CS231n笔记7-ConvNets Typical Architecture与VGGNet
Posted LiemZuvon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS231n笔记7-ConvNets Typical Architecture与VGGNet相关的知识,希望对你有一定的参考价值。
ConvNets Typical Architecture与VGGNet
ConvNets Typical Architecture-卷积神经网络经典结构
写到这里,小编已经大体覆盖了构建一个大型卷积神经网络所需要的知识点。下面是小编在上课是总结的卷积神经网络的结构。

读者是不是觉得上面的图的那些英文都似曾相识,是的,小编在之前的学习笔记中都有介绍,为了方便读者阅读,下面小编给出相应的链接
Conv与Pooling:http://blog.csdn.net/u012767526/article/details/51418288
Batch norm:http://blog.csdn.net/u012767526/article/details/51405701
FC与ReLU:http://blog.csdn.net/u012767526/article/details/51399596
Dropout:http://blog.csdn.net/u012767526/article/details/51407443
SOFTMAX/SVM:http://blog.csdn.net/u012767526/article/details/51396196
一个深度神经网络一般有以下两部分构成:
- 卷积部分
- 全连接部分
卷积部分
我们这里称Conv-Batch norm-ReLU为一个Conv Layer。一般这一部分是由大量的Conv Layer级联构成,其中掺杂如Pooling也Dropout这些层。一般大约5个Conv Layer之后会有一个Pooling层,然后Dropout层必须放在Pooling层之后,当然这两个层都是可选的。
全连接部分
全连接层的要求一般不高,而且现在的趋势是尽可能的去掉全连接层(ResNet和GoogLeNet里面都已经很难看到全连接层的身影了…)。全连接部分典型的结构是FC-Batch norm-ReLU-Dropout的组合,这种组合一般不会超过两个,然后再最后通过一层FC就算结果,再把结果传递给LOSS Function(这里根据需要可以有相应的选择,多数情况下是SOFTMAX)。
深度学习网络结构发展趋势
- 展度更小的过滤器(比如1*1, 3*3, 1*3, 3*1之类的)
- 更深的网络(AlexNet, ILSVRC 2012,8层->VGG, ILSVRC 2014, 19层->ResNet, ILSVRC 2015, 152层!)
- 摆脱Pooling和FC层,只保留Conv Layer
- 网络结构越来越复杂,比如ResNet和GoogLeNet引入的Inception结构,近期出现的RNN、LSTM等,以及他们的相互组合。
VGGNet分析
下面让我们一起来看看14年的深度学习的代表VGG,以及我们上面提到的结构是如果在VGG里面体现出来的。
首先,下面是来源自VGG论文里面的关于VGG结构的描述。
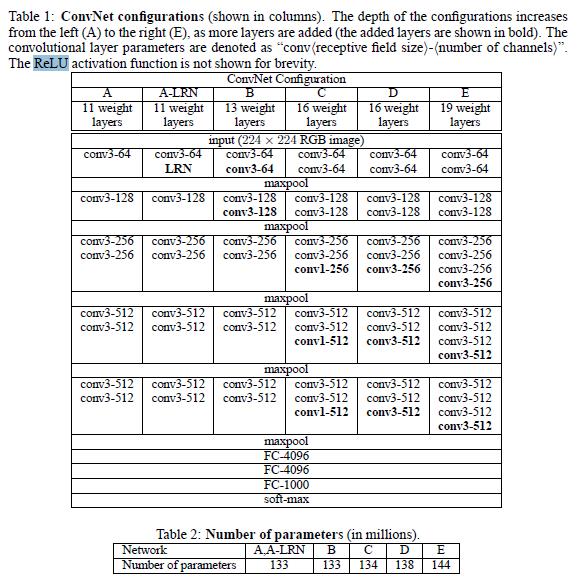
这里有两个表格,其中第一个表格是描述的是VGGNet的诞生过程。为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,这种方式在经典的神经网络中经常见得到,就是先训练一部分小网络,然后再确保这部分网络稳定之后,再在这基础上逐渐加深。表1从左到右体现的就是这个过程,并且当网络处于D阶段的时候,效果是最优的,因此D阶段的网络也就是最后的VGGNet啦!
VGG的组成
由表一D可以看出,VGG也是由卷积和全连接部分组成,在卷积部分,VGG采用的是展度为3的过滤器,卷积步长为1,2*2并且步长为2的MaxPooling。之后将卷积部分的结果传到全连接部分,全连接部分则是有3个全连接层以及一个SOFTMAX层构成。VGG的结果是很符合我们的经典深度神经网络的结构的。
VGG的训练细节
结构细节
下面给出的是VGG的结构细节
CONV(X)-(Y):由卷积层以及ReLU组合而成,也就是我们设的Conv Layer,这里并没有用到Batch norm(读者猜猜为什么?:)),X表示过滤器的展度,Y表示过滤器的数量,卷积过程步长为1。
MaxPooling:使用2*2的Pooling,步长为2。
FC-(X):由全连接层以及ReLU组合而成,X代表输出的特征维数,在前两个FC层中,
Dropout:Dropout只在前两个全连接层后面出现。第三个FC-(X)不用Dropout。
SOFTMAX:误差评价函数。
下图给出了VGG的空间以及参数数量计算

VGG训练方法以及参数设置细节
权重更新策略:Mini-batch gradient descent with Momentum;Batch Size为256,Momentum参数为 0.9。
正则化:L2 norm, Dropout。L2 penalty设置为
5∗10−4
,Dropout参数为0.5。
学习率:初始设为
10−2
,并在validation error到达瓶颈时将学习率除以10直到validation error不能再改进为止。(在训练中,学习率总共降过3次,迭代次数有370K,共 74次对全部数据的扫描)。
权重初始化:使用Pre-training的方式,每次初始化权重时使用正态分布,均值为0,方差为
10−2
;Bias设为0。
VGG的可能改进方式?
这是小编自己捣鼓的,仅供参考哦!如有雷同,纯属巧合…
利用我们在上半部分提出的经典结构,我们可能对VGG做如下改进。
- 在卷积层和全连接层后面增加Batch norm。
- 减少Pooling的使用,减少FC的使用,在靠近SOFTMAX的Pooling使用MeanPooling(参考GoogLeNet)。
- 权重初始化时使用Xaiver/2。
- 除了3*3的过滤器,考虑3*1与1*3的过滤器组合。
- …脑洞无极限,继续加油!
希望最后自己能够实现出这种改进的VGG,不过可能么那么快咯!~
后记
呼,内容量真不少啊,深度学习还在不断地发展,学习也不能停止。后面小编会介绍RNN,LSTM等这些新的网络结构,以及它们在传统深度学习网络中的应用。大家一起加油吧!
以上是关于CS231n笔记7-ConvNets Typical Architecture与VGGNet的主要内容,如果未能解决你的问题,请参考以下文章