终使用通才代理。
在体育运动中,PageRank 算法已被用于对以下球队的表现进行排名: 美国国家橄榄球联盟 (NFL) 球队;[72] 个人足球运动员;[73]和钻石联赛的运动员。[74]
PageRank 已用于对空间或街道进行排名,以预测有多少人(行人或车辆)来到各个空间或街道。[75] [76]在词汇语义中,它已被用于执行词义消歧、[77] 语义相似性、[78],还可以根据WordNet 同义词集具有给定语义属性的强度(例如积极性或消极性。
8. nofollow
005 年初,Google为 HTML 链接和锚元素的rel属性实施了一个新值,“ nofollow ”,[80],以便网站开发人员和博主可以创建 Google 不会出于 PageRank 目的考虑的链接——它们是在 PageRank 系统中不再构成“投票”的链接。添加 nofollow 关系是为了帮助打击垃圾邮件索引。
例如,人们以前可以创建许多带有指向其网站的链接的留言板帖子,以人为地抬高他们的 PageRank。使用 nofollow 值,留言板管理员可以修改他们的代码以自动将“rel=‘nofollow’”插入帖子中的所有超链接,从而防止 PageRank 受到这些特定帖子的影响。然而,这种避免方法也有各种缺点,例如降低合法评论的链接价值。(请参阅:博客中的垃圾邮件#nofollow)
为了手动控制网站内页面之间的 PageRank 流量,许多网站管理员实践了所谓的 PageRank Sculpting [81] ——这是一种策略性地将 nofollow 属性放置在网站的某些内部链接上以便漏斗的行为网站管理员认为最重要的那些页面的 PageRank。这种策略自 nofollow 属性开始就已使用,但可能不再有效,因为 Google 宣布使用 nofollow 阻止 PageRank 传输不会将该 PageRank 重定向到其他链接。
9. 参考
https://en.wikipedia.org/wiki/PageRank
以上是关于翻译: 网页排名PageRank算法的来龙去脉 以及 Python实现的主要内容,如果未能解决你的问题,请参考以下文章