调试并修改Lucene源码
Posted 巨头之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了调试并修改Lucene源码相关的知识,希望对你有一定的参考价值。
需求: 搜索关键词的词频始终保持为1,即在document无论搜索关键词出现几次,只能计算该搜索关键词只出现1次。那为什么会有这需求呢? 词频会影响到document的相似度计算分。 搜了下相关资料,发现solr4.x之前计算相似度的算法是TF-IDF, solr4.x 之后的算法改为BM25,下文会有这两种算法的大致描述。 既然要改词频,那就只能先clone Lucene的源码下来研究下,也就有了该文点点滴滴的记录, 下文主要对比较核心的点进行记录。
本文基于Lucene源码8.5.1
注意:下载的是lucene-solr源码包,单独的lucene不支持ant idea|eclipse
1. 在lucene源码中引入IK分词器jar包报错
Exception in thread "main" java.lang.AbstractMethodError: org.apache.lucene
...
参考了 Lucene和ik的版本问题, 这可能是IK分词器和lucene的版本对应不上导致的,本次下载的lucene源码版本是8.5.1,IK分词器是
找个版本比较新的IK分词器jar包试下,IKAnalyzer6.5.0.jar
上面的链接打不开的话,就尝试这个链接:https://pan.baidu.com/s/1-pTUm4auvfSWpEzWLhZftg
提取码:w1ag
2. 怎么在idea工具里,给ivy项目添加jar包

如图所示,在项目模块的ivy.xml文件里添加库依赖,打开右侧的Ant,右键刚才添加库依赖的模块名,点击 Run Build
3. 探究Lucene源码中词频的存储位置以及score的生成(基于Lucene4.0版本之后)
对生成索引和检索阶段都设置IK分词器,Lucene词频的计算位置在BM25Similarity.BM25Scorer.score函数,存储是在Lucene84PostingsReader.BlockDocsEnum.freqBuffer数组中
在调试中,发现只有匹配搜索词的Document才会进入score函数,而且IK会对搜索词进行分词,比如将 搜索词 “谷歌网站从来” 分词成 “谷歌”、“网站”、“从来” 这三个词,而score的调用是和Document存在该分词的个数密切相关的,具体看下面截图(已加说明)
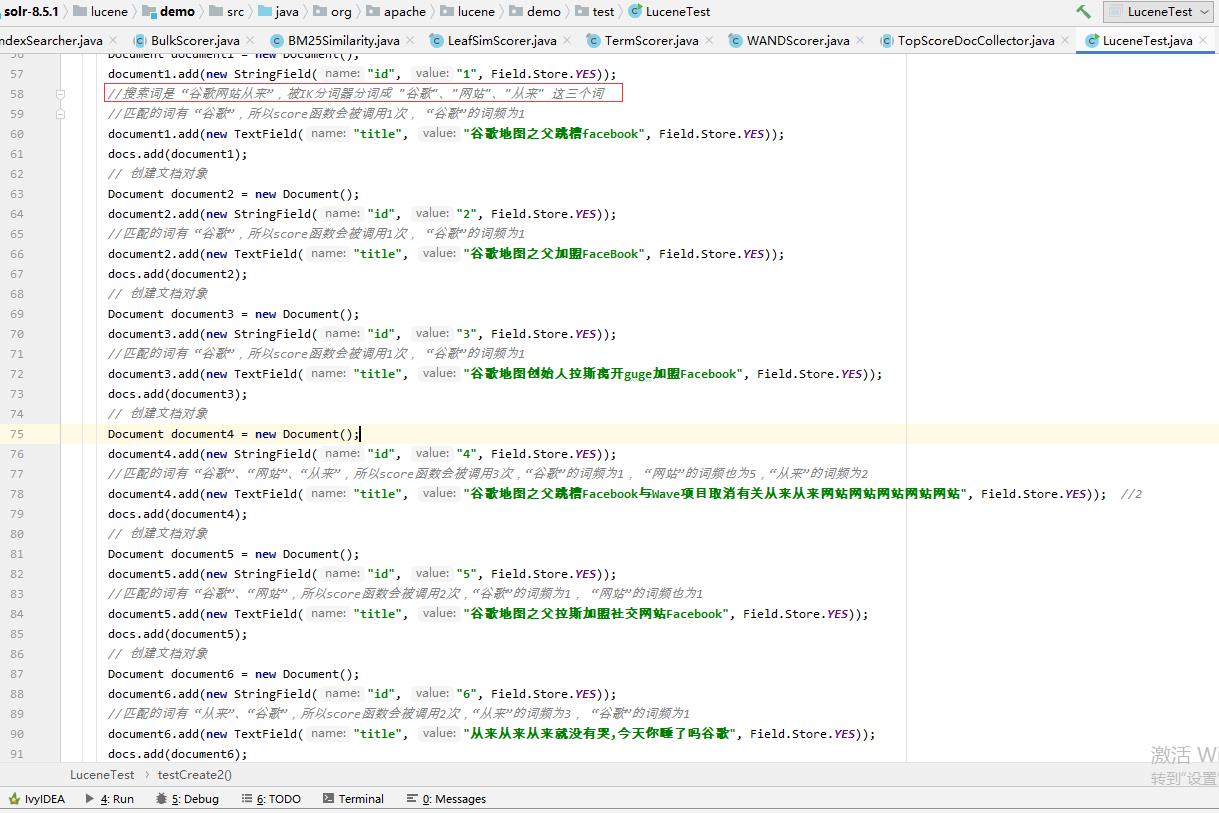
Document的score值是在WANDScorer.score函数里计算的,在这个函数里会对Document中匹配搜索的分词进行词频统计的调用和 各词频间score值的相加, 最终得到Document对应的score值
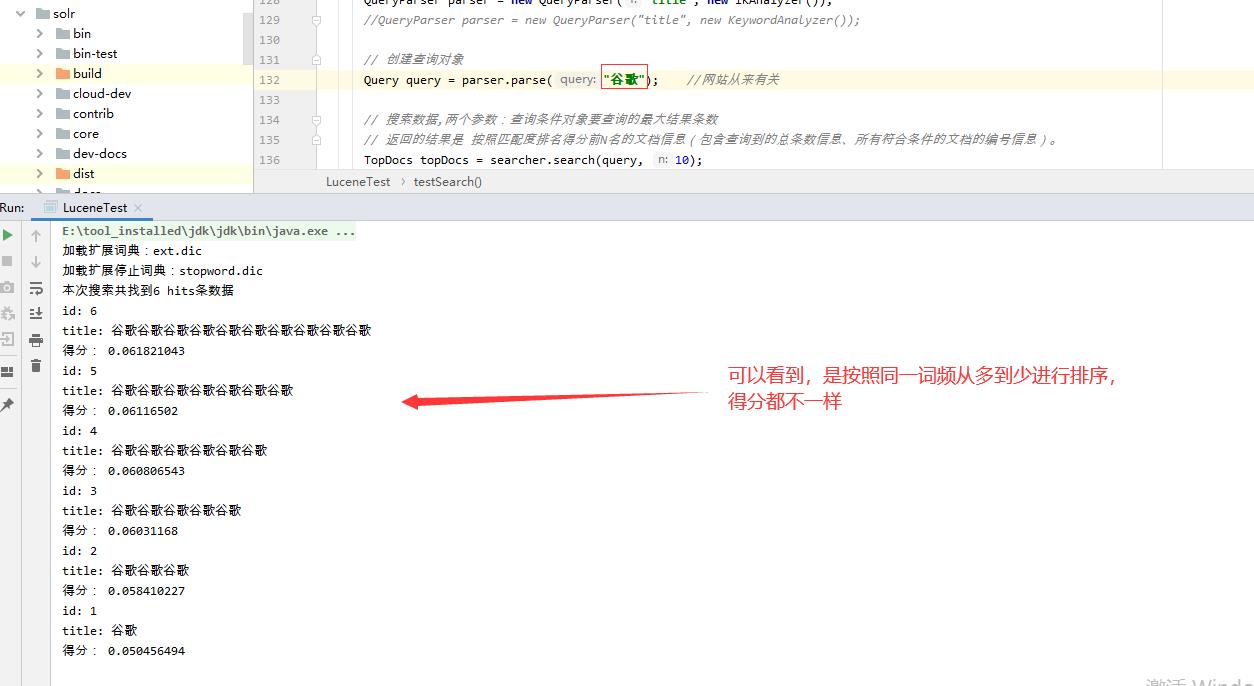
将BM25Similarity.BM25Scorer.score函数的freq置为1,即可实现词频始终为1, 接着对比下词频改动前后的搜索结果,看下面截图.
不改动Lucene源码中的词频时,输出结果分析:
将Lucene源码中的词频改为1,即同一文档中相同词出现的频率始终记录为1,输出结果分析:
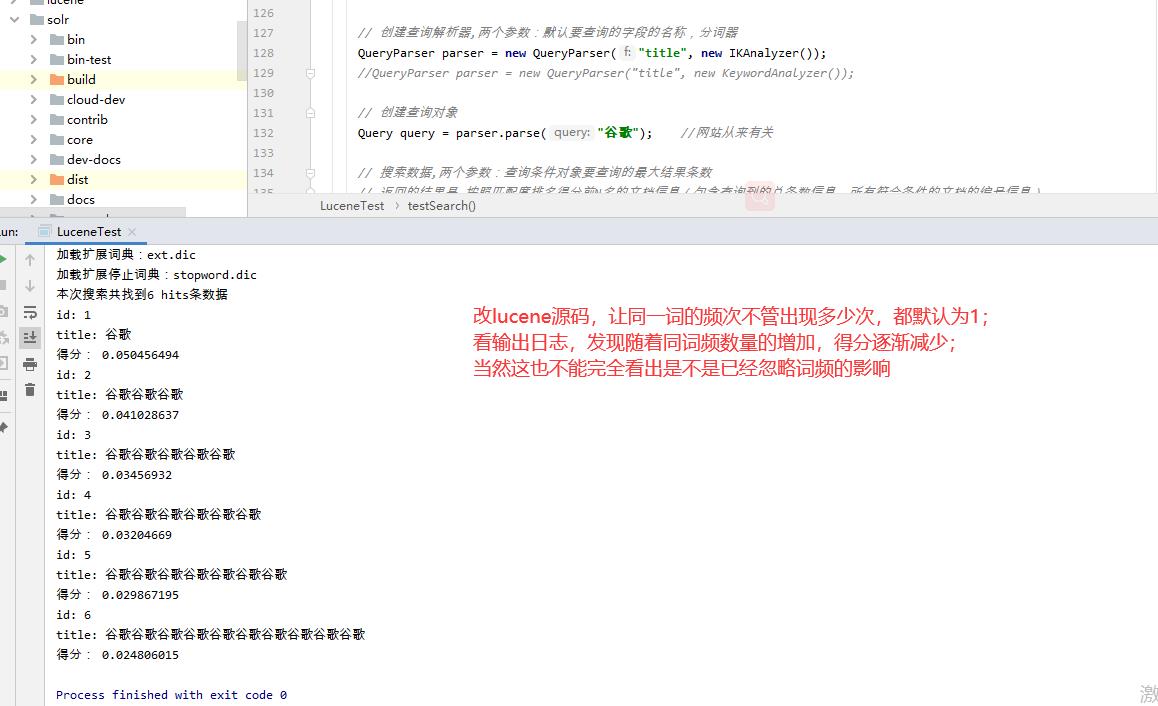
从上面的输出结果中,无法确定已排除词频的影响,接着看

到这里,是不是可以确定已忽略词频这一因素
4. 修改lucene源码,编译构建成到solr应用
主要用到的ant构建task:
-
ant编译lucene-core(由于修改的源码是在lucene-core模块):在lucene-solr 目录下执行 ant compile-core
-
构建solr服务: 在lucene-solr 目录下的 solr 目录,执行ant server
也可以通过idea工具运行ant task
 —
—

5. 两种经典搜索算法的介绍
https://mubu.com/doc/2T8QHvqurPC 密码: j8s2
6.Solr搜索时用到的关键函数
https://www.bbsmax.com/A/B0zqZkrKJv/
7. 6.x以上版本的Solr集成到Tomcat的流程
参考 https://blog.csdn.net/oumuv/article/details/81368144
8. 词频默认为1的配置,未测
在managed-schema文件的field标签内设置
omitTermFreqAndPositions=true|false, 如果设置则省略掉freq和term vector中的地址信息
9. 修改solr_core的数据源时,即更改 导入的数据表以及字段,更改前后的数据是不一样的,注意:
一般更改数据表及字段是 修改solr_core的solr-data-config.xml和managed-schema这两个文件,修改之后重启solr,重新Dataimport是正常执行的,但是Query的时候查出来的全还是旧数据.
解决方法: 删除/【solr_home路径】/【solr_core路径】/下的data目录,重启solr,然后再执行Dataimport操作,等待数据导入和生成索引,之后Query即可
10. IK分词器修改最小分词长度
参考: https://blog.csdn.net/gxl___/article/details/83501344
以上是关于调试并修改Lucene源码的主要内容,如果未能解决你的问题,请参考以下文章