(DDIA)数据存储与检索——LSM简介
Posted 雨钓Moowei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(DDIA)数据存储与检索——LSM简介相关的知识,希望对你有一定的参考价值。
一、SSTables and LSM-Trees
在上一篇文章《(DDIA)数据存储与检索(一)》的图3-3中,每个日志结构的segment文件存储的都是键值对。 这些key-value会按照他们被写入的顺序存储,并且在日志中后加的key-value的值更有用。
现在我们可以对segment文件的格式做一个简单的更改。 我们要求key-value对的序列按键排序。 乍一看,这个要求似乎破坏了顺序写的优势,但我们马上就会讲到这样做是值得的。
我们把这种格式称为Sorted String Table,或者 SSTable, 我们还需要每个key在每个合并的segment文件中只出现一次。(segment的压缩合并过程已经确保了这一点)。SSTables比使用Hashtable的log segment有几个显著的优点。:
-
segment文件的合并更加简单和高效,即使segment文件比可用内存大。 该方法与merge sort算法中使用的方法类似,如图3-4所示。 逐个读取输入文件,查看每个文件中的第一个key,将最低的key(根据排序顺序)复制到输出文件,然后重复。这将生成一个新的合并后的segment文件,且新的segment文件也是按key排好序的。

如果同一个key出现在多个输入的segment中会怎样? 当多个segment包含相同的key时,我们可以保留最近segment的value,并丢弃旧segment中的value。
-
为了在segment文件中找到一个特定的key,你不再需要在内存中保存所有key的索引。 请参见图3-5的示例:假设你正在查找key=handiwork的所有记录,但是你不知道该key在segment文件中的确切偏移量。 但是,你如果知道key=handbag和key=handsome的偏移量,因为segment是按照key排序的,所以 handiwork 一定在这两者之间出现。 这意味着你可以直接跳转到handbag的偏移位置,然后从那里挨个扫描所有数据,直到你找到 key=handiwork的记录(除非文件中没有这个key)。
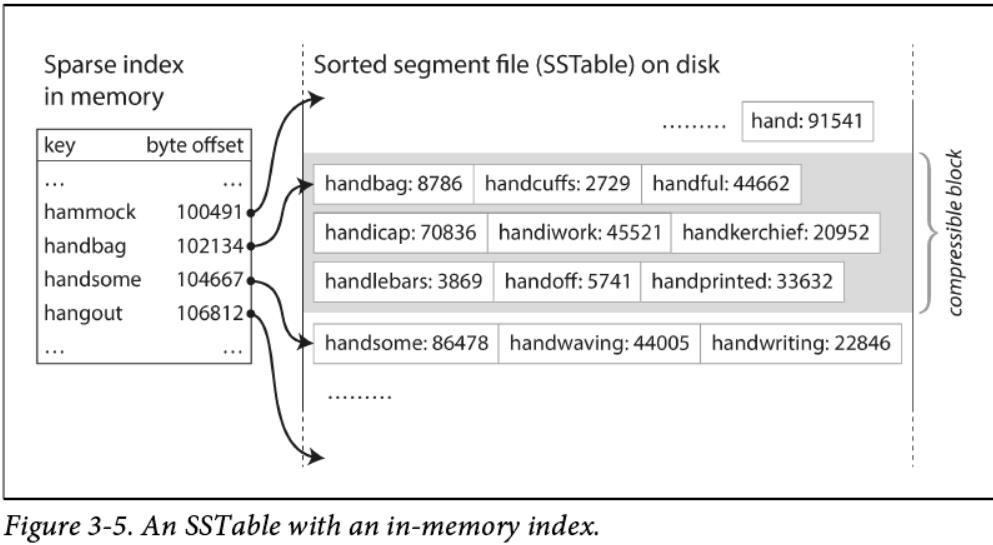
虽然你仍然需要一个内存索引来告诉您一些键的偏移量,但是这个内存索引可以是稀疏的:对于每一千个字节的segment文件来说,一个key就足够的,因为计算机可以非常快速地完成对这么小的数据的扫描( 如果所有的键和值都有固定的大小,那么可以在segment文件中使用二进制搜索,并且完全避免内存索引。然而,在实践中,key-value通常是可变长度的,这使得在没有索引的情况下很难确定一个记录的结束位置和下一个记录的开始位置。)
-
当读操作请求任意范围的几个键值对,可以将这些记录分组到一个块中,并在将其写入磁盘之前进行压缩(图3-5中的阴影区域表示)。稀疏内存索引中的每个key都指向一个压缩块的开始位置。除了节省磁盘空间外,压缩还减少了I/O的带宽占用。
二、Constructing and maintaining SSTables
如上,SSTable是有很大好处的,但是你如何让你的数据按key排序呢?我们的输入可以以任何顺序发生。 在磁盘上维护排序结构是可能的(参见第79页的“b -Tree”),然而在内存中维护它要容易得多。 你可以使用许多著名的树状数据结构例如red-black trees 或者 AVL trees [2]。 有了这些数据结构,你就可以以任意的顺序插入key,并按照排序顺序读取它们。
我们可以在数据引擎中这样做:
- 当写入数据时,将其添加到内存平衡树数据结构(例如,红黑树)中。这种内存中的树有时被称为Memtable。
- 当memtable超过某个阈值(通常是几兆字节)时,将其写入磁盘并作为一个SSTable文件存储。 这个操作是非常高效的,因为Memtable已经维护了按key排序的key-value数据对。 新的SSTable文件成为数据库的一部分。在将SSTable写入磁盘的同时,可以继续向新的Memtable实例中写入数据。
- 当向数据库进行读请求时,数据库首先要在Memtable中找到相应的key,然后尝试在最近的磁盘SSTable Segment中找到key,之后尝试在老的SSTable Segment中查找,知道找到该key,或者遍历完所有的SSTable Segment。
- 在后台会运行一个合并和压缩进程,以组合SSTable Segment文件,并抛弃哪些已经被覆盖或删除的值。
这个方案是非常高效的。 它只会遇到一个问题:如果数据库崩溃了,最近一段时间内写入的数据(这些数据存在Memtable中,还没有写到磁盘)就会丢失。为了避免这个问题,我们可以将一个单独的日志放在磁盘上,并且在这个日志中记录所有的写入的操作,且每个写入操作都可以立即被追加到这个日志文件中。 这个日志不是按顺序排列的,它是否排序都无关紧要,因为它唯一目的是在崩溃后恢复Memtable中的数据。 每次将Memtable写入一个SSTable之后就可以丢弃这个日志。
三、Making an LSM-tree out of SSTables
这里描述的算法被Level DB[6]和Rocks DB[7]所使用的,这些键值存储引擎库设计的目的是为了嵌入到其他应用程序中。除此之外,在Riak中可以使用Level DB并替代Bitcask。 类似的存储引擎应用在Cassandra和HBase[8]中,这两种方法都是受谷歌Bigtable的启发[9](介绍了SSTable and memtable的术语)
最初这个索引结构是Patrick O 'Neil等人提出的,命名为 Log-Structured Merge-Tree (or LSM-Tree) [10],主要目的是构建一个日志结构的文件系统。 基于类似合并和压缩文件原则的存储引擎通常被称为LSM存储引擎。
Lucene是一种索引引擎,用于支持Elasticsearch和Solr的全文搜索,它使用一个类似的方法来存储它的术语词典(term dictionary)[12,13]。 全文索引比键值索引更复杂,但基本思想是相似的。根据给定的词进行搜索查询,找到所有的有提及该词的文档 (网页、产品说明等)。 它也是是用key-value结构实现的,其中key是一个词(term),value是包含该单词的所有文档的id列表(张贴列表), 在Lucene中,这个从term到发布列表的映射以类似SStable的形式存储 ,同样存在相关的后台进程对这些文件进行合并[14]。
四、Performance optimizations
与往常一样,许多细节都是为了使存储引擎在实践中表现的更好。 例如,当查找数据库中不存在的key时,LSM-tree算法可能会很慢, 您需要先检查Memtable中的数据,然后检查SSTable segment中的数据,直到遍历完所有的SSTable segment(可能需要从磁盘中读取每个SSTable segment),然后才能确定该key不存在。 为了优化这种访问,通常存储引擎会使用布隆过滤器Bloom filter [15] (Bloom filter是一个内存数据结构,用于近似一个集合,它可以告诉你一个key是否出现在数据库中,从而省去了许多不必要的磁盘读取)
对于SSTables的压缩和合并的顺序以及时间等细节也有很多不同的实现。 最常见的选项是size-tiered和leveled compaction,Level DB 和 Rocks DB 使用的是leveled compaction (这正是Level DB名字的由来)。HBase 使用的是 size-tiered, 此外Cassandra 两种模式都支持[16]
在size-tiered compaction中,更新的和较小的SSTables依次被合并到更老的和更大的SSTables中。 在leveled compaction中,大的范围被分割成更小的SSTables,而旧的数据被移动到单独的“层”中,这样就可以使压缩更增量地进行,并减少使用磁盘空间。
尽管有许多微妙之处,但LSM-Trees的基本思想——保持在后台中合并SSTables——是简单而有效的。 当数据集比可用内存大得多的时候,它仍然可以运行良好。 由于数据是以排序之后存储的,所以你可以高效地执行范围查询,并且由于磁盘写操作也是顺序的,所以LSM-Tree可以实现非常高的写吞吐量。
未完待续。。。。

以上是关于(DDIA)数据存储与检索——LSM简介的主要内容,如果未能解决你的问题,请参考以下文章