Pandas入门
Posted xiaopihaierletian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas入门相关的知识,希望对你有一定的参考价值。
参考url:Preface | Python Data Science Handbook
描述:笔记
目录
1、pandas对象简介
1.1 Pandas的Series对象
1.2 Pandas的DataFrame对象
1.3 Pandas的Index对象
2、数据取值与选择
2.1 Series数据选择方法
2.2 DataFrame数据选择方法
3、Pandas数值运算方法
3.1 通用函数:保留索引
3.2 通用函数:索引对其
3.3 通用函数:DataFrame与Series的运算
4、处理缺失值
4.1 选择处理缺失值的方法
4.2 Pandas的缺失值
4.3 处理缺失值
5、层级索引
5.1 多级索引Series
5.2 多级索引的创建方法
5.3 多级索引的取值与切片
5.4 多级索引行列转换
5.5 多级索引的数据累计方法
6、合并数据集:Concat与Append操作
6.1 知识回顾:Numpy数组的合并
6.2 通过pd.concat实现简易合并
7、合并数据集:合并与连接
7.1 关系代数
7.2 数据连接的类型
7.3 设置数据合并的键
7.4 设置数据连接的集合操作规则
7.5 重复列名:suffixes参数
8、累计与分组
8.1 行星数据
8.2 Pandas的简单累计功能
8.3 GroupBy:分隔、应用和组合
9、数据透视表
9.1 演示数据透视表
9.2 手工制作数据透视表
9.10 数据透视表语法
10、向量化字符串操作
10.1 Pandas字符串操作简介
10.2 Pandas字符串方法列表
11、处理时间序列
11.1 Python的日期与时间工具
11.2 Pandas时间序列:用时间做索引
11.3 Pandas时间序列数据结构
11.4 时间频率与偏移量
11.5 重新取样、迁移和窗口
12、高性能Pandas:eval()与query()
12.1 query()与eval()的设计动机:复合代数式
12.2 用pandas.eval()实现高性能运算
12.3 用DataFrame.eval()实现列间运算
12.4 DateFrame.query()方法
12.5 性能决定使用时机
1、pandas对象简介
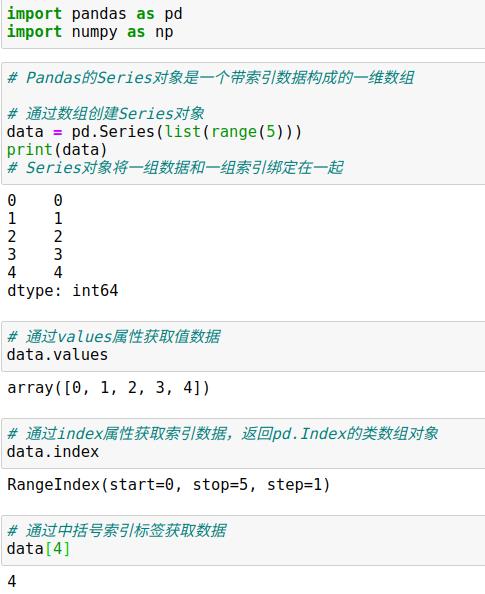
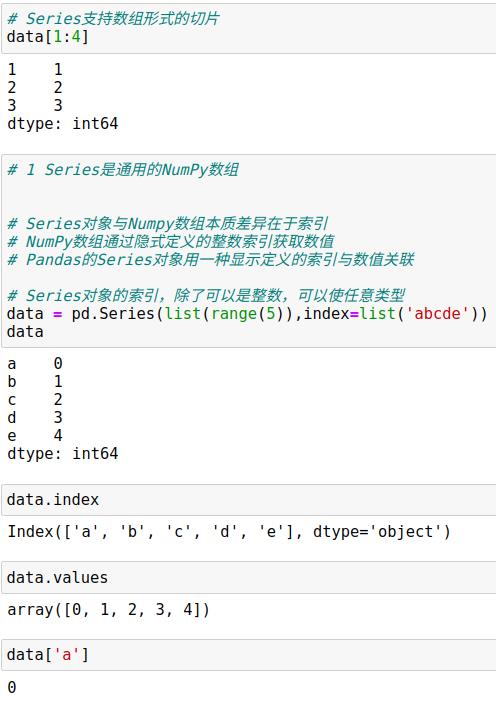
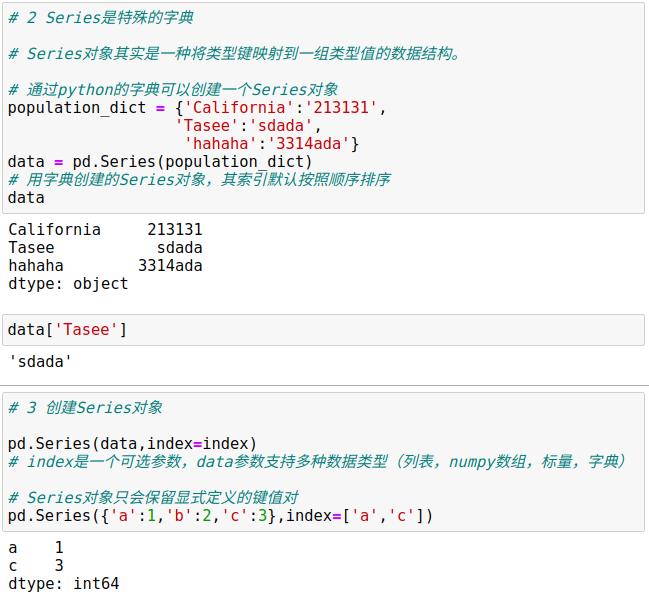
1.1 Pandas的Series对象
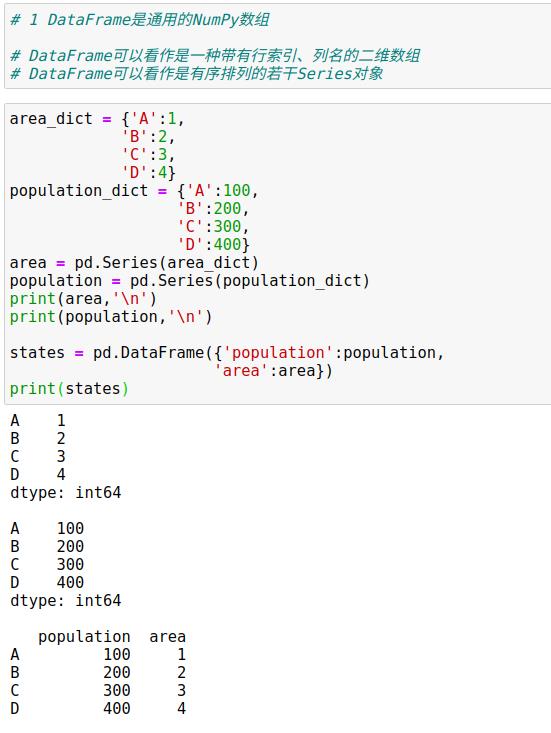
1.2 Pandas的DataFrame对象

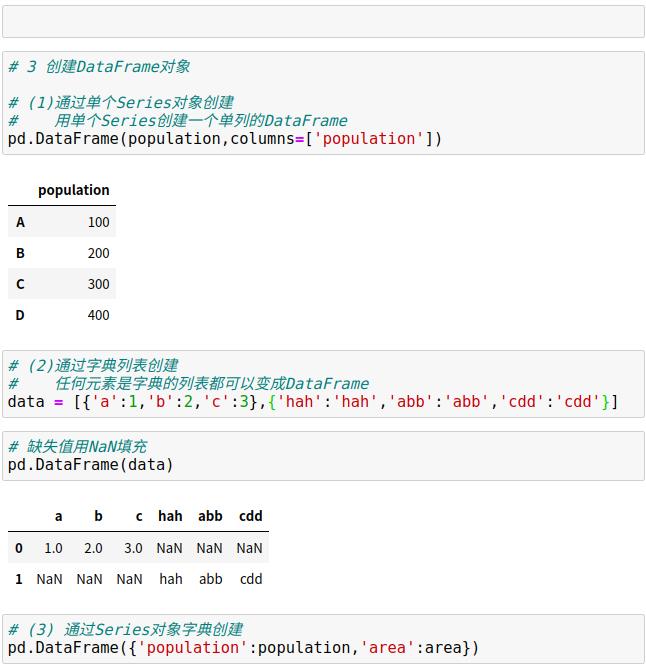

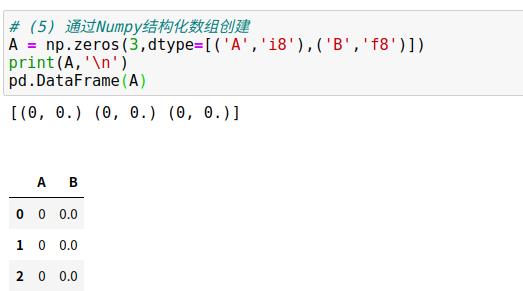
1.3 Pandas的Index对象

2、数据取值与选择
2.1 Series数据选择方法

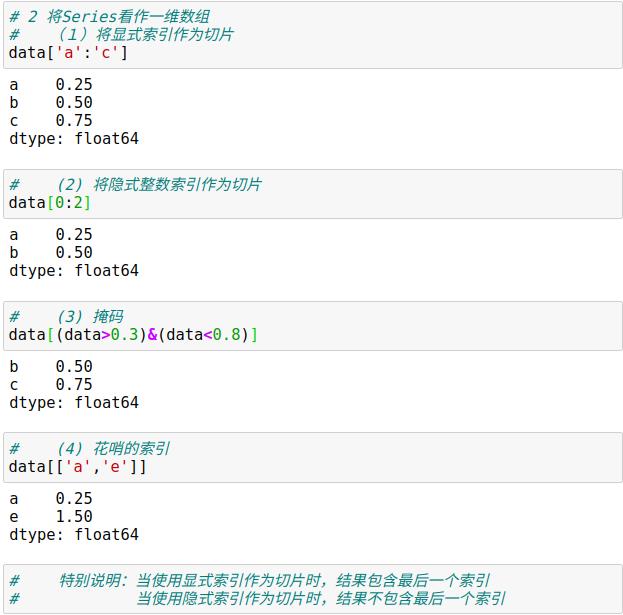
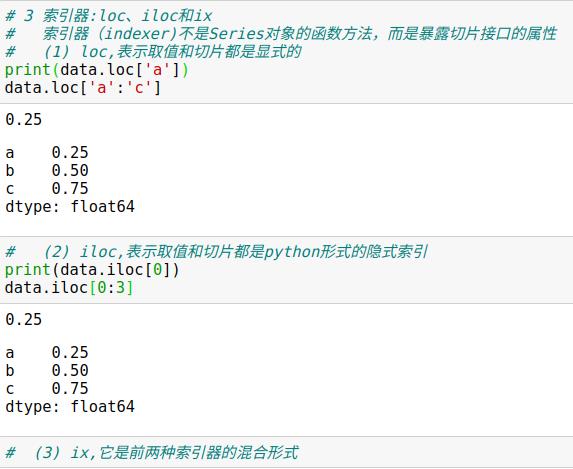
2.2 DataFrame数据选择方法
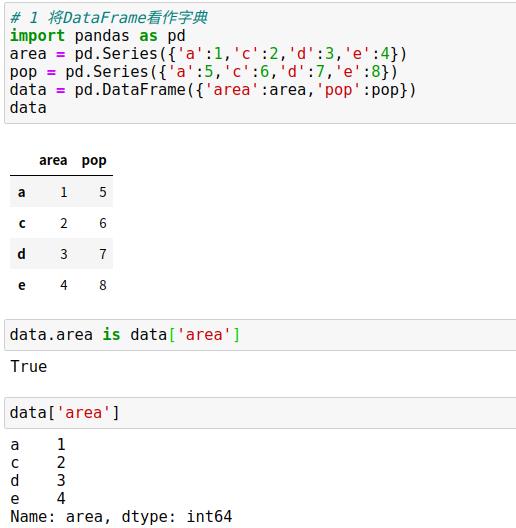
DataFrame在有些方面像二维或结构化数组,在有些方面又像一个共享索引的若干Series对象构成的字典。


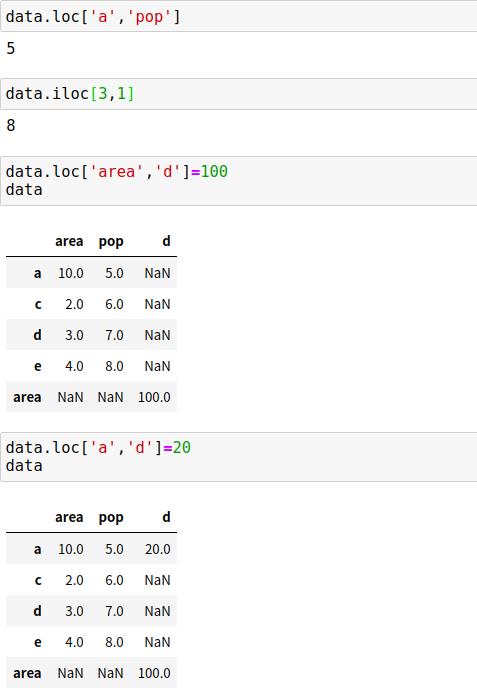

3、Pandas数值运算方法
3.1 通用函数:保留索引


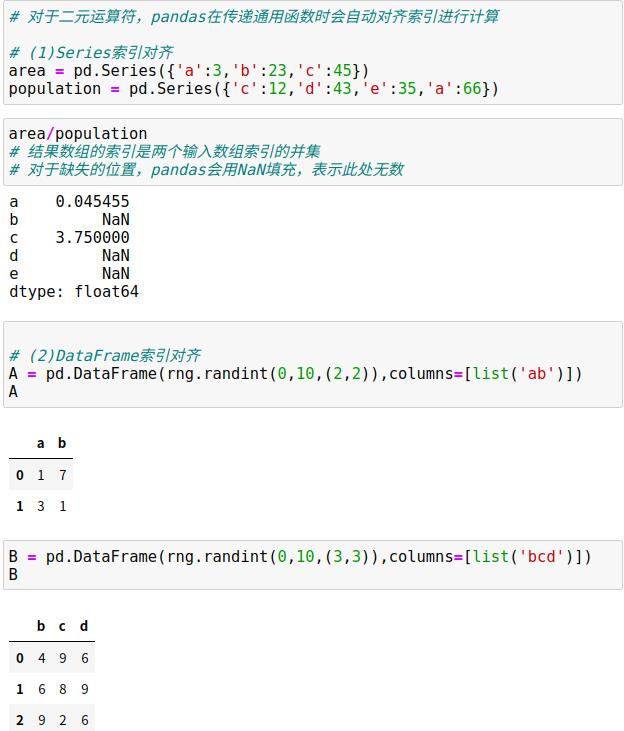
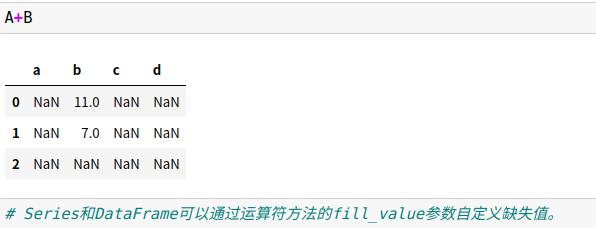
3.2 通用函数:索引对齐
| + | add() |
| - | sub()、subtract() |
| * | mul()、multiply() |
| / | truediv()、div()、divide() |
| // | floordiv() |
| % | mod() |
| ** | pow() |
3.3 通用函数:DataFrame与Series的运算

4、处理缺失值
4.1 选择处理缺失值的方法
一般情况下可以分为两种:一种方法是通过一个覆盖全局的掩码表示缺失值,另一种方法是用一个标签值表示缺失值。
在掩码方法中,掩码可能是一个与原数组维度相同的完整布尔类型数组,也可能是用一个比特(0或1)表示有缺失值的局部状态。
在标签方法中,标签值可能是具体的数据(例如-999表示确实的整数),也有可能是极少出现的形式。
4.2 Pandas的缺失值
pandas选择用标签方法表示缺失值,包括两种python原有的缺失值:浮点数据类型的NaN的值,以及python的None对象。
(1)None:python对象类型的缺失值
缺失值标签None是python单体对象,不能作为任何numpy/pandas数组类型的缺失值,只能用于'object'数组类型(即由python对象构成的数组)
在python中没有定义整数与None之间的加法运算
(2)NaN:数值类型的缺失值
缺失值标签NaN(not a number),是一种按照IEEE浮点数标准设计、在任何系统中都兼容的特殊浮点数
无论和NaN进行何种操作,最终结果都是NaN(NaN看作数据类病毒——将它接触过的数据同化)

numpy的nan版聚合函数,可以忽略缺失值的影响,如np.nansum(),参考url第4节聚合函数:二、NumPy入门 - Norni - 博客园
(3)pandas中NaN与None的差异

| 类型 | 缺失值转换规则 | NA标签值 |
| floating浮点型 | 无变化 | np.nan |
| object对象类型 | 无变化 | None或np.nan |
| integer整数类型 | 强制转换为float64 | np.nan |
| boolean布尔类型 | 强制转换为object | None或np.nan |
4.3 处理缺失值
(1)发现缺失值
isnull()和notnull(),每种方法都返回布尔类型的掩码数据

(2)剔除缺失值
dropna()方法可以剔除缺失值。
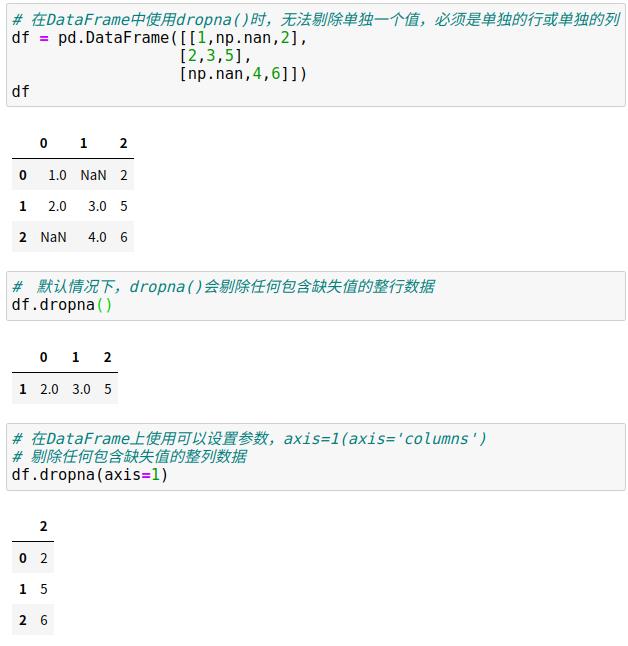
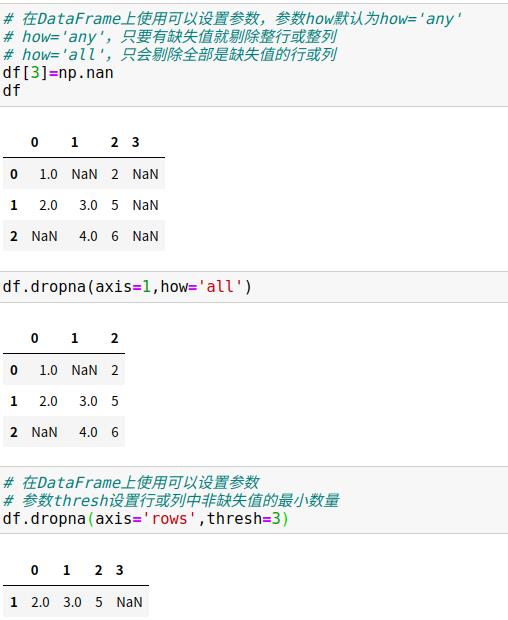
(3)填充缺失值
fillna()方法,将返回填充了缺失值后的数组副本


5、层级索引
5.1 多级索引的创建方法
1、为Series或DataFrame创建多级索引最直接的办法就是将index参数设置为至少二维的索引数组
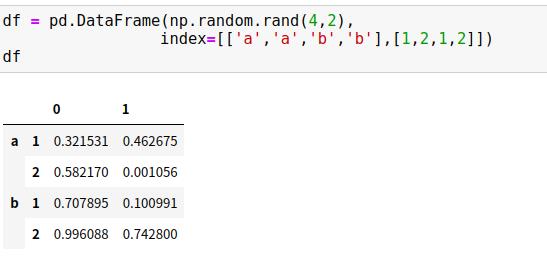
2、将元组作为键的字典传递给pandas
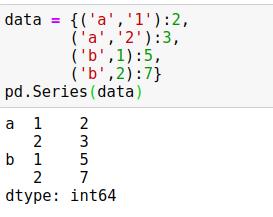
3、显式的创建多级索引

在创建Series或DataFrame时,将MultiIndex对象作为index参数,或通过reindex方法更新Series或DataFrame的索引。
4、高维数据的多级索引
unstack()方法可以快速将一个多级索引的Series转换为普通索引的DataFrame
stack()方法相反
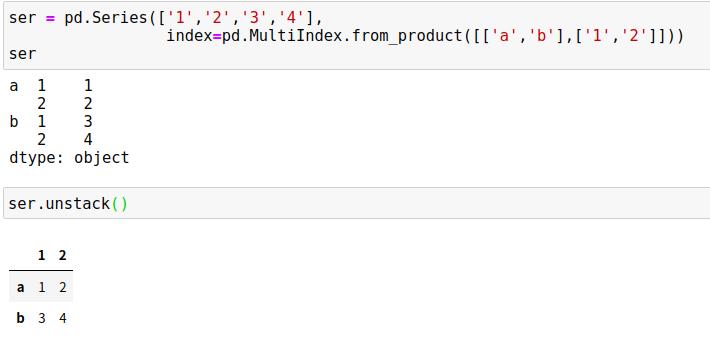
如果可以用含多级索引的一维Series数据表示二维数据,则可以用Series或DataFrame表示三维甚至更高维度的数据。
5、多级索引的等级名称
在MultiIndex构造器中通过names参数设置等级名称,也可以在创建之后通过索引的names属性来修改名称

6、多级列索引
方法类似。
5.2 多级索引的取值与切片
Series的索引与numpy一维数组的索引相似
DataFrame的基本索引是列索引,因此Series中多级索引的用法到了DataFrame中就应用在列上了
与单索引类似,loc、iloc都索引器都可以使用
pandas内置的IndexSlice对象,可以用来实现DataFrame多级索引的切片

5.3 多级索引行列转换
1、有序索引和无序索引
局部切片需要保证索引有序,否则会出现错误
通过sort_index()和sortlevel()方法实现索引排序
2、索引stack和unstack
将一维多级索引数据转换为简单的二维形式,可以通过level参数设置转换的索引层级
3、索引的设置与重置

5.4 多级索引的数据累计方法
对于层级索引数据,可以设置参数level实现对数据子集的累计操作,参数axis设置行或列

6、合并数据集:Concat与Append操作
6.1 知识回顾:Numpy数组的合并
参考url中2.5:二、NumPy入门 - Norni - 博客园
6.2 通过pd.concat实现简易合并
pandas的pd.concat()函数与np.concatenate语法类似。


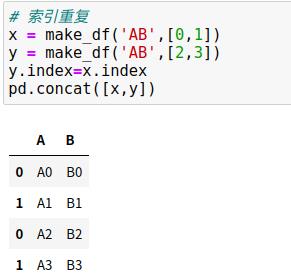
1、重复索引
np.concatenate与pd.concat最主要的差异之一是pandas在合并时会保留索引,即使索引是重复的。

2、类似join的合并
DataFrame在默认情况下,某个位置缺失的数据会用NaN表示
默认的合并方式是对所有输入列进行并集合并(即join='outer'), join='inner'则是实现对输入列的交集合并

3、append()方法
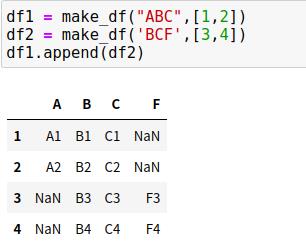
与python列表中的append()和extend()方法不同,pandas的append()不直接更新原有对象的值,而是为合并后的数据创建一个新对象。
7、合并数据集:合并与连接
pandas的基本特性之一就是高性能的内存式数据连接(join)与合并(merge)操作
pandas的主接口是pd.merge函数
7.1 关系代数
pd.merge()实现的功能基于关系代数(relational algebra)的一部分。
关系代数方法论的强大之处在于,它提出的若干简单操作规则经过组合就可以为任意数据集构建十分复杂的操作。
7.2 数据连接的类型
pd.merge()函数实现了三种数据连接的类型:一对一,多对一和多对多。
1、一对一连接


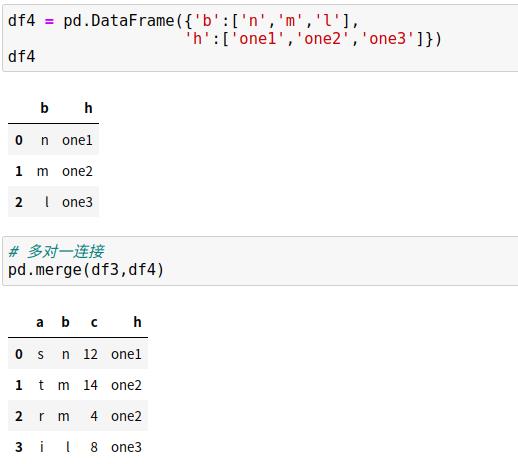
2、多对一连接
多对一连接指在需要连接的两个列中,有一列的值有重复,结果保留重复值。
3、多对多连接
如果左右两个输入的共同列都包含重复值,那么合并的结果就是一种多对多连接
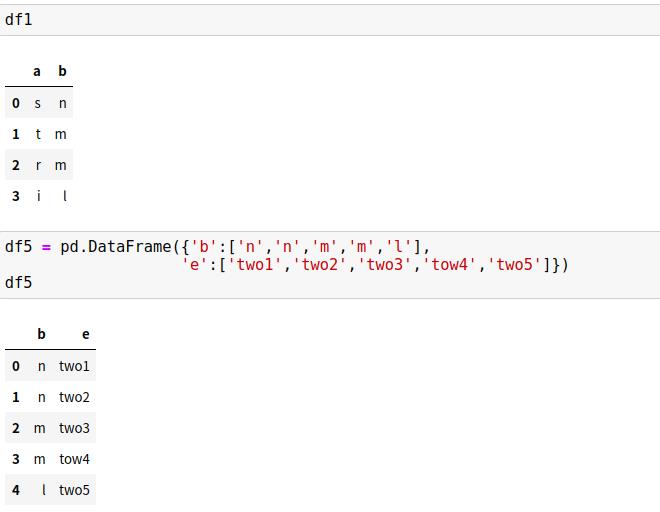

7.3 设置数据合并的键
1、合并列时参数on的用法
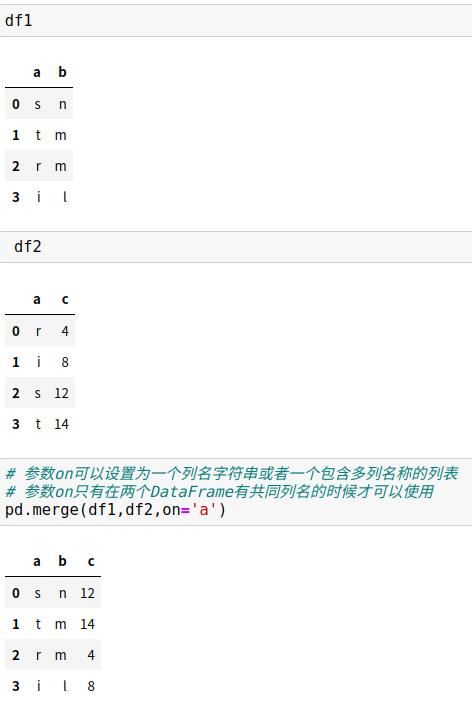
2、合并列时,left_on和right_on参数
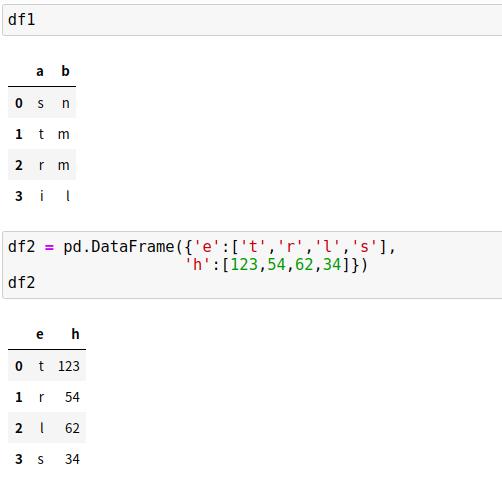

3、合并索引时,设置left_index与right_index参数

4、DataFrame实现了join()方法,也可以按照索引进行数据合并

7.4 设置数据连接的集合操作规则
当一个值出现在一列,却没有出现在另一列时,则可以考虑集合操作

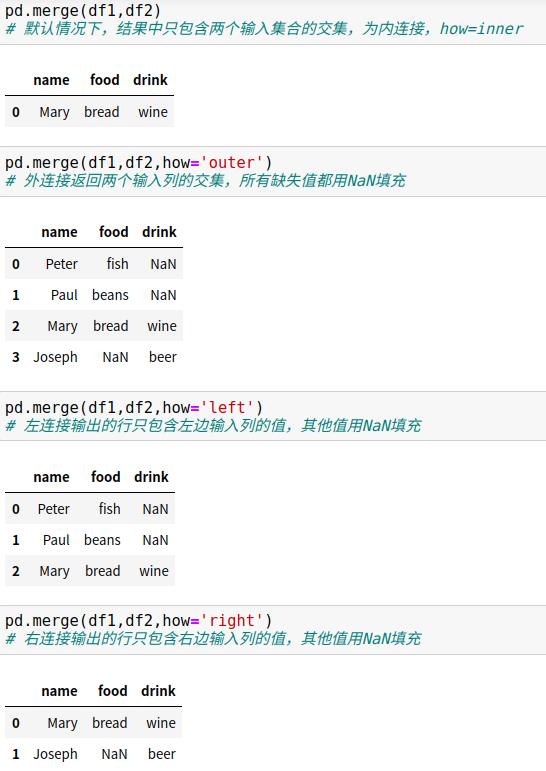
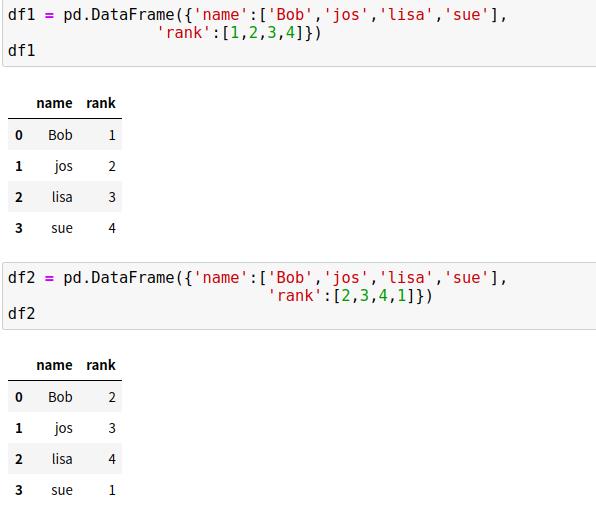
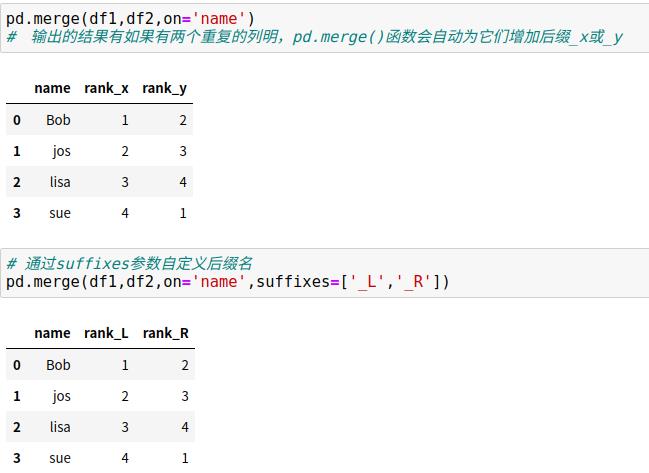
7.5 重复列名:suffixes参数
8、累计与分组
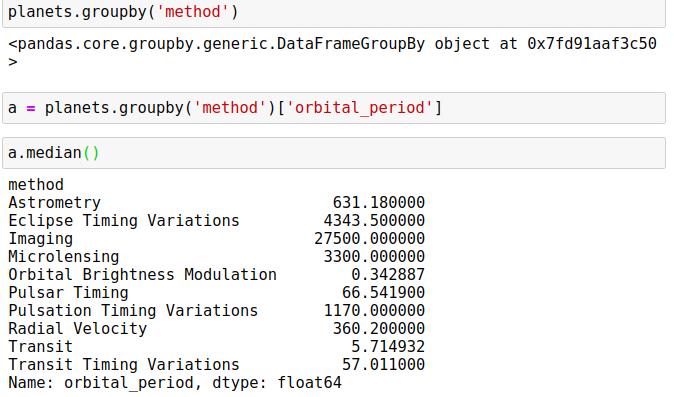
8.1 行星数据

8.2 Pandas的简单累计功能
describe()方法可以计算每一列的若干常用统计值。
| 指标 | 描述 |
| count() | 计数项 |
| first()、last() | 第一项与最后一项 |
| mean()、median() | 均值与中位数 |
| min()、max() | 最小值与最大值 |
| std()、var() | 标准差与方差 |
| mad() | 均值绝对偏差(mean absolute deviation) |
| prod() | 所有项乘积 |
| sum() | 所有项求和 |
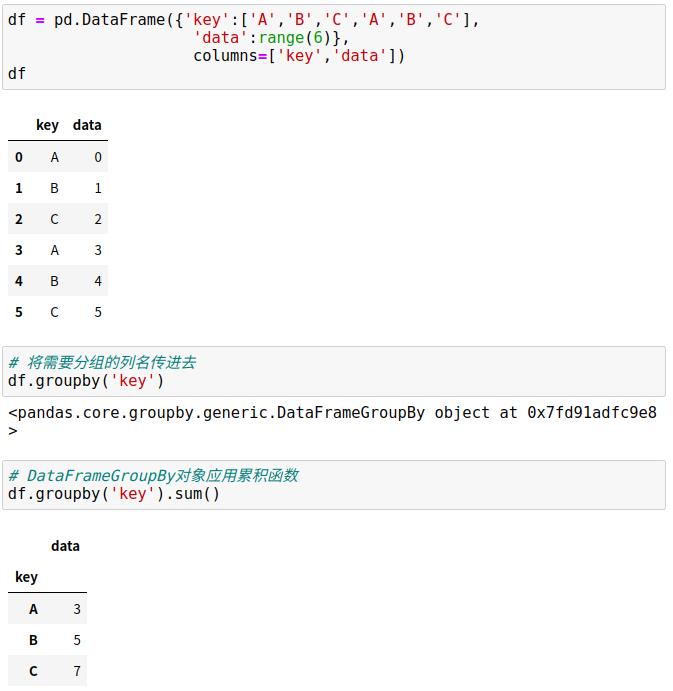
8.3 GroupBy:分割、应用和组合
1、分割(split)、应用(apply)和组合(combine)
2、GroupBy对象
GroupBy对象中最重要的操作是aggregate、filter、transform和apply(累计、过滤、转换和应用)
GroupBy的基本操作:
(1)按列取值
(2)按组迭代

(3)调用方法

3、累计、过滤、转换和应用

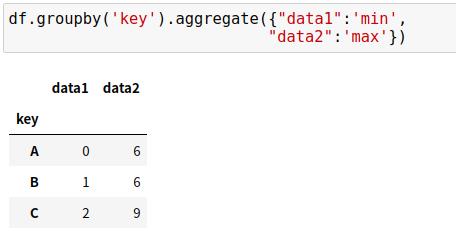
(1)累计
aggregate()支持更复杂的操作,比如字符串、函数或者函数列表,并且能一次性计算所有累计值

支持通过python字典指定不同列需要累计的函数
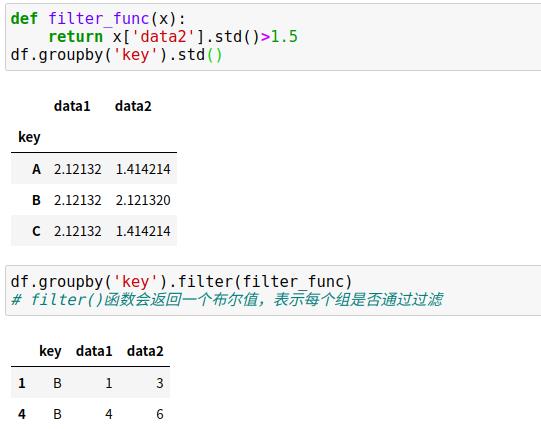
(2)过滤
过滤操作可以按照分组的属性丢弃若干数据
(3)转换
数据经过转换之后,其形状与原来的输入数据是一样的。

(4)应用
apply()方法能在每个组上应用任意方法
apply()函数输入一个DataFrame,返回一个Pandas对象(DataFrmae或Series)或一个标量(scalar,单个数值)

4、设置分割的键
(1)将列表、数组、Series或索引作为分组键
分组键可以是长度与DataFrame匹配的任意Series或列表。

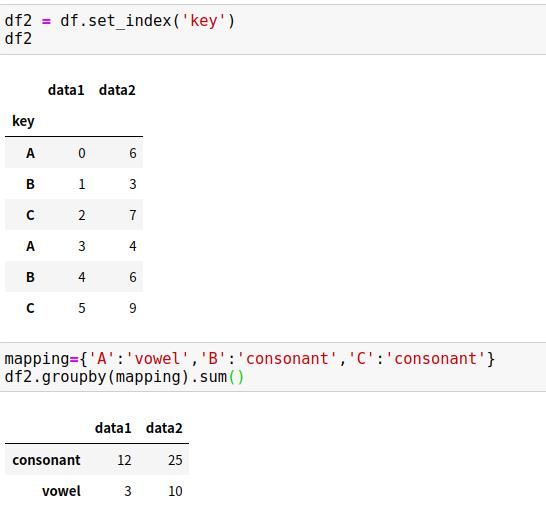
(2)用字典或Series将索引映射到分组名称。
另一种方法是提供一个字典,将索引映射到分组键
(3)任意Python程序
将任意python函数传入GroupBy,函数映射到索引,然后新的分组输出
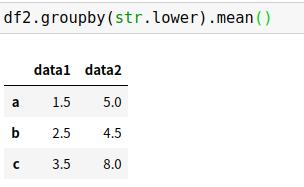
(4)多个有效键构成的列表
任意之前有效的键都可以组合起来进行分组,从而返回一个多级索引的分组结果

9、数据透视表
9.1 手工制作数据透视表

通过标准的groupby分组方法可以手工的制作数据透视表
9.2 数据透视表语法

1、多级数据透视表
pd.cut函数能将特定标签分段,如age=[0,18,80]
通过指定参数index或columns的值能够透视多个等级
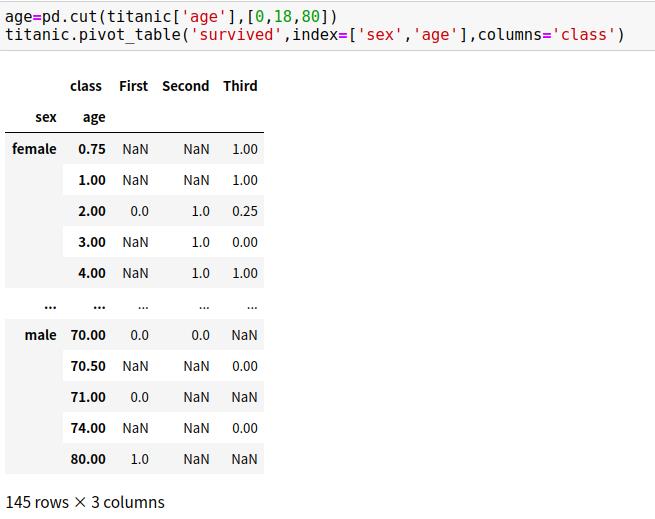

2、其他数据透视表选项
fill_value和dropna这两个参数用于处理缺失值。
aggfunc参数用于设置累计函数类型,默认为均值(mean),累计函数可以是常见的字符串('sum','count'等),也可以是标准的累计函数(np.sum()、np.min()等)。

10、向量化字符串操作
10.1 Pandas字符串操作简介
Pandas为包含字符串的Series和Index对象提供的str属性,即可以满足向量化字符串操作的需求,又可以正确地处理缺失值。

10.2 Pandas字符串方法列表
1、与python字符串相似的方法列表
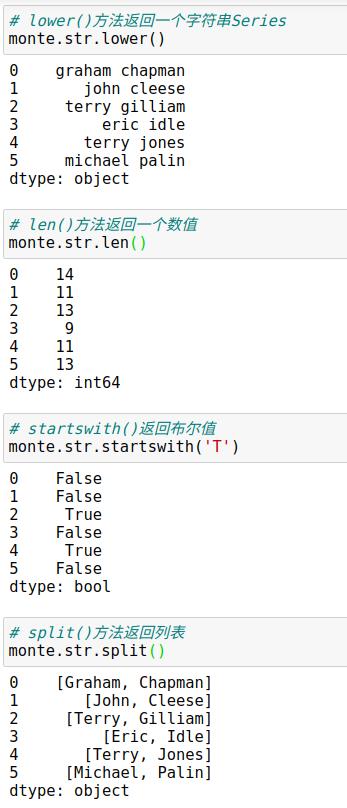
2、使用正则表达式方法
Pandas向量化字符串方法是根据python标准库的re模块函数实现的API
| 方法 | 描述 |
| match() | 对每个元素调用re.match(),返回布尔类型值 |
| extract() | 对每个元素调用re.match(),返回匹配的字符串组(groups) |
| findall() | 对每个元素调用re.findall() |
| replace() | 用正则表达式替换字符串 |
| contains() | 对每个元素调用re.search(),返回布尔类型值 |
| count() | 计算符合正则模式的字符串的数量 |
| split() | 等价于str.split(),支持正则表达式 |
| rsplit() | 等价于str.rsplit(),支持正则表达式 |
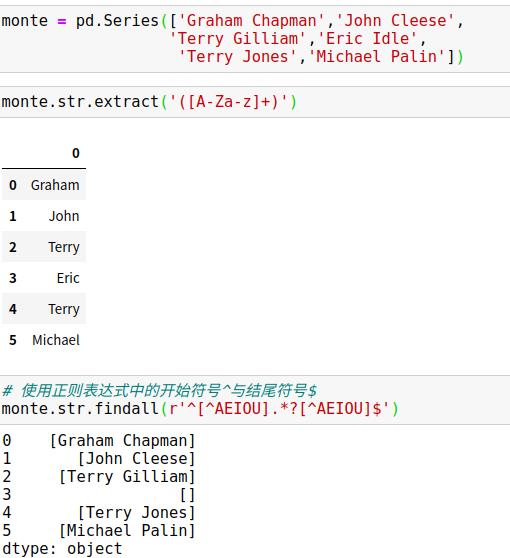
3、其他字符串方法
| get() | 获取元素索引位置上的值,索引从0开始 |
| slice() | 对元素进行切片取值 |
| slice_replace() | 对元素进行切片替换 |
| cat() | 连接字符串 |
| repeat() | 重复元素 |
| normalize() | 将字符串转换为Unicode规范形式 |
| pad() | 在字符串的左边、右边或两边增加空格 |
| wrap() | 将字符串按照指定的宽度换行 |
| join() | 用分隔符连接Series的每个元素 |
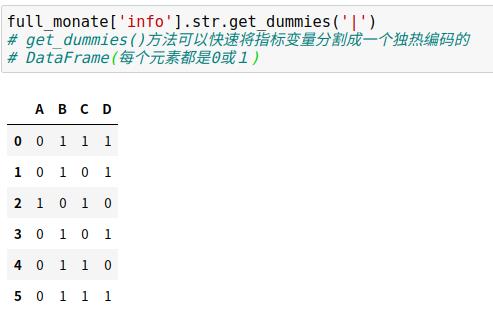
| get_dummies() | 按照分隔符提取每个元素的dummy变量,转换为独热(one-hot)编码的DataFrame |
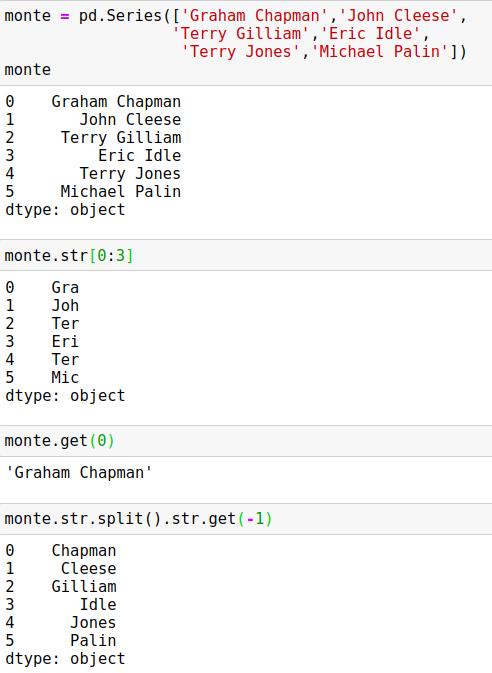
(1)向量化字符串的取值与切片操作
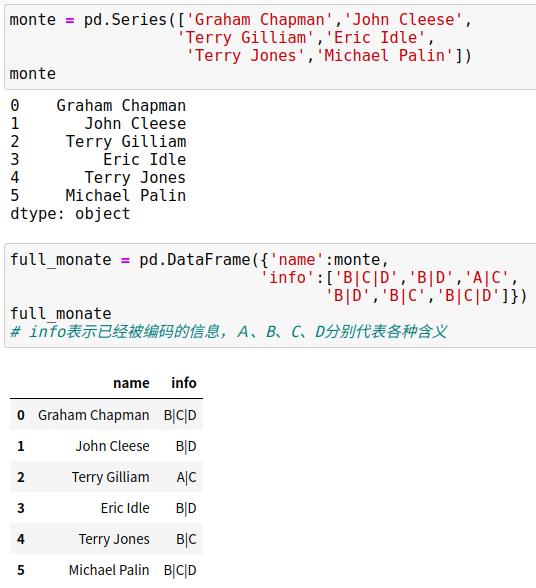
(2)指标变量
11、处理时间序列
11.1 Python的日期与时间工具
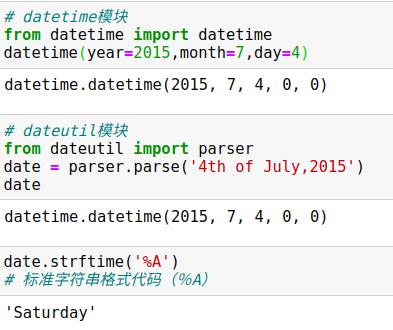
1、原生python的日期与时间工具:datatime与dateutil
2、时间类型数组:Numpy的datetime64类型
datetime64类型将日期编码为64为整数

datetime64与timedelta64对象的一个共同特点是,它们都是在基本时间单位的基础上建立的。
datetime64对象是64位精度,所以可编码的时间范围可以是基本单元的2^64倍。
3、Pandas的日期与时间工具
pandas所有关于日期与时间的处理方法全部都是通过Timestamp对象实现的,它利用numpy.datetime64的有效存储和向量化接口将datatime和datautil的易用性有机结合起来。
pandas通过一组Timestamp对象就可以创建一个可以作为Series或DataFrame索引的DatatimeIndex。

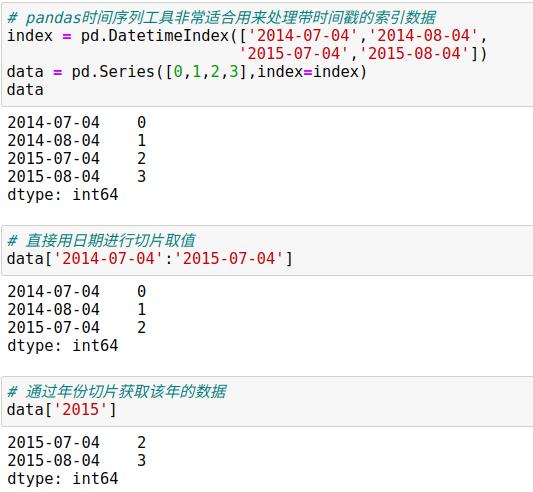
11.2 Pandas时间序列:用时间做索引
11.3 Pandas时间序列数据结构
Pandas用来处理时间序列的基础数据类型:
(1)针对时间戳,pandas提供Timestamp类型,对应的索引数据结构是DatetimeIndex
(2)针对时间周期数据,pandas提供了Period类型,对应的索引数据结构是PeriodIndex
(3)针对时间增量或持续时间,pandas提供了Timedelta类,对应的索引数据结构是TimedeltaIndex
pd.to_datetime()函数,可以解析很多日期与时间格式,对其传递一个日期会返回一个Timestamp类型,传递一个时间序列会返回一个DatetimeIndex类型

pd.date_range(start,end,频率代码(可选))创建规律时间戳序列
pd.timedelta_range()处理规律时间间隔
pd.period_range()处理周期

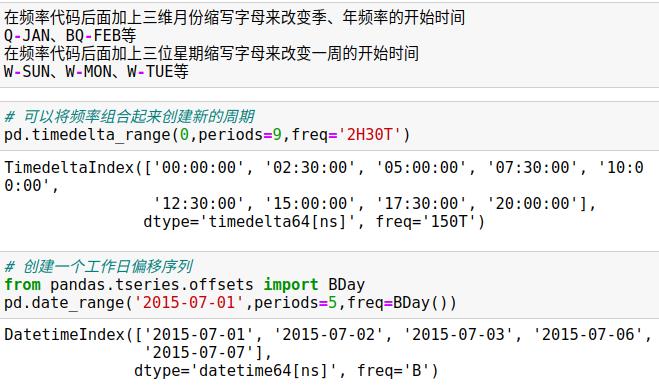
11.4 时间频率与偏移量
pandas时间序列工具的基础是是时间频率或偏移量(offset)代码
| 代码 | 描述 | 代码 | 描述 |
| D | 天(calendar day,按日历算,含双休日) | B | 天(business day ,仅含工作日) |
| W | 周(weekly) | ||
| M | 月末(month end) | BM | 月末(business month end,仅含工作日) |
| Q | 季末(quarter end) | BQ | 季末(business quarter end,仅含工作日) |
| A | 年末(year end) | BA | 年末(business quarter end,仅含工作日) |
| H | 小时(hours) | BH | 小时(business hours,工作时间) |
| T | 分钟(minutes) | ||
| S | 秒(seconds) | ||
| L | 毫秒(milliseconds) | ||
| U | 微秒(microseconds) | ||
| N | 纳秒(nanoseconds) |
月、季、年频率都是具体周期的结束时间(月末、季末、年末)
| 代码 | 频率 |
| MS | 月初(month start) |
| BMS | 月初(business month start,仅含工作日) |
| QS | 季初(quarter start) |
| BQS | 季初(business quarter start,仅含工作日) |
| AS | 年初(year start) |
| BAS | 年初(business year start, 仅含工作日) |
以S为后缀的代码表示日期开始
11.5 重新取样、迁移和窗口

1、重新取样与频率转换
处理时间序列数据时,经常需要按照新的频率(更高频率、更低频率)对数据进行重新取样,resample和asfreq方法实现。
resample()和asfreq()这两个方法的区别:resample()方法是以数据累计(data aggregation)为基础,而asfreq()方法是以数据选择(data selection)为基础

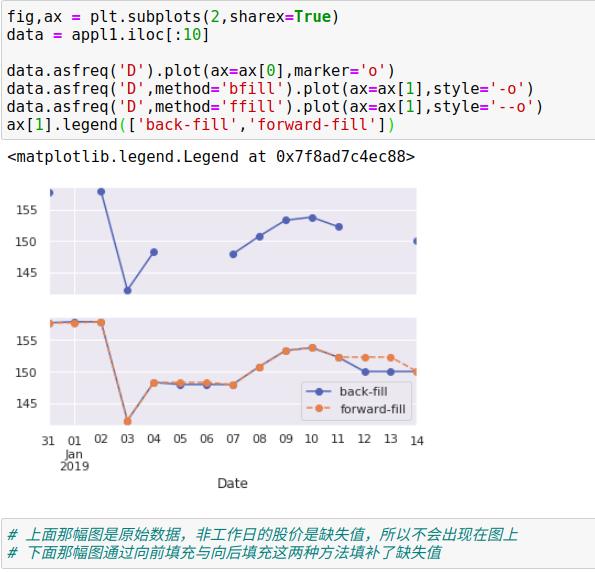
2、时间迁移
另一种常用的时间序列操作是对数据按时间进行迁移,通过方法shift()和tshift()。
shift()就是迁移数据,而tshift()是迁移索引,两种方法都按照频率代码进行迁移。

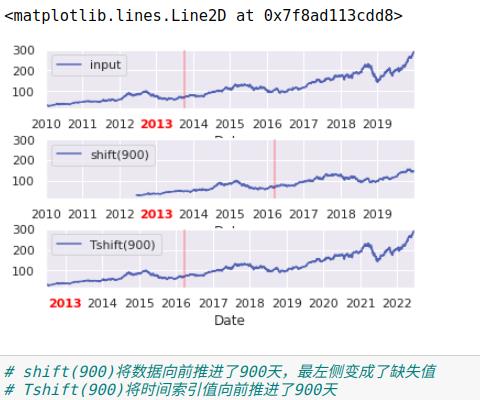
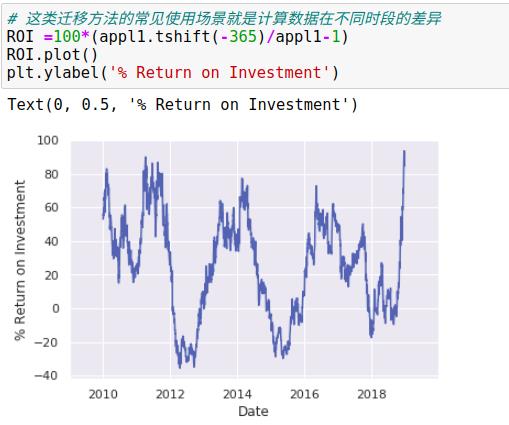
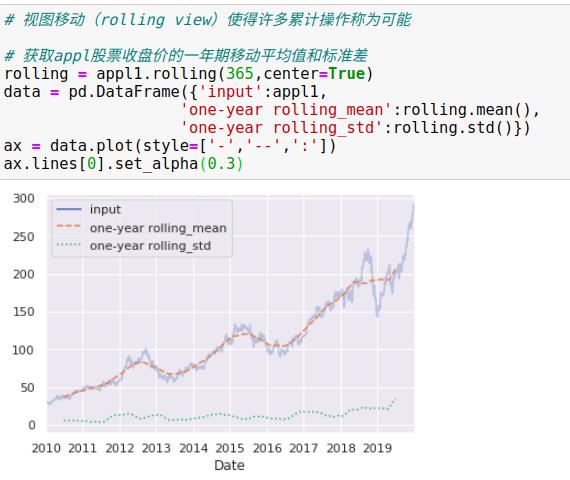
3、移动时间窗口
pandas处理时间序列数据的第3种操作是移动统计值(rolling statistics),这些指标可以通过Series和DataFrame的rolling()属性来实现,它会返回与groupby操作类似的结果。
12、高性能Pandas:eval()与query()
12.1 query()与eval()的设计动机:复合代数式
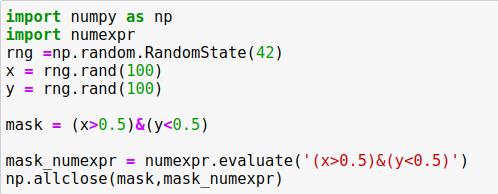
Numexpr程序库可以在不为中间过程分配全部内存的前提下,完成元素到元素的复合代数式运算。
12.2 用pandas.eval()实现高性能运算
pandas的eval()函数用字符串代数式实现了DataFrame的高性能运算

pd.eval()支持许多运算:
(1)算术运算符

(2)比较运算符

(3)对象属性与索引

12.3 用DataFrame.eval()实现列间运算
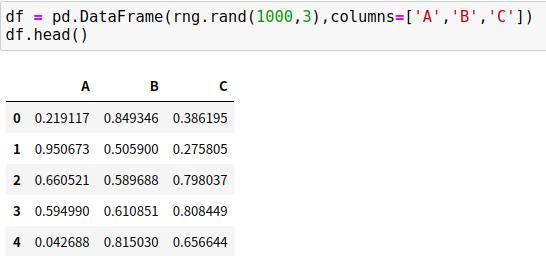
pd.eval()可以借助列名称进行运算


1、用DataFrame.eval()新增列和修改已有的列

2、DataFrame.eval()使用局部变量
DataFrame.eval()方法支持通过@符号使用python的局部变量

@符号表示'这是一个变量名称而不是一个列名称',从而可以灵活的用两个'命名空间'的资源(列名称的命名空间和python对象的命名空间)计算代数式。
由于pandas.eval()函数只能获取一个(python)命名空间的内容,所以@符号只能在DataFrame.eval()方法中使用,而不能在pandas.eval()函数中使用。
12.4 DateFrame.query()方法
12.5 性能决定使用时机
以上是关于Pandas入门的主要内容,如果未能解决你的问题,请参考以下文章