数据库查询语言——DQL语言
Posted Jqivin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库查询语言——DQL语言相关的知识,希望对你有一定的参考价值。
文章目录
一、基础查询
select 要查询的内容
【from 表名】
1、查询单个字段 select 字段名 from 表名;
2、查询多个字段 select 字段名,字段名 from 表名;
3、查询所有字段 select * from 表名
4、查询常量 select 常量值;
注意:字符型和日期型的常量值必须用单引号引起来,数值型不需要
5、查询函数 select 函数名(实参列表);
6、查询表达式 select 100/1234;
7、起别名
①as
②空格
8、去重: select distinct 字段名 from 表名;
9、+
作用:做加法运算
select 数值+数值; 直接运算
select 字符+数值;先试图将字符转换成数值,如果转换成功,则继续运算;否则转换成0,再做运算
select null+值;结果都为null
10、【补充】concat函数
功能:拼接字符
select concat(字符1,字符2,字符3,…);
11、【补充】ifnull函数
功能:判断某字段或表达式是否为null,如果为null 返回指定的值,否则返回原本的值
select ifnull(commission_pct,0) from employees;
12、【补充】空值查询 IS NULL
功能:NULL 与包含0、空字符串或者仅仅包含空格不同,是原来就没有填充过任何值。
select * from jobs
where min_salary is null;
特点:
①通过select查询完的结果 ,是一个虚拟的表格,不是真实存在
② 要查询的东西 可以是常量值、可以是表达式、可以是字段、可以是函数
二、条件查询
根据条件过滤原始表的数据,查询到想要的数据
语法:
select
要查询的字段|表达式|常量值|函数
from
表
where
条件 ;
分类:
一、条件表达式 示例:salary>10000 条件运算符:
<= >= = != <>二、逻辑表达式 示例:salary>10000 && salary<20000
逻辑运算符:
and(&&):两个条件如果同时成立,结果为true,否则为false
or(||):两个条件只要有一个成立,结果为true,否则为false
not(!):如果条件成立,则not后为false,否则为truesql SELECT * FROM jobs WHERE min_salary > 10000 && min_salary < 20000;
三、模糊查询
示例:last_name like ‘a%’
通配符:
- % :任意多个字符,包括0个字符
- _ :只代表一个字符
四、限制查询
select语句返回所有匹配的行,为了返回第一行或者前几行,可以使用LIMIT字句。
limit n; # 前n行
limit n,n #从第n行开始之后(不包括第n行)的n行,第一个数为开始的位置,第二个数为要检索的行数
三、排序查询
语法:
select
要查询的东西
from
表
where
条件
order by 排序的字段|表达式|函数|别名 【asc|desc】
实例:
mysql> SELECT * FROM jobs
-> WHERE min_salary > 3000 && min_salary < 20000
-> ORDER BY job_id DESC;
+------------+---------------------------------+------------+------------+
| job_id | job_title | min_salary | max_salary |
+------------+---------------------------------+------------+------------+
| ST_MAN | Stock Manager | 5500 | 8500 |
| SA_REP | Sales Representative | 6000 | 12000 |
| SA_MAN | Sales Manager | 10000 | 20000 |
| PU_MAN | Purchasing Manager | 8000 | 15000 |
| PR_REP | Public Relations Representative | 4500 | 10500 |
| MK_REP | Marketing Representative | 4000 | 9000 |
| MK_MAN | Marketing Manager | 9000 | 15000 |
| IT_PROG | Programmer | 4000 | 10000 |
| HR_REP | Human Resources Representative | 4000 | 9000 |
| FI_MGR | Finance Manager | 8200 | 16000 |
| FI_ACCOUNT | Accountant | 4200 | 9000 |
| AD_VP | Administration Vice President | 15000 | 30000 |
| AC_MGR | Accounting Manager | 8200 | 16000 |
| AC_ACCOUNT | Public Accountant | 4200 | 9000 |
+------------+---------------------------------+------------+------------+
14 rows in set (0.00 sec)
常见函数
1.字符函数
concat:连接
mysql> SELECT CONCAT ('A','b');
+------------------+
| CONCAT ('A','b') |
+------------------+
| Ab |
+------------------+
1 row in set (0.00 sec)
substr:截取子串
mysql> SELECT SUBSTR('abcde',3);
+-------------------+
| SUBSTR('abcde',3) |
+-------------------+
| cde |
+-------------------+
1 row in set (0.00 sec)
upper:变大写
lower:变小写
length:获取字节长度
2.数学函数
ceil:向上取整
round:四舍五入
mod:取模
floor:向下取整
rand:获取随机数,返回0-1之间的小数
3.日期函数
now:返回当前日期+时间
year:返回年
month:返回月
day:返回日
date_format:将日期转换成字符
curdate:返回当前日期
str_to_date:将字符转换成日期
curtime:返回当前时间
hour:小时
minute:分钟
second:秒
datediff:返回两个日期相差的天数
monthname:以英文形式返回月
4. 分组函数
max 最大值
min 最小值
sum 和
avg 平均值
count 计算个数
where子句中不能出现分组函数
特点:
①语法
select max(字段) from 表名;
②支持的类型
sum和avg一般用于处理数值型
max、min、count可以处理任何数据类型
③以上分组函数都忽略null
④都可以搭配distinct使用,实现去重的统计
select sum(distinct 字段) from 表;
⑤count函数
count(字段):统计该字段非空值的个数
count(*):统计结果集的行数
四、分组查询
核心:group by 子句,having子句
group by:创建分组,比如说我想按department_id分组,那么我使用group by department_id 语句就可以实现。它是按department_id排序并分组数据,这导致对每个department_id合起来只计算一次,而不是对每个department_id都计算一次。
having:主要用来实现过滤分组,主要对分组后的数据进行处理,进而来弥补where子句的不足。它其实类似where子句。
注意:
group by子句必须出现在where子句之后,order by子句之前。
1. 语法:
select 分组函数,分组后的字段
from 表
【where 筛选条件】
group by 分组的字段
【having 分组后的筛选】
【order by 排序列表】
2. 特点
使用关键字 筛选的表 位置 分组前筛选 where 原始表 group by的前面 分组后筛选 having 分组后的结果 group by的后面
原始表中有的用where子句,原始表中没有的,使用筛选后的结果的用having。
示例:查询哪个部门的员工数大于2;
mysql> SELECT COUNT(*),department_id
-> FROM employees
-> GROUP BY department_id
-> HAVING COUNT(*) > 2;
+----------+---------------+
| COUNT(*) | department_id |
+----------+---------------+
| 6 | 30 |
| 45 | 50 |
| 5 | 60 |
| 34 | 80 |
| 3 | 90 |
| 6 | 100 |
+----------+---------------+
6 rows in set (0.00 sec)
五、连接查询
笛卡尔积现象:两张表连接查询如果没有任何限制,就会产生m*n条记录。(两张表分别有m和n行数据)。这就是笛卡尔积现象。
怎么避免笛卡尔积现象:连接时加条件,满足这个条件的才能被筛选出来。最终产生的条数减少了,但是这个过程,也就是匹配的次数并没有减少。
- 含义
当查询中涉及到了多个表的字段,需要使用多表连接
select 字段1,字段2
from 表1,表2,…; - 分类:内连接,外连接
内连接
- 等值连接:查询条件是一个等量关系。
sql92语法:
select
employee_id,department_name
from
employees as e,departments as d
where
e.department_id = d.department_id;
sql99语法:
#优点:表连接的条件是独立的,连接之后,如果还需要进一步筛选,再往后继续添加where子句
select
...
from
a
(inner) join #inner可以省略
b
on
a和b的连接条件
where
筛选条件
SELECT employee_id,department_name
FROM
employees e
INNER JOIN
departments d
ON
e.department_id = d.department_id;
2.非等值连接
查询条件不是一个等量关系;
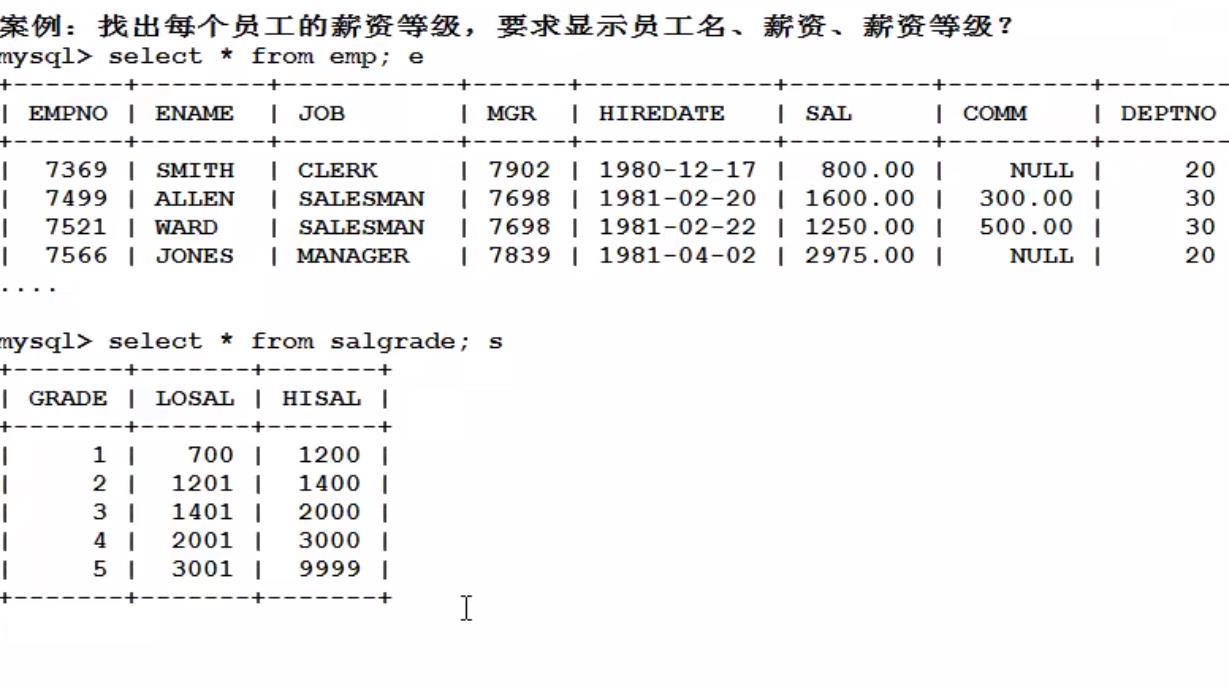
select emp.ename,emp.sal,salgrade.grade
from emp e
join salgrade s
on e.sal between s.losal and s.hisal;
3.自连接:连接条件在同一个表中 ,自己连自己
方法:一张表看成两张表
案例:查询员工名字和对应的领导名
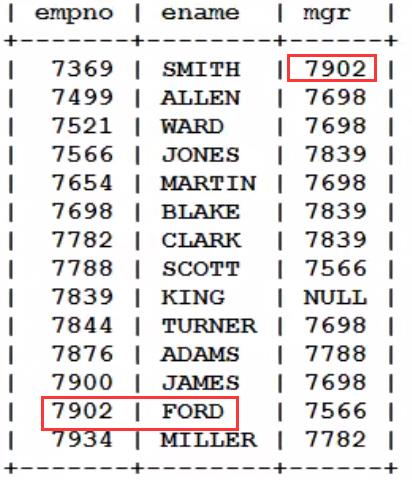
select a.ename as '员工名',b.ename as '领导名'
from emp a
join emp b
on a.mgr = b.empno;
外连接
内连接特点:完成能够匹配上这个条件的数据查询出来。
外连接分为左外连接和右外连接
在外连接中,两张表中产生了主次关系,主表中即使没有匹配关系,也要把全部的行查询出来,不是主表的表只查询对应的条件,没有值的用NULL表示。
right代表主表是右表,也就是join右边的表是主表,把这张表的数据全部查询出来(行)
left代表主表是左表。
select
...
from
a
left/right (outer) join #outer可以省略
b
on
a和b的连接条件
where
筛选条件
多表连接
select ...
from a
join b
on a和b的连接条件
left join c
on a和c的连接条件
join d
on a和d的连接条件
六、子查询
查询一般值得是select语句。SQL还支持子查询,即在select语句中嵌套select语句。子查询总是从内向外进行查询。
子查询可以出现在select,from,where子句中。
select
..(select).
from
..(select).
where
..(select).
where子查询很简单
from子查询:将子查询的查询结果当成一张临时表。
示例:查询每个岗位平均工资对应的薪资等级。

select 子查询:子查询一次只能返回一条结果,必须返回的是一条记录,多于一条就会报错。
七、联合查询(union)
将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
查询语句3
...
特点
1、要求多条查询语句的查询列数必须一致
2、要求多条查询语句的查询的各列类型、顺序最好一致(语法不报错但是结果不对)
3、union 默认是去重的,union all包含重复项。(去重的意思就是如果两个表中有相同的两行数据项,会自动去掉一行)
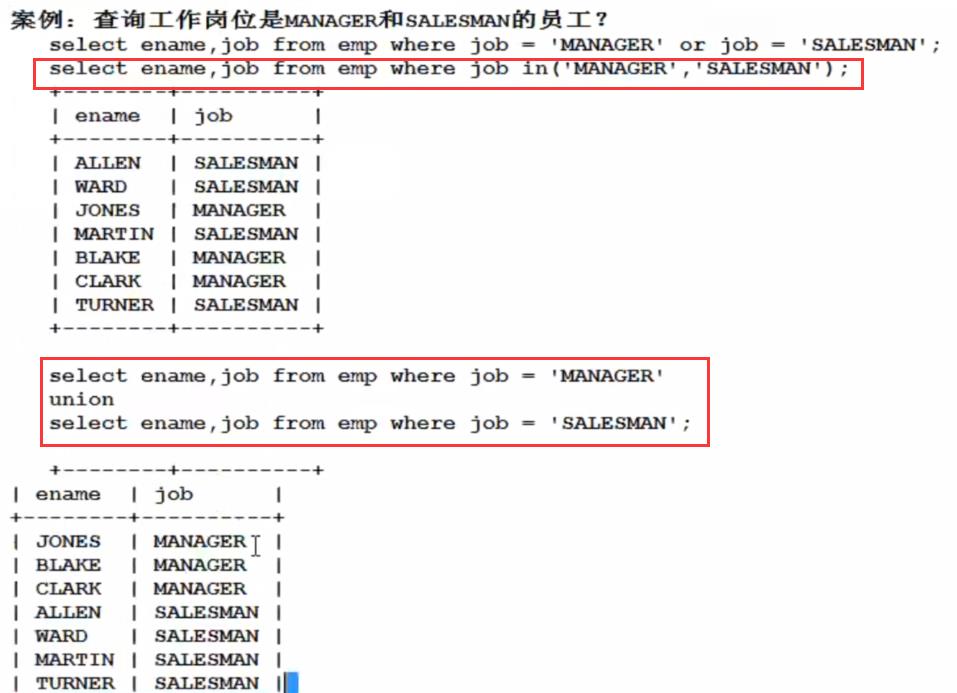
union效率要高一点,对于表连接来说,每连接一次新表,则匹配的次数满足笛卡尔积,成别的翻,但是union可以减少匹配的次数,在减少匹配次数的情况下,还可以完成两个结果集的拼接。
以上是关于数据库查询语言——DQL语言的主要内容,如果未能解决你的问题,请参考以下文章