机器学习中的特征缩放(feature scaling)
Posted xianhan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习中的特征缩放(feature scaling)相关的知识,希望对你有一定的参考价值。
参考:https://blog.csdn.net/iterate7/article/details/78881562
在运用一些机器学习算法的时候不可避免地要对数据进行特征缩放(feature scaling),比如:在随机梯度下降(stochastic gradient descent)算法中,特征缩放有时能提高算法的收敛速度。
什么是特征缩放
特征缩放的目标就是数据规范化,使得特征的范围具有可比性。它是数据处理的预处理处理,对后面的使用数据具有关键作用。
机器算法为什么要特征缩放
特征缩放还可以使机器学习算法工作的更好。比如在K近邻算法中,分类器主要是计算两点之间的欧几里得距离,如果一个特征比其它的特征有更大的范围值,那么距离将会被这个特征值所主导。因此每个特征应该被归一化,比如将取值范围处理为0到1之间。
第二个原因则是,特征缩放也可以加快梯度收敛的速度。
特征缩放的一些方法
调节比例(Rescaling)
这种方法是将数据的特征缩放到[0,1]或[-1,1]之间。缩放到什么范围取决于数据的性质。对于这种方法的公式如下:
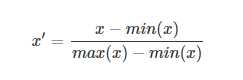
xx是最初的特征值,x‘x′是缩放后的值。
平均值规范化(Mean normalisation)
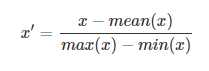
标准化(Standardization)
特征标准化使每个特征的值有零均值(zero-mean)和单位方差(unit-variance)。这个方法在机器学习地算法中被广泛地使用。例如:SVM,逻辑回归和神经网络。这个方法的公式如下:
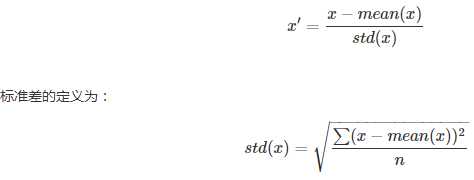
缩放到单位长度(Scaling to unit length)
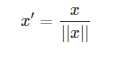
就是除以向量的欧拉长度( the Euclidean length of the vector),二维范数。
总结
数据的归一化和缩放非常重要,会影响到特征选择和对真实业务问题的判定。
参考
https://en.wikipedia.org/wiki/Feature_scaling
以上是关于机器学习中的特征缩放(feature scaling)的主要内容,如果未能解决你的问题,请参考以下文章
机器学习-特征工程-Feature generation 和 Feature selection
R语言基于机器学习算法进行特征筛选(Feature Selection)
机器学习 | 特征选择(Feature Selection)
R语言基于Boruta进行机器学习特征筛选(Feature Selection)