爬取4k图片
Posted 学好编程不秃头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取4k图片相关的知识,希望对你有一定的参考价值。
爬虫xpath爬取4k壁纸图片
第一步先安装lxml的依赖库
pip install lxml ‐i https://pypi.douban.com/simple
https://pypi.douban.com/simple通过国内镜像下载可以加速
创建一个python文件
引入 etree
from lxml import etree
爬取的网站为: [https://pic.netbian.com/4kdongman/]

先学习一些xpath的基础语法
etree.parse() 解析本地文件
etree.html() 服务器响应文件
先获得页面的源码响应
base_url = "https://pic.netbian.com/4kdongman/" #要访问的基础页面(即第一页)
headers =
'user-agent':"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"
#ua伪装防止反爬
request = urllib.request.Request(url=base_url,headers=headers) #创建一个request的对象

向页面发送请求
response = urllib.request.urlopen(request)
content = response.read().decode('gbk') #由于页面为gbk则我们也解码为gbk
print(content) #获得页面的源码
通过etree.HTML()对页面进行解析
tree = etree.HTML(content)
最后在tree.xpath(“xpath表达式”)
//div[@class='slist']/ul/li/a/img/@alt
完整代码如下
from lxml import etree
import urllib.request
# https://pic.netbian.com/4kdongman/index_2.html
def create_request(page):
base_url = "https://pic.netbian.com/4kdongman/"
if page == 1:
url = base_url
else:
url = base_url + "index_" + str(page) + ".html"
headers =
'user-agent': "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('gbk')
return content
# https: // pic.netbian.com
def upload_data(content):
tree = etree.HTML(content)
name_list = tree.xpath("//div[@class='slist']/ul/li/a/img/@alt")
src_List = tree.xpath("//div[@class='slist']/ul/li/a/img/@src")
# print(src_List)
for i in range(len(name_list)):
src = src_List[i]
src = "https://pic.netbian.com" + src
filename = './picture/' + name_list[i] + ".jpg"
urllib.request.urlretrieve(url=src, filename=filename)
if __name__ == '__main__':
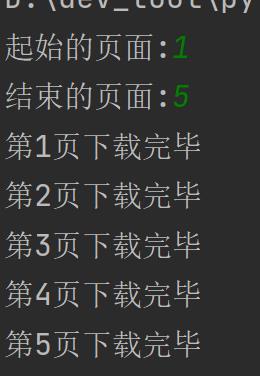
page_start = int(input("起始的页面:"))
end_start = int(input("结束的页面:"))
for page in range(page_start, end_start + 1):
request = create_request(page)
content = get_content(request)
# 解析下载数据
upload_data(content)
print("第"+str(page)+"页下载完毕")
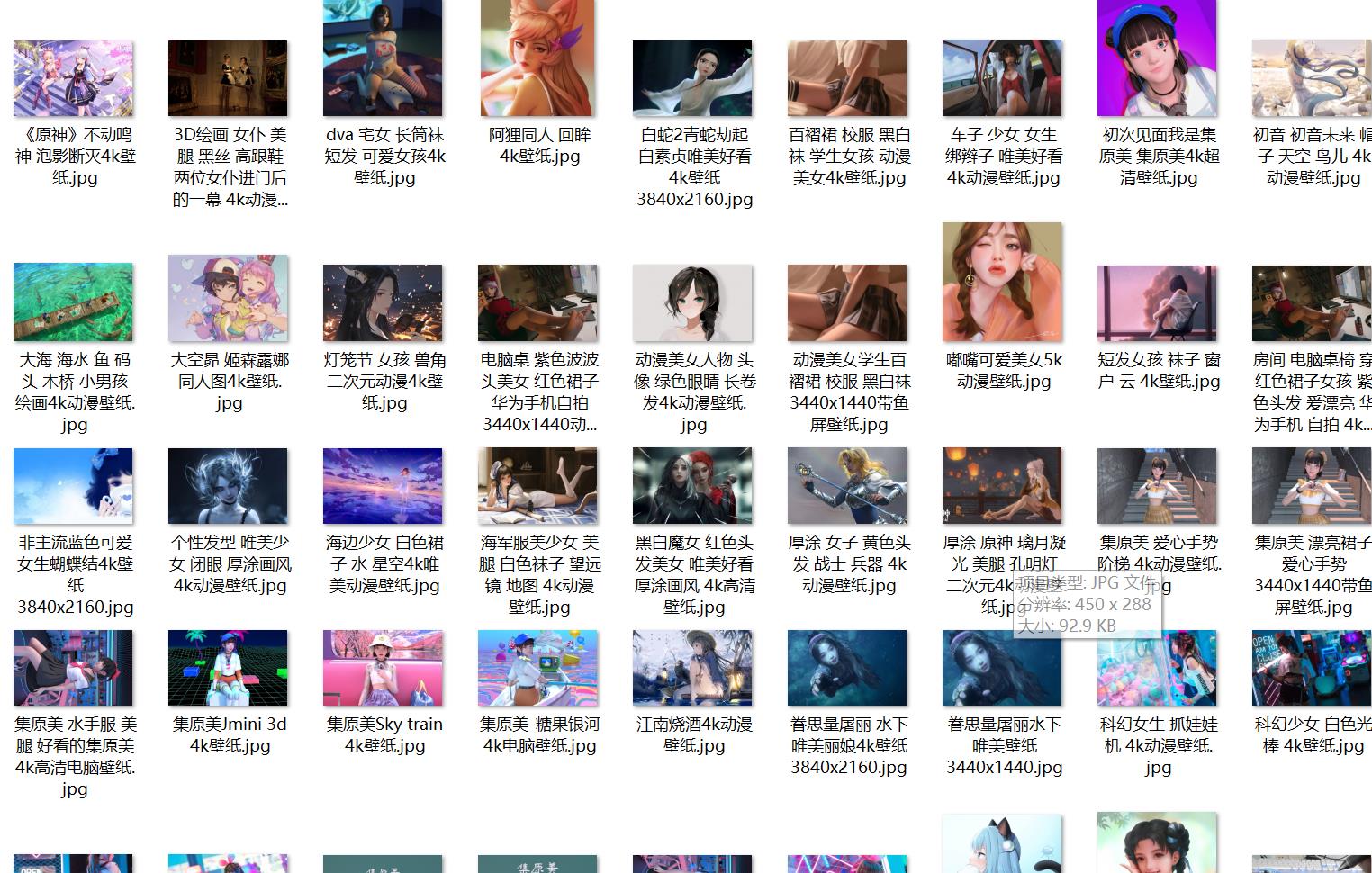
到这我们就可以发现图片已经下载完成了
以上是关于爬取4k图片的主要内容,如果未能解决你的问题,请参考以下文章