《HDMapNet:An Online HD Map Construction and Evaluation Framework》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《HDMapNet:An Online HD Map Construction and Evaluation Framework》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:HDMapNet
1. 概述
介绍:在这篇文章中提出一种生成向量化高精地图(verctorized HD map)的方案,通过如IMU、GPS、Lidar等传感器数据融合可以生成全局的高精度定位信息,对于局部的信息是通过相机和Lidar实现的,其中最为关键便是行车过程中的车道信息。对于局部信息的获取方法是这篇文章的重点,其通过编码器处理环视图像和Lidar数据,之后将其映射到bev空间并引入时序得到融合信息表达,之后用于预测车道实例。
下图展示的便是生成高清地图的工作流程,通过将全局信息获取定位结果和局部信息融合得到精细化高精地图:
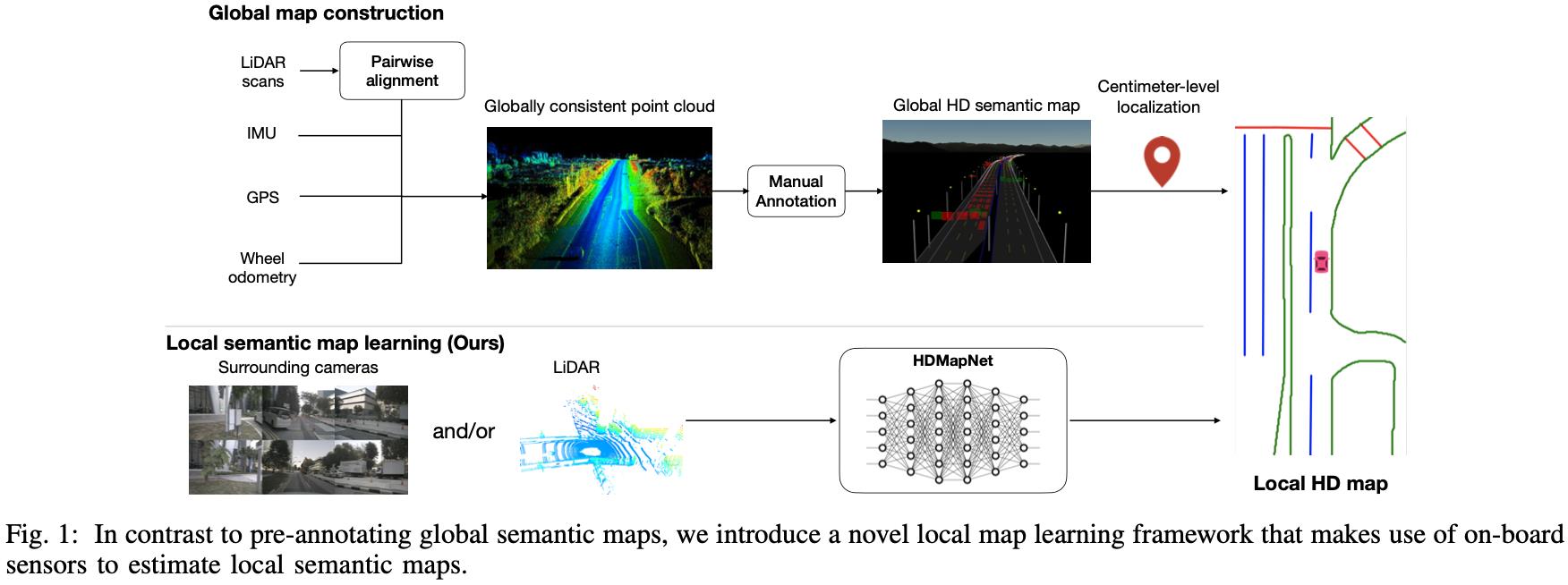
这里如何使用 全局信息获取部分定位并不是关注点重点,局部信息获取才是这篇文章着力想探讨的东西。
2. 方法设计
在局部信息获取流程中输入环视相机数据或者附加Lidar数据,各自经过对应编码器之后在bev下实现特征融合 ,之后用于预测车道实例。
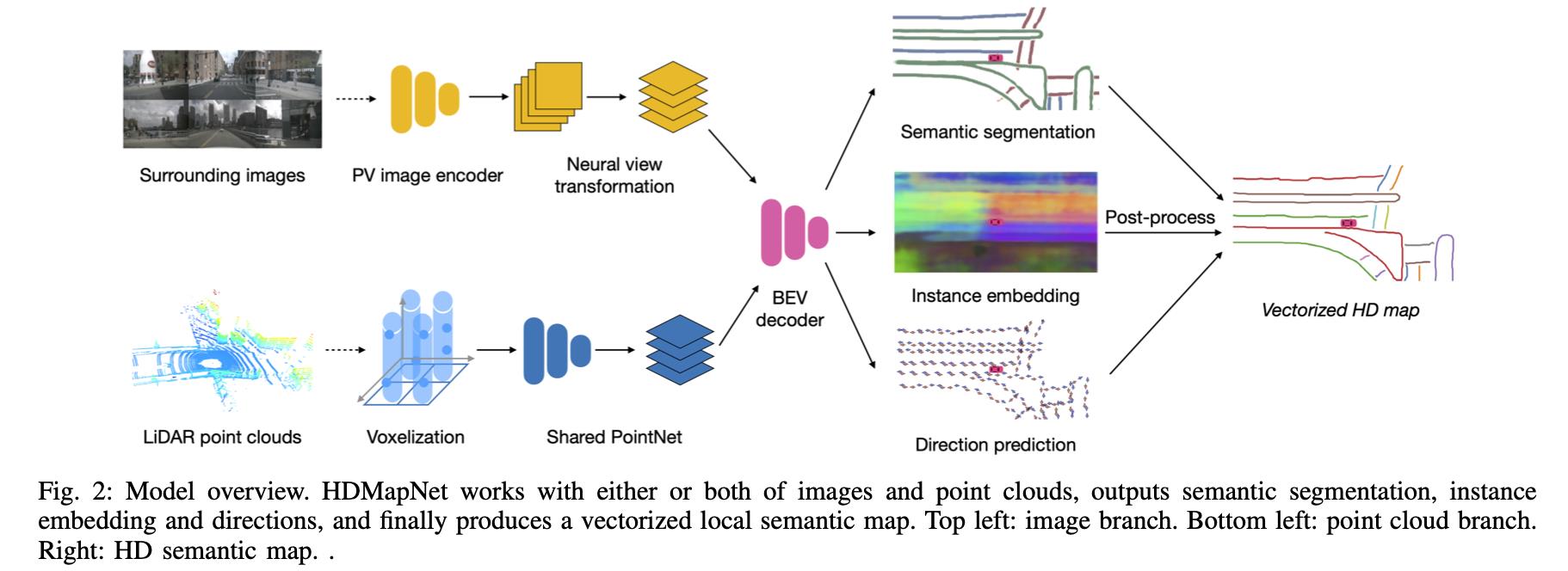
2.1 编码器
图像数据编码:
图像数据经过CNN网络编码之后得到语义特征图,但是由于单纯的2D图像是很难获取实际深度值的,直接使用相机内外参数(假设深度为1)会导致投影出现偏差,对此文章中采用的是一种多层全连接将图像坐标数据映射到相机坐标下:
F
I
i
c
[
h
]
[
w
]
=
ϕ
V
i
h
w
(
F
I
i
p
v
[
1
]
[
1
]
,
…
,
F
I
i
p
v
[
H
p
v
]
[
W
p
v
]
)
F_I_i^c[h][w]=\\phi_V_i^hw(F_I_i^pv[1][1],\\dots,F_I_i^pv[H_pv][W_pv])
FIic[h][w]=ϕVihw(FIipv[1][1],…,FIipv[Hpv][Wpv])
相机坐标下的数据再通过相机外参映射到世界坐标系下,相当于这一步处理过程隐式编码了深度信息。对于多个摄像头的场景通过取多个相机投射结果均值的方式获取最终的bev特征图,其从图像到bev完成信息投射的过程可以描述为下图的流程:
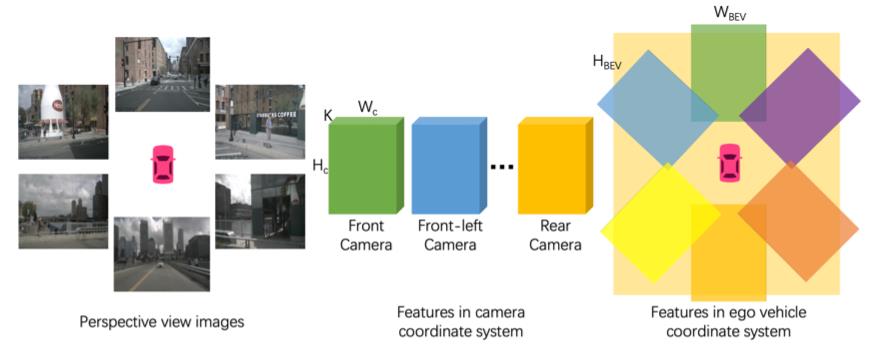
Lidar数据编码:
对于Lidar数据这里采用的是类似PointNet这样的点云数据处理网络,也就是下面的处理过程(
P
N
PN
PN代表点云处理网络):
f
j
p
i
l
l
a
r
=
P
N
(
f
p
∣
∀
p
∈
P
j
)
f_j^pillar=PN(\\f_p|\\forallp\\in P_j\\)
fjpillar=PN(fp∣∀p∈Pj)
之后这个特征经过几个卷积之后生成对应bev特征。
2.2 解码器
这里的解码其实就是车道信息的获取过程,其中设计到车道信息分割、车道实例信息获取、高精地图向量化元素获取,其中对于车道分割采用的是语义分割。
车道实例信息获取:
这里车道实例信息获取是采用LaneNet中信息聚类的形式得到的,也就是embedding空间中拉近统一类的距离,拉远不同类的距离。对于拉近同类的距离:
L
v
a
r
=
1
C
∑
c
=
1
C
1
N
c
∑
j
=
1
N
c
[
∣
∣
μ
c
−
f
j
i
n
s
t
a
n
c
e
∣
∣
−
δ
v
]
+
2
L_var=\\frac1C\\sum_c=1^C\\frac1N_c\\sum_j=1^N_c[||\\mu_c-f_j^instance||-\\delta_v]_+^2
Lvar=C1c=1∑CNc1j=1∑Nc[∣∣μc−fjinstance∣∣−δv]+2
再拉远不同车道线的特征表达:
L
d
i
s
t
=
1
C
(
C
−
1
)
∑
c
A
≠
c
B
∈
C
[
∣
∣
μ
c
A
−
μ
c
B
∣
∣
−
2
δ
d
]
+
2
L_dist=\\frac1C(C-1)\\sum_c_A\\neq c_B\\in C[||\\mu_c_A-\\mu_c_B||-2\\delta_d]_+^2
Ldist=C(C−1)1cA=cB∈C∑[∣∣μcA−μcB∣∣−2δd]+2
之后将两者损失组合起来:
L
=
α
L
v
a
r
+
β
L
d
i
s
t
L=\\alpha L_var+\\beta L_dist
L=αLvar+βLdist
方向信息获取:
这里的方向指的是以当前某个像素为圆心,将其所在的周围圆周划分为
N
d
N_d
Nd个angle class,前后像素点对应的方向上标签被设置为了1(其余对应为0),这样从当前位置就可通过朝向信息得到同一个实例下一个点的位置,也就是为:
C
n
e
x
t
=
C
n
o
w
+
Δ
s
t
e
p
⋅
D
C_next=C_now+\\Delta_step\\cdot D
Cnext=Cnow+Δstep⋅D
其中,
C
,
Δ
s
t
e
p
,
D
C,\\Delta_step,D
C,Δstep,D分别代表位置、步长、预测出来的朝向。这样的朝向信息在后面的后处理中使用贪心策略实现车道的向量化。
3. 实验结果
语义分割与实例结果对比:
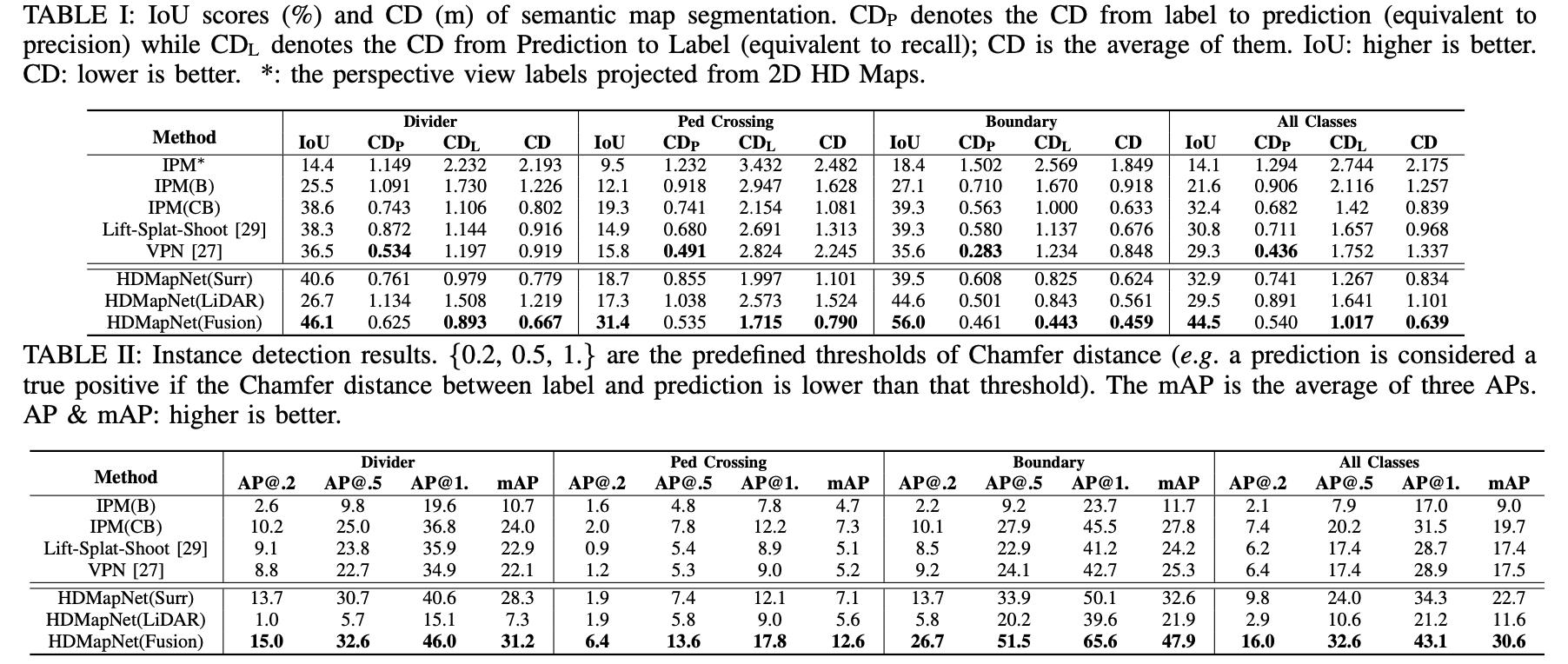
以上是关于《HDMapNet:An Online HD Map Construction and Evaluation Framework》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章