MongoDB数据库文件的读与写
Posted 骑着哈哥去旅行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB数据库文件的读与写相关的知识,希望对你有一定的参考价值。
首先,在ubuntu16.04上使用Docker启动一个MongoDB 4.0.13的容器,基本操作如下:
hpl@hepengli:~$ sudo -i
[sudo] hpl 的密码:
root@hepengli:~# systemctl start docker
root@hepengli:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
root@hepengli:~# docker pull mongo:4.0.13
4.0.13: Pulling from library/mongo
976a760c94fc: Pull complete
c58992f3c37b: Pull complete
0ca0e5e7f12e: Pull complete
f2a274cc00ca: Pull complete
7f6568107a70: Pull complete
08957b2477b2: Pull complete
a66dbd57d2a3: Pull complete
135a9132a862: Pull complete
c9b7c17ba1df: Pull complete
7b595c9e65de: Pull complete
5e74b440cab6: Pull complete
9c04ed8f6ca0: Pull complete
3dbe824121e4: Pull complete
Digest: sha256:1aea2377c5b17dcd5e67d4c33f8f7ee09da62a4dd27ae988958b70efdf3a0a6a
Status: Downloaded newer image for mongo:4.0.13
docker.io/library/mongo:4.0.13
root@hepengli:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mongo 4.0.13 0712bd00d695 2 years ago 416MB
root@hepengli:~# docker run -d -p 27017:27017 --name mongo4.0 0712bd00d695
1e81e661666a5aa01df516663058de8b768a7b09fafa5c53b832c14a6122a97a
root@hepengli:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1e81e661666a 0712bd00d695 "docker-entrypoint.s…" 5 seconds ago Up 3 seconds 0.0.0.0:27017->27017/tcp, :::27017->27017/tcp mongo4.0
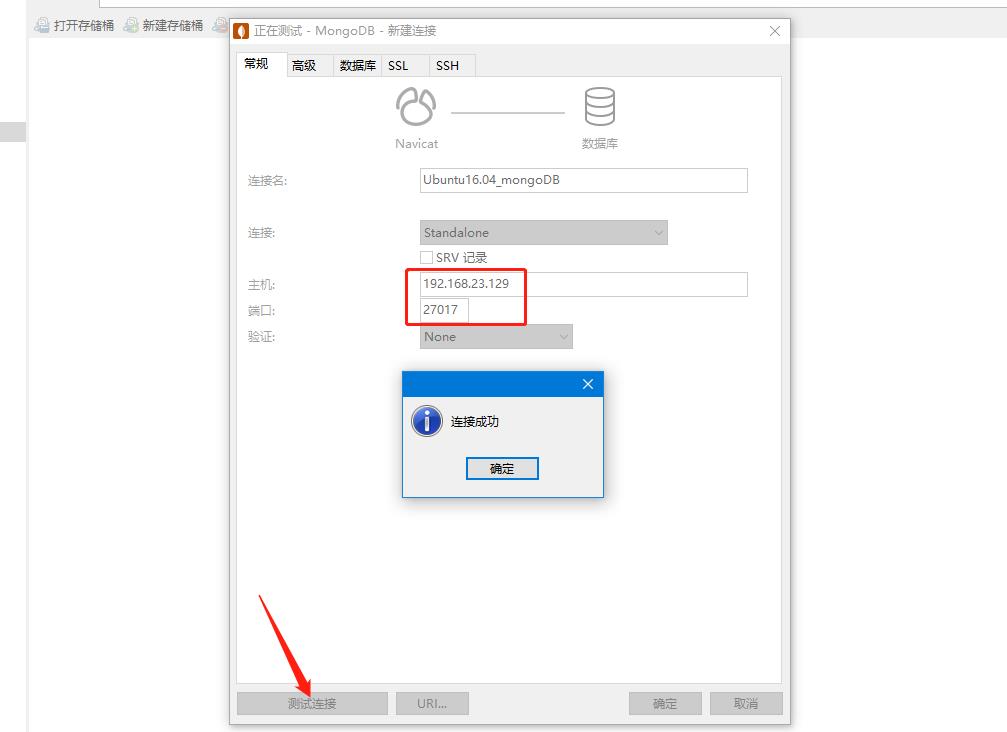
查看linux的IP地址为:192.168.23.129

在宿主机上可以使用Navicat来测试连接:
对于16M以内的小文件,可以使用MongoDB直接存储:
import os
import datetime
from pymongo import MongoClient
class DBDataSave(object):
client = MongoClient('mongodb://192.168.23.129:27017')
db = client.file_data # 使用的数据库
collection = db.datas # 使用数据库中的集合名称
def upload_little_file(self):
upload_dir = r'G:/project/study1/others/mongo_test/upload_files'
file_list = os.listdir(upload_dir)
for file in file_list:
file_path = upload_dir + '/' + file
file_division = file.split('.')
file_size = os.stat(file_path).st_size
f = open(file_path, 'rb')
data = f.read()
doc = [
"file_name": file,
"filet_type": file_division[-1],
'content': data,
"size": file_size,
'add_time': datetime.datetime.now()
]
f.close()
self.collection.insert_many(doc)
def download_little_file(self):
if not os.path.exists('./download_files'):
os.mkdir('./download_files')
files = self.collection.find()
for file in files:
with open('./download_files/' + f"file.get('file_name')", 'wb') as f:
f.write(file.get('content'))
if __name__ == '__main__':
dds = DBDataSave()
# dds.upload_little_file() # 存储文件
dds.download_little_file() # 导出文件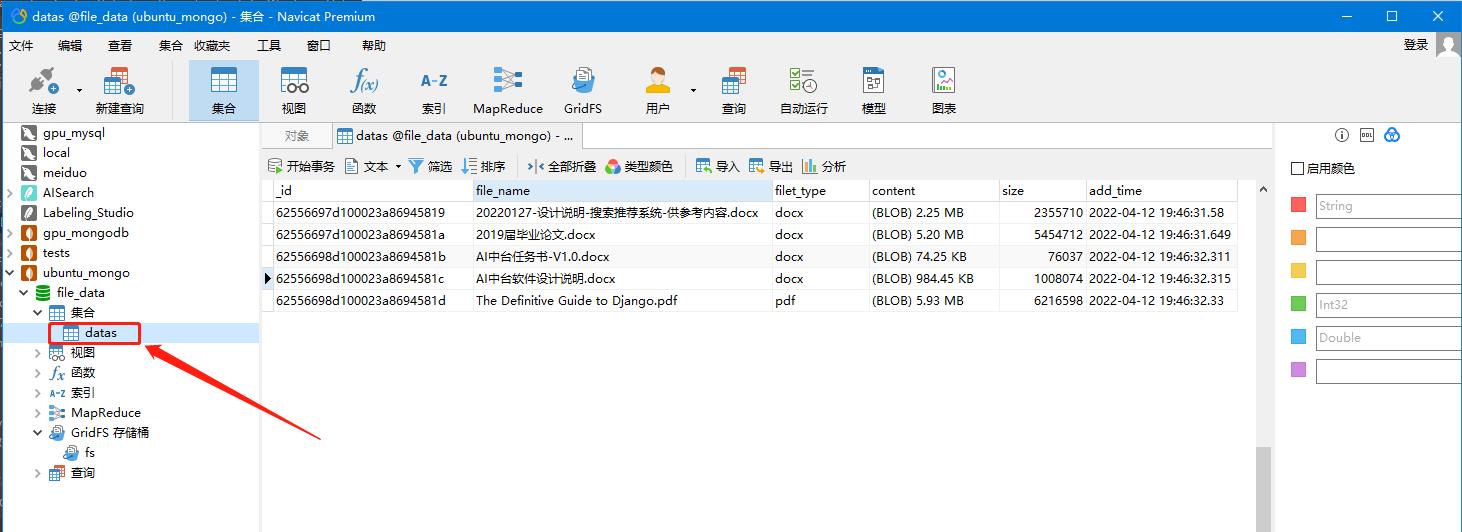
MongoDB内置一套文件系统名为GridFS,可以用来存储大于16M以上的文件:
GridFS具有分布式管理文件的能力,可以突破一般文件系统对file的限制,分段存储,不像普通文件系统是整个存储的。这样读取大型文件时就不会占用大量的内存。
from pymongo import MongoClient
from gridfs import *
import os
class DBDataSaveGF(object):
client = MongoClient('mongodb://192.168.23.129:27017') # 连接本地的MongoDB数据库
db = client.file_data
file_put = GridFS(db)
def db_write_file(self):
upload_path = r'G:/project/study1/others/mongo_test/upload_files'
files = os.listdir(upload_path) # 列出文件夹下的所有文件
for file in files:
file_path = upload_path + '\\\\' + file
with open(file_path, 'rb') as f1:
self.file_put.put(f1, content_type=file.split('.')[-1], filename=file)
def db_read_file(self):
if not os.path.exists('./download_files'):
os.mkdir('./download_files')
files = self.file_put.find()
# files = file_put.find().sort("uploadDate", -1).limit(1) # 返回最近上传的1个文件
for file in files:
with open('./download_files/' + file.filename, 'wb') as f1:
f1.write(file.read())
if __name__ == '__main__':
db = DBDataSaveGF()
# db.db_write_file() # 存储文件
db.db_read_file() # 读取文件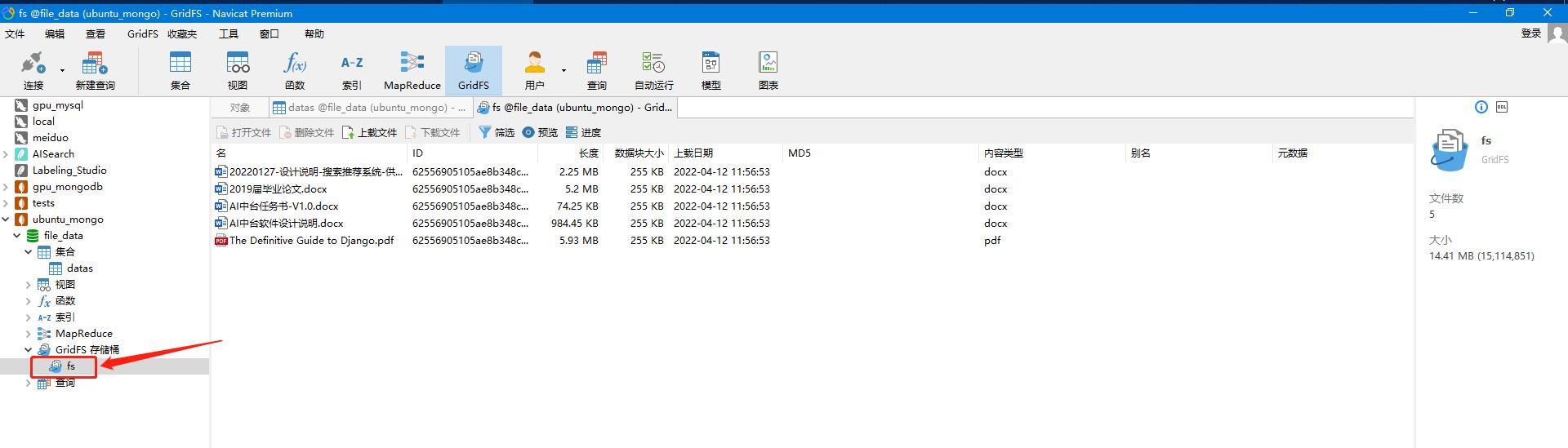
以上是关于MongoDB数据库文件的读与写的主要内容,如果未能解决你的问题,请参考以下文章