jupyter 安装 豆瓣代理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jupyter 安装 豆瓣代理相关的知识,希望对你有一定的参考价值。
参考技术A 通过网页安装。豆瓣电影提供最新的电影介绍及评论包括上映影片的影讯查询及购票服务。你可以记录想看、在看和看过的电影电视剧,顺便打分、写影评。
是指代理人以被代理人(又称本人)的名义,在代理权限内与第三人(又称相对人)实施民事行为,其法律后果直接由被代理人承受的民事法律制度。
的工作主要在开放系统互联(OSI)模型的会话层,从而起到防火墙的作用。
03_使用scrapy框架爬取豆瓣电影TOP250
前言:
本次项目是使用scrapy框架,爬取豆瓣电影TOP250的相关信息。其中涉及到代理IP,随机UA代理,最后将得到的数据保存到mongoDB中。本次爬取的内容实则不难。主要是熟悉scrapy相关命令以及理解框架各部分的作用。
1、本次目标
爬取豆瓣电影TOP250的信息,将得到的数据保存到mongoDB中。
2、准备工作
需要安装好scrapy以及mongoDB,安装步骤这里不做赘述。(这里最好是先了解scrapy框架各个部分的基本作用和基础知识,这样方便后面的内容的理解。scrapy文档链接:https://scrapy-chs.readthedocs.io/zh_CN/latest/)
3、创建scrapy项目和爬虫
首先需要创建一个scrapy项目,命令如下:
scrapy startproject douban (douban为你的项目名称)
创建好之后会有系统提示如下:
You can start your first spider with:
cd douban
scrapy genspider example example.com
提示的意思是让你cd进入到刚刚创建好的douban项目下面,使用下面的命令创建你的爬虫,例如:
scrapy genspider DoubanSpider movie.douban.com/top250
这样,在spiders目录下(如下图)就创建出了一个名为DoubanSpider的爬虫了。
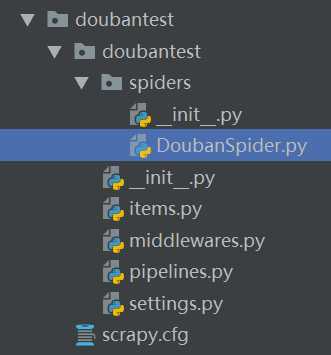
打开爬虫文件,里面默认已经写好了一些代码。这里简单的简单的介绍一下。(详细请参考https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/spiders.html)
name 是你创建爬虫的名称,相当于一个标识符,这个名称是唯一的且也是必须的。
allowed_domains 是允许爬虫爬取的域名列表(可选)
start_urls 是你的爬虫起始访问的URL
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 5 class DoubanspiderSpider(scrapy.Spider): 6 name = ‘DoubanSpider‘ 7 allowed_domains = [‘movie.douban.com/top250‘] 8 start_urls = [‘http://movie.douban.com/top250/‘] 9 10 def parse(self, response): 11 pass
我们所要写的爬虫逻辑就是要在这一部分中来编写的,在开始动手写之前,还需要先在items文件下定义数据结构。
4、数据结构
如下图可以看到电影的相关信息,例如:电影名称,演员,导演,排名,评分等等。
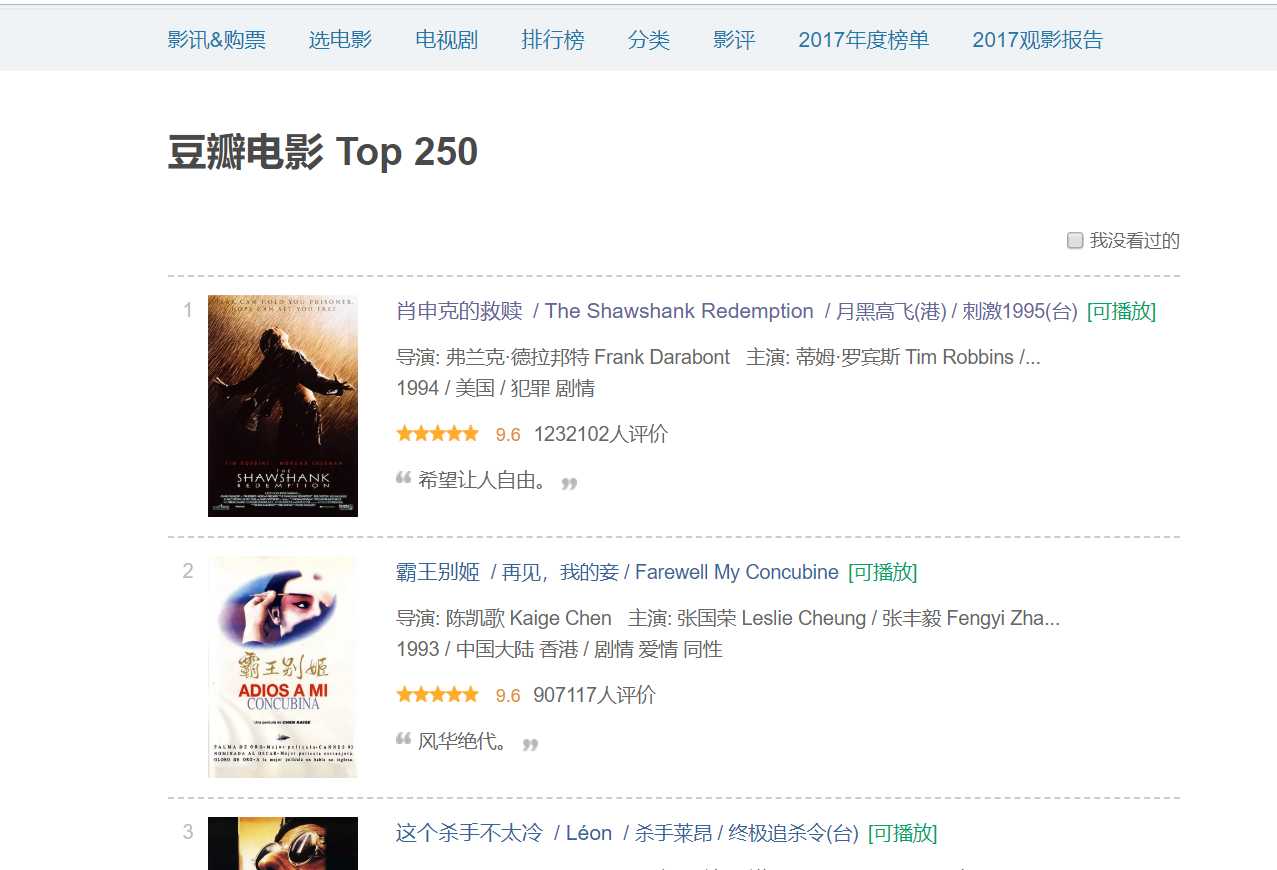
需要做的是,把这些信息先在items定义好。代码如下:
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class DoubanItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 # 排名 15 rank = scrapy.Field() 16 # 标题 17 title = scrapy.Field() 18 # 链接 19 link = scrapy.Field() 20 # 导演&主演 21 director_actors = scrapy.Field() 22 # 时间 23 time = scrapy.Field() 24 # 类别 25 category = scrapy.Field() 26 # 评分 27 star = scrapy.Field() 28 # 评论数 29 comment = scrapy.Field() 30 # 引言 31 quote = scrapy.Field()
定义好这些之后,待会编写爬虫逻辑的时候,对于爬取到的相应数据只需要放进相应的变量里即可。
5、编写spider
下面要做的就是把需要的电影信息解析出来,这里使用xpath来完成。先来分析网站,如下图。
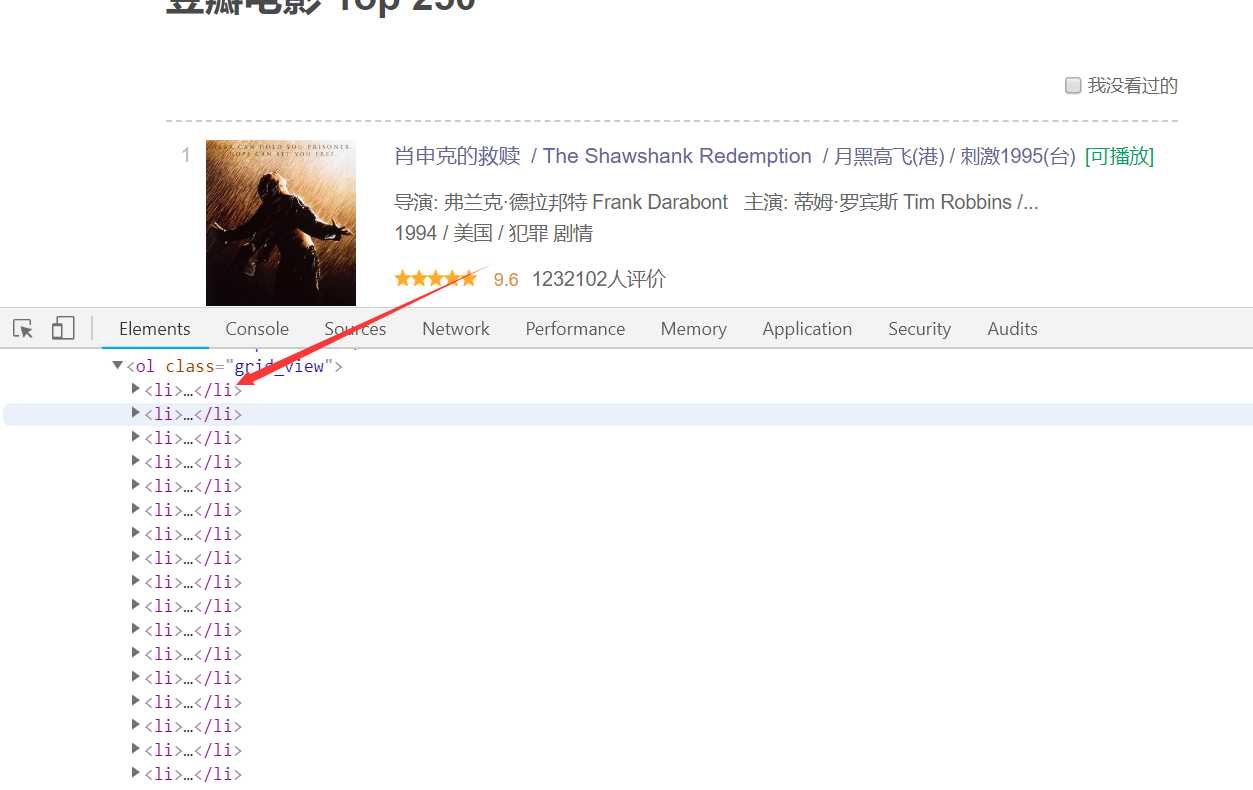
可以发现,每一个电影信息都在class为“grid_view”的ol节点下的li节点里。展开li节点,如下图
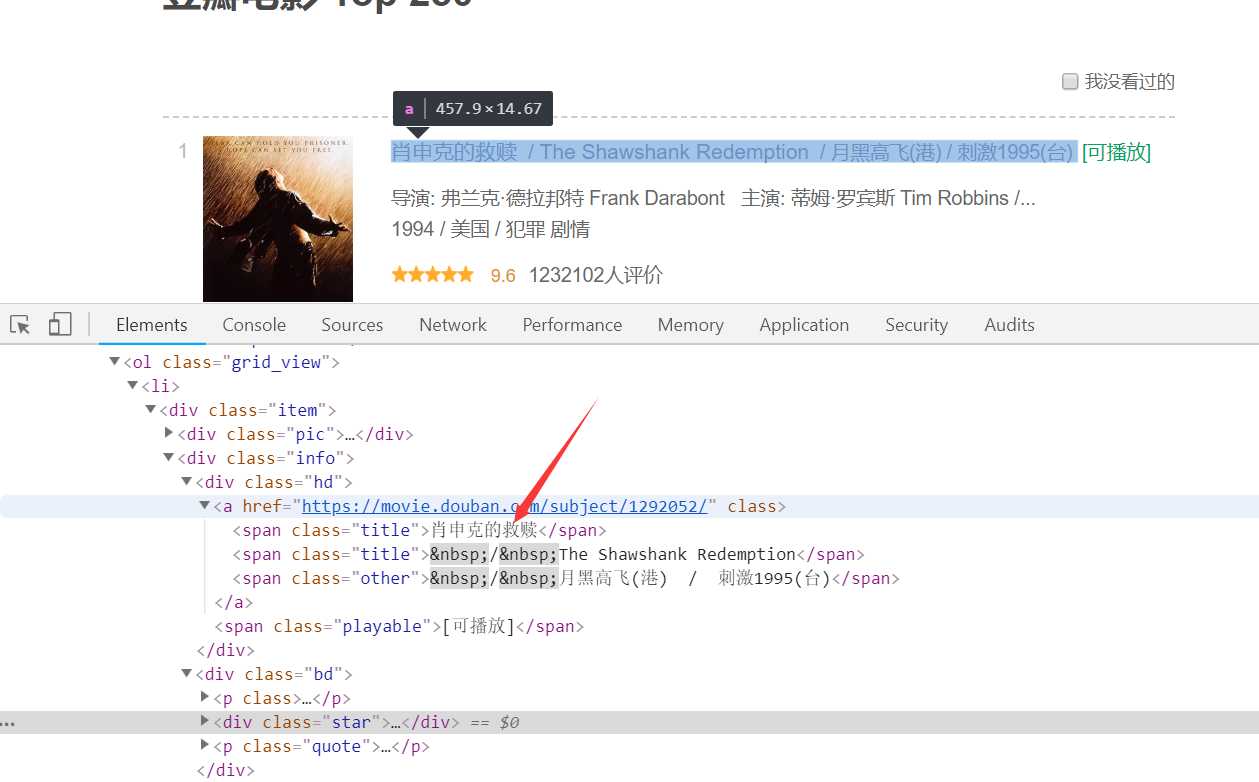
我们需要的电影名称就包含在class为“hd”的div/a的span节点下,这是运用xpath选择器很容易就能得到电影名称。其他的信息获取也同理,由于这次重点在sracpy框架的使用,所以获取信息这部分比较简单的内容就不在赘述,直接上代码:
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 from douban.items import DoubanItem 5 6 7 class MoviespiderSpider(scrapy.Spider): 8 name = ‘movieSpider‘ 9 allowed_domains = [‘movie.douban.com‘] 10 start_urls = [‘http://movie.douban.com/top250‘] 11 12 def parse(self, response): 13 items = response.xpath(‘//ol[@class="grid_view"]//li‘) 14 item = DoubanItem() 15 for each in items: 16 # 排名 17 item[‘rank‘] = each.xpath(‘.//div[@class="pic"]/em//text()‘).extract_first() 18 # 标题 19 item[‘title‘] = each.xpath(‘.//div[@class="hd"]/a/span[@class="title"][1]//text()‘).extract_first() 20 # 链接 21 item[‘link‘] = each.xpath(‘.//div[@class="info"]/div/a/@href‘).extract_first() 22 # 导演&主演 23 item[‘director_actors‘] = each.xpath(‘.//div[@class="bd"]/p[1]/text()[1]‘).extract_first().strip().replace(‘xa0‘, ‘‘) 24 # 时间和类别的集合 25 time_category = each.xpath(‘.//div[@class="bd"]/p[1]/text()[2]‘).extract_first() 26 # 时间 27 item[‘time‘] = time_category.split(‘/‘)[0].strip() 28 # 类别 29 item[‘category‘] = time_category.split(‘/‘)[-1].strip() 30 # 评分 31 item[‘star‘] = each.xpath(‘.//div[@class="star"]/span[@class="rating_num"]/text()‘).extract_first() 32 # 评论数 33 item[‘comment‘] = each.xpath(‘.//div[@class="star"]/span[last()]/text()‘).extract_first()[:-3] 34 # 引言 35 item[‘quote‘] = each.xpath(‘.//p[@class="quote"]/span/text()‘).extract_first() 36 yield item
以上代码实现的就是从网页中提取出所需要的信息,其中第4行和14行代码是把我们刚刚定义好的信息导入进来,并且将item实例化,最后将item返回。
写到这里其实就可以得到这个页面所有电影信息了。但是这样还不够,还需要实现访问剩下页面的电影,那么就需要在写一段代码来实现访问剩下的其他页面,将得到页面的response在传给parse函数进行解析即可,代码实现如下:
1 for i in range(1, 10): 2 page = i * 25 3 start = ‘?‘ + ‘start=‘ + str(page) 4 next_url = response.urljoin(start) 5 yield scrapy.Request(url=next_url, callback=self.parse)
下图是第二页的URL,易得出start和页数的关系,再通过urljoin构造出新的next_url,即下一页的URL,最后返回Request,其中url为下一页的URL,callback为回调函数,这里只需要再次回调parse函数进行页面解析即可。

这样一个简单爬虫就写好了。但是到这里还不行,因为我们还未修改请求的UA代理,网站接收到请求知道这是一个爬虫,会拒绝访问,下面需要添加一个随机UA。
6、RandomUA
添加UA代理最简单的一种方式是在settings文件里面,在DEFAULT_REQUEST_HEADERS 这一项里,添加User-Agent即可。
1 DEFAULT_REQUEST_HEADERS = { 2 ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, 3 ‘Accept-Language‘: ‘en‘, 4 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 ‘ 5 ‘Safari/537.36 ‘ 6 }
但是这不是我们想要的,这里需要构造一个UA代理列表,每一次发送请求都会提取出一个随机的UA值,达到每一次请求的UA都是随机的。那要怎么做呢?同样先是在settings文件中,先构造一个UA列表,代码如下:
1 User_Agent = [ 2 ‘Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)‘, 3 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 4 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", 5 "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 6 "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", 7 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", 8 "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", 9 "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", 10 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", 11 "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", 12 "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", 13 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", 14 "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", 15 "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", 16 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", 17 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", 18 ]
然后在middleware文件下,创建一个名为RandomUAMiddleware的类,导入刚刚在settings中创建好的UA的列表,导入random库,然后创建一个名为process_request的方法,编写好实现代码即可,代码实现如下:
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your spider middleware 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 7 import random 8 9 from douban.settings import User_Agent 10 from scrapy import signals 11 class RandomUAMiddleware(object): 12 def process_request(self,request,spider): 13 user_agent = random.choice(User_Agent) 14 request.headers[‘User-Agent‘] = user_agent
接下来只需要返回settings文件中,打开下载中间键,添加RandomUAMiddleware即可,代码实现如下:
1 DOWNLOADER_MIDDLEWARES = {‘douban.middlewares.RandomUAMiddleware‘: 100 }
这样就可以随机生成UA了。
7、PROXY
实现了生成随机UA之后,我们还希望每一次的请求使用不同的IP地址,这样做就可以防止被网站的管理员ban掉。怎么实现代理ip呢?其实方法和UA大同小异。
首先也是要在settings中构造一个代理IP列表(当然,下面这个代理列表现在可能已经不能用了),代码如下:
1 Proxy_list = [‘http://47.95.9.128:8118‘, 2 ‘http://112.16.172.107:58337‘, 3 ‘http://103.205.26.84:41805‘, 4 ‘http://61.145.182.27:53281‘, 5 ‘http://117.191.11.71:80‘, 6 ‘http://47.92.98.68:3128‘, 7 ‘http://120.206.182.11:80‘, 8 ‘http://59.44.43.198:80‘, 9 ‘http://114.236.138.171:80‘]
接着也是在middleware文件下,导入该列表,创建代理的类和方法。代码实现如下:
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your spider middleware 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 7 import random 8 9 from scrapy import signals 10 11 from douban.settings import Proxy_list 12 13 class ProxyMiddleware(object): 14 def process_request(self, request, spider): 15 proxy = random.choice(Proxy_list) 16 request.meta[‘proxy‘] = proxy
最后也同样需要在settings中打开下载中间键,添加写好的ProxyMiddleware即可,代码实现如下:
DOWNLOADER_MIDDLEWARES = {‘douban.middlewares.ProxyMiddleware‘: 200}
这样随机代理IP的功能也实现了。
8、mongoDB
要将爬取的数据,保存在mongoDB,首先在items里面定义collection表名,代码如下:
# mongoDB表名 collection = ‘movies‘
然后在settings里面创建相关参数,代码如下:
MONGO_URI = ‘localhost‘ MONGO_DB = ‘doubanmovies‘
接下来需要在pipeline文件下创建一个MongopPipeline的类,定义好相关方法,代码实现如下:
1 import pymongo 2 3 4 class MongoPipeline(object): 5 def __init__(self, mongo_uri, mongo_db): 6 self.mongo_uri = mongo_uri 7 self.mongo_db = mongo_db 8 9 @classmethod 10 def from_crawler(cls, crawler): 11 return cls( 12 mongo_uri=crawler.settings.get(‘MONGO_URI‘), 13 mongo_db=crawler.settings.get(‘MONGO_DB‘) 14 ) 15 16 def open_spider(self, spider): 17 self.client = pymongo.MongoClient(self.mongo_uri) 18 self.db = self.client[self.mongo_db] 19 20 def process_item(self, item, spider): 21 self.db[item.collection].insert(dict(item)) 22 return item 23 24 def close_spider(self, spider): 25 self.client.close()
最后在settings文件中,打开ITEM_PIPELINES,并添加写好的pipeline,代码如下:
ITEM_PIPELINES = { ‘douban.pipelines.MongoPipeline‘: 100}
8、运行爬虫
运行爬虫的命令为 scrapy crawl movieSpider(movieSpider为你的爬虫名)
最后查看结果,如下:
2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=125> {‘category‘: ‘剧情‘, ‘comment‘: ‘238142‘, ‘director_actors‘: ‘导演: 巴瑞·莱文森 Barry Levinson主演: 达斯汀·霍夫曼 Dustin Hoffman ...‘, ‘link‘: ‘https://movie.douban.com/subject/1291870/‘, ‘quote‘: ‘生活在自己的世界里,也可以让周围的人显得可笑和渺小。‘, ‘rank‘: ‘145‘, ‘star‘: ‘8.7‘, ‘time‘: ‘1988‘, ‘title‘: ‘雨人‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=125> {‘category‘: ‘剧情 犯罪 悬疑‘, ‘comment‘: ‘228752‘, ‘director_actors‘: ‘导演: 忻钰坤 Yukun Xin主演: 霍卫民 Weimin Huo / 王笑天 Xiaotian Wang ‘ ‘...‘, ‘link‘: ‘https://movie.douban.com/subject/25917973/‘, ‘quote‘: ‘荒诞讽刺,千奇百巧,抽丝剥茧,百转千回。‘, ‘rank‘: ‘146‘, ‘star‘: ‘8.7‘, ‘time‘: ‘2014‘, ‘title‘: ‘心迷宫‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=125> {‘category‘: ‘剧情 历史 战争‘, ‘comment‘: ‘143256‘, ‘director_actors‘: ‘导演: 特瑞·乔治 Terry George主演: 唐·钱德尔 Don Cheadle / 苏菲·奥...‘, ‘link‘: ‘https://movie.douban.com/subject/1291822/‘, ‘quote‘: ‘当这个世界闭上双眼,他却敞开了怀抱。‘, ‘rank‘: ‘147‘, ‘star‘: ‘8.9‘, ‘time‘: ‘2004‘, ‘title‘: ‘卢旺达饭店‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=75> {‘category‘: ‘喜剧 剧情 爱情‘, ‘comment‘: ‘118018‘, ‘director_actors‘: ‘导演: 查理·卓别林 Charles Chaplin主演: 查理·卓别林 Charles Chaplin ...‘, ‘link‘: ‘https://movie.douban.com/subject/1294371/‘, ‘quote‘: ‘大时代中的人生,小人物的悲喜。‘, ‘rank‘: ‘97‘, ‘star‘: ‘9.2‘, ‘time‘: ‘1936‘, ‘title‘: ‘摩登时代‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=75> {‘category‘: ‘剧情 家庭 奇幻 冒险‘, ‘comment‘: ‘303989‘, ‘director_actors‘: ‘导演: 蒂姆·波顿 Tim Burton主演: 伊万·麦克格雷格 Ewan McGregor / 阿...‘, ‘link‘: ‘https://movie.douban.com/subject/1291545/‘, ‘quote‘: ‘抱着梦想而活着的人是幸福的,怀抱梦想而死去的人是不朽的。‘, ‘rank‘: ‘98‘, ‘star‘: ‘8.7‘, ‘time‘: ‘2003‘, ‘title‘: ‘大鱼‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=75> {‘category‘: ‘剧情 惊悚‘, ‘comment‘: ‘411734‘, ‘director_actors‘: ‘导演: 中岛哲也 Tetsuya Nakashima主演: 松隆子 Takako Matsu / 冈田将生 ...‘, ‘link‘: ‘https://movie.douban.com/subject/4268598/‘, ‘quote‘: ‘没有一人完全善,也没有一人完全恶。‘, ‘rank‘: ‘99‘, ‘star‘: ‘8.7‘, ‘time‘: ‘2010‘, ‘title‘: ‘告白‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=75> {‘category‘: ‘剧情 爱情 家庭‘, ‘comment‘: ‘185700‘, ‘director_actors‘: ‘导演: 杨德昌 Edward Yang主演: 吴念真 / 李凯莉 Kelly Lee / 金燕玲 Elai...‘, ‘link‘: ‘https://movie.douban.com/subject/1292434/‘, ‘quote‘: ‘我们都曾经是一一。‘, ‘rank‘: ‘100‘, ‘star‘: ‘9.0‘, ‘time‘: ‘2000‘, ‘title‘: ‘一一‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=200> {‘category‘: ‘剧情 爱情‘, ‘comment‘: ‘115940‘, ‘director_actors‘: ‘导演: Luc Besson主演: 让-马克·巴尔 Jean-Marc Barr / 让·雷诺 Jean ‘ ‘Re...‘, ‘link‘: ‘https://movie.douban.com/subject/1300960/‘, ‘quote‘: ‘在那片深蓝中,感受来自大海的忧伤寂寞与美丽自由。‘, ‘rank‘: ‘224‘, ‘star‘: ‘8.7‘, ‘time‘: ‘1988‘, ‘title‘: ‘碧海蓝天‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=200> {‘category‘: ‘科幻 悬疑 惊悚‘, ‘comment‘: ‘224481‘, ‘director_actors‘: ‘导演: 詹姆斯·沃德·布柯特 James Ward Byrkit主演: 艾米丽·芭尔多尼 Em...‘, ‘link‘: ‘https://movie.douban.com/subject/25807345/‘, ‘quote‘: ‘小成本大魅力。‘, ‘rank‘: ‘225‘, ‘star‘: ‘8.4‘, ‘time‘: ‘2013‘, ‘title‘: ‘彗星来的那一夜‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=125> {‘category‘: ‘剧情 爱情‘, ‘comment‘: ‘365533‘, ‘director_actors‘: ‘导演: 乔·怀特 Joe Wright主演: 凯拉·奈特莉 Keira Knightley / 马修·...‘, ‘link‘: ‘https://movie.douban.com/subject/1418200/‘, ‘quote‘: ‘爱是摈弃傲慢与偏见之后的曙光。‘, ‘rank‘: ‘148‘, ‘star‘: ‘8.5‘, ‘time‘: ‘2005‘, ‘title‘: ‘傲慢与偏见‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=125> {‘category‘: ‘剧情 喜剧 犯罪‘, ‘comment‘: ‘183367‘, ‘director_actors‘: ‘导演: 达米安·斯兹弗隆 Damián Szifron主演: 达里奥·葛兰帝内提 Darío...‘, ‘link‘: ‘https://movie.douban.com/subject/24750126/‘, ‘quote‘: ‘始于荒诞,止于更荒诞。‘, ‘rank‘: ‘149‘, ‘star‘: ‘8.8‘, ‘time‘: ‘2014‘, ‘title‘: ‘荒蛮故事‘} 2018-12-18 22:35:25 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=125> {‘category‘: ‘纪录片‘, ‘comment‘: ‘108078‘, ‘director_actors‘: ‘导演: 雅克·贝汉 Jacques Perrin / 雅克·克鲁奥德 Jacques Cluzaud主演:...‘, ‘link‘: ‘https://movie.douban.com/subject/3443389/‘, ‘quote‘: ‘大海啊,不全是水。‘, ‘rank‘: ‘150‘, ‘star‘: ‘9.0‘, ‘time‘: ‘2009‘, ‘title‘: ‘海洋‘}
以上仅为部分输出结果,让我们来查看一下mongoDB保存的数据,如下图:
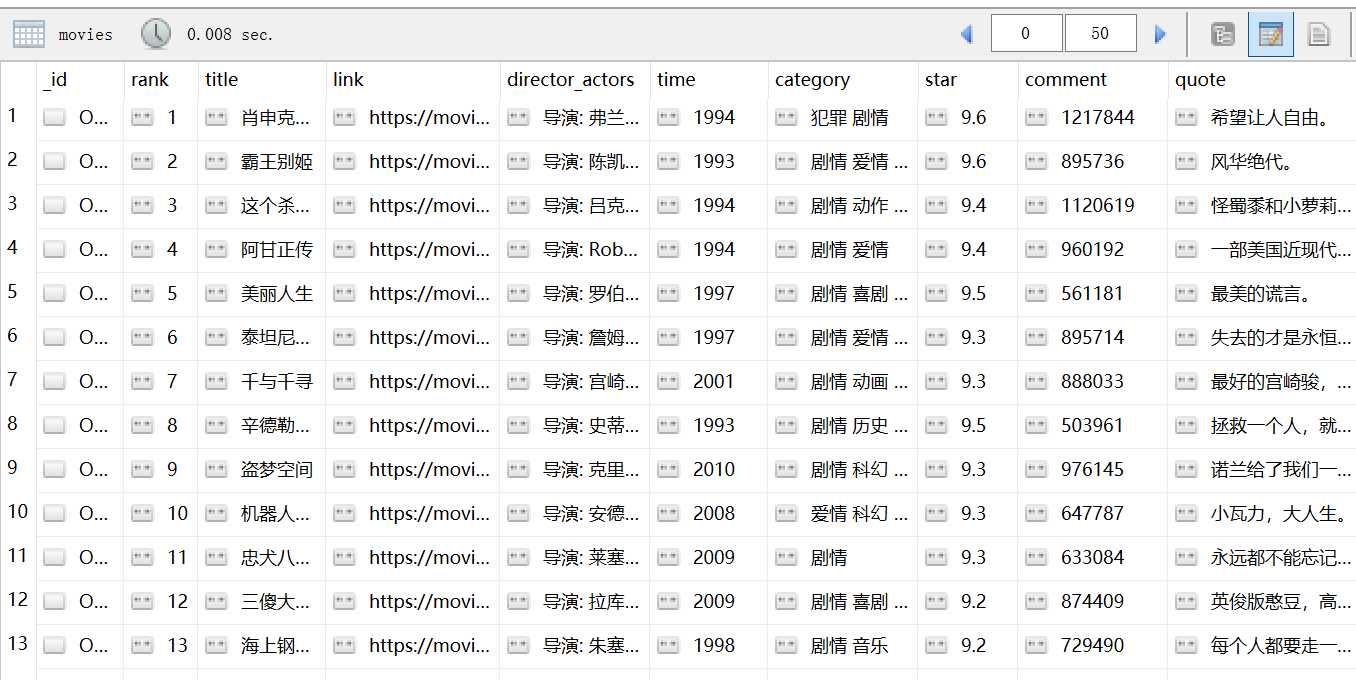
这样就成功的使用scrapy框架爬取到了豆瓣电影TOP250的信息了。
结语:
感觉scrapy框架功能很强大,还需要好好熟练和掌握,另外感觉自己写文章的功力还是没啥子进步啊,emm...还说点什么呢...今天的菠萝和葡萄不错。
以上是关于jupyter 安装 豆瓣代理的主要内容,如果未能解决你的问题,请参考以下文章