从零开始实现主成分分析(PCA)算法
Posted 风雪夜归子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始实现主成分分析(PCA)算法相关的知识,希望对你有一定的参考价值。
声明:版权所有,转载请联系作者并注明出处:
http://blog.csdn.net/u013719780?viewmode=contents
知乎专栏:
https://www.zhihu.com/people/feng-xue-ye-gui-zi
前面两篇文章详细讲解了线性判别分析LDA,说到LDA,就不能不提到主成份分析,简称为PCA,是一种非监督学习算法,经常被用来进行数据降维、有损数据压缩、特征抽取、数据可视化(Jolliffe, 2002)。它也被称为Karhunen-Loève变换。
1. PCA原理
PCA的思想是将
n
维特征映射到
1.1 最大方差理论
在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。因此我们认为,最好的
k
维特征是将
首先,考虑在一维空间 (k=1) 上的投影。我们可以使用
向。为了方便(并且不失一般性),我们假定选择一个单位向量,从而
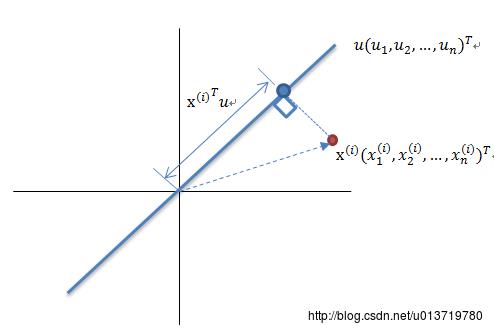
如上图所示,红色点表示原样本点
x(i)
,
u
是蓝色直线的斜率也是直线的方向向量,而且是单位向量,直线上的蓝色点表示原样本点
假设原始数据集为
Xmxn
,我们的目标是找到最佳的投影空间
Wnxk=(w1,w2,…,wk)
,其中
wi
是单位向量且
wi
与
wj(i≠j)
正交, 何为最佳的
W
?就是原始样本点投影到
由于投影后均值为0,因此投影后的总方差为:
1m∑i=1m(x(i)Tw)2=1m∑i=1mwTx(i)x(i)Tw=∑i=1mwT(1mx(i)x(i)T)w1
1mx(i)x(i)T
是不是似曾相识,没错,它就是原始数据集
X
的协方差矩阵(因为
5.7 tensorflow2实现主成分分析(PCA) ——python实战(上篇)