Binder机制(一)
Posted xuguoli_beyondboy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Binder机制(一)相关的知识,希望对你有一定的参考价值。
binder的介绍:
由于不同的进程不可以直接互相访问,所以需要一些机制来确保进程间能够通信,在linxu中,有以下几种:
1.管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
2.信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
3.报文(Message)队列(消息队列):消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
4.共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
5.信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
6.套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
上面几点来源于:https://www.ibm.com/developerworks/cn/linux/l-ipc/
基于上面的各种机制及手机的应用场景,安卓采用binder机制来实现进程间的共享机制。
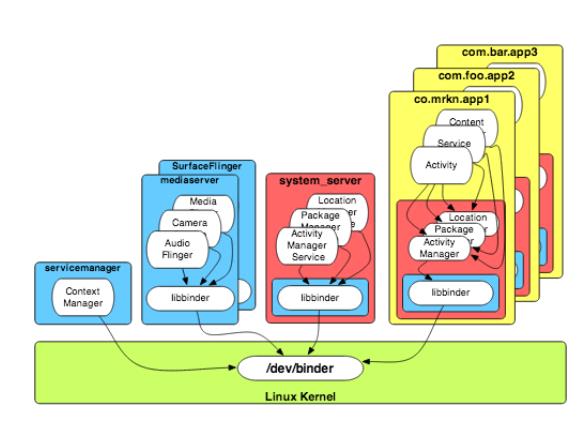
根据(Aleksandar Gargenta)描述,安卓出于安全性、稳定性和内存管理的目的,android的应用和系统服务需要运行在分离的进程中,但是它们之间需要通讯和共享数据,但同时也要满足以下几点:
- 安全性:每一个进程就是一个沙盒,运行在一个不同的系统标识中。
- 稳定性:如果一个进程失常(例如:崩溃),它不影响其它的进程。
- 内存管理:“不需要”的进程会被移除,为新的释放资源(主要是内存)。
- 事实上,一个单独的Android应用可以让它的组件运行在不同的进程中。
那安卓为什么会采用binder机制,而不用其他的机制呢?那就是基于binder机制以下几点: - 线程迁移:远程对象可以像本地的一样调用自动管理线程池方法;“跳转”到其它的进程中;同步和异步(单向)的调用模式。
- 分辨发送者和接受者(通过UID/PID)- 对于安全很重要。
- 独特的跨进程边界对象映射。
- 一个远程对象的引用可以传递到的另外的进程中,并且可以用作一个标志令牌。
- 各个进程之间发送文件描述符的能力。
- 简单的Android接口定义语言(AIDL)。
- 内置支持很多编组的常见数据类型。
- 通过自动生成的代理和存根简化事务调用模型(只有Java)。
- 跨进程递归 – 例如:当调用本地对象上的方法时就跟递归的语义一样。
- 如果客户端和服务器运行在同样的进程中,就会是本地执行模式(不是IPC数据信号编集)。
不过binder也存在以下的缺陷: - 不支持RPC(只有本地).
- 客户端与服务之间是基于消息的通信 – 不适合流.
- 没有被POSIX或任何其他标准定义.
binder的初步分析:
采用binder驱动协议,其客户端(binder client)和服务器端(binder sever)进程间通信的过程,大概如图:
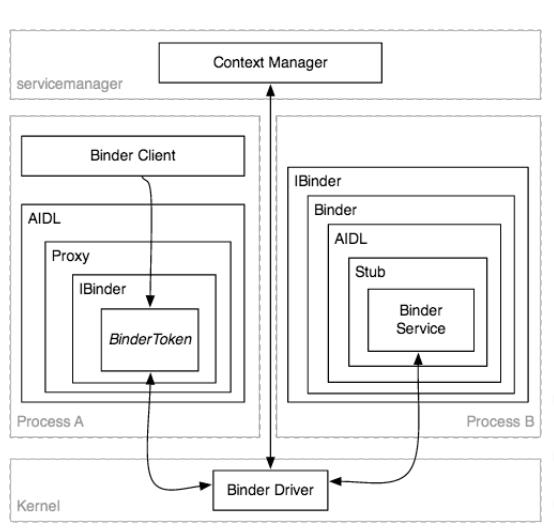
其术语如下:
Binder (Framework):所有的IPC架构。
Binder Driver:内核级别的驱动,处理各个进程之间的通信。
Binder Protocol:底层协议(基于ioctl),用于与Binder驱动通信。
IBinder Interface:定义良好的行为(例如:方法),Binder对象必须实现。
AIDL:Android接口定义语言,用于描述IBinder接口的业务操作。
Binder (Object):通用IBinder接口的实现。
Binder Token:一个抽象的32位数值,在系统的所有进程中唯一的标识一个Binder对象.
Binder Service:真正实现Binder(对象)的业务操作.
Binder Client:一个对象,使用Binder服务提供的行为.
Binder Transaction:远程Binder对象调用一个行为(例如:一个方法),基于Binder协议,可能涉及发送、接受的数据.
Parcel:”可以在IBinder中发送消息的容器(数据和对象的引用)”,事务处理的数据单元——一个用作流出请求,另一个用作流入.
Marshalling:将高级的应用程序数据结构(例如:请求、响应参数)转化成parcel对象的过程,目的是将它们嵌套进Binder的事务中.
Unmarshalling:将Binder事务中获取到的parcel对象重构成高级应用的数据结构的过程(例如:请求、响应参数).
Proxy:一个AIDL接口的实现,编组、解组数据,映射调用事务的方法,将一个封装的IBinder引用指向Binder对象.
Stub:一个AIDL接口局部的实现,当编组/解组数据时,映射事务到Binder Service调用.
Context Manager:一个特殊的已知处理的Binder对象,被用作为其它Binder注册、查询.
从上次写的内存管理了解到,用内存映射可以提高文件传输效率,具体介绍可以参考下面的博客:
http://blog.csdn.net/xuguoli_beyondboy/article/details/50153145
android系统中,我们常常需要获得由servicemanager管理的系统服务如:WindowService,WiFiService等等,但从上面我们了解到应用程序和服务是独立在各个进程运行,因此应用程序肯定要频繁发送数据给服务或从服务得到数据,由于是不同进程的通讯,其应用程序不能直接访问服务数据,因此android用基于binder驱动的内存映射方式来实现这效果并且提高效率,其数据通信如图:
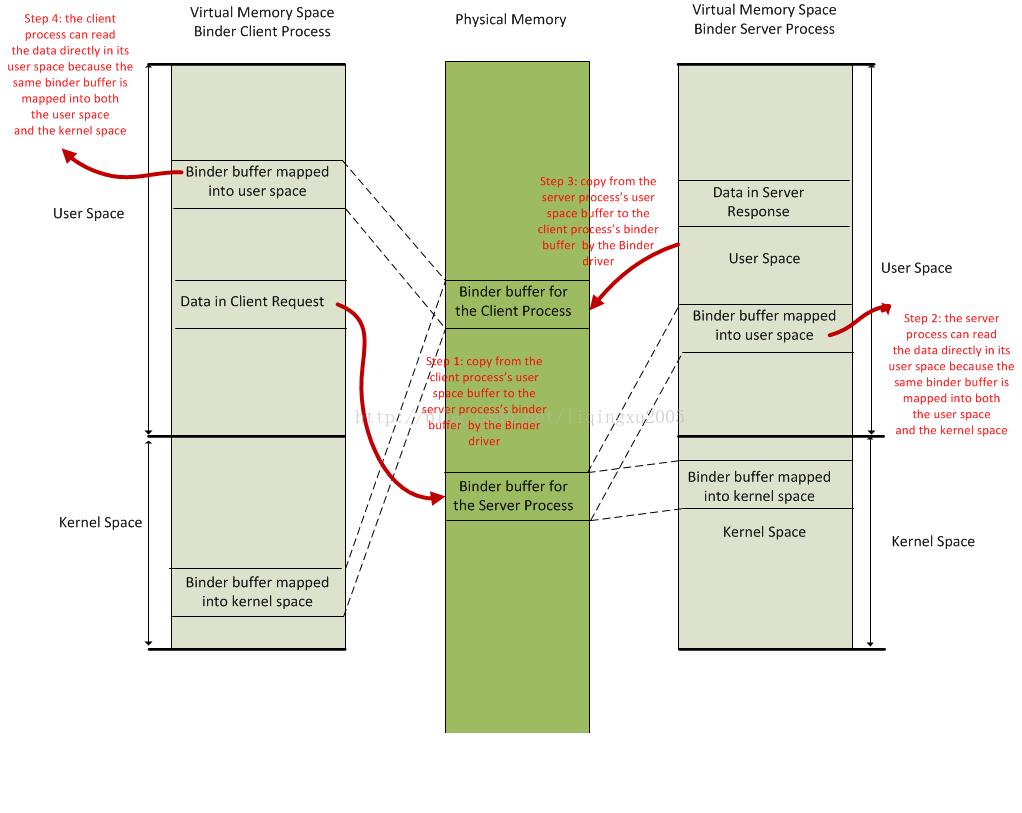
拷贝过程:
1. Client将数据从用户空间传输到Binder驱动;
2. Binder驱动将第1步得到的数据拷贝到Service通过mmap申请得到的那块物理空间;
3. Binder驱动将第2步得到的物理空间对应的虚拟地址传递给Service的用户空间;
4. Service的用户空间通过Binder驱动传递过来的虚拟地址来访问Client传输过来的数据。
注:整个过程只有第2步是需要拷贝数据的,这也是Binder进程间通信机制的精华所在。
这样只对数据进行一次拷贝就完成了进程间的数据交换,从而大大了提高了客户端和服务端的数据交互效率。
Linux中的字符设备通常要经过alloc_chrdev_region(),cdev_init()等一系列操作才能在内核中注册自己,而misc类型驱动则相对简单,只需要调用misc_register()就可以轻松解决。
binder.c(\\common\\drivers\\android\\binder.c)与驱动相关的源码:
static struct miscdevice binder_miscdev =
//动态分配次设备号
.minor = MISC_DYNAMIC_MINOR,
.name = "binder",//驱动名称
.fops = &binder_fops//Binder驱动支持的文件操作
;
//binder提供给上层应用操作文件的接口
static const struct file_operations binder_fops =
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,//IO设备操作管理
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
;当上层进层在访问Binder驱动时,首先就需要打开/dev/binder节点,这个操作最终的实现是在binder_open()中。
源码:
//Binder驱动为用户创建一个它自己的binder_proc实体,之后用户对Binder设备的操作将以这个对象为基础
static int binder_open(struct inode *nodp, struct file *filp)
struct binder_proc *proc;
binder_debug(BINDER_DEBUG_OPEN_CLOSE, "binder_open: %d:%d\\n",
current->group_leader->pid, current->pid);
proc = kzalloc(sizeof(*proc), GFP_KERNEL);//分配空间
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo);//进程任务链表
init_waitqueue_head(&proc->wait);//进程等待链表
proc->default_priority = task_nice(current);//初始化优先级
binder_lock(__func__);//获取锁
binder_stats_created(BINDER_STAT_PROC);//binder_stats是binder中的统计载体数据载体
hlist_add_head(&proc->proc_node, &binder_procs);//将proc加入到binder_procs的队列头部
proc->pid = current->group_leader->pid;//进程ID
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;//将这个proc与filp关联起来,这样下次通过filp就能找到这个proc
binder_unlock(__func__);//解除锁
if (binder_debugfs_dir_entry_proc)
char strbuf[11];
snprintf(strbuf, sizeof(strbuf), "%u", proc->pid);
proc->debugfs_entry = debugfs_create_file(strbuf, S_IRUGO,
binder_debugfs_dir_entry_proc, proc, &binder_proc_fops);
return 0;
初始化完成之后,就需要把一块拿来共享的内存块映射到用户进程中,其函数是mmap(),它会返回指向该块内存的虚拟地址,关于虚拟地址和物理地址转换,可以参考我之前写的一篇博客:
http://blog.csdn.net/xuguoli_beyondboy/article/details/50153145
源码:
//内存映射
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
int ret;
struct vm_struct *area;//内核的虚拟地址,而vm_area_struct *vma表示用户的虚拟地址
struct binder_proc *proc = filp->private_data;//进程结构体
const char *failure_string;//失败字符记录
struct binder_buffer *buffer//它表示要映射的物理内存在内核空间的起始位置
if (proc->tsk != current)
return -EINVAL;
//最大虚拟内存为4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
binder_debug(BINDER_DEBUG_OPEN_CLOSE,
"binder_mmap: %d %lx-%lx (%ld K) vma %lx pagep %lx\\n",
proc->pid, vma->vm_start, vma->vm_end,
(vma->vm_end - vma->vm_start) / SZ_1K, vma->vm_flags,
(unsigned long)pgprot_val(vma->vm_page_prot));
//是否禁止了mmap
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS)
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);//获取锁
//判断进程是否做过映射
if (proc->buffer)
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
//获取空闲的物理内存映射到内核的虚拟地址
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL)
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
proc->buffer = area->addr;//映射后的虚拟地址
//它表示的是内核使用的虚拟地址与进程使用的虚拟地址之间的差值,即如果某个物理页面在内核空间中对应的虚拟地址是addr的话,
//那么这个物理页面在进程空间对应的虚拟地址就为addr + user_buffer_offset。
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
#ifdef CONFIG_CPU_CACHE_VIPT
if (cache_is_vipt_aliasing())
while (CACHE_COLOUR((vma->vm_start ^ (uint32_t)proc->buffer)))
pr_info("binder_mmap: %d %lx-%lx maps %p bad alignment\\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer);
vma->vm_start += PAGE_SIZE;
#endif
//仅分配页page数组的空间
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL)
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
//来为虚拟地址空间分配一个空闲的物理页内存
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma))
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
//将内核和用户进程虚拟内存联系起来
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
//插入到已经维护已经被分配的列表中
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;//此内存可用
//插入到维护空闲物理内存的红黑树中
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
err_alloc_small_buf_failed:
kfree(proc->pages);
proc->pages = NULL;
err_alloc_pages_failed:
mutex_lock(&binder_mmap_lock);
vfree(proc->buffer);
proc->buffer = NULL;
err_get_vm_area_failed:
err_already_mapped:
mutex_unlock(&binder_mmap_lock);
err_bad_arg:
pr_err("binder_mmap: %d %lx-%lx %s failed %d\\n",
proc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
//分配物理内存,映射到内核和用户进程的虚拟地址中
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
void *page_addr;//物理内存页地址
unsigned long user_page_addr;//用户页的虚拟地址
struct vm_struct tmp_area;//内核的虚拟地址
struct page **page;//指向物理页的页指针
struct mm_struct *mm;
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: %s pages %p-%p\\n", proc->pid,
allocate ? "allocate" : "free", start, end);
if (end <= start)
return 0;
trace_binder_update_page_range(proc, allocate, start, end);
if (vma)
mm = NULL;
else
mm = get_task_mm(proc->tsk);
if (mm)
down_write(&mm->mmap_sem);
vma = proc->vma;
if (vma && mm != proc->vma_vm_mm)
pr_err("%d: vma mm and task mm mismatch\\n",
proc->pid);
vma = NULL;
if (allocate == 0)
goto free_range;
if (vma == NULL)
pr_err("%d: binder_alloc_buf failed to map pages in userspace, no vma\\n",
proc->pid);
goto err_no_vma;
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE)
int ret;
struct page **page_array_ptr;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
//分配页的物理空间
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
if (*page == NULL)
pr_err("%d: binder_alloc_buf failed for page at %p\\n",
proc->pid, page_addr);
goto err_alloc_page_failed;
//初始化内核的虚拟地址及将物理内存映射到内核的虚拟地址
tmp_area.addr = page_addr;
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */;
page_array_ptr = page;
ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr);
if (ret)
pr_err("%d: binder_alloc_buf failed to map page at %p in kernel\\n",
proc->pid, page_addr);
goto err_map_kernel_failed;
//将物理内存映射到用户进程的虚拟地址
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
ret = vm_insert_page(vma, user_page_addr, page[0]);
if (ret)
pr_err("%d: binder_alloc_buf failed to map page at %lx in userspace\\n",
proc->pid, user_page_addr);
goto err_vm_insert_page_failed;
/* vm_insert_page does not seem to increment the refcount */
if (mm)
up_write(&mm->mmap_sem);
mmput(mm);
return 0;
free_range:
for (page_addr = end - PAGE_SIZE; page_addr >= start;
page_addr -= PAGE_SIZE)
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
if (vma)
zap_page_range(vma, (uintptr_t)page_addr +
proc->user_buffer_offset, PAGE_SIZE, NULL);
err_vm_insert_page_failed:
unmap_kernel_range((unsigned long)page_addr, PAGE_SIZE);
err_map_kernel_failed:
__free_page(*page);
*page = NULL;
err_alloc_page_failed:
;
err_no_vma:
if (mm)
up_write(&mm->mmap_sem);
mmput(mm);
return -ENOMEM;
这节初步介绍用户进程和内核是如何共享一块物理内存,这也大概了解用户进程如何和数据内核交互数据。
参考资料:
http://blog.csdn.net/Luoshengyang/article/details/6621566
http://events.linuxfoundation.org/images/stories/slides/abs2013_gargentas.pdf
https://www.ibm.com/developerworks/cn/linux/l-ipc/
以上是关于Binder机制(一)的主要内容,如果未能解决你的问题,请参考以下文章