哈希算法&&Java中的HashMap实现原理
Posted Airsolstice
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希算法&&Java中的HashMap实现原理相关的知识,希望对你有一定的参考价值。
HashMap是通过一个Entry的数组实现的。而Entry的结构有三个属性,key,value,next。如果在c中,我们遇到next想到的必然是指针,其实在java这就是个指针。每次通过hashcode的值,来散列存储数据。而hashcode()这个犯法最简单的算法是:
String中的哈希算法:
public int hashCode()
int h = hash;
if (h == 0 && value.length > 0)
char val[] = value;
for (int i = 0; i < value.length; i++)
h = 31 * h + val[i];
hash = h;
return h;
其中为什么以31为乘数,我一直不是很明白...还请知道的人求教,不胜感激
h = 0;
h1 = h*31+104 = 0*31+104 = 104
h2=h1*31+97=104*31+97=3321
h3=h2*31+115=3321*31+115=103066
h4=h3*31+104=103066*31+104=3195150
通过上述算法得出一个hash值,然后按照如下的方法得出一个hash桶,这个桶就是用来存放指向这个哈希桶的值的,因此也可以叫一个哈希域。
int index = (hash & 0x7FFFFFFF) % length;</pre><pre code_snippet_id="1635422" snippet_file_name="blog_20160405_2_9723445" name="code" class="java"></pre><pre code_snippet_id="1635422" snippet_file_name="blog_20160405_2_9723445" name="code" class="java"><pre name="code" class="java">// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];这个哈希域其实是一个指针链表。正如上面所说的,HashMap其实是一个Entry<E >的数组,这个数组的下标指针其实是行,也是哈希桶的域。而Entry中next指针,其实是行的内容,也是桶的容器,它是一个链表,所以容量可以灵活变化
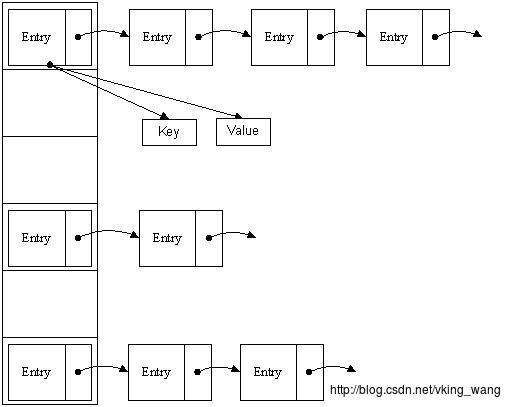
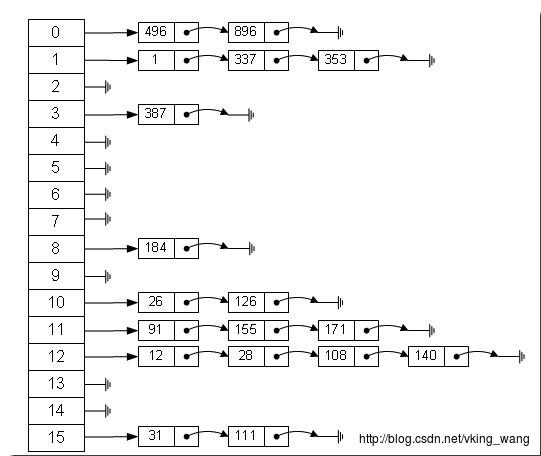
因此,hashmap其实就是形象的将一个数组分类了,而数组的每个下标表示一个桶,每个桶就是一个域,每次寻找一个值时,只要先算得到这个内容的hashcode,就可以知道在哪个域里面了,这将会省很多的迭代过程。
在我们平常用的过程中,equals()和hashcode()这两个方法其实需要同时复写。我们都知道,继承Object的类其实都是需要复写equals()的,不然这个方法的本身其实就是‘==’的作用。但是,在复写equals方法的时候,需要注意的是,一定要保证hashcode的唯一性。也要保证一个hashcode内容的唯一性。所以很多时候,在复写equals的同时,也要复写hashcode方法。
这是String中的equals方法:
public boolean equals(Object anObject)
if (this == anObject)
return true;
if (anObject instanceof String)
String anotherString = (String) anObject;
int n = value.length;
if (n == anotherString.value.length)
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0)
if (v1[i] != v2[i])
return false;
i++;
return true;
return false;
在HashMap中,判断两个值是否相等的过程是:
**判断这个两个对象引用是否一样,如果一样,说明是一个对象,返回true;否则,下一步
**计算这个两个字符串的hashcode是否一样(在最初复写equals的时候,就应该结合hashcode(),这两者是相互印证的),如果不一样,返回false;否则,下一步
**将这两个字符串内容,逐位比较,知道最后一个内容都完全一样,返回true,否则,false
*****************************************************************************************************
到这里就分析结束了
以上内容部分参考自:http://blog.csdn.net/vking_wang/article/details/14166593
以上是关于哈希算法&&Java中的HashMap实现原理的主要内容,如果未能解决你的问题,请参考以下文章