Spark Streaming实时流处理项目实战Spark Streaming整合Flume实战二
Posted 怒上王者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming实时流处理项目实战Spark Streaming整合Flume实战二相关的知识,希望对你有一定的参考价值。
Spark Streaming整合Flume实战二
基于拉方式:Pull-based Approach using a Custom Sink
Spark Streaming 基于拉方式处理 Flume-ng 数据源(Pull-based Approach using a Custom Sink)
这种方式不是 Flume 直接推送数据到 SparkStreaming ,这种方法运行了一个如下所示的 Flume Sink 。
- Flume 将数据推送到 Sink 中,然后数据在此处缓存。
- Spark Streaming 使用一个可靠的 Flume 接收器和事务从 Sink 中拉取数据。只有在 SparkStreaming 接收到数据并且把数据复制后才认为操作成功。
这个方法比前面Push的方法提供了强大的可靠性和容错保证。然而,这需要配置 Flume 运行一个自定义 Sink 。
官网链接:https://spark.apache.org/docs/2.2.0/streaming-flume-integration.html
配置步骤
1. 一般要求
选择一台在 Flume 代理中运行自定义 Sink 的机器。 Flume 其余的管道被配置为向那个代理发送数据。 Spark 集群中的机器都能连接到运行自定义 Sink 的那台机器上。
2. 配置Flume
在选定的机器上配置 Flume 需要如下的两步。
一、 添加如下的 JAR 包到要运行自定义 Sink 的机器中的 Flume 的 classpath 中 (如下 jar 放在/opt/module/flume-1.7.0/lib目录下)
spark-streaming-flume-sink_2.11-2.2.0.jar
commons-lang3 -3.3.2.jar
二、 flume agent配置文件:flume_pull_streaming.conf 配置如下
simple-agent.sources = netcat-source
simple-agent.sinks = spark-sink
simple-agent.channels = memory-channel
simple-agent.sources.netcat-source.type = netcat
simple-agent.sources.netcat-source.bind = hadoop01
simple-agent.sources.netcat-source.port = 44444
simple-agent.sinks.spark-sink.type = org.apache.spark.streaming.flume.sink.SparkSink
simple-agent.sinks.spark-sink.hostname = hadoop01
simple-agent.sinks.spark-sink.port = 41414
simple-agent.channels.memory-channel.type = memory
simple-agent.sources.netcat-source.channels = memory-channel
simple-agent.sinks.spark-sink.channel = memory-channel
3. Spark Streaming应用程序开发
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.flume.FlumeUtils, SparkFlumeEvent
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* Spark Streaming整合Flume的第二种方式:Pull
*/
object FlumePullWordCount
def main(args: Array[String]): Unit =
if (args.length != 2)
System.err.println("Usage: FlumePushWordCount <hostname port>")
System.exit(1)
val Array(hostname,port) = args
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumePullWordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5))
//TODO... Spark Streaming整合Flume之Pull方式
val flumeStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc, hostname, port.toInt)
flumeStream.map(x =>new String(x.event.getBody.array()).trim)
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
ssc.start()
ssc.awaitTermination()
4. 本地测试联调
先启动Flume,后启动Spark Streaming应用程序。
- 启动flume
flume-ng agent \\
--name simple-agent \\
--conf $FLUME_HOME/job \\
--conf-file $FLUME_HOME/job/flume_pull_streaming.conf \\
-Dflume.root.logger=INFO,console

- 启动Spark应用程序
启动IDEA程序之前,需要传入两个参数,因为开头定义了两个参数,不传会自动退出
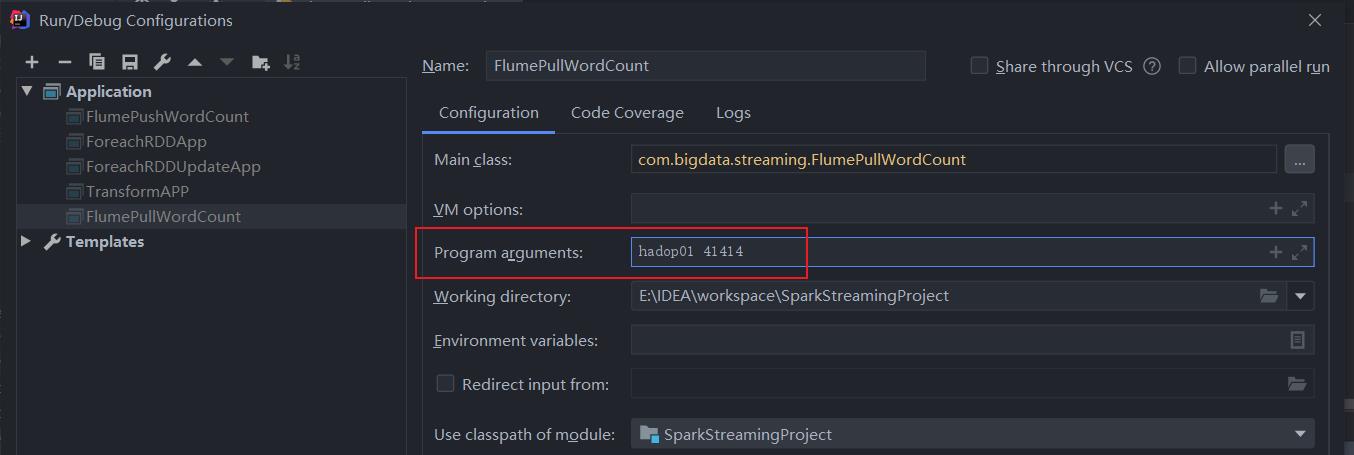
- 测试输入数据,观察IDEA统计结果
[root@hadoop01 job]# telnet hadoop01 44444
Trying 192.168.118.151...
Connected to hadoop01.
Escape character is '^]'.
a a a b c c c d
OK

IDEA输入结果

以上是关于Spark Streaming实时流处理项目实战Spark Streaming整合Flume实战二的主要内容,如果未能解决你的问题,请参考以下文章