Apache Kafka 简介与使用
Posted 有且仅有
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Kafka 简介与使用相关的知识,希望对你有一定的参考价值。
Kafka 可以简单理解为分布式MQ,用Scala编写,运行在JVM上。
分布式程序,除了其自身的基本概念外,最重要的就是要知道它是如何实现高并发和高可用的:
- Kafka 用 Partitions 实现了高并发;
- Kafka 用 Partitions 复制 + Zookeeper 实现了高可用;
注:以下内容中英文混合存在,只是为了描述方便。更全面和准确的文档,可以查看Kafka官网。
一、Kafka - 简介
Apache Kafka is a distributed streaming platform. 卡夫卡是一个分布式流平台。
它有三个关键的能力:
消息队列 - 可以使你能pub/sub streams of records. 从这方面看,它很像一个消息队列。
容错存储 - 使你可以存储streams of records in a fault-tolerant way.
流处理 - 可以使你能够处理 stream of records 在它们出现时。
有三个基本概念:
作为集群运行 - Kafka is run as a cluster on one or more servers.
主题 - The Kafak cluster stores stream of records in categories called topics.
Record = key + value + timestamp- Each record consists of a key, a value and a timestamp.
有四个核心API:
发布者 - The Producer API allows an application to publish a stream of records to one or more Kafka topics.
消费者 - The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
流处理 - The Streams API allows an application to act as stream processor, 使得你能从topics消费输入流和产生输出流到topics上。
连接器 - The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems.
Kafka 构建了一个语言无关的基于TCP protocol 的通信机制,用来高性能的实现clients 和 servers 之间通信;
1、Topics and Logs - 主题和日志
Topic - 主题
一个 topic 是一个类型名,指示哪些records被发布。
对于每个 topic, Kafka 集群会将其保存为一个被分区的log ,就像下图这样:

(Topic = partitioned log 0 + partitioned log 1 + partitioned log 2)每个分区都是一个ordered, immutable sequence of records,它们会被不断的追加到 a structured commit log.
每个分区中的记录都被分配一个顺序的id,称为唯一标示此分区内每个记录的 offset.
Kafka集群保存所有被发布的 records 无论它们是否已被消费,可以用一个配置来控制。
例如:log.retention.hours=148,代表在记录发布的6天后才会将其删除。
Log - 日志
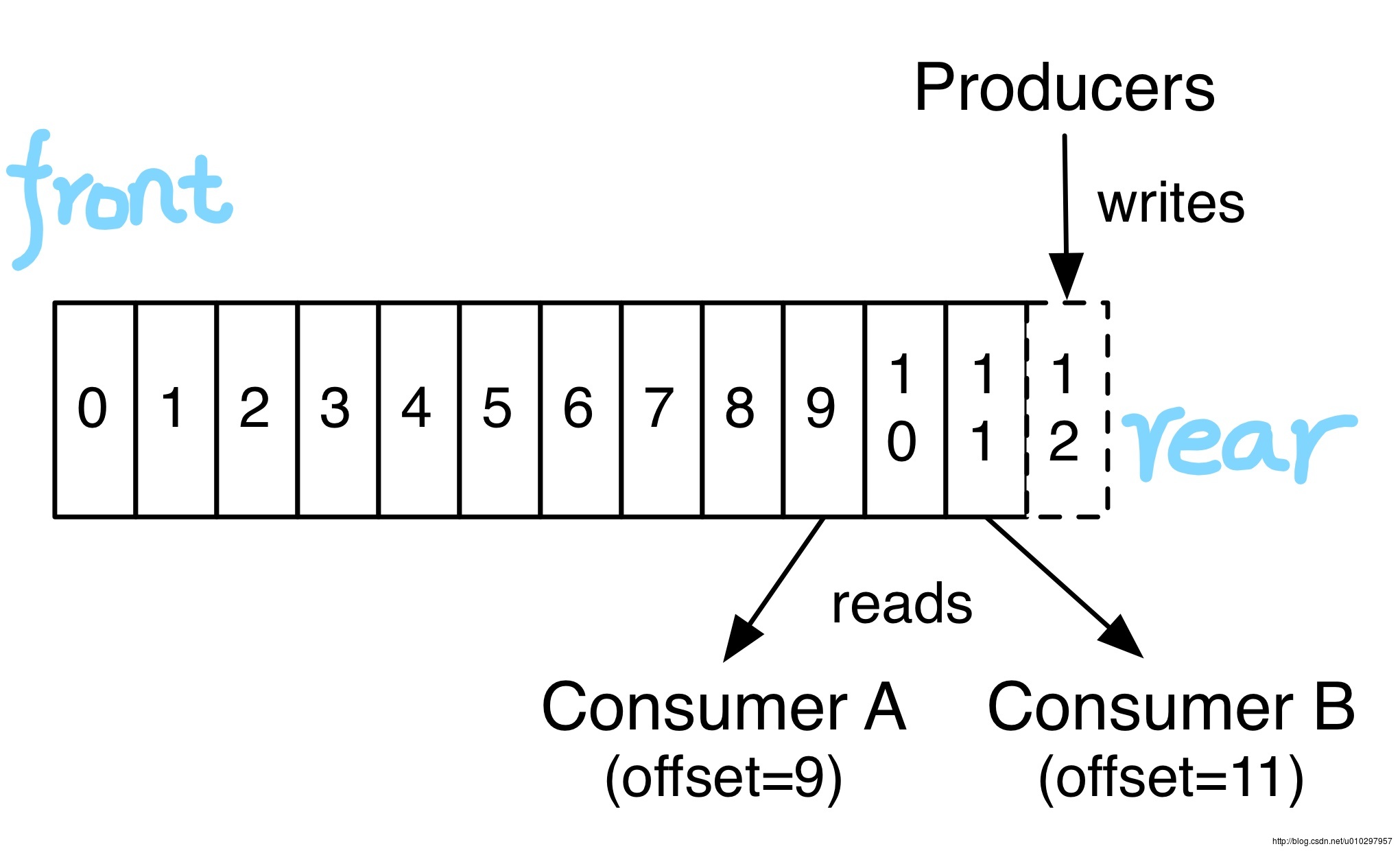
事实上,每个消费者唯一需要持有的元数据基本上就是log的the offset or position,消费者控制自己的offset:可以线性的读、也可以从任何位置开始读,因为自己控制position。
以上这些Topic和Log的特性决定了消费者消费这件事是非常廉价容易的,他们可以随意来随意消费而互不影响。
Partitions - 分区
Log的Partitions即是水平切分,它服务于以下两个目的:
(扩容)首先,可以使Log的扩展能超过安装在一台单机上的大小限制。
每个Partition必须安装在托管它的服务器上,但是Topic可以有很多Partition,所以Topic理论上可以处理无限量的数据;
分区会被均衡的分布于集群中的每台机器上。
(高并发)第二,Partition们作为并行的单位,更多的是在这点上;
2、Distribution - 分布式
Log的分区们会被分布在Kafka服务器集群中,每个服务器处理自己分到分区。每个分区会被复制为创建时指定的复制数量,参数--replication-factor N 。
每个partition有一个被称为”Leader”的节点,0或多个”Followers”:
Leader处理所有读和写请求,Followers被动的从leader复制。
如果Leader挂掉了,那么集群会在Follower中重新选出一个Leader;
3、举例
一个有3台服务器的Kafka集群。(安装过程在后面,这是假设安装过了)
使用如下命令创建一个Topic:
# Topic名 TestTopic001,分区数2,复制因子1(即不复制) [root@iZ28gss3aiwZ bin]# ./kafka-topics.sh --create --topic TestTopic001 --partitions 2 --replication-factor 1 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181然后查看:
[root@iZ28gss3aiwZ bin]# ./kafka-topics.sh --describe --topic TestTopic001 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181输出如下:
Topic:TestTopic001 PartitionCount:2 ReplicationFactor:1 Configs: Topic: TestTopic001 Partition: 0 Leader: 2 Replicas: 2 Isr: 2 Topic: TestTopic001 Partition: 1 Leader: 3 Replicas: 3 Isr: 3此时被生成的Topic目录
在集群中的3台服务器(
broker)中,Kafka将两个分区分别放在了broker-2和broker-3上。此时去到两台机器的事务日志目录下,可以看到生成了相应的主题分区的目录:broker-1:无目录生成broker-2:- <log_dir>/TestTopic001-0
- 00000000000000000000.index
- 00000000000000000000.log
- 00000000000000000000.timeindex
- …
- <log_dir>/TestTopic001-0
broker-3:- <log_dir>/TestTopic001-1
- 00000000000000000000.index
- 00000000000000000000.log
- 00000000000000000000.timeindex
- …
每个Topic的每个分区会对应一个单独的目录,其下有配套的Log文件 + index文件 + timeindex文件
- <log_dir>/TestTopic001-1
参数
分区
--partitions是任意正整数,会被分散在所有broker上,越多的分区一般意味着越高的并发。复制因子
--replication-factor是不能大于broker数量的,如果等于broker数量,则会在每台broker上都复制一份。正如文首所说:
Partitions - 分区(即水平切分),实现了高并发;
Partitions 的复制(复制因子>1)+ Zookeeper 实现了高可用;
3、Producers - 生产者
生产者发布数据到Topic中。
生产者还负责给record选择分区:
- 可以简单的使用轮询(round-robin)方式简单的负载均衡。
- 或者可以根据某些语义分区函数(例如基于record中的某个key)。
4、Consumers- 消费者
一、概述
消费者通过一个group name 来标记自己,每个被发布到topic上的record只会被消费者组中的一个实例所消费。
Records会负载均衡的被发送到同组中的所有消费者实例上。
如果所有消费者实例都有不同的group name ,那这就是广播了。
二、分析一个实例如下
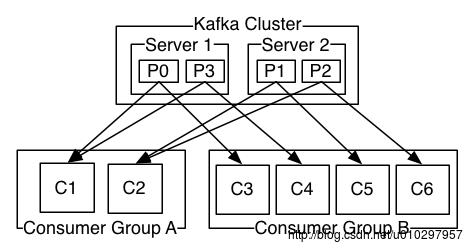
- 一个两台服务器组成的Kafka集群,每个Topic会被分为4个Partition(P0-P3);
- 假设有2个客户端应用在消费:
- 第1个应用的消费者组叫Group A,它启动了2个消费者实例。
- 第2个应用的消费者组叫Group B,它启动了4个消费者实例。
三、消费者与分区
Kafka实现消费的方式是通过将log中的分区划分到消费者实例上,以便每个实例都是任何时间点的“fair share”分区的唯一消费者。维护成员资格的过程由Kafka协议动态处理。
- 一个分区只能被一个消费者组中的唯一的一个实例所订阅;
- 消费者组中的实例数量不能超过Topic分区数量;
- 如果新的消费者实例加入,它们将从组中其他成员接管一些分区;
- 如果一个实例消失,其分区将被分发到剩余的实例。
四、顺序
Kafka仅提供分区内的顺序,而不提供跨分区的即Topic的总顺序。如果需要保证Topic的总顺序,则可以使用仅具有一个分区的Topic,不过这意味着每个消费者group只能有一个消费者实例。
二、开源消息系统比较
| - | ActiveMQ | RabbitMQ | Kafka |
|---|---|---|---|
| 所属社区/公司 | Apache | Pivotal Software | Apache/LinkedIn |
| 开发语言 | Java | Erlang | Scala |
| 可支持协议 | OpenWire、STOMP、REST、XMPP、AMQP | AMQP | 仿 AMQP |
| 事务 | 支持 | 不支持 | 不支持 |
| 集群 | 支持 | 支持 | 支持 |
| 负载均衡 | 支持 | 支持 | 支持 |
| 动态扩容 | 不支持 | 不支持 | 支持(通过zookeeper) |
| 高性能、高吞吐 | 否 | 否 | 是 |
| 其它 | 是JMS的实现 |
三、安装与使用
1. 安装
Kafka依赖Zookeeper,所以要先安装Zookeeper(Zookeeper简介、安装与使用),安装后启动。
下载官网版本最新版本,解压到你的目录:
tar -zxf kafka_2.12-0.10.2.1.tgz -C <YOUR_DIR> // 为了方便,将目录重命名为kafka mv kafka_2.12-0.10.2.1/ kafka修改服务器配置文件:
由上文描述我们知道,Kafka天生是集群的即使只有一个broker,所以我们配置多个broker的情况,修改每个机器上的配置文件
<Kafka_home>/config/server.properties:############################# Server ############################# # broker id 要全集群唯一,你的每个机器上要配置不一样的(既然注册在zookeeper上也可以叫zookeeper上唯一),我是直接设置的1、2、3 broker.id = 1 # Switch to enable topic deletion or not, default value is false delete.topic.enable=true # Kafka的Socket Server监听的地址和端口,这里最好自己显示设定一下,否则值是Java的方法java.net.InetAddress.getCanonicalHostName()的返回值。 ## 监听本机所有网络接口(network interfaces) listeners=PLAINTEXT://0.0.0.0:9092 ## 被发布到Zookeeper上,公布给Client让Client使用 advertised.listeners=PLAINTEXT://kafka1.host:9092 ############################# Log ############################# # log文件存储目录 log.dir = <dirctory what you want> # 默认Topic分区数量 num.partitions=3 # log文件在被删除前的保存时间 log.retention.hours=168 ############################# Zookeeper ############################# # 你的zookeeper集群的地址 zookeeper.connect=zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181log4j配置:
在
<kafka_home>/config/log4j.properties中,有各种类型日志的输出配置,需要怎样改变可以自行修改,这部分属于log4j部分,就不再详述;我这里是修改为按day分文件、修改日志路径;
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender ... log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender # '.'yyyy-MM-dd-HH修改为'.'yyyy-MM-dd log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd # 可以看到修改日志路径,只需要定义kafka.logs.dir就行 log4j.appender.kafkaAppender.File=$kafka.logs.dir/server.log ... ...修改
<kafka_home>/bin/kafka-run-class.sh里LOG_DIR的赋值即可# Log directory to use if [ "x$LOG_DIR" = "x" ]; then # "$base_dir/logs"修改为"/data/logs/kafka" LOG_DIR="/data/logs/kafka" fi启动,启动脚本是在
<kafka_home>/bin/kafka-server-start.sh,如果机器内存不够可以先修改下脚本中Kafka使用的JVM堆内存设置:if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx300M -Xms300M" fi然后启动:
# 指定后台启动;指定配置文件地址 [root@host kafka]# bin/kafka-server-start.sh -daemon config/server.properties也可以先不加
-daemon,用以看是否有正常日志输出,正常的话直接结束进程再使用-daemon启动。
2. 网络
有可能你的Linux服务器或Kafka配置不对,会导致各种网络的问题,在这里我专门列出来。(使用netstat -anp | grep 9092来查看端口的监听和连接情况。)
首先是Kafka自身的配置,在
<Kafka_home>/config/server.properties中:listeners
listeners=PLAINTEXT://0.0.0.0:90920.0.0.0代表监听本机所有网络接口(network interfaces),最好这样做!尤其当你使用的是阿里云等云服务提供商的机器时。因为云服务器一般有内网IP和外网IP(即内网网络接口和外网网络接口),而如果你仅仅监听内网IP的话,由于外部网络访问此服务器只能用外网IP,则访问肯定会被拒绝。advertised.listeners
advertised.listeners=PLAINTEXT://<your_hostname>:9092<your_hostname>被发布到Zookeeper上,被直接公布给Client让Client使用:可以直接赋值为服务器的外网IP,这样无论broker或者Client都连接你的外网IP;
也可以自己配置一个
hostname,比如叫kafka1.host;- 在服务器的
/etc/hosts中配置:内网IP kafka1.host; - 在内网其它服务器
/etc/hosts中配置:内网IP kafka1.host; - 在外部所有客户端配置:
外网IP kafka1.host;
- 在服务器的
其次是系统防火墙
在CentOS7中,可以关闭、也可以将
TCP 9092端口开放(推荐):systemctl status firewalld // 查看状态 systemctl stop firewalld // 停用 systemctl start firewalld // 启动 firewall-cmd --zone=public --list-ports // 查看所有允许的端口 firewall-cmd --zone=public --add-port=9092/tcp --permanent // 添加TCP的9092端口 firewall-cmd --reload // 重载
3. 使用
可以看官方的快速开始:http://kafka.apache.org/quickstart,有简单的创建Topic、生产消息、消费消息的过程;(直接执行脚本不加参数可以看到help,如果使用--help有些脚本是不支持的)
Topic
创建Topic:
bin/kafka-topics.sh --create --topic TestTopic003 --partitions 3 --replication-factor 3 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181查看所有Topic:
bin/kafka-topics.sh --list --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181分析具体Topic:
bin/kafka-topics.sh --describe --topic TestTopic003 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181删除某个Topic(在
delete.topic.enable=true情况下才是物理删除):bin/kafka-topics.sh --delete --topic TestTopic003 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181删除某个Topic - 手动方式:删除所有kafka节点下
$log.dir目录下TestTopic003-*的所有目录;登录zookeeper 客户端后操作删除主题的元数据,包括/brokers/topics/TestTopic003和/config/topics/TestTopic003。生产者-发送消息
# 发送时重要的是指定要往哪些broker上发(broker可以同属一个集群也可以不是,这样你就可以发到多个集群上) bin/kafka-console-producer.sh --topic TestTopic003 --broker-list kafka1.host:9092,kafka2.host:9092,kafka3.host:9092 This is a message This is another message消费者-消费
官网中说从
0.9.0.0开始引入了新的配置方式,我看起来最重要的就是取消了zookeeper,所以官网上的消费实例这样写:bin/kafka-console-consumer.sh --topic TestTopic003 --from-beginning --bootstrap-server kafka1.host:9092,kafka2.host:9092,kafka3.host:9092 This is a message This is another message如果是旧版本的Kakfa则使用如下配置去订阅消费:
bin/kafka-console-consumer.sh --topic TestTopic003 --from-beginning --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181 // 会输出如下提示 Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
4. zookeeper中 – 仅用于了解
Kafka会在Zookeeper中创建和使用的目录如下:
- admin
- cluster
- config
- consumers
- controller
- controller_epoch
- isr_change_notification
/brokers
ids
your broker id 1your broker id 2- …
your broker id N
topics
topic your created 1topic your created 2- …
topic your created N__consumer_offsets
partitions
<num><num>
state
seqid
三、Java实例
引入客户端jar包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>生产者 - Producer
其实直接使用
org.apache.kafka.clients.producer.KafkaProducer的类注释部分即可:public static void main(String[] args) Properties props = new Properties(); props.put("bootstrap.servers", "你的服务器地址们"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 1; i < 5; i++) producer.send(new ProducerRecord<String, String>("TestTopic001", Integer.toString(i))); producer.close();消费者 - Consumer
也是直接使用
org.apache.kafka.clients.consumer.KafkaConsumer的类注释部分即可:public static void main(String[] args) Properties props = new Properties(); props.put("bootstrap.servers", "你的服务器地址们"); props.put("group.id", "自己起个唯一的组名"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("TestTopic001")); while (true) ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
更详细的Java使用实例,需要大家在实际情况下再自己拓展了,这里我只说到这了。
转载注明出处:http://blog.csdn.net/u010297957/article/details/72758765
以上是关于Apache Kafka 简介与使用的主要内容,如果未能解决你的问题,请参考以下文章