redis 集群 实操 (史上最全5w字长文)
Posted 架构师-尼恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis 集群 实操 (史上最全5w字长文)相关的知识,希望对你有一定的参考价值。
文章很长,建议收藏起来慢慢读! 总目录 博客园版 为大家准备了更多的好文章!!!!
推荐:尼恩Java面试宝典(持续更新 + 史上最全 + 面试必备)具体详情,请点击此链接
尼恩Java面试宝典,34个最新pdf,含2000多页,不断更新、持续迭代 具体详情,请点击此链接

说明
redis cluster是 生存环境常用的组件,是面试必备的组件
本文从原理到实操,都给大家做了一个介绍,后面会 持续完善
Redis集群高可用常见的三种方式:
Redis高可用常见的有两种方式:
- Replication-Sentinel模式
- Redis-Cluster模式
- 中心化代理模式(proxy模式)
Replication-Sentinel模式
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。
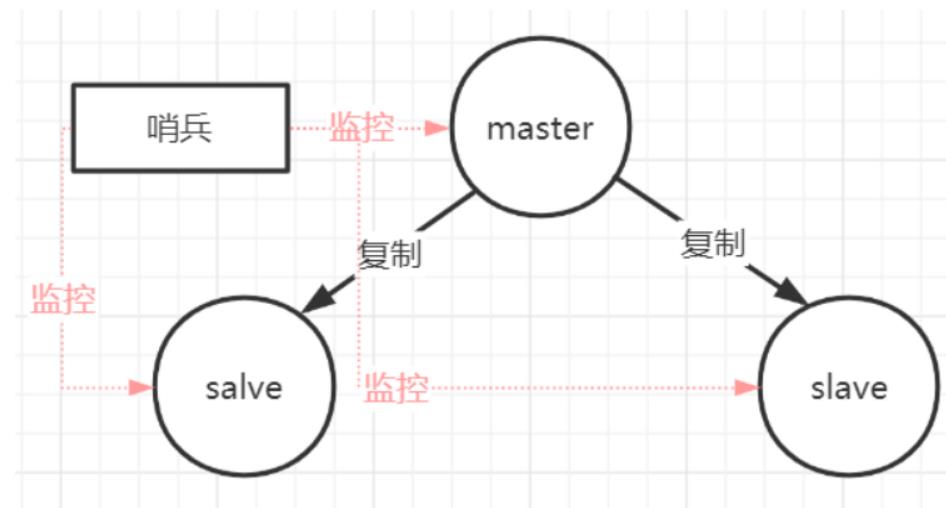
Redis sentinel 其中三个特性:
- 监控(Monitoring):
Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification):
当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
哨兵本身也有单点故障的问题,可以使用多个哨兵进行监控,哨兵不仅会监控redis集群,哨兵之间也会相互监控。
每一个哨兵都是一个独立的进程,作为进程,它会独立运行。

特点:
-
1、保证高可用
-
2、监控各个节点
-
3、自动故障迁移
缺点:
主从模式,切换需要时间丢数据
没有解决 master 写的压力
Redis-Cluster模式
redis在3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的数据。
cluster模式为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。
相对于 Codis 的不同,它是去中心化的,如图所示,该集群有三个 Redis 节点组成, 每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相 互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议相互交互集群信息。
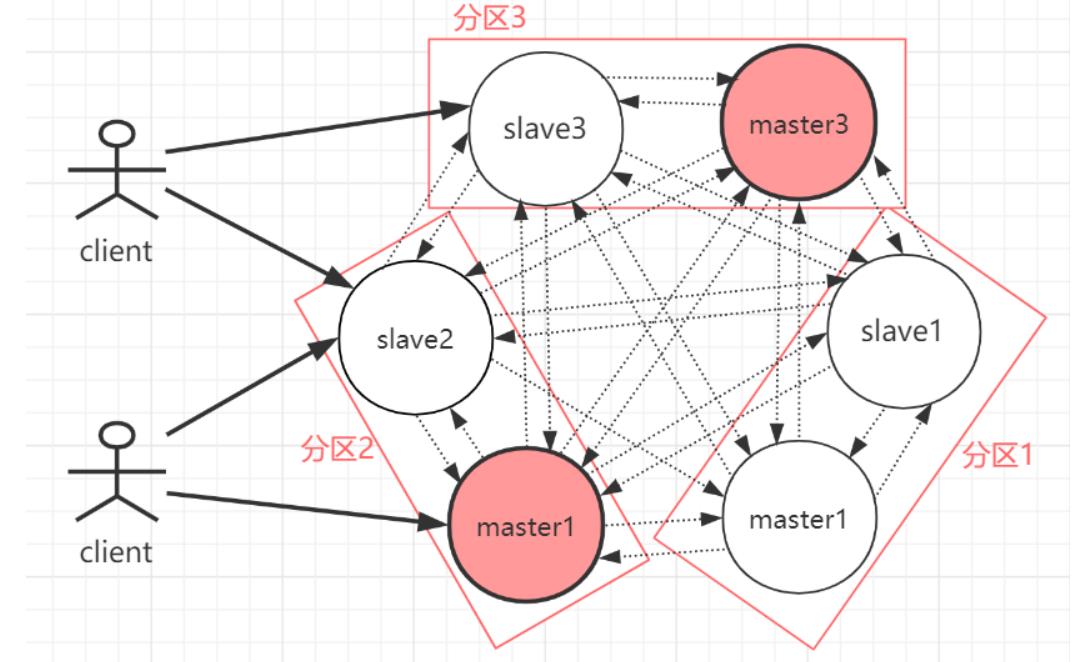
如上图,官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式。
Redis Cluster 将所有数据划分为 16384 的 slots,它比 Codis 的 1024 个槽划分得更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像 Codis,它不 需要另外的分布式存储来存储节点槽位信息。
Redis Cluster是一种服务器Sharding技术(分片和路由都是在服务端实现),采用多主多从,每一个分区都是由一个Redis主机和多个从机组成,片区和片区之间是相互平行的。
Redis Cluster集群采用了P2P的模式,完全去中心化。
3 主 3 从六个节点的Redis集群(Redis-Cluster)
Redis 集群是一个提供在多个Redis节点间共享数据的程序集。
下图以三个master节点和三个slave节点作为示例。
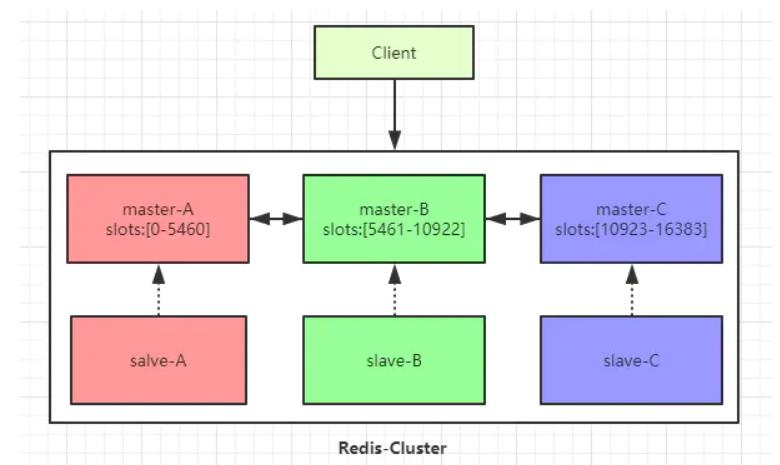
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。
集群的每个节点负责一部分hash槽,如图中slots所示。
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有1-n个从节点。
例如master-A节点不可用了,集群便会选举slave-A节点作为新的主节点继续服务。
中心化代理模式(proxy模式)
这种方案,将分片工作交给专门的代理程序来做。代
理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的 Redis 实例并返回给业务程序。
其基本原理是:通过中间件的形式,Redis客户端把请求发送到代理 proxy,代理 proxy 根据路由规则发送到正确的Redis实例,最后 代理 proxy 把结果汇集返回给客户端。
redis代理分片用得最多的就是Twemproxy,由Twitter开源的Redis代理,其基本原理是:通过中间件的形式,Redis客户端把请求发送到Twemproxy,Twemproxy根据路由规则发送到正确的Redis实例,最后Twemproxy把结果汇集返回给客户端。
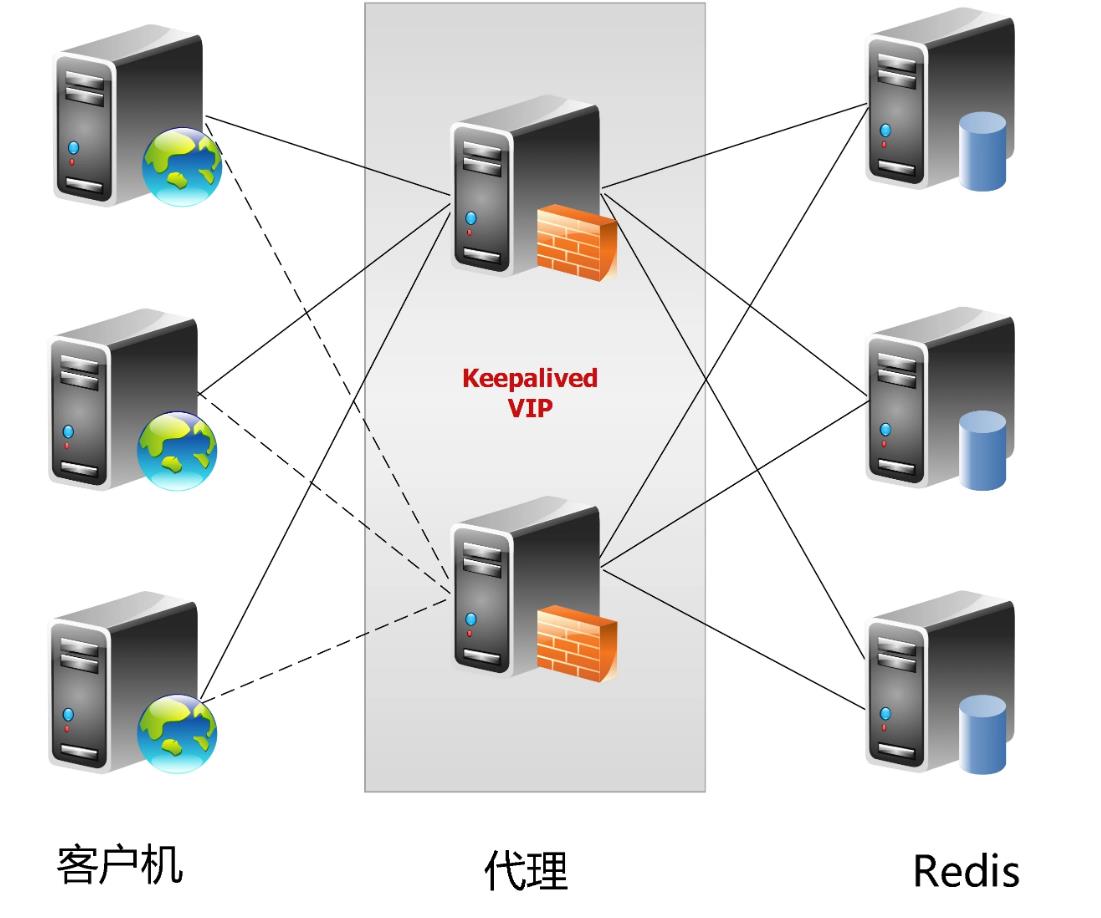
这种机制下,一般会选用第三方代理程序(而不是自己研发),因为后端有多个 Redis 实例,所以这类程序又称为分布式中间件。
这样的好处是,业务程序不用关心后端 Redis 实例,运维起来也方便。虽然会因此带来些性能损耗,但对于 Redis 这种内存读写型应用,相对而言是能容忍的。
Twemproxy 代理分片
Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
Twemproxy是由Twitter开源的集群化方案,它既可以做Redis Proxy,还可以做Memcached Proxy。
它的功能比较单一,只实现了请求路由转发,没有像Codis那么全面有在线扩容的功能,它解决的重点就是把客户端分片的逻辑统一放到了Proxy层而已,其他功能没有做任何处理。
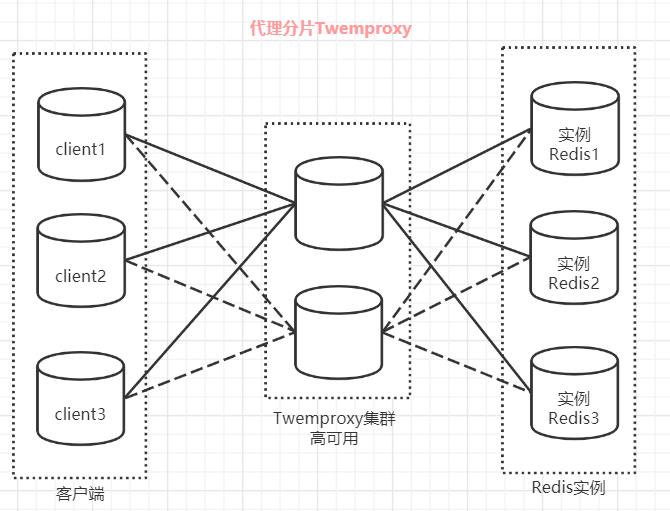
Tweproxy推出的时间最久,在早期没有好的服务端分片集群方案时,应用范围很广,而且性能也极其稳定。
但它的痛点就是无法在线扩容、缩容,这就导致运维非常不方便,而且也没有友好的运维UI可以使用。
Codis代理分片
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有明显的区别 (有一些命令不支持), 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务,
现在美团、阿里等大厂已经开始用codis的集群功能了,
什么是Codis?
Twemproxy不能平滑增加Redis实例的问题带来了很大的不便,于是豌豆荚自主研发了Codis,一个支持平滑增加Redis实例的Redis代理软件,其基于Go和C语言开发,并于2014年11月在GitHub上开源 codis开源地址 。
Codis的架构图:
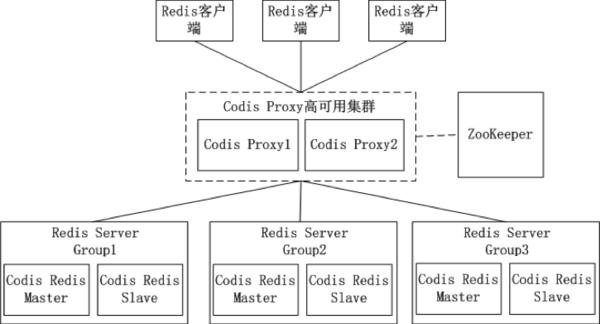
在Codis的架构图中,Codis引入了Redis Server Group,其通过指定一个主CodisRedis和一个或多个从CodisRedis,实现了Redis集群的高可用。
当一个主CodisRedis挂掉时,Codis不会自动把一个从CodisRedis提升为主CodisRedis,这涉及数据的一致性问题(Redis本身的数据同步是采用主从异步复制,当数据在主CodisRedis写入成功时,从CodisRedis是否已读入这个数据是没法保证的),需要管理员在管理界面上手动把从CodisRedis提升为主CodisRedis。
如果手动处理觉得麻烦,豌豆荚也提供了一个工具Codis-ha,这个工具会在检测到主CodisRedis挂掉的时候将其下线并提升一个从CodisRedis为主CodisRedis。
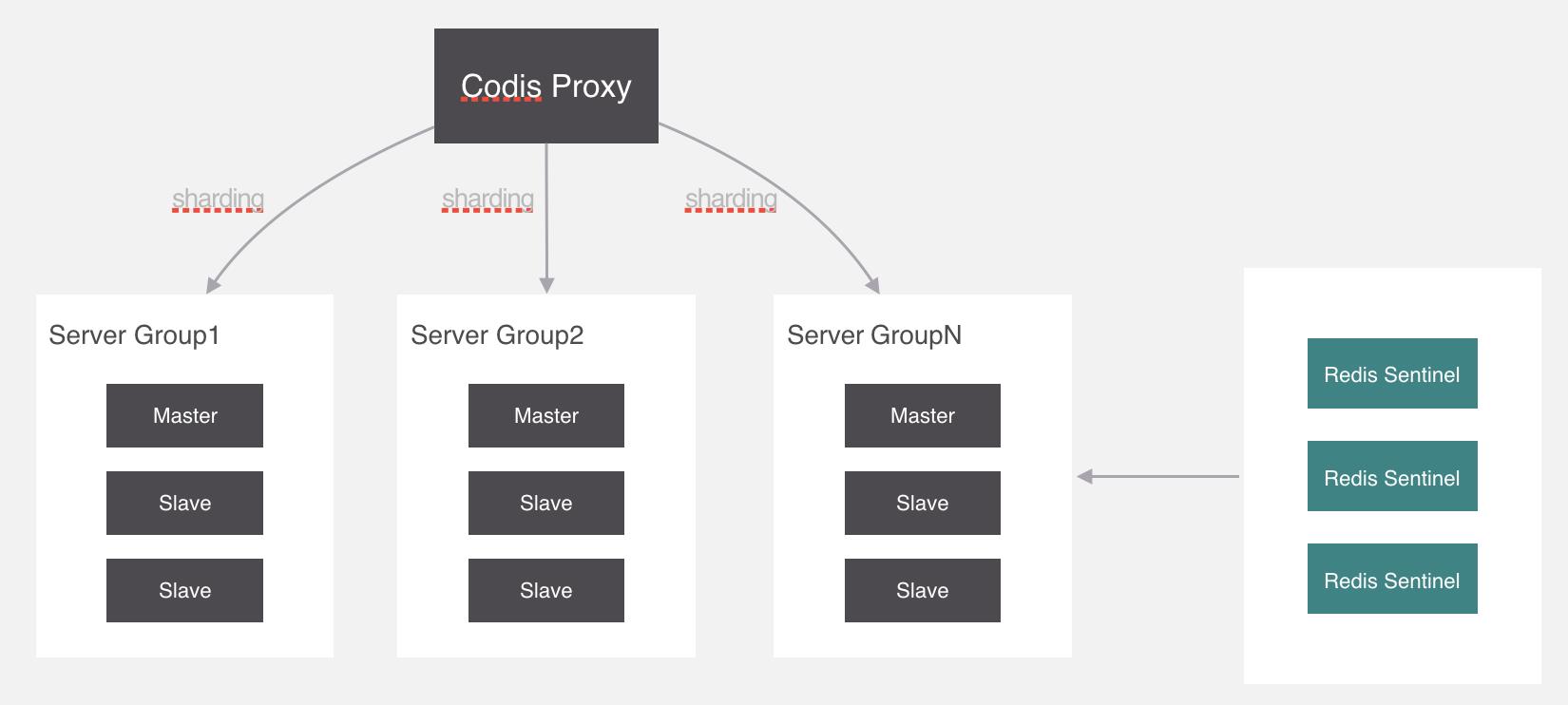
Codis的预分片
Codis中采用预分片的形式,启动的时候就创建了1024个slot,1个slot相当于1个箱子,每个箱子有固定的编号,范围是1~1024。
Codis的分片算法
Codis proxy 代理通过一种算法把要操作的key经过计算后分配到各个组中,这个过程叫做分片。
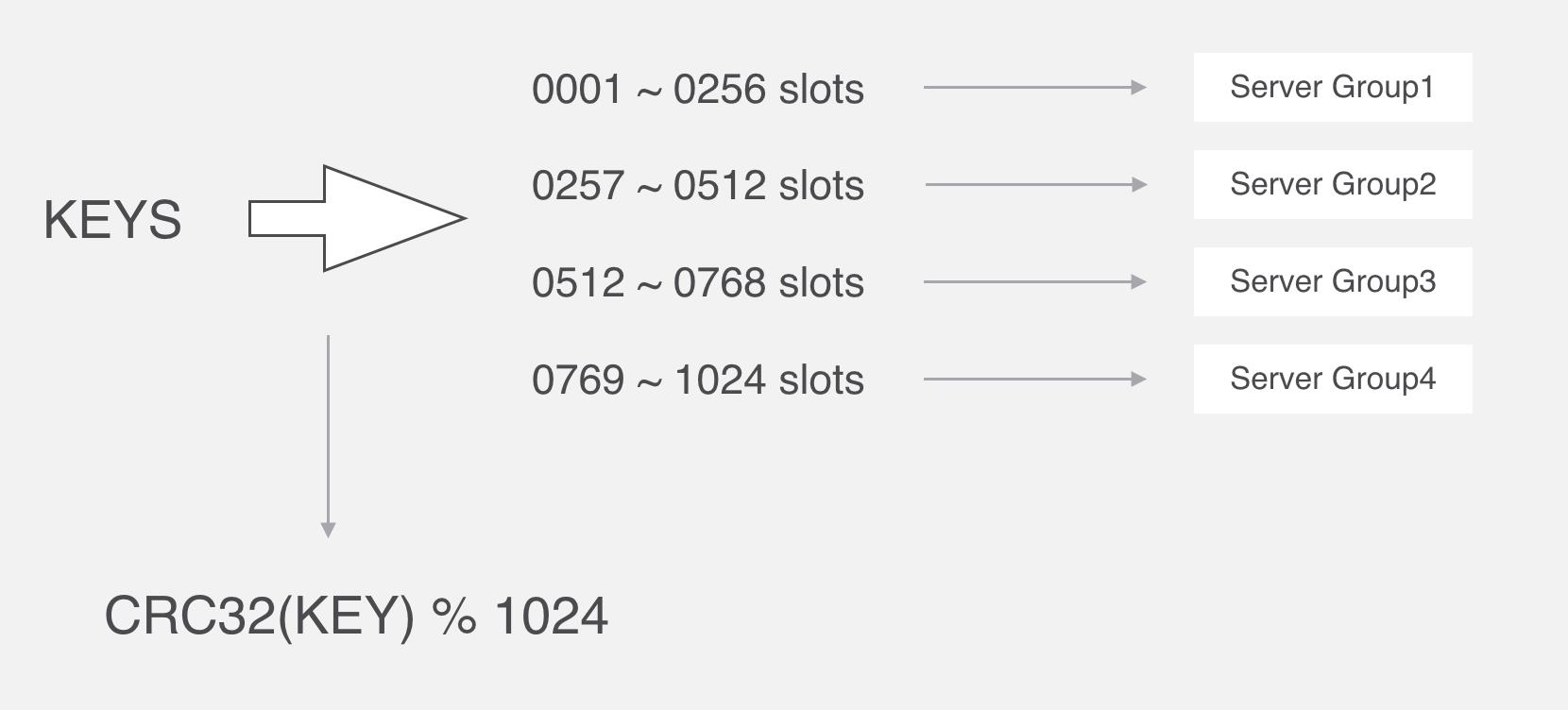
在Codis里面,它把所有的key分为1024个槽,每一个槽位都对应了一个分组,具体槽位的分配,可以进行自定义,现在如果有一个key进来,首先要根据CRC32算法,针对key算出32位的哈希值,然后除以1024取余,然后就能算出这个KEY属于哪个槽,然后根据槽与分组的映射关系,就能去对应的分组当中处理数据了。
CRC全称是循环冗余校验,主要在数据存储和通信领域保证数据正确性的校验手段,CRC校验(循环冗余校验)是数据通讯中最常采用的校验方式。
slot这个箱子用作存放Key,至于Key存放到哪个箱子,可以通过算法“crc32(key)%1024”获得一个数字,这个数字的范围一定是1~1024之间,Key就放到这个数字对应的slot。
例如,如果某个Key通过算法“crc32(key)%1024”得到的数字是5,就放到编码为5的slot(箱子)。
slot和Server Group的关系
1个slot只能放1个Redis Server Group,不能把1个slot放到多个Redis Server Group中。1个Redis Server Group最少可以存放1个slot,最大可以存放1024个slot。
因此,Codis中最多可以指定1024个Redis Server Group。
槽位和分组的映射关系就保存在codis proxy当中
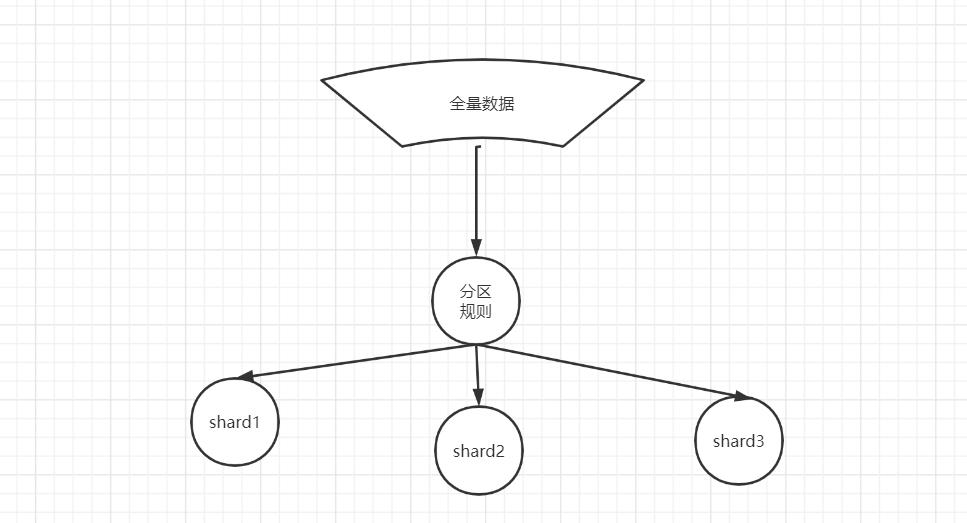
数据分片(sharding)的基本原理
什么是数据分片?
名词说明:
数据分片(sharding)也叫数据分区
为什么要做数据分片?
全量数据较大的场景下,单节点无法满足要求,需要数据分片
什么是数据分片?
按照分片规则把数据分到若干个shard、partition当中
range 分片
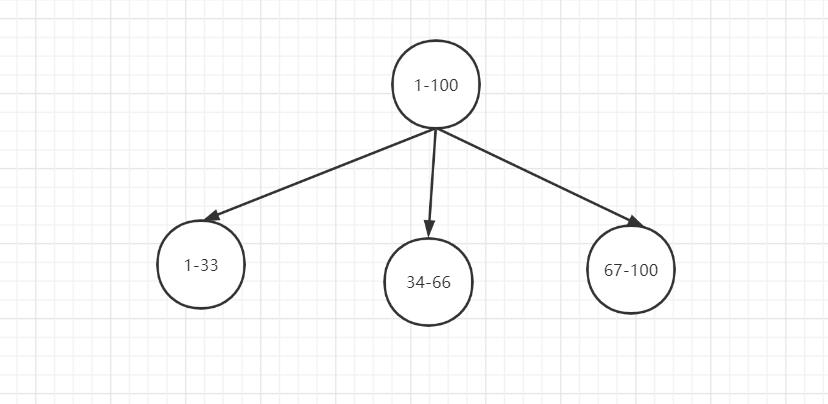
一种是按照 range 来分,就是每个片,一段连续的数据,这个一般是按比如时间范围/数据范围来的,但是这种一般较少用,因为很容易发生数据倾斜,大量的流量都打在最新的数据上了。
比如,安装数据范围分片,把1到100个数字,要保存在3个节点上
按照顺序分片,把数据平均分配三个节点上
- 1号到33号数据保存到节点1上
- 34号到66号数据保存到节点2上
- 67号到100号数据保存到节点3上
ID取模分片
此种分片规则将数据分成n份(通常dn节点也为n),从而将数据均匀的分布于各个表中,或者各节点上。
扩容方便。
ID取模分片常用在关系型数据库的设计
具体请参见 秒杀视频的 亿级库表架构设计
hash 哈希分布
使用hash 算法,获取key的哈希结果,再按照规则进行分片,这样可以保证数据被打散,同时保证数据分布的比较均匀
哈希分布方式分为三个分片方式:
- 哈希取余分片
- 一致性哈希分片
- 虚拟槽分片
哈希取余模分片
例如1到100个数字,对每个数字进行哈希运算,然后对每个数的哈希结果除以节点数进行取余,余数为1则保存在第1个节点上,余数为2则保存在第2个节点上,余数为0则保存在第3个节点,这样可以保证数据被打散,同时保证数据分布的比较均匀
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上
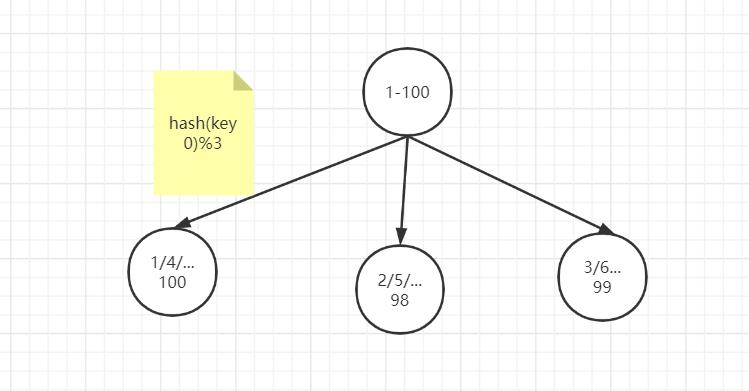
哈希取余分片是非常简单的一种分片方式
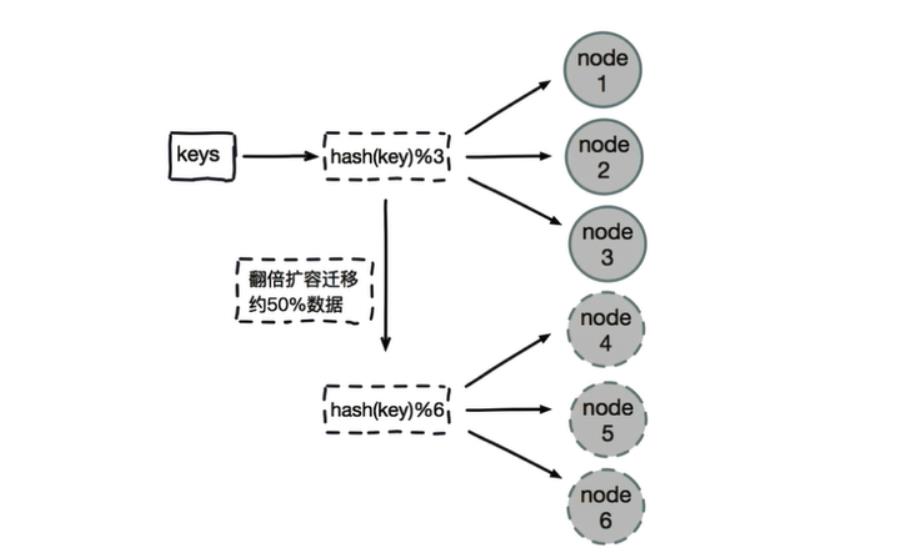
哈希取模分片有一个问题
即当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分布
哈希取余分片,建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。
数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据
哈希取余分片优点:
- 配置简单:对数据进行哈希,然后取余
哈希取余分片缺点:
- 数据节点伸缩时,导致数据迁移
- 迁移数量和添加节点数据有关,建议翻倍扩容
一致性哈希分片
一致性哈希原理:
将所有的数据当做一个token环,
token环中的数据范围是0到2的32次方。
然后为每一个数据节点分配一个token范围值,这个节点就负责保存这个范围内的数据。
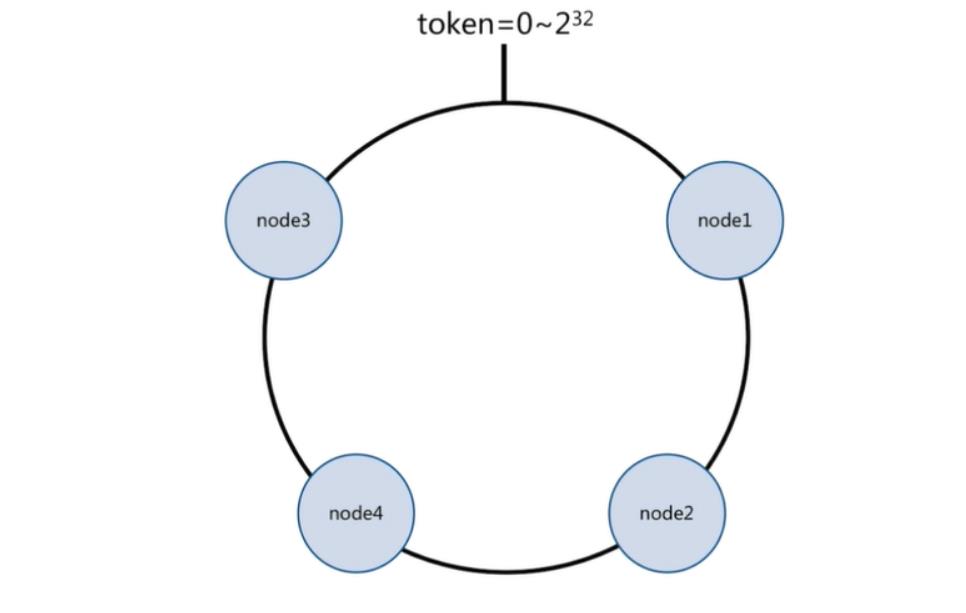
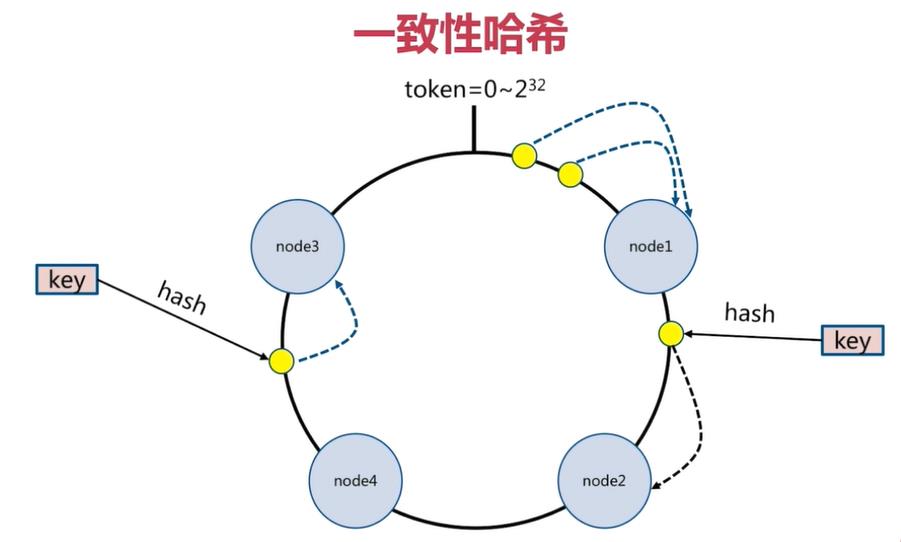
对每一个key进行hash运算,被哈希后的结果在哪个token的范围内,则按顺时针去找最近的节点,这个key将会被保存在这个节点上。
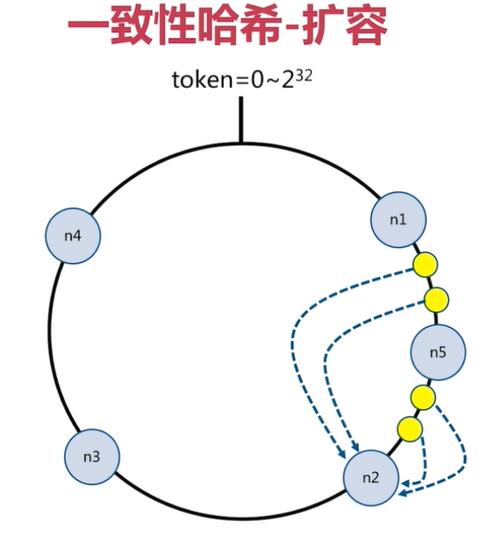
一致性哈希分片的节点扩容
在下面的图中:
-
有4个key被hash之后的值在在n1节点和n2节点之间,按照顺时针规则,这4个key都会被保存在n2节点上
-
如果在n1节点和n2节点之间添加n5节点,当下次有key被hash之后的值在n1节点和n5节点之间,这些key就会被保存在n5节点上面了
下图的例子里,添加n5节点之后:
- 数据迁移会在n1节点和n2节点之间进行
- n3节点和n4节点不受影响
- 数据迁移范围被缩小很多
同理,如果有1000个节点,此时添加一个节点,受影响的节点范围最多只有千分之2。所以,一致性哈希一般用在节点比较多的时候,节点越多,扩容时受影响的节点范围越少
分片方式:哈希 + 顺时针(优化取余)
一致性哈希分片优点:
- 一致性哈希算法解决了分布式下数据分布问题。比如在缓存系统中,通过一致性哈希算法把缓存键映射到不同的节点上,由于算法中虚拟节点的存在,哈希结果一般情况下比较均匀。
- 节点伸缩时,只影响邻近节点,但是还是有数据迁移
“但没有一种解决方案是银弹,能适用于任何场景。所以实践中一致性哈希算法有哪些缺陷,或者有哪些场景不适用呢?”
一致性哈希分片缺点:
一致性哈希在大批量的数据场景下负载更加均衡,但是在数据规模小的场景下,会出现单位时间内某个节点完全空闲的情况出现。
虚拟槽分片 (范围分片的变种)
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式.
虚拟槽分片 ,可以理解为范围分片的变种, hash取模分片+范围分片, 把hash值取余数分为n段,一个段给一个节点负责
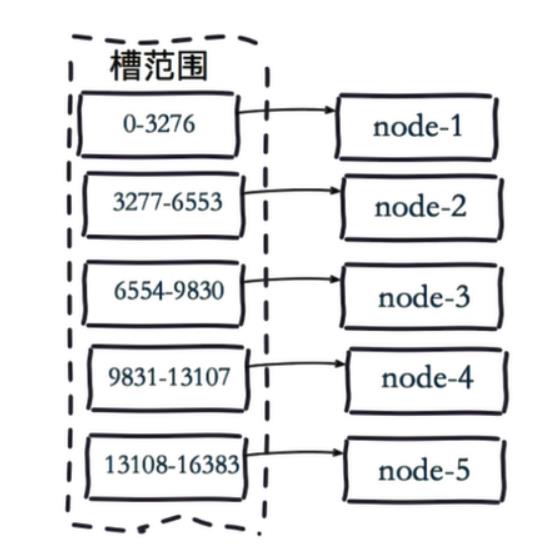
虚拟槽分片 (范围分片的变种)
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式.
在该分片方式中:
- 首先 预设虚拟槽,每个槽为一个hash值,每个node负责一定槽范围。
- 每一个值都是key的hash值取余,每个槽映射一个数据子集,一般比节点数大
Redis Cluster中预设虚拟槽的范围为0到16383

虚拟槽分片的映射步骤:
1.把16384槽按照节点数量进行平均分配,由节点进行管理
2.对每个key按照CRC16规则进行hash运算
3.把hash结果对16383进行取余
4.把余数发送给Redis节点
5.节点接收到数据,验证是否在自己管理的槽编号的范围
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。
当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
3个节点的Redis集群虚拟槽分片结果:
[root@localhost redis-cluster]# docker exec -it redis-cluster_redis1_1 redis-cli --cluster check 192.168.56.121:6001
192.168.56.121:6001 (c4cfd72f...) -> 0 keys | 5461 slots | 1 slaves.
192.168.56.121:6002 (c15a7801...) -> 0 keys | 5462 slots | 1 slaves.
192.168.56.121:6003 (3fe7628d...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.56.121:6001)
M: c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd 192.168.56.121:6001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: a212e28165b809b4c75f95ddc986033c599f3efb 192.168.56.121:6006
slots: (0 slots) slave
replicates 3fe7628d7bda14e4b383e9582b07f3bb7a74b469
M: c15a7801623ee5ebe3cf952989dd5a157918af96 192.168.56.121:6002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 5e74257b26eb149f25c3d54aef86a4d2b10269ca 192.168.56.121:6004
slots: (0 slots) slave
replicates c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd
S: 8fb7f7f904ad1c960714d8ddb9ad9bca2b43be1c 192.168.56.121:6005
slots: (0 slots) slave
replicates c15a7801623ee5ebe3cf952989dd5a157918af96
M: 3fe7628d7bda14e4b383e9582b07f3bb7a74b469 192.168.56.121:6003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
虚拟槽分片特点:
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。槽是集群内数据管理和迁移的基本单位。
槽的范围一般远远大于节点数,比如Redis Cluster槽范围是0~16383。
采用大范围槽的主要目的是为了方便数据拆分和集群扩展,每个节点会负责一定数量的槽。
Redis虚拟槽分区的优点:
-
解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
-
节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
-
支持节点、槽、键之间的映射查询,用于数据路由,在线伸缩等场景。
-
无论数据规模大,还是小,Redis虚拟槽分区各个节点的负载,都会比较均衡 。而一致性哈希在大批量的数据场景下负载更加均衡,但是在数据规模小的场景下,会出现单位时间内某个节点完全空闲的情况出现。
Redis集群如何高可用
要实现Redis高可用,前提条件之一,是需要进行Redis的节点集群
集群的必要性
所谓的集群,就是通过添加服务节点的数量,不同的节点提供相同的服务,从而让服务器达到高可用、自动failover的状态。
面试题:单个redis节点,面临哪些问题?
答:
(1)单个redis存在不稳定性。当redis服务宕机了,就没有可用的服务了。
(2)单个redis的读写能力是有限的。单机的 redis,能够承载的 QPS 大概就在上万到几万不等。
对于缓存来说,一般都是用来支撑读高并发、高可用。
单个redis节点,二者都做不到。
Redis集群模式的分类,可以从下面角度来分:
- 客户端分片
- 代理分片
- 服务端分片
- 代理模式和服务端分片相结合的模式
客户端分片包括:
ShardedJedisPool
ShardedJedisPool是redis没有集群功能之前客户端实现的一个数据分布式方案,
使用shardedJedisPool实现redis集群部署,由于shardedJedisPool的原理是通过一致性哈希进行切片实现的,不同点key被分别分配到不同的redis实例上。
代理分片包括:
- Codis
- Twemproxy
服务端分片包括:
- Redis Cluster
从否中心化来划分
它们还可以用是否中心化来划分
- 无中心化的集群方案
其中客户端分片、Redis Cluster属于无中心化的集群方案
- 中心化的集群方案
Codis、Tweproxy属于中心化的集群方案。
是否中心化是指客户端访问多个Redis节点时,是直接访问还是通过一个中间层Proxy来进行操作,直接访问的就属于无中心化的方案,通过中间层Proxy访问的就属于中心化的方案,它们有各自的优劣,下面分别来介绍。
如何学习redis集群
说明:
(1)redis集群中,每一个redis称之为一个节点。
(2)redis集群中,有两种类型的节点:主节点(master)、从节点(slave)。
(3)redis集群,是基于redis主从复制实现。
集群搭建实操:Docker方式部署redis-cluster步骤
1、redis容器初始化
2、redis容器集群配置
这里引用了别人的一个镜像publicisworldwide/redis-cluster,方便快捷。
redis-cluster的节点端口共分为2种,
-
一种是节点提供服务的端口,如6379、6001;
-
一种是节点间通信的端口,固定格式为:10000+6379/10000+6001。
若不想使用host模式,也可以把network_mode去掉,但就要加ports映射。
这里使用host(主机)网络模式,把redis数据挂载到本机目录/data/redis/800*下。
Docker网络
Docker使用Linux桥接技术,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。
因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
Docker网桥是宿主机虚拟出来的,并不是真实存在的网络设备,外部网络是无法寻址到的,这也意味着外部网络无法通过直接Container-IP访问到容器。
如果容器希望外部访问能够访问到,可以通过映射容器端口到宿主主机(端口映射),即docker run创建容器时候通过 -p 或 -P 参数来启用,访问容器的时候就通过[宿主机IP]:[容器端口]访问容器。
Docker容器的四类网络模式
| Docker网络模式 | 配置 | 说明 |
|---|---|---|
| host模式 | –net=host | 容器和宿主机共享Network namespace。 |
| container模式 | –net=container:NAME_or_ID | 容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。 |
| none模式 | –net=none | 容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥连接,配置IP等。 |
| bridge模式 | –net=bridge | (默认为该模式) |
桥接模式(default)
Docker容器的默认网络模式为桥接模式,如图所示:

Docker安装时会创建一个名为docker0的bridge虚拟网桥。
bridge模式是docker的默认网络模式,不写–net参数,就是bridge模式。
新创建的容器都会自动连接到这个虚拟网桥。
bridge网桥用于同一主机上的docker容器相互通信,连接到同一个网桥的docker容器可以相互通信。
bridge 对宿主机来讲相当于一个单独的网卡设备 ,对于运行在宿主机上的每个容器来说相当于一个交换机,所有容器的虚拟网线的一端都连接到docker0上。
容器通过本地主机进行上网,容器会创建名为veth的虚拟网卡,网卡一端连接到docker0网桥,另一端连接容器,容器就可以通过网桥通过分配的IP地址进行上网。
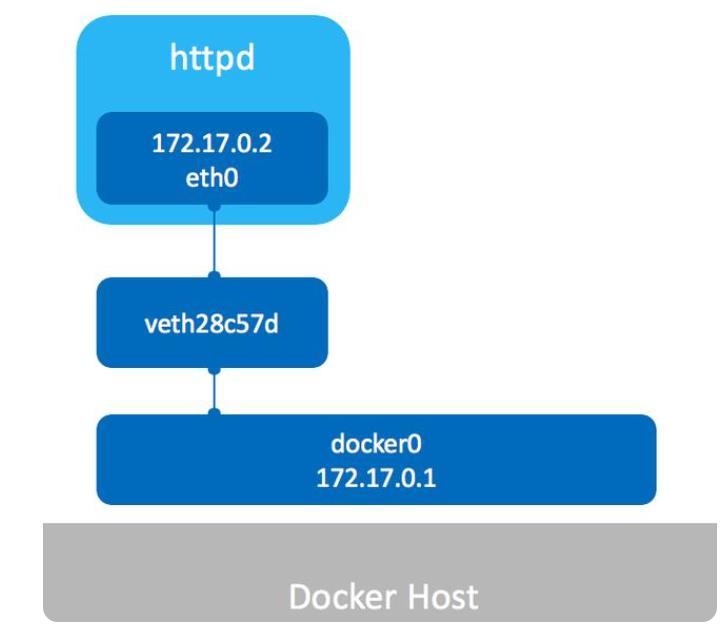
docker exec -it rmqbroker-a cat /etc/hosts
[root@localhost ~]# docker exec -it rmqbroker-a cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.30.0.5 c55ea6edcc14
使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。
可以使用iptables -t nat -vnL查看。
pkts bytes target prot opt in out source destination
15141 908K RETURN all -- br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0
536K 32M RETURN all -- br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0
0 0 RETURN all -- br-f232a6bcdb94 * 0.0.0.0/0 0.0.0.0/0
0 0 RETURN all -- docker0 * 0.0.0.0/0 0.0.0.0/0
11 572 DNAT tcp -- !br-f232a6bcdb94 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3306 to:172.19.0.2:3306
0 0 DNAT tcp -- !br-f232a6bcdb94 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3307 to:172.19.0.3:3306
0 0 DNAT tcp -- !br-f232a6bcdb94 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3308 to:172.19.0.4:3306
3 156 DNAT tcp -- !br-f232a6bcdb94 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:23306 to:172.19.0.5:23306
0 0 DNAT tcp -- !br-f232a6bcdb94 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:1080 to:172.19.0.5:1080
0 0 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8011 to:172.20.0.2:9555
8 416 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8001 to:172.20.0.2:8001
0 0 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8013 to:172.20.0.3:9555
0 0 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8003 to:172.20.0.3:8003
0 0 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8012 to:172.20.0.4:9555
0 0 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8002 to:172.20.0.4:8002
20 1040 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8848 to:172.20.0.5:8848
0 0 DNAT tcp -- !br-e495dc44c56b * 0.0.0.0/0 0.0.0.0/0 tcp dpt:1082 to:172.20.0.5:1080
0 0 DNAT tcp -- !br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:9877 to:172.30.0.2:9876
0 0 DNAT tcp -- !br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:9876 to:172.30.0.3:9876
5 260 DNAT tcp -- !br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:9001 to:172.30.0.4:9001
0 0 DNAT tcp -- !br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:10912 to:172.30.0.5:10912
0 0 DNAT tcp -- !br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:10911 to:172.30.0.5:10911
0 0 DNAT tcp -- !br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:10922 to:172.30.0.6:10922
0 0 DNAT tcp -- !br-9a8ffe43b503 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:10921 to:172.30.0.6:10921
我们也可以自定义自己的bridge网络,docker文档建议使用自定义bridge网络
创建一个自定义网络, 可以指定子网、IP地址范围、网关等网络配置
docker network create --driver bridge --subnet 172.22.16.0/24 --gateway 172.22.16.1 mynet2
查看docker网络,是否创建成功。
docker network ls
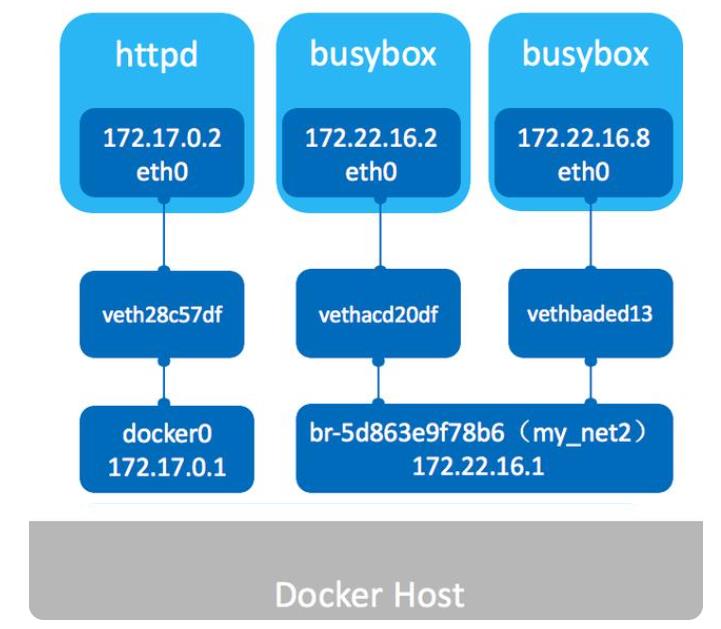
总之:Docker网络bridge桥接模式,是创建和运行容器时默认模式。这种模式会为每个容器分配一个独立的网卡,桥接到默认或指定的bridge上,同一个Bridge下的容器下可以互相通信的。我们也可以创建自定义bridge以满足个性化的网络需求。
HOST模式

Docker使用了Linux的Namespaces技术来进行资源隔离,如:
- PID Namespace隔离进程,
- Mount Namespace隔离文件系统,
- Network Namespace隔离网络等。
一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、Iptable规则等都与其他的Network Namespace隔离。
bridge模式下,一个Docker容器一般会分配一个独立的Network Namespace。
host模式类似于Vmware的桥接模式,与宿主机在同一个网络中,但没有独立IP地址。
一个Docker容器一般会分配一个独立的Network Namespace。
但如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。
容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
容器与主机在相同的网络命名空间下面,使用相同的网络协议栈,容器可以直接使用主机的所有网络接口
Container模式

None
获取独立的network namespace,但不为容器进行任何网络配置,之后用户可以自己进行配置,
容器内部只能使用loopback网络设备,不会再有其他的网络资源
创建文件目录结构
mkdir -p /home/docker-compose/redis-cluster/conf/6001,6002,6003,6004,6005,6006/data
离线环境镜像导入
从有公网的环境拉取镜像,然后导出镜像
-
publicisworldwide/redis-cluster redis-cluster镜像
-
nien/redis-trib 集群管理工具:自动执行节点握手,自动操作节点主从配置,自动给主节点分配槽
无公网的环境,上传到到内网环境, 上传镜像到目标虚拟机
然后导入docker,load到docker
docker load -i /vagrant/3G-middleware/redis-cluster.tar
docker load -i /vagrant/3G-middleware/redis-trib.tar
导入后看到两个image 镜像:
[root@localhost ~]# docker image ls
publicisworldwide/redis-cluster latest 29e4f38e4475 2 years ago 94.9MB
nien/redis-trib latest 0f7b910114d5 4 years ago 32MB
redis容器启动集群
节点规划(三主三从)
| 容器名称 | 容器IP地址 | 映射端口号 |
|---|---|---|
| redis-master1 | 172.20.0.2 | 7001->7001 |
| redis-master2 | 172.20.0.3 | 7002->7002 |
| redis-master3 | 172.20.0.4 | 7003->7003 |
| redis-slave-1 | 172.30.0.2 | 7004->7004 |
| redis-slave-2 | 172.30.0.3 | 7005->7005 |
| redis-slave-3 | 172.30.0.4 | 7006->7006 |
创建内部网络
注意,首先创建 内部网络
创建普通的网络,即可
#创建网络,指定网段
docker network create ha-network-overlay
docker inspect ha-network-overlay #查看网络
如果需要指定网段,可以如下(此处忽略):
创建redis配置文件
daemonize no
port 7001
pidfile /var/run/redis.pid
dir "/data"
logfile "/data/redis.log"
cluster‐enabled yes#启动集群模式
cluster‐config‐file nodes.conf
cluster‐node‐timeout 10000
#bind 127.0.0.1
protected‐mode no #关闭保护模式
appendonly yes #开启aof
repl-timeout 600 #默认60
repl-ping-replica-period 100 #默认10
#如果要设置密码需要增加如下配置:
#requirepass 123321 #设置redis访问密码
#masterauth 123321 #设置集群节点间访问密码,跟上面一致
-
port:节点端口;
-
requirepass:添加访问认证;
-
masterauth:如果主节点开启了访问认证,从节点访问主节点需要认证;
-
protected-mode:保护模式,默认值 yes,即开启。开启保护模式以后,需配置 bind ip 或者设置访问密码;关闭保护模式,外部网络可以直接访问;
-
daemonize:是否以守护线程的方式启动(后台启动),默认 no;
当redis.conf配置文件中daemonize参数设置的yes,这使得redis是以后台启动的方式运行的,
由于docker容器在启动时,需要任务在前台运行,否则会启动后立即退出,
因此导致redis容器启动后立即退出问题。
所以redis.conf中daemonize必须是no
-
appendonly:是否开启 AOF 持久化模式,默认 no;
-
logfile “/data/redis.log”
指定日志文件路径,默认值为 logfile ’ ', 默认为控制台打印,并没有日志文件生成
-
bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通 过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
-
cluster-enabled:是否开启集群模式,默认 no;
-
cluster-config-file:集群节点信息文件;
-
cluster-node-timeout:集群节点连接超时时间;
-
cluster-announce-ip:集群节点 IP,填写宿主机的 IP;
-
cluster-announce-port:集群节点映射端口;
-
cluster-announce-bus-port:集群节点总线端口。
每个 Redis 集群节点都需要打开两个 TCP 连接。一个用于为客户端提供服务的正常 Redis TCP 端口,例如 6379。还有一个基于 6379 端口加 10000 的端口,比如 16379。
第二个端口用于集群总线,这是一个使用二进制协议的节点到节点通信通道。节点使用集群总线进行故障检测、配置更新、故障转移授权等等。客户端永远不要尝试与集群总线端口通信,与正常的 Redis 命令端口通信即可,但是请确保防火墙中的这两个端口都已经打开,否则 Redis 集群节点将无法通信。
创建容器编排文件
使用docker-compose方式,先创建一个docker-compose.yml文件,容器的ip使用host模式,内容如下:
version: '3.5'
services:
redis1:
image: nien/redis-cluster:5.0.0
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster/conf/6001/data:/data
environment:
- REDIS_PORT=6001
redis2:
image: nien/redis-cluster:5.0.0
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster/conf/6002/data:/data
environment:
- REDIS_PORT=6002
redis3:
image: nien/redis-cluster:5.0.0
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster/conf/6003/data:/data
environment:
- REDIS_PORT=6003
redis4:
image: nien/redis-cluster:5.0.0
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster/conf/6004/data:/data
environment:
- REDIS_PORT=6004
redis5:
image: nien/redis-cluster:5.0.0
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster/conf/6005/data:/data
environment:
- REDIS_PORT=6005
redis6:
image: nien/redis-cluster:5.0.0
network_mode: host
restart: always
volumes:
- /home/docker-compose/redis-cluster/conf/6006/data:/data
environment:
- REDIS_PORT=6006
作为参考,如果容器的ip使用BRIDGE模式,docker-compose.yml文件内容如下:
version: '3'
services:
redis1:
image: publicisworldwide/redis-cluster
restart: always
volumes:
- /data/redis/6001/data:/data
environment:
- REDIS_PORT=6001
ports:
- '6001:6001' #服务端口
- '16001:16001' #集群端口
redis2:
image: publicisworldwide/redis-cluster
restart: always
volumes:
- /data/redis/6002/data:/data
environment:
- REDIS_PORT=6002
ports:
- '6002:6002'
- '16002:16002'
redis3:
image: publicisworldwide/redis-cluster
restart: always
volumes:
- /data/redis/6003/data:/data
environment:
- REDIS_PORT=6003
ports:
- '6003:6003'
- '16003:16003'
redis4:
image: publicisworldwide/redis-cluster
restart: always
volumes:
- /data/redis/6004/data:/data
environment:
- REDIS_PORT=6004
ports:
- '6004:6004'
- '16004:16004'
redis5:
image: publicisworldwide/redis-cluster
restart: always
volumes:
- /data/redis/6005/data:/data
environment:
- REDIS_PORT=6005
ports:
- '6005:6005'
- '16005:16005'
redis6:
image: publicisworldwide/redis-cluster
restart: always
volumes:
- /data/redis/6006/data:/data
environment:
- REDIS_PORT=6006
ports:
- '6006:6006'
- '16006:16006'
启动服务redis容器
创建文件后,直接启动服务
docker-compose down
rm -rf /home/docker-compose/redis-cluster
rm -rf /home/docker-compose/redis-cluster-ha
mkdir -p /home/docker-compose/redis-cluster-ha
cp -rf /vagrant/3G-middleware/redis-cluster-ha /home/docker-compose/
ll /home/docker-compose/redis-cluster-ha
cd /home/docker-compose/redis-cluster-ha
chmod 777 -R /home/docker-compose/redis-cluster-ha/7001,7002,7003,7004,7005,7006/data
chmod 777 -R /home/docker-compose/redis-cluster-ha/7001,7002,7003,7004,7005,7006/logs
docker-compose up -d
docker-compose logs
docker-compose logs -f redis1
docker-compose logs -f redis2
docker run --rm -it nien/redis-trib create --replicas 1 192.168.56.121:7001 192.168.56.121:7002 192.168.56.121:7003 192.168.56.121:7004 192.168.56.121:7005 192.168.56.121:7006
查看启动的进程
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2bdd27191859 publicisworldwide/redis-cluster "/usr/local/bin/entr…" 18 seconds ago Up 17 seconds redis-cluster_redis4_1
afdf208c55f3 publicisworldwide/redis-cluster "/usr/local/bin/entr…" 18 seconds ago Up 17 seconds redis-cluster_redis1_1
d14d7dbd207f publicisworldwide/redis-cluster "/usr/local/bin/entr…" 18 seconds ago Up 17 seconds redis-cluster_redis5_1
25070ed4a434 publicisworldwide/redis-cluster "/usr/local/bin/entr…" 18 seconds ago Up 17 seconds redis-cluster_redis2_1
35e1ff66d2db publicisworldwide/redis-cluster "/usr/local/bin/entr…" 18 seconds ago Up 17 seconds redis-cluster_redis3_1
615bfbf336c0 publicisworldwide/redis-cluster "/usr/local/bin/entr…" 18 seconds ago Up 17 seconds redis-cluster_redis6_1
状态为Up,说明服务均已启动,镜像无问题。
注意:以上镜像不能设置永久密码,其实redis一般是内网访问,可以不需密码。
建立redis集群
这里同样使用了另一个镜像nien/redis-trib,执行时会自动下载。
离线场景请提前load,或者导入到私有的restry。
使用redis-trib.rb创建redis 集群
上面只是启动了6个redis容器,并没有设置集群,通过下面的命令可以设置集群。
使用 redis-trib.rb create 命令完成节点握手和槽分配过程
docker run --rm -it nien/redis-trib create --replicas 1 hostip:6001 hostip:6002 hostip:6003 hostip:6004 hostip:6005 hostip:6006
#hostip 换成 主机的ip
docker run --rm -it nien/redis-trib create --replicas 1 192.168.56.121:7001 192.168.56.121:7002 192.168.56.121:7003 192.168.56.121:7004 192.168.56.121:7005 192.168.56.121:7006
–replicas 参数指定集群中每个主节点配备几个从节点,这里设置为1,
redis-trib.rb 会尽可能保证主从节点不分配在同一机器下,因此会重新排序节点列表顺序。
节点列表顺序用于确定主从角色,先主节点之后是从节点。
创建过程中首先会给出主从节点角色分配的计划,并且会生成报告
日志如下:
[root@localhost redis-cluster]# docker run --rm -it nien/redis-trib create --replicas 1 192.168.56.121:6001 192.168.56.121:6002 192.168.56.121:6003 192.168.56.121:6004 192.168.56.121:6005 192.168.56.121:6006
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.56.121:6001
192.168.56.121:6002
192.168.56.121:6003
Adding replica 192.168.56.121:6004 to 192.168.56.121:6001
Adding replica 192.168.56.121:6005 to 192.168.56.121:6002
Adding replica 192.168.56.121:6006 to 192.168.56.121:6003
M: c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd 192.168.56.121:6001
slots:0-5460 (5461 slots) master
M: c15a7801623ee5ebe3cf952989dd5a157918af96 192.168.56.121:6002
slots:5461-10922 (5462 slots) master
M: 3fe7628d7bda14e4b383e9582b07f3bb7a74b469 192.168.56.121:6003
slots:10923-16383 (5461 slots) master
S: 5e74257b26eb149f25c3d54aef86a4d2b10269ca 192.168.56.121:6004
replicates c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd
S: 8fb7f7f904ad1c960714d8ddb9ad9bca2b43be1c 192.168.56.121:6005
replicates c15a7801623ee5ebe3cf952989dd5a157918af96
S: a212e28165b809b4c75f95ddc986033c599f3efb 192.168.56.121:6006
replicates 3fe7628d7bda14e4b383e9582b07f3bb7a74b469
Can I set the above configuration? (type 'yes' to accept): yes
注意:出现Can I set the above configuration? (type ‘yes’ to accept): 是要输入yes 不是Y
docker添加 --rm 参数,意思是启动容器,执行完成后,停止即删除
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join...
>>> Performing Cluster Check (using node 192.168.56.121:6001)
M: c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd 192.168.56.121:6001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: a212e28165b809b4c75f95ddc986033c599f3efb 192.168.56.121:6006@16006
slots: (0 slots) slave
replicates 3fe7628d7bda14e4b383e9582b07f3bb7a74b469
M: c15a7801623ee5ebe3cf952989dd5a157918af96 192.168.56.121:6002@16002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 5e74257b26eb149f25c3d54aef86a4d2b10269ca 192.168.56.121:6004@16004
slots: (0 slots) slave
replicates c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd
S: 8fb7f7f904ad1c960714d8ddb9ad9bca2b43be1c 192.168.56.121:6005@16005
slots: (0 slots) slave
replicates c15a7801623ee5ebe3cf952989dd5a157918af96
M: 3fe7628d7bda14e4b383e9582b07f3bb7a74b469 192.168.56.121:6003@16003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
详解redis-trib.rb 的命令
命令说明:
redis-trib.rb help
Usage: redis-trib <command> <options> <arguments ...>
#创建集群
create host1:port1 ... hostN:portN
--replicas <arg> #带上该参数表示是否有从,arg表示从的数量
#检查集群
check host:port
#查看集群信息
info host:port
#修复集群
fix host:port
--timeout <arg>
#在线迁移slot
reshard host:port #个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口
--from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入。
--slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--yes #设置该参数,可以在打印执行reshard计划的时候,提示用户输入yes确认后再执行reshard
--timeout <arg> #设置migrate命令的超时时间。
--pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。
#平衡集群节点slot数量
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
#将新节点加入集群
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
#从集群中删除节点
del-node host:port node_id
#设置集群节点间心跳连接的超时时间
set-timeout host:port milliseconds
#在集群全部节点上执行命令
call host:port command arg arg .. arg
#将外部redis数据导入集群
import host:port
--from <arg>
--copy
--replace
docker run --rm -it nien/redis-trib info 192.168.56.121:6001
docker run --rm -it nien/redis-trib info 192.168.56.121:6002
docker run --rm -it nien/redis-trib info 192.168.56.121:6003
通过客户端命令使用集群
检查集群状态
docker exec -it redis-cluster_redis1_1 redis-cli --cluster check 192.168.56.121:6001
使用到的命令为: redis-cli --cluster check
结果如下:
[root@localhost redis-cluster]# docker exec -it redis-cluster_redis1_1 redis-cli --cluster check 192.168.56.121:6001
192.168.56.121:6001 (c4cfd72f...) -> 0 keys | 5461 slots | 1 slaves.
192.168.56.121:6002 (c15a7801...) -> 0 keys | 5462 slots | 1 slaves.
192.168.56.121:6003 (3fe7628d...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.56.121:6001)
M: c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd 192.168.56.121:6001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: a212e28165b809b4c75f95ddc986033c599f3efb 192.168.56.121:6006
slots: (0 slots) slave
replicates 3fe7628d7bda14e4b383e9582b07f3bb7a74b469
M: c15a7801623ee5ebe3cf952989dd5a157918af96 192.168.56.121:6002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 5e74257b26eb149f25c3d54aef86a4d2b10269ca 192.168.56.121:6004
slots: (0 slots) slave
replicates c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd
S: 8fb7f7f904ad1c960714d8ddb9ad9bca2b43be1c 192.168.56.121:6005
slots: (0 slots) slave
replicates c15a7801623ee5ebe3cf952989dd5a157918af96
M: 3fe7628d7bda14e4b383e9582b07f3bb7a74b469 192.168.56.121:6003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
redis-cli --cluster命令详解
redis-cli --cluster命令参数详解
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
参考的cluster命令
CLUSTER info:打印集群的信息。
CLUSTER nodes:列出集群当前已知的所有节点(node)的相关信息。
CLUSTER meet <ip> <port>:将ip和port所指定的节点添加到集群当中。
CLUSTER addslots <slot> [slot ...]:将一个或多个槽(slot)指派(assign)给当前节点。
CLUSTER delslots <slot> [slot ...]:移除一个或多个槽对当前节点的指派。
CLUSTER slots:列出槽位、节点信息。
CLUSTER slaves <node_id>:列出指定节点下面的从节点信息。
CLUSTER replicate <node_id>:将当前节点设置为指定节点的从节点。
CLUSTER saveconfig:手动执行命令保存保存集群的配置文件,集群默认在配置修改的时候会自动保存配置文件。
CLUSTER keyslot <key>:列出key被放置在哪个槽上。
CLUSTER flushslots:移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
CLUSTER countkeysinslot <slot>:返回槽目前包含的键值对数量。
CLUSTER getkeysinslot <slot> <count>:返回count个槽中的键。
CLUSTER 以上是关于redis 集群 实操 (史上最全5w字长文)的主要内容,如果未能解决你的问题,请参考以下文章