python实现时间序列预处理
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python实现时间序列预处理相关的知识,希望对你有一定的参考价值。
时间序列的预处理
拿到一个观察值序列后,首先要对它的纯随机性和平稳性进行检验,这两个重要的检验被称为序列的预处理。根据检验结果可以将序列分为不同的类型,对不同类型的序列会采取不同的分析方法。
什么样的认为是平稳的数据:
稳定的平均值,稳定的方差,不依赖于时间的自协方差
对于纯随机序列(又称为白噪声序列),序列的各项之间没有任何相关关系,序列在进行完全无序的随机波动,可以终止对该序列的分析。白噪声序列是没有信息可提取的平稳序列。
对于平稳非白噪声序列,它的均值和方差是常数,现已有一套非常成熟的平稳序列的建模方法。通常是建立一个线性模型来拟合该序列的发展,借此提取该序列的有用信息。ARMA 模型是最常用的平稳序列拟合模型。
对于非平稳序列,由于它的均值和方差不稳定,处理方法一般是将其转变为平稳序列,这样就可以应用有关平稳时间序列的分析方法,如建立ARMA模型来进行相应的研究。如果一个时间序列经差分运算后具有平稳性,则该序列为差分平稳序列,可以使用ARIMA模型进行分析。
平稳性的检验
对序列的平稳性的检验有两种检验方法:
一种是根据时序图和自相关图的特征做出判断的图检验,该方法操作简单、应用广泛,缺点是带有主观性;
另一种是构造检验统计量进行检验的方法,目前最常用的方法是单位根检验。
时序图检验
① 时序图检验 根据平稳时间序列的均值和方差都为常数的性质,平稳序列的时序图显示该序列值始终在一个常数附近随机波动,而且被动的范围有界;如果有明显的趋势性或者周期性,那它通常不是平稳序列。
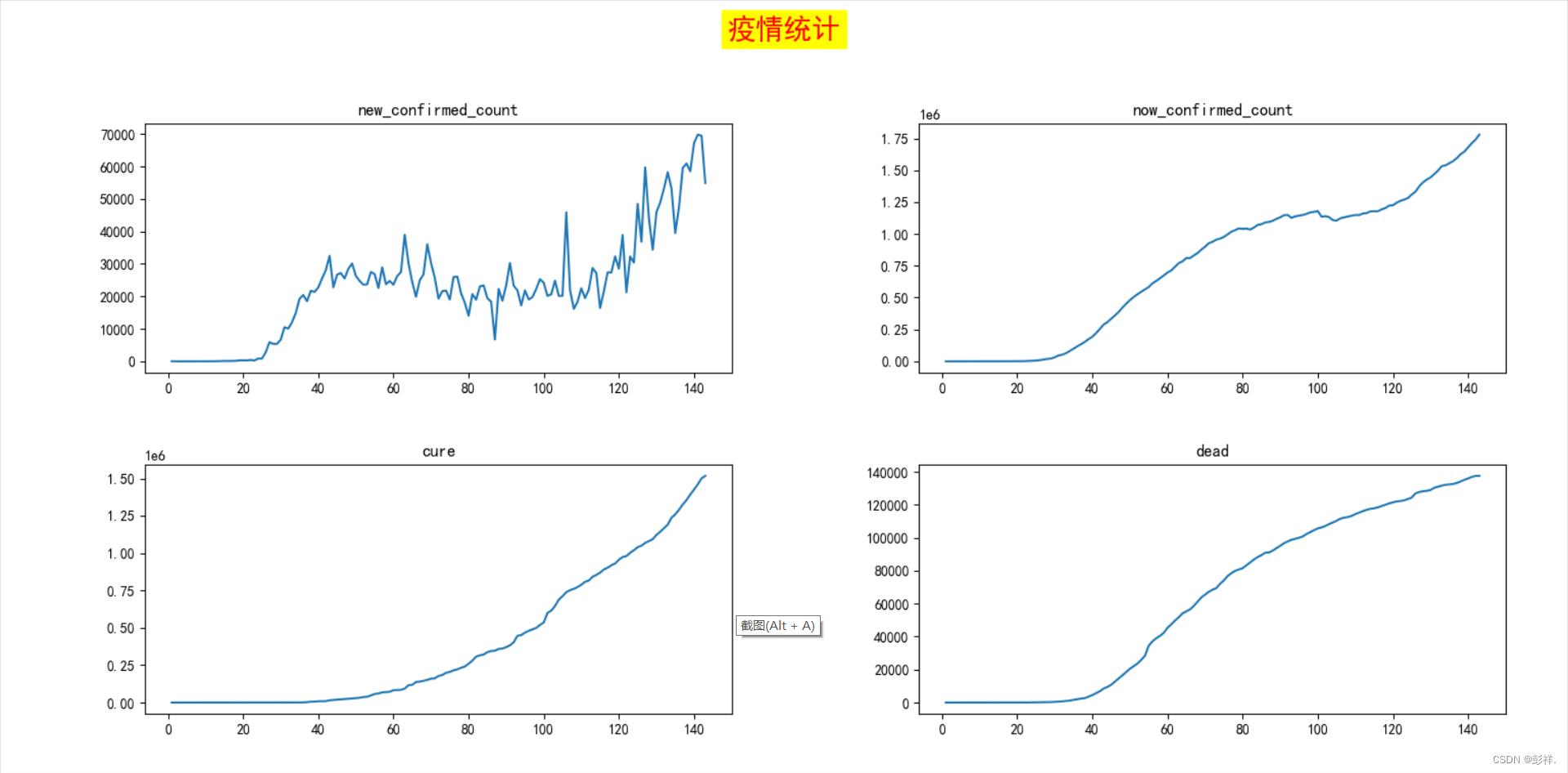
序列的特征可以通过图像来简单展示:
def view_show():
import matplotlib.pyplot as plt
data = read_csv('../datasets/Convid_19_american.csv', header=0, index_col=0)
length=len(data.columns.tolist())#获取表头列表
rows=int(length/2)
plt.rcParams['font.family'] = 'SimHei'
for i in range(length-1):
plt.subplot(rows, 2, i+1)
plt.title(data.columns.tolist()[i])
plt.plot([i for i in range(1, 144)], data[data.columns.tolist()[i]])
plt.suptitle('疫情统计', fontsize=20, color='red', backgroundcolor='yellow')
plt.tight_layout(rect=(0, 0, 1, 1)) # 使子图标题和全局标题与坐标轴不重叠
plt.show()
自相关图检验
② 自相关图检验 平稳序列具有短期相关性,这个性质表明对平稳序列而言通常只有近期的序列值对现时值的影响比较明显,间隔越远的过去值对现时值的影响越小。随着延迟期数k的增加,平稳序列的自相关系数pk(延迟 k 期)会比较快的衰减趋向于零,并在零附近随机波动,而非平稳序列的自相关系数衰减的速度比较慢,这就是利用自相关图进行平稳性检验的标准。
若自相关系数随着延迟期数k的增加,很快衰减向零,则一般是平稳序列。
方法:
from statsmodels.graphics.tsaplots import plot_acf
# plot_acf(x, ax=None, lags=None, *, alpha=0.05, use_vlines=True,
# adjusted=False, fft=False, missing='none', title='Autocorrelation',
# zero=True, vlines_kwargs=None, **kwargs)
#alpha:置信区间范围
#lags:绘制的k的最大值
调用:
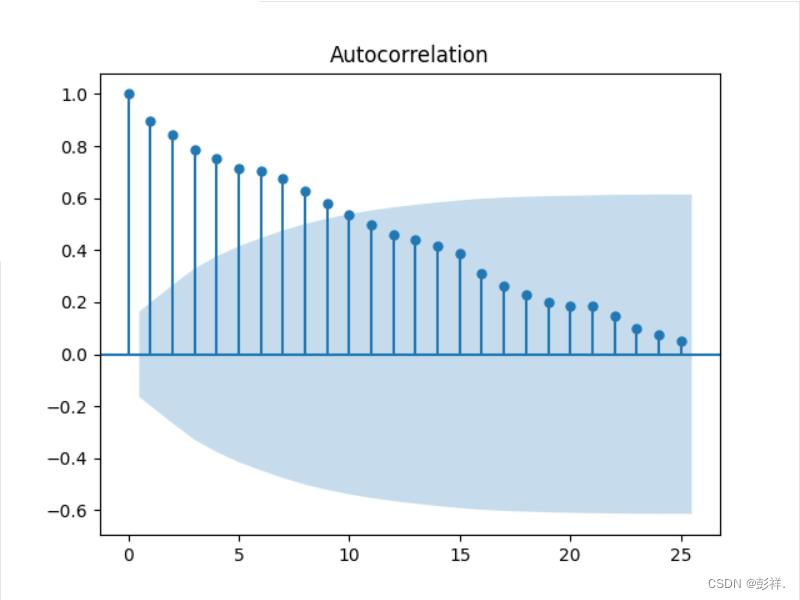
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(data['new_confirmed_count'], lags=25)
plt.show()
由图可知,该数据为平稳序列,其为新增加,相当于差分后的,但从时序图检验可知,其还是呈上升趋势,所以我们一般还需要进行差分。
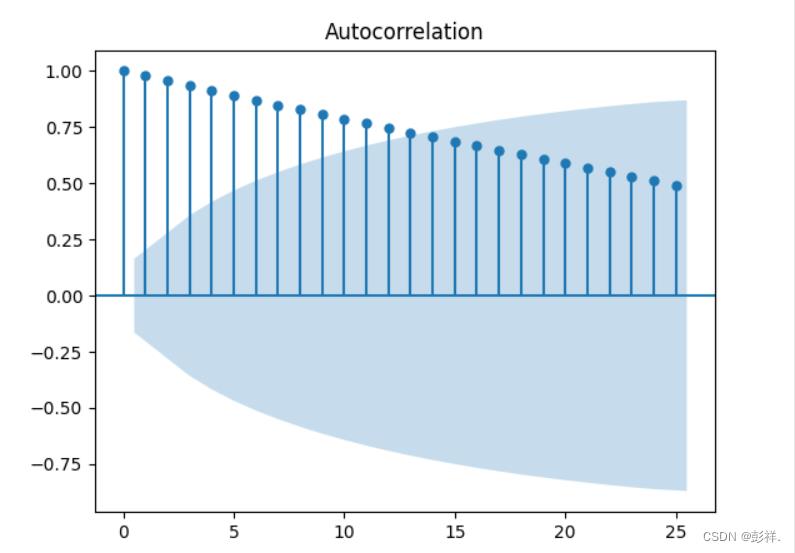
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(data['total_confired_count'], lags=25)
plt.show()
该数据为非平稳序列,其为累计确诊,即前后依赖性很大
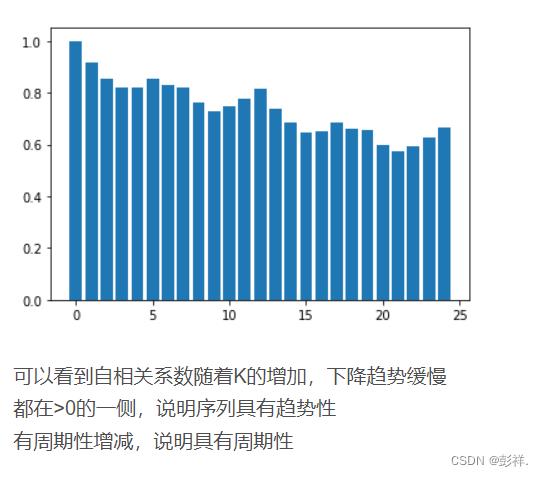
大多数时间序列都是非平稳的,一般可以通过差分、取对数等方法转化成平稳时间序列,若不成就不能使用平稳时间序列分析方法了。虽说还有各种非平稳时间序列的分析方法,预测好坏看各家本领,但终归不如平稳时间序列分析来的省心。
③ 单位根检验是指检验序列中是否存在单位根,如果存在单位根就是非平稳时间序列。
纯随机性检验
如果一个序列是纯随机序列,那么它的序列值之间应该没有任何关系,即满足y(k) = 0, k ≠ 0,这是一种理论上才会出现的理想状态,实际上纯随机序列的样本自相关系数不会绝对为零,但是很接近零,并在零附近随机波动。
纯随机性检验,一般是构造检验统计量来检验序列的纯随机性,常用的检验统计量有Q统计量、LB统计量,由样本各延迟期数的自相关系数可以计算得到检验统计量,然后计算出对应的p值,如果p值显著大于显著性水平a,则表示该序列不能拒绝纯随机的原假设,可以停止对该序列的分析。
LB检验
假设其为白噪声看是否接收假设
acorr_ljungbox(x, lags=None, boxpierce=False, model_df=0, period=None, return_df=None, auto_lag=False)
# lags:为延迟期数,如果为整数,则是包含在内的延迟期数,如果是一个列表或数组,那么所有时滞都包含在列表中最大的时滞中
# boxpierce:为True时表示除开返回LB统计量还会返回Box和Pierce的Q统计量
# model_df:模型自由度
# periods: 季节性周期长短
# 返回值:
# lbvalue:测试的统计量
# pvalue:基于卡方分布的p统计量
# bpvalue:((optionsal), float or array) – 基于 Box-Pierce 的检验的p统计量
# bppvalue:((optional), float or array) – 基于卡方分布下的Box-Pierce检验的p统计量
调用:
# 纯随机性检验:LB检验,看是否是白噪声,白噪声无规律没法用
from statsmodels.stats.diagnostic import acorr_ljungbox
df = acorr_ljungbox(data['total_confired_count'], lags=[5, 10, 15, 20], return_df=True)
print(df)
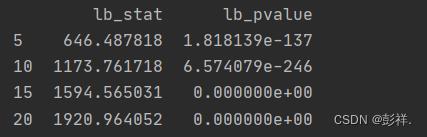
可以看到P_values很小,因此拒绝原假设,认为此序列不是白噪声序列
Q检验
Q检验与LB检验类似
df=acorr_ljungbox(data_diff,lags[5,10,15,20],
boxpierce=True,return_df=True)
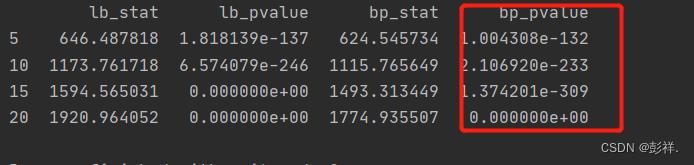
约小越好
以上是关于python实现时间序列预处理的主要内容,如果未能解决你的问题,请参考以下文章