jeecg项目学习(开源项目持续学习)
Posted 知青先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jeecg项目学习(开源项目持续学习)相关的知识,希望对你有一定的参考价值。
目录
jeecg低代码多系统技术理论学习:
https://www.wenjiangs.com/doc/nkyrsvhi 文档地址
https://github.com/jeecgboot/jeecg-boot github地址
https://gitee.com/jeecg/jeecg-boot gitee地址
在线手册笔记:
后台:1-83
前台:84-146
权限控制:147-163
online表单组件(表单设计器):在线表单开发 164-264
app打包:265-268
socket+单点:269-276
表单设计器:277-336
第三方系统:337-342
开发相关资料文档:343-361
项目部署可能出现的环境问题:363-374
技术架构:
语言:Java 8
IDE(JAVA): IDEA / Eclipse安装lombok插件
IDE(前端): WebStorm 或者 IDEA
依赖管理:Maven
数据库:mysql5.7+ & Oracle 11g & Sqlserver2017
缓存:Redis
后端
基础框架:Spring Boot 2.3.5.RELEASE
微服务框架: Spring Cloud Alibaba 2.2.3.RELEASE
持久层框架:Mybatis-plus 3.4.1、minidao
安全框架:Apache Shiro 1.7.0,Jwt 3.11.0
微服务技术栈:Spring Cloud Alibaba、Nacos、Gateway、Sentinel、Skywalking
数据库连接池:阿里巴巴Druid 1.1.22
缓存框架:redis
日志打印:logback
其他:fastjson,poi,Swagger-ui,quartz, lombok(简化代码)等。
前端
Vue 2.6.10,Vuex,Vue Router
Axios
ant-design-vue
webpack,yarn
vue-cropper - 头像裁剪组件
@antv/g2 - Alipay AntV 数据可视化图表
Viser-vue - antv/g2 封装实现
eslint,@vue/cli 3.2.1
vue-print-nb - 打印
安装环境:
前台:
1、在npm中安装yarn。
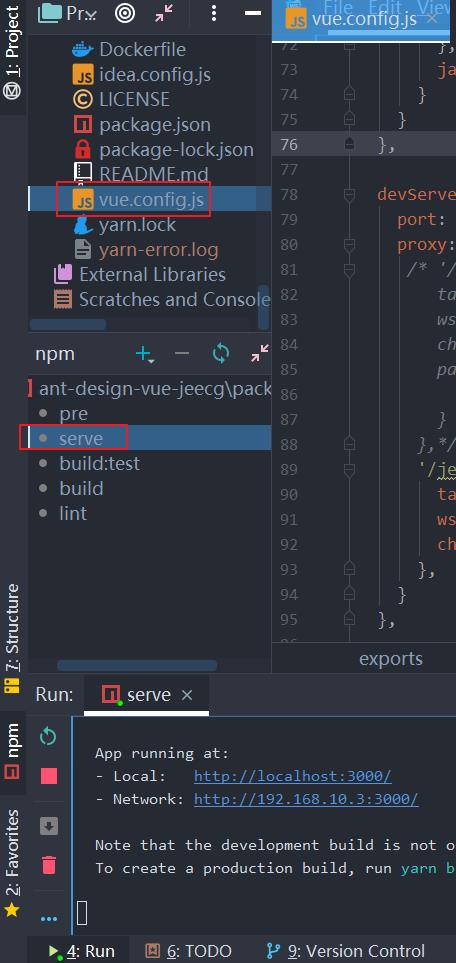
2、在项目下,webstorm 工具内yarn install安装相关插件。修改vue.config.js开发文件
3、启动vue:找到项目目录下文件package.json文件,鼠标右键选择Show npm Scripts。
npm run server.
4、出现启动失败,升级npm版本,重新拉取依赖。
5、登入信息:http://localhost:3000 admin/123456
6、界面二开,根据后台规则来。
后台:
1、基础服务:安装jdk8、Maven、Redis、Mysql
2、导入基础脚本:
create database jeecg-boot default character set utf8mb4 collate utf8mb4_general_ci;
jeecg-boot/db/jeecg-boot-mysql.sql
3、修改项目基础服务配置项 /src/main/resources/application-dev.yml
redis、mysql
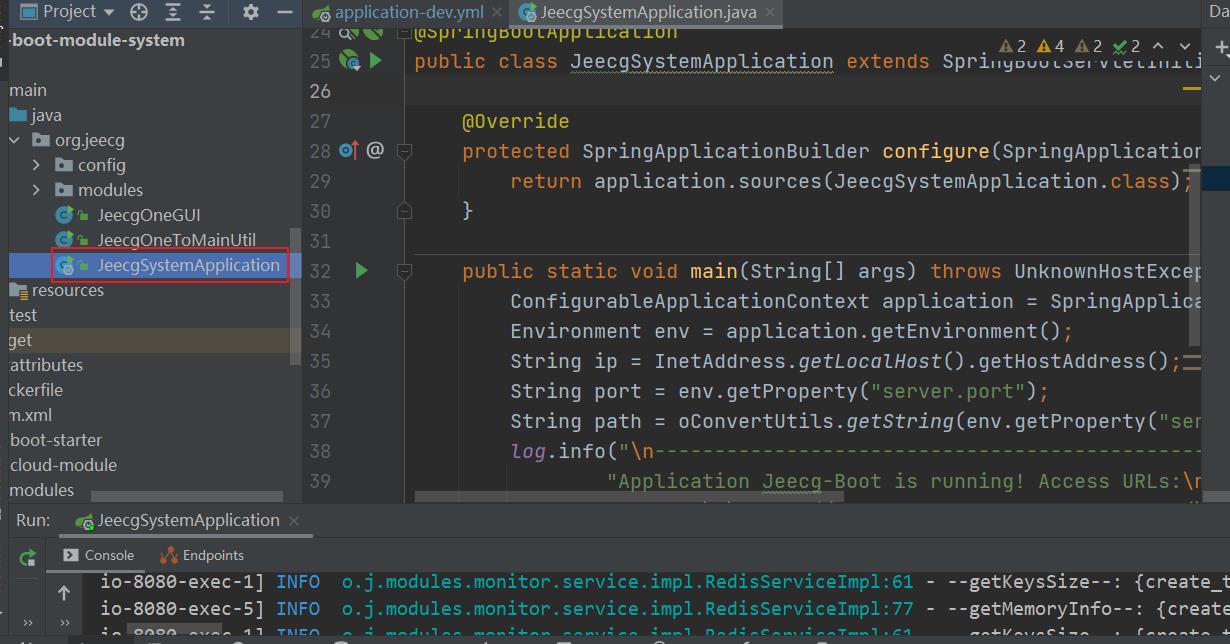
4、启动基础信息:src/main/java/org/jeecg/JeecgApplication.java 启动器
http://localhost:8080/jeecg-boot 这是后台发布接口界面。
5、二次开发的项目结构:
项目结构说明:
├─jeecg-boot-parent(父POM: 项目依赖、modules组织)
│ ├─jeecg-boot-base-common(共通Common模块: 底层工具类、注解、接口)
│ ├─jeecg-boot-module-system (系统管理模块: 系统管理、权限等功能) – 默认作为启动项目
│ ├─jeecg-boot-module-? (自己扩展新模块项目,启动的时候,在system里面引用即可)
部署:
通用修改基础配置:
1、修改数据库连接 application-prod.yml
2、修改缓存redis配置 application-prod.yml
3、修改上传附件配置 application-prod.yml
一:采用nginx+tomcat部署方案jar方式
后端服务通过JAR方式运行
前端项目build后的静态资源,部署到nginx中
通过jeecg-boot-parent打包项目。
jeecg-boot-module-system作为启动项目。
前台build将生产的文件部署到nginx文件html中
二:nginx+tomcat部署方案war部署
后端服务发布部署到tomcat中
前端项目由于build后都是静态问题,部署到nginx中
pom.xml文件中项目打包格式设置为war | war
pom.xml文件删除插件spring-boot-maven-plugin
增加项目web容器部署的支持:/src/main/java/org/jeecg/JeecgApplication.java 地址,修改如下:
package org.jeecg;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.boot.web.servlet.support.SpringBootServletInitializer;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@SpringBootApplication
@EnableSwagger2
public class JeecgApplication extends SpringBootServletInitializer
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder application)
return application.sources(JeecgApplication.class);
public static void main(String[] args)
SpringApplication.run(JeecgApplication.class, args);
注释掉WebSocket配置:jeecg-boot-module-system/org.jeecg.config.WebSocketConfig
tomcat设置连接编码utf-8
前台build将生产的文件部署到nginx文件html中
三:极简方式部署,采用单体方式
首先前台修改配置,去掉项目名 jeecg-boot:地址|ant-design-jeecg-vue/src/utils/request.js ant-design-jeecg-vue/public/index.html
修改路由History 模式为“hash”,前端:npm run build
将编译的dist文件夹下 部署到后台项目的static目录下
修改控制层初始化跳转页面:jeecg-boot-module-system\\src\\main\\java\\org\\jeecg\\config\\WebMvcConfiguration 地址:index.html
修改后台配置上下文名称
四:分离打包:半自动,可以全自动
将spring-boot-maven-plugin替换成maven-jar-plugin,jar打包
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>启动器类</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
程序打包
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-lib</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>target/lib</outputDirectory>
<excludeTransitive>false</excludeTransitive>
<stripVersion>false</stripVersion>
<includeScope>runtime</includeScope>
</configuration>
</execution>
</executions>
</plugin>
建立lib文件,copy打包的jar
将程序打包的jar部署到统计目录文件下进行执行
建立config文件,放入application.yml文件
一:前台知识点:
二:以下是后台知识点:
enum:定义一个枚举类
注解自定义类:
@Target(ElementType.METHOD)
1、定义注解应用的范围:可以在ElementType文件中查看
2、指定具体的应用范围:在方法上使用
@Retention(RetentionPolicy.RUNTIME):
1、注解的生命周期有三个阶段:1、Java源文件阶段;2、编译到class文件阶段;3、运行期阶段
2、在jvm运行时,得到检测,进行特殊操作
@Documented
1、生成javadoc文档
@interface
1、定义接口关键字
spring:
@Component:将此类注入成一个bean
@value:获取字典值
@Configuration:用于定义配置类,可以包含多个bean
@EnableCaching:开启缓存注解
@Cacheable:方法上,先查询缓存
@CacheEvict:方法上,先查询缓存后,进行及时清理
@Cacheput:方法上,实时更新缓存
@CacheConfig:类上,value标注
@DateTimeFormat:针对时间的入参格式化
@Conditional:该注解是满足此条件才注入bean
@Lazy:延迟加载,减少springIOC容器启动的加载时间
@Resource:是由J2EE导入的,不写name与type属性,则通过自动注入策略。
@Autowired:是由spring导入,该实例必须存在,不允许为null值,如果为null值,则设置required属性为false
@Transactional:为类或者方法加入事务控制,保持ACID
sprinboot:
@ConditionalOnBean // 当给定的在bean存在时,则实例化当前Bean,这个bean可能由于某种原因而没有注册到ioc里,这时@ConditionalOnBean可以让当前bean也不进行注册
@ConditionalOnMissingBean // 当给定的在bean不存在时,则实例化当前Bean,感觉这个是在多态环境下使用,当一个接口有多个实现类时,如果只希望它有一个实现类,那就在各个实现类上加上这个注解
@ConditionalOnClass // 当给定的类名在类路径上存在,则实例化当前Bean
@ConditionalOnMissingClass // 当给定的类名在类路径上不存在,则实例化当前Bean
websocket:
@ServerEndpoint:使用的是tomcat里的注解,还有一种是通过pom的方式注入javax包|也可以使用不同框架的集成包
key-value:value=“url”:服务断点地址
此注解中需要实现一下动作:
1、建立连接:@OnOpen
2、接收消息:@OnMessage
3、关闭连接: @OnClose
4、错误捕获:@OnError
5、存放消息会话:session
工具包:
commons-io包
FileUtils:针对文件的各项封装
IOUtils:针对流的各项操封装
FilenameUtils:针对文件名操作的封装
EndianUtils:暂无用过
StringUtils:字符串工具类
其他工具类:
RegUtil:正则工具类
RandomUtil:随机数的相关的工具类
EmailUtil:Email相关的工具类
DateUtil:日期时间相关的工具类
ClassUtil: Class与反射相关的一些工具类
OssBootUtil:文件云存储工具
RedisUtil:redis工具文件
MD5Util:加解密相关工具
JwtUtil:单点相关封装
Result:接口状态封装
springAOP注解:
@Pointcut:创建一个切点类,改路径下及其子包所有方法进行匹配
@Around:用来在调用一个具体方法前和调用后来完成一些具体的任务
quartz定时包:
@PersistJobDataAfterExecution:Quartz在成功执行了Job实现类的execute方法后,更新JobDetail中JobDataMap的数据
@DisallowConcurrentExecution:禁止并发执行多个相同定义的JobDetail,
jackson包注解:
@JsonIgnore:json组装,需要忽略的字段
@Deprecated:将被弃用,暂时可用,以后不再进行维护
@ApiModelProperty:
1、value()
源码:String value() default “”;
参数类型为String,作用为此属性的简要描述。
2、name()
源码: String name() default “”;
参数类型为String,作用为允许重写属性的名称。
3、allowableValues()
源码:String allowableValues() default “”;
参数类型为String,作用为限制此参数存储的长度。
4、access()
源码:String access() default “”;
参数类型为String,作用为允许从API文档中过滤属性
5、notes()
源码: String notes() default “”;
参数类型为String,作用为该字段的注释说明
6、dataType()
源码: String dataType() default “”;
参数类型为String,作用为参数的数据类型。
7、required()
源码:boolean required() default false;
参数类型为String,作用为指定参数是否可以为空,默认为false
8、 position()
源码:int position() default 0;
参数类型为int,作用为允许显式地对模型中的属性排序。
9、hidden()
源码:boolean hidden() default false;
参数类型为boolean,作用为是否允许模型属性隐藏在Swagger模型定义中,默认为false。
10、example()
源码:String example() default “”;
参数为String类型,作用为属性的示例值。
11、readOnly()
源码:boolean readOnly() default false;
参数类型为boolean,作用为是否允许将属性指定为只读,默认为false。
12、reference()
源码: String reference() default “”;
参数类型为String,作用为指定对对应类型定义的引用,重写指定的任何其他数据名称。
13、allowEmptyValue()
源码:boolean allowEmptyValue() default false;
参数类型为boolean,作用为是否允许传递空值,默认为false
@JsonFormat:@JsonFormat(timezone = “GMT+8”,pattern = “yyyy-MM-dd HH:mm:ss”)在处理返回时间格式的字段加入此格式注解 ,需要GMT+8操作
excel包
https://blog.51cto.com/u_9771070/2722382#_2 地址
@Excel:到Filed 上面,是对Excel一列的一个描述,这个注解是必须要的注解
@ExcelCollection:表示一个集合,主要针对一对多的导出
@ExcelEntity:一个继续深入导出的实体,是作用一个类型为实体的属性上面
@ExcelIgnore:注解修饰的字段,表示在导出的时候不导出
@ExcelTarget:作用于最外层的对象,描述这个对象的id,以便支持一个对象,可以针对不同导出做出不同处理,其作用在实体类的上
@ExcelVerify:暂无资料
lombok包下的注解:
@Data : 注在类上,提供类的get、set、equals、hashCode、canEqual、toString方法
@AllArgsConstructor : 注在类上,提供类的全参构造
@NoArgsConstructor : 注在类上,提供类的无参构造
@Setter : 注在属性上,提供 set 方法
@Getter : 注在属性上,提供 get 方法
@EqualsAndHashCode: 注在类上,提供对应的 equals 和 hashCode 方法.
参数列:callSuper=false,不继承父类的方法,callSuper=true,继承父类的方法
不同的地方:不继承不会调用父类的equals和hashcode,继承的话,生成的代码中会加入一层父类equals和hashcode的判断。
@Log4j/@Slf4j : 注在类上,提供对应的 Logger 对象,变量名为 log
@Accessors:
例子:@Accessors(chain = true) | @Accessors(fluent = false)|@Accessors(prefix = ‘p’)
fluent: 一个布尔值。如果为true,则 getter forpepper是 just pepper(),而 setter 是pepper(T newValue)。
chain: 一个布尔值。如果为true,则生成的 setter 返回this而不是void。
prefix: 字符串列表。如果存在,字段必须以这些前缀中的任何一个作为前缀。每个字段名称依次与列表中的每个前缀进行比较,如果找到匹配项,则去除前缀以创建字段的基本名称。
@TableId:表id指定名称
tomcat优化:
1、连接优化
参数详解:
1、 protocol:协议类型,可选类型有4种,BIO(阻塞型IO),NIO,NIO2和APR。
BIO(Blocking I/O) 阻塞式I/O操作,传统的Java I/O操作(即java.io包及其子包)。
NIO(New I/O)是Java SE 1.4及后续版本提供的一种新的I/O操作方式(即java.nio包及其子包)。
2、executor:Executor元素必须出现在server.xml中的Connector配置元素之前,引用此池的名称,名称必须唯一
3、maxHttpHeaderSize:请求和响应的HTTP头的最大大小,以字节为单位指定。如果没有指定,这个属性被设置为8192(8 KB)
4、maxThreads:连接器创建处理请求线程的最大数目 默认200
5、minSpareThreads:线程的最小运行数目 默认10
6、maxConnections:在任何给定的时间内,服务器将接受和处理的最大连接数。当这个数字已经达到时,服务器将接受但不处理,等待进一步连接。
7、enableLookups: 关闭DNS反向查询。
8、compression:是否启用gzip压缩,默认为关闭状态。off:不使用压缩。on:压缩文本数据force:任何情况下强制压缩
9、compressionMinSize:依赖compression="on"的配置,on则启用此项。设置被压缩最小值,超过后才被压缩,默认2k
10、compressableMimeType
11、connectionTimeout:当请求已经被接受,但未被处理,也就是等待中的超时时间。默认值为60000
12、acceptCount:最大队列长度 默认为100
13、redirectPort:重定向端口
14、tcpNoDelay:如果为true,服务器socket会设置TCP_NO_DELAY选项,在大多数情况下可以提高性能。默认为true
15、disableUploadTimeout:给servlet更长的时间。比如上传文件,默认false
16、URIEncoding:URL编码字符集。
2、配置线程池
参数:
name:线程池名称
namePrefix:执行程序创建的每个线程的名称前缀。格式:namePrefix+threadNumber
maxThreads:线程的最大数量,默认为 200
minSpareThreads:最小线程数,默认25
maxIdleTime:空闲线程关闭之前的毫秒数,满足最小线程数,默认值为60000(1分钟)
prestartminSpareThreads:是否应该在启动Executor时启动minSpareThreads,默认值为 false
threadPriority:执行程序中线程的线程优先级,默认为 5
className:实现的类。默认org.apache.catalina.core.StandardThreadExecutor
daemon:线程是否是守护程序线程。默认为true
maxQueueSize:在我们拒绝之前可以排队等待执行的可运行任务的最大数量。默认值是Integer.MAX_VALUE
threadRenewalDelay:如果配置了ThreadLocalLeakPreventionListener,它将通知此执行程序有关已停止的上下文。
nginx:
1、静态资源的压缩:gzip
server
listen 80; //监听端口
server_name localohst; //监听域名
gzip on; //开启gzip压缩
gzip_min_length 1k; //最小的长度,1K,文件如果太小,小于1K,就不会压缩,因为没准压缩之后还要变大
gzip_buffers 4 16k; //设置缓存的单位,压缩的时候要分配的缓冲区,缓冲区以16K为单位,往缓冲区写入内容的时候超过16K的时候,那么就会按照4倍的大小创建新的缓冲区,也就是建立一个64K的存储,这样把压缩的内容倒进去
gzip_comp_level 6; //压缩级别1-9,比如level为1的话,压缩的比例比较低,但是效率比较高,比如100K的文件压缩之后还剩40K或者50K,但是处理的时间很短;如果level为9的话,压缩的效果最好,效率会低一点,比如还是100K的文件,压缩的会更小,甚至20K ,这样对cpu消耗会高点,一般设置中间差不多
gzip_type text/plain application/javascript text/css application/xml; //定义了压缩的类型,比如文本的,js、css等文本文件压缩,像是图片啊,就没必要定义了,本身就支持,这里就不需要定义了,默认压缩text/html 不需要指定,否则报错
location /
root /var/www/a.com; //根目录定位
index index.html;
JVM优化:
jvm目标:
GC的时间足够的小
GC的次数足够的少
发生Full GC的周期足够的短
根据物理机的比例配比
整个堆的大小=年轻代大小 + 年老代大小 + 持久代大小。堆的最大值和最小值设置一样,可以预防抖动
Young:年轻代 1
-Xmn:2G
1、新生区(Eden)
2、幸存区S0(survivor#0)
3、幸存区S1(survivor#1)
Tenured:年老代 2
Perm:永久代,jdk1.8开始替换永久代为元空间,采用将虚拟机转换到本地内存
永久代设置:
-XX:PermSize:初始空间
-XX:MaxPermSize:最大空间
元空间设置:
-XX:MetaspaceSize=N
-XX:MaxMetaspaceSize=N
合并的原因:
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
4、Oracle 可能会将HotSpot 与 JRockit 合二为一。
2、jvm调优工具
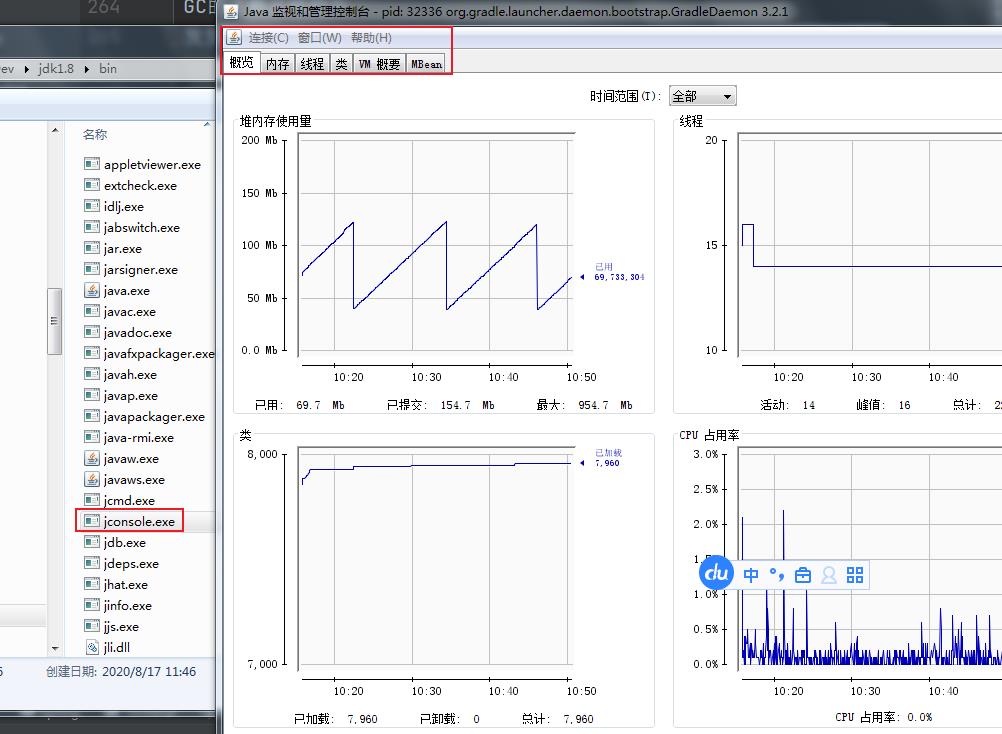
一:JConsole.exe:是一款基于 JMX(Java Manage-ment Extensions) 的可视化监视、管理工具。它的主要功能是通过 JMX 的 MBean(Managed Bean) 对系统进行信息收集和参数动态调整。
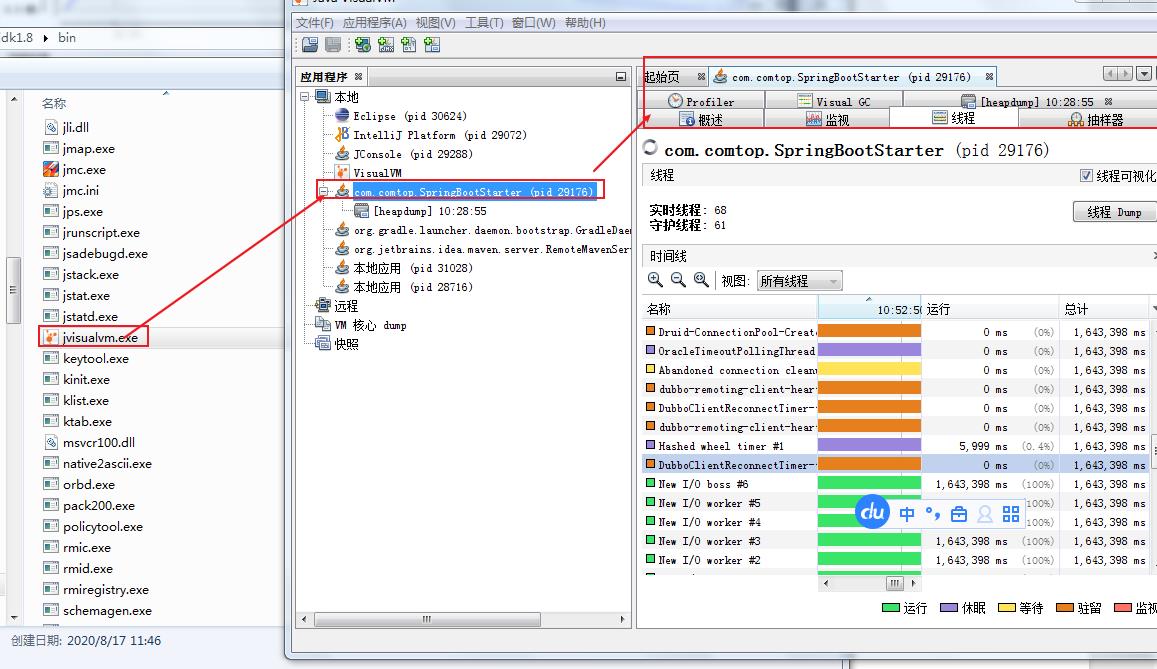
二: jvisualvm.exe:是功能最强大的运行监视和故障处理程序之一,曾经在很长一段时间内是 Oracle 官方主力发展的虚拟机故障处理工具。
三: Java Mission Control(jmc.exe):
jmc面板中:一个是 MBean ,一个是 JFR 飞行记录器。
Mbean:这里的信息跟Jconsole和jvisualvm控制台一样内容。
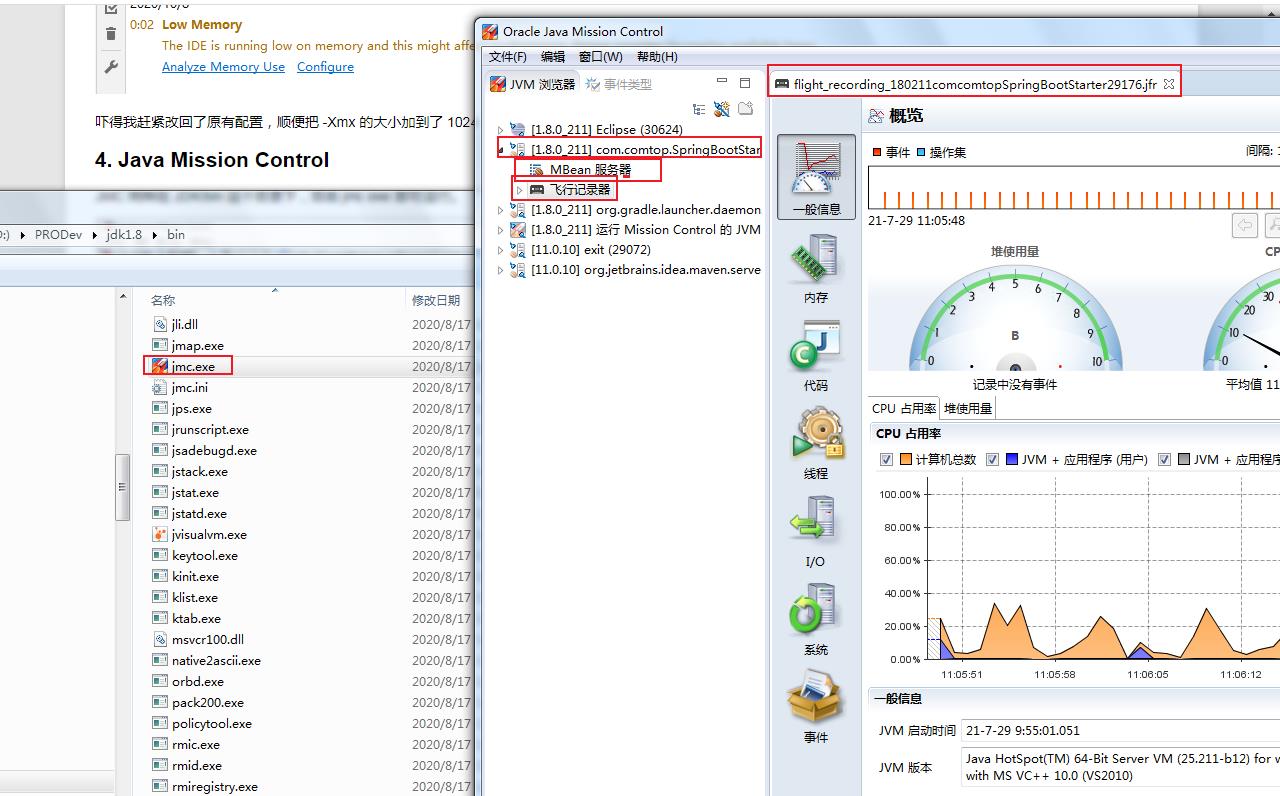
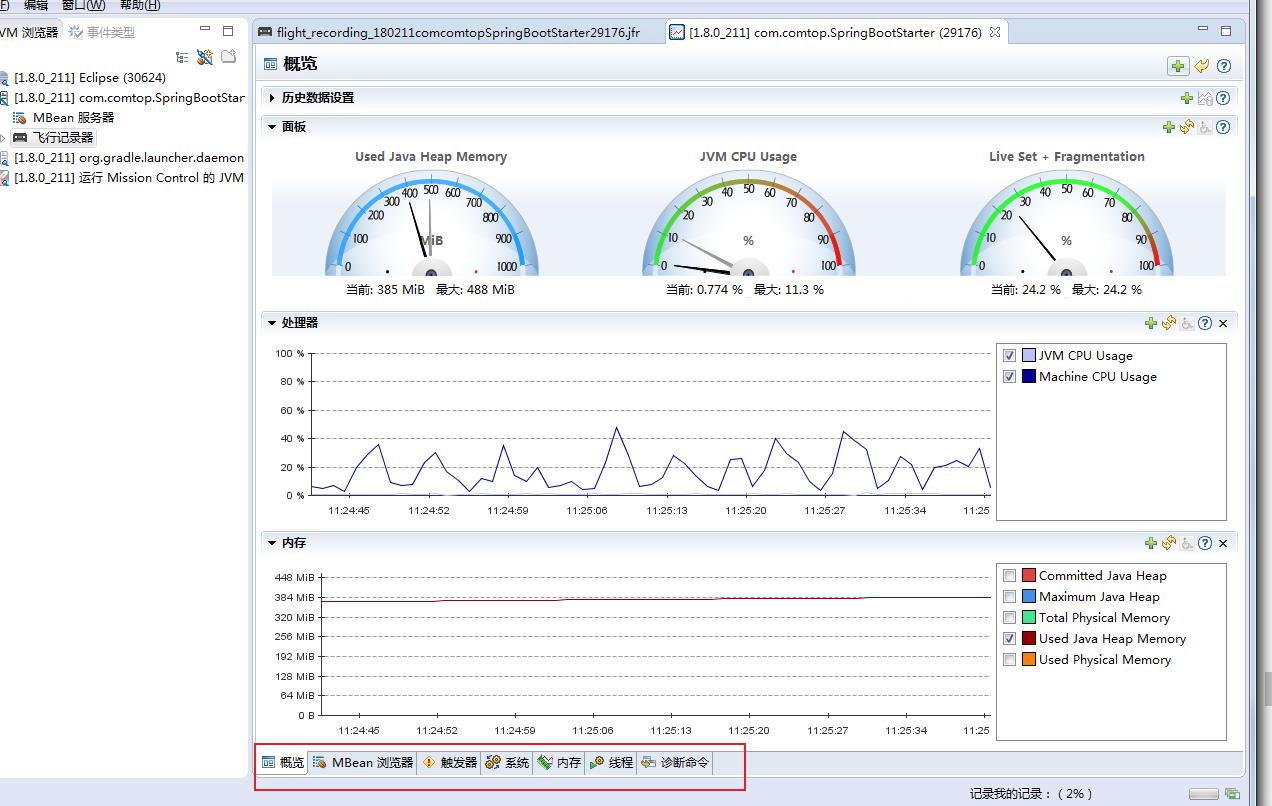
飞行记录报告里包含以下几类信息:
一般信息:关于虚拟机、操作系统和记录的一般信息。
内存:关于内存管理和垃圾收集的信息。
代码:关于方法、异常错误、编译和类加载的信息。
线程:关于应用程序中线程和锁的信息。
I/O:关于文件和套接字输入、输出的信息。
系统:关于正在运行Java虚拟机的系统、进程和环境变量的信息。
事件:关于记录中的事件类型的信息,可以根据线程或堆栈跟踪,按照日志或图形的格式查看。
3、jvm参数调优
1、初始大小的堆内存:为物理内存的64分之一
2、线内存:默认1M
3、-server:新生代GC方式并行 旧生代和持久代GC的方式并发
4、-Xss:每个线程的堆栈大小。默认1M
5、-XX:+UseParallelGC 并行垃圾回收器(默认)针对于年轻代
6、-XX:MaxGCPauseMillis 设置每次年轻代垃圾回收的最长时间
7、-XX:+UseAdaptiveSizePolicy:自动选择年轻代区大小和相应的Survivor区比例,达到系统的目标时间和收集频率。
8、
9、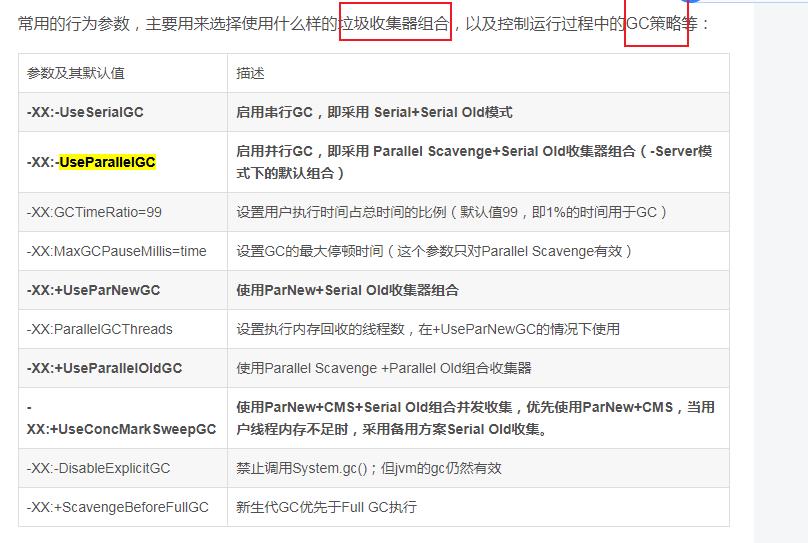
:GC参数
GC搭配+回收算法:
Serial收集器:新生代收集器,使用复制算法,使用一个线程进行GC,串行,其它工做线程暂停。
ParNew收集器:新生代收集器,使用复制算法,Serial收集器的多线程版,用多个线程进行GC,并行,其它工做线程暂停。使用-XX:+UseParNewGC开关来控制使用ParNew+Serial Old收集器组合收集内存;使用-XX:ParallelGCThreads来设置执行内存回收的线程数。
Parallel Scavenge 收集器:吞吐量优先的垃圾回收器,做用在新生代,使用复制算法,关注CPU吞吐量,即运行用户代码的时间/总时间。使用-XX:+UseParallelGC开关控制使用Parallel Scavenge+Serial Old收集器组合回收垃圾。
Serial Old收集器:老年代收集器,单线程收集器,串行,使用标记整理算法,使用单线程进行GC,其它工做线程暂停。
Parallel Old收集器:吞吐量优先的垃圾回收器,做用在老年代,多线程,并行,多线程机制与Parallel Scavenge差不错,使用标记整理算法,在Parallel Old执行时,仍然须要暂停其它线程。
CMS(Concurrent Mark Sweep)收集器:老年代收集器,致力于获取最短回收停顿时间(即缩短垃圾回收的时间),使用标记清除算法,多线程,优势是并发收集(用户线程能够和GC线程同时工做),停顿小。使用-XX:+UseConcMarkSweepGC进行ParNew+CMS+Serial Old进行内存回收,优先使用ParNew+CMS(缘由见Full GC和并发垃圾回收一节),当用户线程内存不足时,采用备用方案Serial Old收集。
1.8默认:
-XX:+UseParallelGC 并行垃圾回收器(默认)
-XX:+UseSerialGC 串行垃圾回收器
4、jvm调优步奏
1,监控GC的状态
使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化;
2,分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化;如果GC时间超过1-3秒,或者频繁GC,则必须优化;
注:如果满足下面的指标,则一般不需要进行GC:
Minor GC执行时间不到50ms;
Minor GC执行不频繁,约10秒一次;
Full GC执行时间不到1s;
Full GC执行频率不算频繁,不低于10分钟1次;
3,调整GC类型和内存分配
如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择;
4,不断的分析和调整
通过不断的试验和试错,分析并找到最合适的参数
5,全面应用参数
如果找到了最合适的参数,则将这些参数应用到所有服务器,并进行后续跟踪。
5、需要优化配置场景
1、现OOM内存溢出
调整初始堆大小和年轻代堆大小
2、系统经常卡顿,full gc 过长
调整年轻代和年老代比例
3、内存占用率高,full gc频繁
优化程序代码
分析几个系统所用的jvm配置:
一:weblogic 12c
/data/jdk1.8.0_221/bin/java
-server
-Xms4096m
-Xmx4096m
-Xss300k
-Dweblogic.Name=wdms_operationpvm
-Djava.security.policy=/data/wls1213/Oracle_Home/wlserver/server/lib/weblogic.policy
-Dweblogic.ProductionModeEnabled=true
-Dweblogic.security.SSL.trustedCAKeyStore=/data/wls1213/Oracle_Home/wlserver/server/lib/cacerts
-Djava.endorsed.dirs=/data/jdk1.8.0_221/jre/lib/endorsed:/data/wls1213/Oracle_Home/wlserver/…/oracle_common/modules/endorsed
-da
-Dwls.home=/data/wls1213/Oracle_Home/wlserver/server
-Dweblogic.home=/data/wls1213/Oracle_Home/wlserver/server
-Dweblogic.management.server=http://10.10.6.168:9000
-Dweblogic.utils.cmm.lowertier.ServiceDisabled=true
-XX:+HeapDumpOnOutOfMemoryError
Headless模式是系统的一种配置模式。在系统可能缺少显示设备、键盘或鼠标这些外设的情况下可以使用该模式。
-Djava.awt.headless=true
Weblogic管理服务
-Dsun.zip.disableMemoryMapping=true
G1垃圾回收模式
-XX:+UseG1GC
-XX:MaxGCPauseMillis=50
-XX:GCPauseIntervalMillis=200
weblogic.Server
二:不同GC参数
CMS常用参数
- -XX:+UseConcMarkSweepGC
- -XX:ParallelCMSThreads
CMS线程数量 - -XX:CMSInitiatingOccupancyFraction
使用多少比例的老年代后开始CMS收集,默认是68%(近似值),如果频繁发生SerialOld卡顿,应该调小,(频繁CMS回收) - -XX:+UseCMSCompactAtFullCollection
在FGC时进行压缩 - -XX:CMSFullGCsBeforeCompaction
多少次FGC之后进行压缩 - -XX:+CMSClassUnloadingEnabled
- -XX:CMSInitiatingPermOccupancyFraction
达到什么比例时进行Perm回收 - GCTimeRatio
设置GC时间占用程序运行时间的百分比 - -XX:MaxGCPauseMillis
停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代
G1常用参数
- -XX:+UseG1GC
- -XX:MaxGCPauseMillis
建议值,G1会尝试调整Young区的块数来达到这个值 - -XX:GCPauseIntervalMillis
GC的暂停间隔目标 - -XX:+G1HeapRegionSize
分区大小,建议逐渐增大该值,1 2 4 8 16 32。
随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长
ZGC做了改进(动态区块大小) - G1NewSizePercent
新生代最小比例,默认为5% - G1MaxNewSizePercent
新生代最大比例,默认为60% - GCTimeRatio
GC时间建议比例,G1会根据这个值调整堆空间 - ConcGCThreads
线程数量 - InitiatingHeapOccupancyPercent
启动G1的堆空间占用比例
rocketmq 配置
程序架构优化:
redis优化配置:
sql服务器配置文件优化
C时间占用程序运行时间的百分比
- -XX:MaxGCPauseMillis
停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代
G1常用参数
- -XX:+UseG1GC
- -XX:MaxGCPauseMillis
建议值,G1会尝试调整Young区的块数来达到这个值 - -XX:GCPauseIntervalMillis
GC的暂停间隔目标 - -XX:+G1HeapRegionSize
分区大小,建议逐渐增大该值,1 2 4 8 16 32。
随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长
ZGC做了改进(动态区块大小) - G1NewSizePercent
新生代最小比例,默认为5% - G1MaxNewSizePercent
新生代最大比例,默认为60% - GCTimeRatio
GC时间建议比例,G1会根据这个值调整堆空间 - ConcGCThreads
线程数量 - InitiatingHeapOccupancyPercent
启动G1的堆空间占用比例
以上是关于jeecg项目学习(开源项目持续学习)的主要内容,如果未能解决你的问题,请参考以下文章