SparseArray 那些事儿(带给你更细致的分析)
Posted 思忆(GeorgeQin)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparseArray 那些事儿(带给你更细致的分析)相关的知识,希望对你有一定的参考价值。
前言
说到android 常用的数据结构,那不得不提一下SparseArray(稀疏数组),我们在很多业务以及Android源码中能见到
基本介绍 (Whate)
简单来讲就是一个使用int作为Key的 Map ,官网的介绍就是:
SparseArrays map integers to Objects
继承关系:
它继承自Object,实现了Cloneable:
public class SparseArray<E> implements Cloneable
其中E就是我们的泛型参数,即我们要存入数据的类型
构造方法:
public SparseArray()
this(10);
public SparseArray(int initialCapacity)
我们可以看到,它有两个构造方法,一个参数为容量大小,另一个无参构造方法,最终调用的是容量为10的的构造方法。
增删改查:
既然是一个数据结构,当然要从增删改查来介绍它的基本用法:
使用方法(How)
增:
提供了put和append方法让使用可以放以int 作为key,任何类型作为值的数据。
public void put(int key, E value)
public void append(int key, E value)
删:
当然也就是指定某个key去删除
public void delete(int key)
public void remove(int key)
也可以删除某个key之后返回删除那个key的值:
public E removeReturnOld(int key)
因为SparseArray 内部存储是用数组实现的,所以提供了按照数组下标来移除元素的功能(使用的时候要注意数组越界的问题):
public void removeAt(int index)
还提供了基于数组下标的范围移除的功能(比如从数组的第1个开始往后移除大小3个的):
public void removeAtRange(int index, int size)
改:
还提供了可以修改某个下标对应值的方法
public void setValueAt(int index, E value)
查:
根据我们存入的key找到我们的值
public E get(int key)
public E get(int key, E valueIfKeyNotFound)
还可以根据数组下标获取值
public E valueAt(int index)
同样可以根据下标获取key:
public int keyAt(int index)
也可以根据我们的key或者value反查出下标:
public int indexOfKey(int key)
public int indexOfValue(E value)
public int indexOfValueByValue(E value)
- 特别说明:
indexOfValue方法通过value值查下标的话,如果多个key都使用了相同的value,只会返回升序查找的第一个符合要求的下标,
其他功能
//大小
public int size()
//清空
public void clear()
看完这里基本用法已经是都介绍完了,当然了解事物三部曲: 是什么、怎么用都讲了,最后一步为什么当然也不能少,下面就来细讲讲它都实现原理:
主要源码分析 (Why)
为了方便理解,我们先从get方法开始分析:
public E get(int key, E valueIfKeyNotFound)
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED)
return valueIfKeyNotFound;
else
return (E) mValues[i];
get方法最终调用的是这个方法,方法第一行首先调用了ContainerHelpers.binarySearch(mKeys, mSize, key)方法,这个方法接受三个参数,第三个是我们即将存数据所指定的key,第一个和第二个是我们的全局变量,分别是存我们所有key的数组和 当前存入数据的大小:
//存放我们的key
private int[] mKeys;
//存放我们的值
private Object[] mValues;
//表示存入数据量的大小
private int mSize;
从这里我们也能看到,我们的存入的键值对分别被存到量两个数组中,然后用一个全局变量表示当前存入数据量的大小,那为何要单独用一个变量来表示它的大小而不是这两个数组的长度呢?这个我们后面讲。
现在参数以及含义都知道了,我们来看看这个方法,这个方法其实就是SparseArray核心的二分查找法,后面存取等操作都会有它到身影,我们来分析一下:
核心的二分查找法:
/**
* 找到目标key的 位置
*
* @param keysArray 存key的数组
* @param size 数组的大小
* @param targetKey 要找的key
* @return 如果找到了返回相应的key ,
* 若未找到,则返回这个key应该被存放的位置的取反 ~location
*/
static int binarySearch(int[] keysArray, int size, int targetKey)
//位置(初始值为0)
int location = 0;
//查找上限
int ceiling = size - 1;
//二分法查找
while (location <= ceiling)
//除以二取先中间的key
final int mid = (location + ceiling) >>> 1;
final int midKey = keysArray[mid];
if (midKey < targetKey)
location = mid + 1;
else if (midKey > targetKey)
ceiling = mid - 1;
else
return mid; // key found
//此时location的值就是它应该被存储的到数组的位置(0或者length+1)
return ~location; // key not present
我这边把源码中的命名稍微改了一下,让理解起来更容易一点,那么整体看下来,就是从我们存key的数组去找我们的targetKey,如果找到了,则直接返回,没找到返回一个负值
分析:
一开始定义初始位置为0,上限即整个大小,然后当我们当位置小于或者等于上限时候开始循环查找,第9行,对初始位置和上限的和做一个无符号右移,也就是除以2,然后取到位于中间的key,通过比较目标key和中间key的大小去确定确定下次查找的范围,如果中间的值小,说明在中间范围以上,所以下次开始查找的范围的起始位置就是中间位置+1,再次执行循环体的内容,如果找到了则直接返回,如果始终没找到,返回location的取反,其中取反和无符号涉及到位运算,如果还不是特别了解可以参考这里,无论最终location = 0或者length+1 ,它的取反都是一个负数。
细节:
- 如果没找到key 此时到location其实就是该值应该被放置到数组中到位置,此时返回到location到取反~ ,是一个负值,再次取反便可还原该值,在put方法中就有还原这个值对操作。
- 根据二分查找方法可知,我们key的存储顺序是按key大小升序排列的。
再次回到我们的get方法,现在看下来就简单了,i就是我们要找key的位置下标,如果小于0,就表示未找到该key,直接返回未找到,否则返回Value中的第i个元素。
if (i < 0 || mValues[i] == DELETED)
return valueIfKeyNotFound;
else
return (E) mValues[i];
再看另一个条件:mValues[i] == DELETED他其实表示的是存值数组中的第i个元素被删除了,进一步探究,我们再来看看它的删除方法
(delete方法和Remove其实都是一个方法):
删除
public void delete(int key)
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0)
if (mValues[i] != DELETED)
mValues[i] = DELETED;
mGarbage= true;
还是我们熟悉的二分查找法,首先找到这个key对应的数组下标,如果大于或者等于0,表示存在,此时如果还没有被删除,将该位置负值为DELETE,然后将mGarbage标记为置为ture,表示要进行垃圾回收,而DELETED就是一个Object,用于表示该位置的元素被删除了。
private static final Object DELETED = new Object();
那么再回到刚刚的get方法的第二个条件,当存值的数组中被标记为删除之后,即使数组给该下标分配了空间,也会认为key对应的值不存在,而我们的delete操作只是给值中的元素做了标记操作,并没有对数组对象做一些操作,不会像ArrayList 会对数组做移位操作。
思考
到这里再回想一下,一开始为何要设置全局标记位mSize而不是数组的长度来表示size了吧?因为即使我一个原来有值的某一个元素被删除了,而数组大小并没有随之变小,而实际上这个size肯定要减少一个,带着思考,我们来看看size()方法:
public int size()
if (mGarbage)
gc();
return mSize;
首先第一个判断条件就是我们删除操作中的标识位,当执行了删除操作以后,执行gc方法,执行完成后返回全局的mSize,那么我们跟进这个gc方法,看看到底做了什么:
private void gc()
//原始大小
int originSize = mSize;
//回收之后的大小
int afterGcSize = 0;
int[] keys = mKeys;
Object[] values = mValues;
for (int i = 0; i < originSize; i++)
Object val = values[i];
//如果该位置的元素没有被删除
if (val != DELETED)
//一旦这两个值不相等(只要一个元素发生了删除,该元素以后这两个值始终不相等,并且afterGcSize始终小于 i)
if (i != afterGcSize)
//元素移位操作
//将第i个的元素移到 上一个位置
keys[afterGcSize] = keys[i];
values[afterGcSize] = val;
values[i] = null;
//没有删除元素就自增
afterGcSize++;
mGarbage = false;
mSize = afterGcSize;
这边把方法命名重新修改了一下,方便阅读,那么整个方法下来,其实就是数组元素移位,将标记为删除元素之后的元素往前移动到该位置,mSize被重新被赋值为为afterGcSize的大小即真正未删除元素的大小,然后将mGarbage重置为false。
例子:
如果为有一个keys为[-1,2,4]对应值为[A,B,C]的SparseArray,为现在将Key为2的删除,下面用动图模拟一下当调用size时候执行gc的过程:
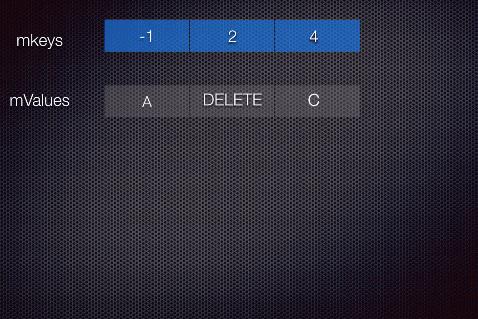
其中 i 表示循环执行的次数,注意看afterGcSize 变化的时机,然后最后gc后的状态,请大家记住,后面还能用到。

gc之后 size = 2, 但是values数组长度还是3
小结:
gc过程就是把元素前移去填补删除到元素,然后返回真正存在元素到大小作为size,这也再次解释了为什么全局会有一个mSize而不是使用数组长度作为size了。
改
我们再来继续看看改的方法,第一个方法还是我们刚刚看过的对检查并gc的方法,gc过后然后和对相应下标做赋值操作:
public void setValueAt(int index, E value)
if (mGarbage)
gc();
mValues[index] = value;
看完这些,我们再回过头来分析我们“最复杂”的方法-增:
增:
先来看看put:
public void put(int key, E value)
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0)
mValues[i] = value;
else
i = ~i;
if (i < mSize && mValues[i] == DELETED)
mKeys[i] = key;
mValues[i] = value;
return;
if (mGarbage && mSize >= mKeys.length)
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
- 第一行先根据之前分析的方法获得下标,如果下标大于0表示该key已经存在,我们直接将存值数组对应的下标进行赋值。
- 重点看else中的逻辑,之前我们分析过了,如果 i小于0 则表示目前数组中不存在该key,并且对i做~(取反)操作即能得到他在数组中应该被存放对位置,再看到第8行,其实这个逻辑是一个重用操作,如果i应该被存放的位置的元素被标记为删除了,很好,直接把对应下标的key和value替换。
- 此时再回想一下此时的状态: 即使删除标记的位置也没匹配上我的下标,so,需要把垃圾清理一下(14行gc),再重新计算一下我们的下标(因为gc之后,删除标记位之后的元素会移动位置,再次计算可能位置就变了)。
- gc之后,我们便看到了类似于insert的方法,分别对keys和values的数组做了处理,最好mSize增加一位,看上去像是数组扩容?我们来一探究竟:
public static int[] insert(int[] array, int currentSize, int index, int element)
assert currentSize <= array.length;
if (currentSize + 1 <= array.length)
System.arraycopy(array, index, array, index + 1, currentSize - index);
array[index] = element;
return array;
int[] newArray = new int[growSize(currentSize)];
System.arraycopy(array, 0, newArray, 0, index);
newArray[index] = element;
System.arraycopy(array, index, newArray, index + 1, array.length - index);
return newArray;
5.首先我们以Keys的调用来分析入参:
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
分别传入的是存Key的数组,当前大小,即将存放key的下标、即将被存放的key。
方法中第一个if体:我们的mSize小于或者等于数组的长度执行一部分逻辑,注意看System.arraycopy方法,这个方法入参的src 和 des 其实就是他本身,那么整段逻辑下来就是必要的时候对数组进行移位操作,移位操作完成后,对index进行赋值操作,所以虽然是insert方法,这里其实没有对数组进行扩容,而是重复利用了空间。那么为什么走到这个条件体呢?回顾之前我们对gc流程,一旦对元素进行删除并且调用了gc之后,存key的数组长度肯定是大于mSize的。
6. 再往下就是我们真正的扩容操作了:
int[] newArray = new int[growSize(currentSize)];
public static int growSize(int currentSize)
return currentSize <= 4 ? 8 : currentSize * 2;
这里的扩容和Arraylist的自增当前容量一半的扩容方式不同的是,当小于4直接是扩容到8,否则直接翻倍。
7.这里我们inser方法分析完成,最终通过这个方法完成了对存键值对数组的互用或者扩,至此put方法分析基本完成。
总结:
- SparseArray 因内部使用了int做为key避免了自动装箱操作,相比HashMap是更省内存的,但是另一方面因为内部是二分查找法,在存储大量数据的情况下,性能是比HashMap差的,但是Android中一般没有特别大量数据的场景,所以Android中尽可能更推荐使用SparseArray。
- SpareArray虽然内部是数组实现的,但是它是按照Key的大小升序的,所以存数据先后并不能决定它在数组下标中的顺序。
- 它除了增加元素可能会有数组扩容操作,其他都是通过标记位,数组元素移位来完成,性能优化更好。
- 适用场景:数据量不大,空间比时间重要,key为int的情况,对于我们客户端来说一般页面数据不会过千,那么SparseArray相对于HashMap在查询上不会有太大的区别,但是在内存上有很大的优势。
以上是关于SparseArray 那些事儿(带给你更细致的分析)的主要内容,如果未能解决你的问题,请参考以下文章