数字媒体概论——声音
Posted _瞳孔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数字媒体概论——声音相关的知识,希望对你有一定的参考价值。
一:声音概念
声音的产生:声音(Sound)是由物体振动产生的声波。是通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。最初发出振动的物体叫声源。
自然界的声音是一个随时间而变化的连续信号。通常用模拟的连续波形描述声波的形状,单一频率的声波可用一条正弦波表示。
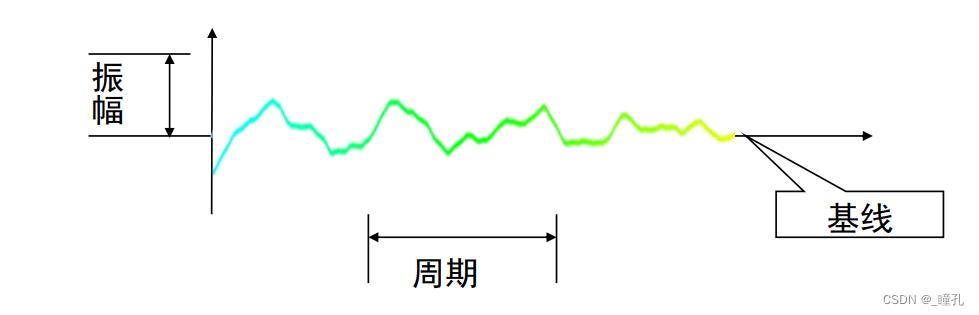
声音三大要素:
- 振幅:表示声音的响度。声音的振幅用来衡量波在其初始位置或静止位置上的偏移大小
- 频率:决定音调的高低。声音的频率表示每秒钟的周期,其单位是赫兹(Hz)
- 泛音:反应音色。声音通常不是单一频率,而是多振动叠加的
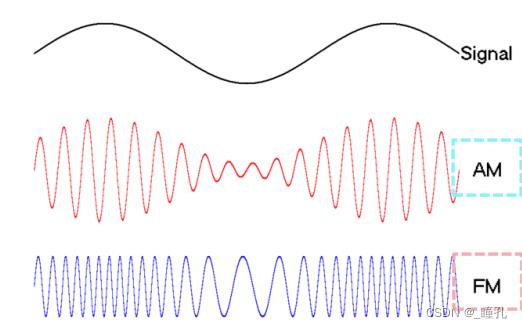
AM (Amplitude Modulation)调幅模式广播,范围在530—1600KHz (中波)。载波的频率保持不变,幅度会根据声音的高低变化而变化。传输距离较远,抗干扰性略弱
FM (Frequency Modulation)则指的是调频模式广播,范围在76-108MHz,在中国为88-108MHz,短波。载波随着音频调制信号的变化而在载波中心频率两边变化。抗干扰力强,失真小,占频带更宽,且传输距离短
声音的频率范围:
- 次声波:0~20Hz
- 人耳能听到的声音:20Hz~20kHz
- 超声波:20kHz~1GHz
- 高超声波:1GHz~10TH
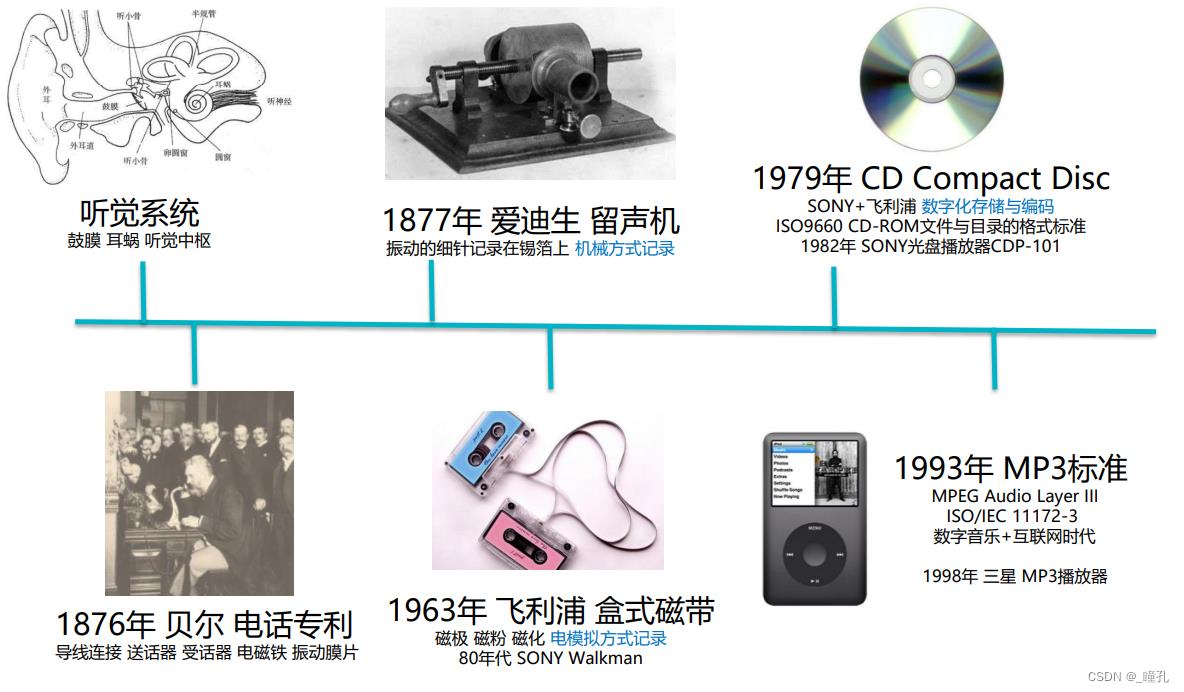
声音处理的历史:
二:声音的数字化
2.1:模数转换
声波是随时间而连续变化的物理量,通过能量转换装置,可用随声波变化而改变的电压或电
流信号来模拟。以模拟电压的幅度来表示声音的强弱。
为使计算机能处理音频,必须对声音信号模数转换,要经过采样、量化和编码三个步骤 ,即脉冲编码调制(Pulse Code Modulation)编码,即PCM编码。
-
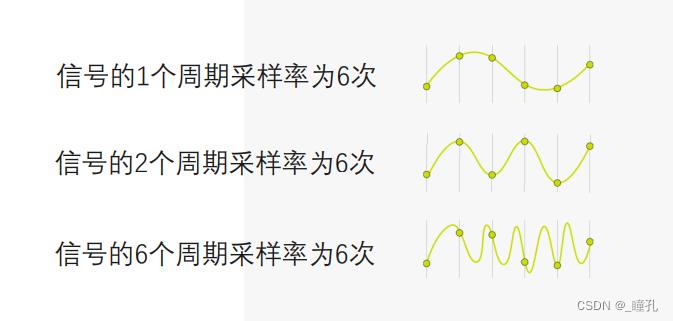
采样(Sampling)指将在时间轴上连续的声音波形进行时间轴上的离散化。具体做法是每隔一个时间t,采集一个波形数据(样本,Sample)。
- 连续波形进行采样的频率/每秒钟采集的样本数量叫做采样率。采样率决定了数字化后可能重构的最高音频频率。
- 采集的样本数至少是最高频率的两倍,亦即每小段波形至少两个样本。
-
量化(Quantization)指采样样本的位深度,即用多少二进位(bit)来表示声音波形的高度,位数越多声音质量越好。这实际上是在振幅轴上的离散化。为了减少量化误差,必须在每个样本中分配足够多的位数。样本位数不够会产生失真,增加样本位数可以降低失真。每个样本8bit声音音质不够好;CD的音质一般16bit;高质量的音频24bit
-
编码:将采样、量化后的数据按照一定的数据格式编排(含数据的压缩)存放到计算机中

-
混叠:如果不遵循一段波形周期至少取样两个样本的规则,那么可能会捕捉到无用的混叠(Aliasing)频率。为了防止这种情况发生,需要在采样之前进行反混叠(Anti-Aliasing),就是一个低通滤波器,可以阻止高于采样频率一半的频率。
- 抖动:每个样本之间的间隔连续时间必须是完全相同的,因为数字化时,没有关于每个样本的时间信息。所以我们必须依靠稳定的重复抽样,采用恒定的时间间隔。(例如,当采样率为48千赫兹时,那么任何两个样本之间的间隔时间为20.833微秒[μs]。)。不稳定的采样间隔,称为抖动(Jitter),会导致重构音频里有噪音
模拟音频转数字信号:

数字信号转模拟音频:
- 在从数字到模拟音频的转换中,目的是产生与数字信息中所包含的数值成比例的信号。
- 每个位代表一个电压值。最高有效位(MSB)转换成最大电压;下一个最高有效位转换成电压的一半,以此类推直到最低有效位(LSB),再把各位对应模拟量相加
- 逐个求采样样本的电压值,并将值保留到下一个样本被取样,输出一个连续信号
- 最后通过应用低通滤波器平滑信号。

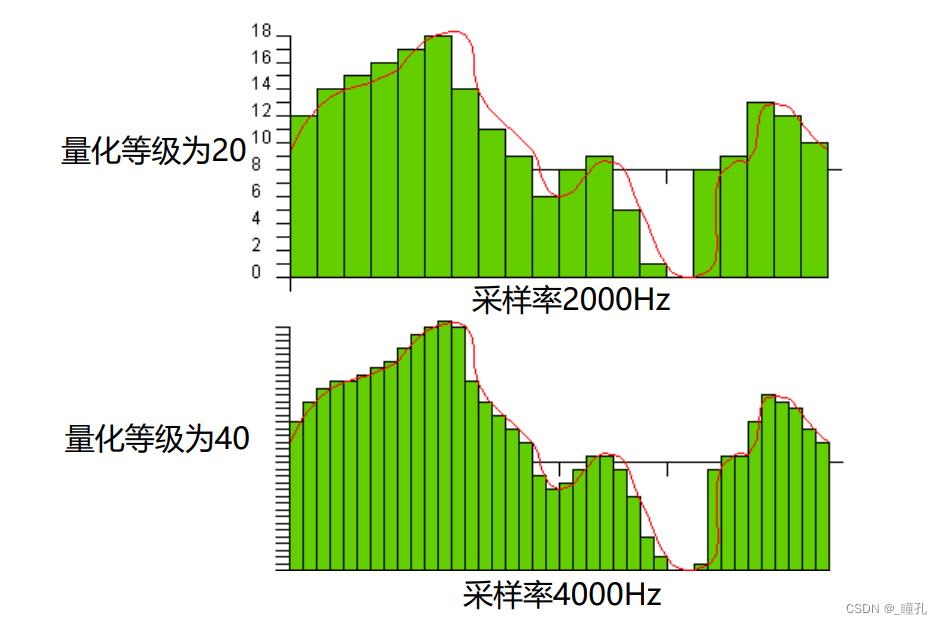
采样及量化的失真(例如电话就是3kHz取样的7位声音,而CD是44.1kHz取样的16位声音):
失真的测度 PSNR:
- PSNR 峰值信噪比Peak Signal to Noise Ratio,衡量两个信号之间的失真程度
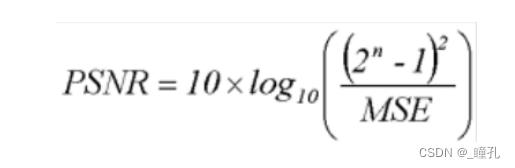
- MSE 均方误差 Mean Square Error 真实值与待测值差平方的期望
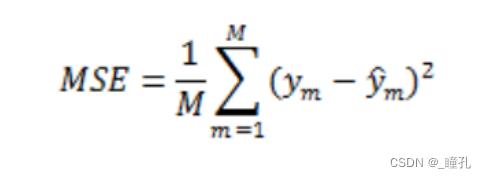
常见采样与量化指标:
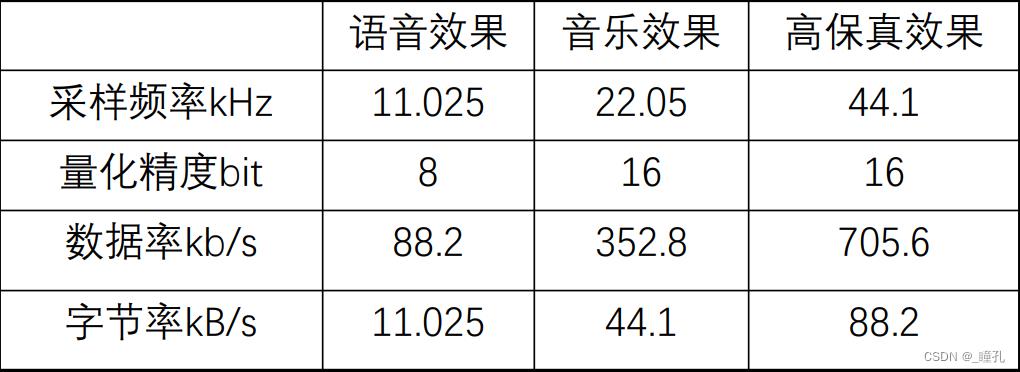
补充:
- 48kHz:DVD、数字电视中使用。
- 96kHz-192kHz:DVD-Audio、蓝光高清等使用。
2.2:通道数
- 单声道、双声道
- 5.1声道: 1992年,DOLBY实验室提供了五个声道的从20Hz到20kHz的全通带频响,即正前方的左(L)、中(C)、右(R),后边的两个独立的环绕声通道左后(LS)和右后(RS)。另外,为了弥补低音的不足,还同时提供了一个100Hz以下的超低音声道供用户选用,因为这只是一个辅助通道,所以定为0.1通道,这样就构成了Dolby Digital AC-3的5.1通道
- 中央声道喇叭,大部分时间它是负责人物对白的部分;前置左、右声道喇叭,则是用来弥补在屏幕中央以外或不能从屏幕看到的动作及其他声音;后置环绕音效喇叭是负责外围及整个背景音乐,让人感觉置身于整个场景的正中央
- 7.1声道: 在前者基础上,将环绕声道一分为四,左侧环绕、右侧环绕、左后环绕和右后环绕
全景声:
- 杜比全景声(Dolby Atmos)由杜比实验室2012年发布,它突破了传统意义上5.1、7.1声道的概念,能够结合影片内容,呈现出动态的声音效果,更真实的营造出由远及近的音效,实现声场包围,展现更多声音细节
- 2014年发布家庭版本,例如LG、三星、飞利浦、Vizio、东芝、SONY;国内创维、TCL、海信、康佳等; (回音壁)

2.3:数字化容量计算
数字音频的存储量:
- 存储量=采样频率×量化位数/8 ×声道数×时间
- 数据率=采样频率×量化位数/8
例如:数字激光唱盘(CD-DA)的标准采样频率为44.1 kHz,量化位数为16 位,立体声。一分钟 CD-DA 音乐所需的存储量为44.1 K×16×2×60÷8 = 10584 KB
2.4:音频编码
2.4.1:音频冗余
音频压缩指的是对原始数字音频信号流(PCM编码)运用适当的数字信号处理技术,在不损失有用信息量,或所引入损失可忽略的条件下,降低其码率,也称为压缩编码。其相应的逆变换称为解压缩或解码
为什么压缩?以CD为例:44.1 K×16×2×60÷8 = 10584 KB。在无损的条件下至少可进行4:1压缩,MP3(MPEG-1 Audio Layer III)达到10+:1
对语音信号的研究发展较早,也较为成熟,音频压缩技术已得到广泛应用,按照方案的不同,又可将其划分为时域压缩、变换压缩、子带压缩,以及多种技术相互融合的混合压缩等等
音频中的冗余:
- 数字音频压缩编码在保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩,通过去除声音信号中冗余成分的方法来实现。所谓音频中的冗余指的是音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助。
- 冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。
- 人耳所能察觉的声音信号的频率范围为20Hz~20KHz,除此之外的其它频率人耳无法察觉,都可视为冗余信号
- 根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应,例如噪声掩蔽、频域掩蔽、时域掩蔽
音频中的冗余——掩蔽效应:一个强纯音会掩蔽在其附近同时发声的弱纯音,这种特性称为频域掩蔽,也称同时掩蔽(simultaneous masking)。一般来说,弱纯音离强纯音越近就越容易被掩蔽;低频纯音可以有效地掩蔽高频纯音,但高频纯音对低频纯音的掩蔽作用则不明显。例如:一个声强为60dB、频率为900Hz的纯音,同时还有一个40dB、1000Hz的纯音,我们的耳朵就只能听到那个900Hz的强音
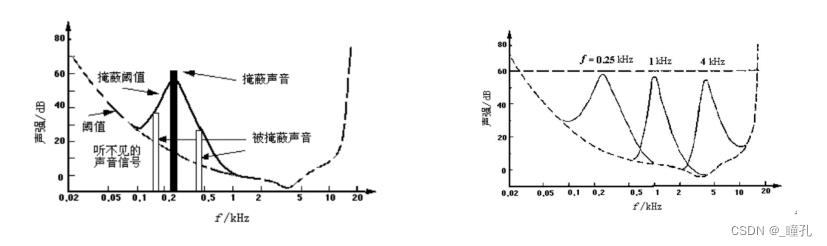
音频中的冗余——掩蔽效应:除了同时发出的声音之间有掩蔽现象之外,在时间上相邻的声音之间也有掩蔽现象,并且称为时域掩蔽。时域掩蔽又分为超前掩蔽(pre-masking)和滞后掩蔽(post-masking),产生时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。一般来说,超前掩蔽很短,只有大约5~20ms,而滞后掩蔽可以持续50~200ms。可以着重记录人耳朵较为敏感的中低频段声音,而对于较高的频率的声音则简略记录,从而压缩所需的存储空间
无压缩的音频格式:CD,WAV
- 微软公司专门为Windows开发的一种存储声音波形的标准数字音频格式
- WAV格式和CD格式一样,也是44.1kHz的取样频率,16位量化数字
- WAV的特点是真实记录自然声波形,基本无数据压缩,数据量大(每分钟的音乐大约需要12兆磁盘空间)
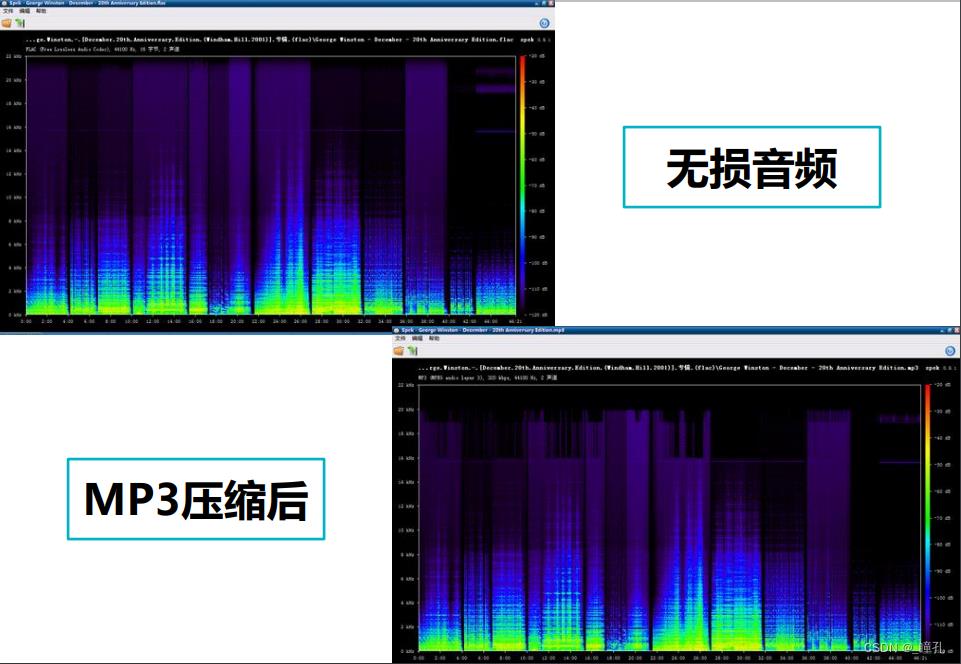
音频压缩分为无损压缩(lossless)及有损压缩(lossy)两大类。无损压缩能够在100%保存原文件的所有数据的前提下,将音频文件的体积压缩的更小,而将压缩后的音频文件还原后,能够实现与源文件相同的大小、相同的码率。
无损压缩格式有APE、FLAC、WavPack、LPAC、WMALossless、AppleLossless等。
FLAC(Free Lossless Audio Code)不破坏任何原有的音频信息,所以可以还原音乐光盘音质。
- 压缩与ZIP方式类似,但压缩率大于ZIP和RAR,因为专门针对PCM音频的特点设计。
- 开源、免费、多平台支持、最先得到广泛硬件支持的无损格式。
- 分帧,每帧数据之间无关联。FLAC文件在传播过程中受损,仍可以播放
MP3:MPEG-1 音频分三层 ,分别为MPEG-1 audio Layer1 ,MPEG audio Layer2以及MPEG audio Layer3,并且高层兼容低层。其中第三层协议被称为MPEG-1 Layer 3,简称MP3。
- 回顾:MPEG-1是MPEG组织制定的第一个视频和音频有损压缩标准。视频压缩算法于1990年定义完成。1992年底,MPEG-1正式被批准成为国际标准。MPEG-1是为CD光碟介质定制的的视频和音频压缩格式
- MP3是在综合既往方案提出的混合压缩技术。压缩比高,低码率条件下高水准的声音质量,适合用于互联网上的传播。缺点是在128kbit/s及以下时,会出现明显的高频丢失。
- MPEG-1 Layer1采用每声道192kbit/s,每帧384个样本,32个等宽子带,固定分割数据块。子带编码用DCT(离散余弦变换)和(快速傅立叶变换)计算子带信号量化bit数。采用基于频域掩蔽效应的心理声学模型,使量化噪声低于掩蔽值。量化采用带死区的线性量化器,主要用于数字盒式磁带(DCC)。
- MPEG-1 Layer2采用每声道128kbit/s,每帧1152个样本(时间上按44.1kHz换算约26ms),32个子带,属不同分帧方式。采用共同频域和时域掩蔽效应的心理声学模型,并对高、中,低频段的比特分配进行限制,并对比特分配、比例因子,取样进行附加编码。Layer2 广泛用于数字电视,CD-ROM,CD-I和VCD等。
- MPEG-1 Layer3采用每声道64kbit/s,用混合滤波器组提高频率分辨率,按信号分辨率分成6X32或18X32个子带,克服平均32个子带的Layer1,Layer2在中低频段分辨率偏低的缺点。采用心理声学模型,增设不均匀量化器,量化值进行熵编码。
其他音频编码格式:
- RealAudio:压缩比高,主要适用于在线音乐。文件格式有RA(RealAudio),RM(RealMedia),RMX等。这些格式的特点是可以随网络带宽的不同而改变声音的质量
- WMA:Windows Media Audio格式是来自于微软;内置版权保护技术Digital Rights Management;在压缩比上进行了深化,低码率下音质要强于MP3和RA格式
- MIDI:Musical Instrument Digital Interface,用于电脑作曲领域,MIDI允许数字合成器和其他设备交换数据,MID文件并不是一段录制好的声音,而是记录声音的信息,然后再告诉声卡如何再现音乐的一组指令
- AAC(Advanced Audio Coding):高级音频编码, 1997 MPEG-2 AAC;2004 MPEG-4 AAC
- 128Kbps的AAC立体声音乐被专家认为不易察觉到与原来未压缩音源的区别;AAC格式在96Kbps码率的表现超过了128Kbps的MP3格式;同128Kbps,AAC格式的音质明显好于MP3
- AAC是在MP3基础上开发出来的,压缩比进一步可达20:1,工序更加复杂
一些概念:
- 预测:对音频信号进行预测可以减少重复冗余信号的处理,提高效率
- 变换:进行信号的时频转换,从而得到频域的频谱系数
- 量化:对量化分析良好控制,更高效地利用比特率
- 熵编码: AAC熵编码拥有一个弹性的比特流结构,使得编码效率进一步提高
- 时域噪音修整(Temporal Noise Shaping)通过在频率域上的预测,来修整时域上的量化噪音的分布
- 长时期预测(Long Term Prediction,LTP):MPEG-4 AAC工具,它用来减少连续两个编码音框之间的信号冗余,对于处理低码率的语音非常有效
- 知觉噪音代替(Perceptual Noise Substitution):MPEG-4 AAC工具,当编码器发现类似噪音的信号时,并不对其进行量化,而是作个标记就忽略过去,当解码时再还原出来,这样就提高了效率
2.5:音频编辑软件
数字音频编辑软件分数字音频制作类和音乐制作类。音乐制作类是一款利用多媒体计算机进行音乐制作的软件;而数字音频制作类是我们广播节目录制应用最多的一款软件。
数字音频制作类编辑软件的功能主要包括录音、混音、后期效果处理等,是以音频处理为核心,集声音记录、播放、编辑、处理和转换于一体的功能强大的数字音频编辑软件,具备制作专业声效所需的丰富效果和编辑功能,用它可以完成各种复杂和精细的专业音频编辑。在声音处理方面包含有频率均衡、效果处理、降噪等多项功能。
常见音频编辑软件如 : Adobe Audition 、 Sonar 、 Vegas 、 Samplitude 、 Nuendo 、SoundForge、WaveCN、GoldWave、WaveLab等
- Adobe Audition:简称AU,由Adobe开发的专业音频编辑和混合环境,为广播设备和后期制作设备方面工作的音频和视频专业人员设计,可提供先进的音频混合、编辑、控制和效果处理功能。最多混合 128 个声道并可使用 45 种以上的数字信号处理效果。
- Audacity:一个跨平台的声音编辑软件,用于录音和编辑音频,是开源的软件(GNU协议),可在Mac OS X、Windows、Linux上运行
FFMPEG 编码音频:
- 音频转码与编码:
- 有损音频转WAV格式:
ffmpeg -i input.mp3 -f wav output.wav - 无损WAV格式压缩:
ffmpeg -i input.wav -f mp3 -acodec libmp3lame -y output.mp3 - 移动设备音频格式 AMR 转换压缩
ffmpeg -i input.amr output.mp3ffmpeg -i in.wav -acodec libamr_nb -ab 12.2k -ar 8000 -ac 1 out.amr
- 有损音频转WAV格式:
- 视频中的音频处理:Adaptive Multi-Rate音频格式:主要用于移动设备的音频,由欧洲通信标准化委员会提出,是在移动通信系统中使用最广泛的语音标准。压缩比比较大,但相对其他压缩格式质量较差,多用于人声、通话等。
2.6:音频采集
音频数据的采集,常见方法有三种:直接获取已有音频、利用音频处理软件捕获截取声音、用麦克风录制声音。音频的采集在于拾音技术的提高,与采集设备(如声卡、话筒等)关系非常大
声卡 (Sound Card):也叫音频卡,是计算机多媒体系统中最基本的组成部分。声卡的基本功能是把来自话筒、磁带、光盘的原始声音信号加以转换,输出到耳机、扬声器、扩音机、录音机等声响设备,或通过音乐设备数字接口(MIDI)发出合成乐器的声音
- PC进入多媒体时代:英国的ADLIB AUDIO公司1984年推出的ADLIB声卡
- 个人电脑领域:1989年,Creative Labs(创新实验室)发布了 Creative Labs SoundBlaster Card (创新声霸卡)。

三:MIDI音乐
MIDI Musical Instrument Digital Interface 乐器数字接口 ,20 世纪80 年代为解决电声乐器之间的通信问题而提出,用音符的数字控制信号来记录音乐。容量小、音质好、适用广。
- MIDI是编曲界最广泛的音乐标准格式,可称为“计算机能理解的乐谱”,几乎所有的现代音乐都是用MIDI加上音色库来制作合成的。
- 一首完整的MIDI音乐只有几十KB大,而能包含数十条音乐轨道。
- 可以把MIDI理解成是一种协议、一种标准、或是一种技术,但不要把它看作是某个硬件设备。它的出现解决了各个不同厂商之间的数字音乐乐器的兼容问题
MIDI文件:MIDI 传输的不是声音信号, 而是音符、控制参数等指令, 它指示MIDI 设备要做什么,怎么做, 如演奏哪个音符、多大音量等。它们被统一表示成MIDI 消息(MIDI Message) 。
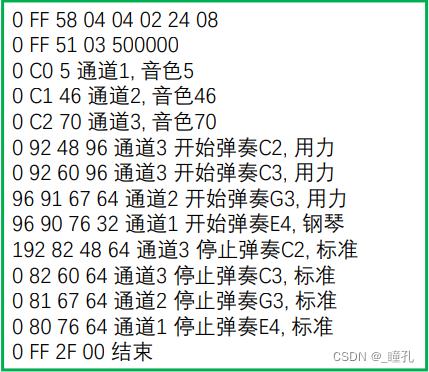
MIDI系统实际就是一个作曲、配器、电子模拟的演奏系统。从一个MIDI设备转送到另一个MIDI设备上去的数据就是MIDI消息。MIDI数据不是数字的音频波形,而是音乐代码或称电子乐谱。

音序器:
- 音序器实际上是一个音乐词处理器word porcessor,应用它可以记录、播放和编辑各种不同MIDI乐器演奏出的乐曲,将其存入MIDI文件
- 是MIDI作曲和配器系统核心部分
- 序列器可以是硬件,也可以是软件,它们作用过程完全与专业录音棚里多轨录音机一样。

音序器软件:
- Cakewalk曾经最流行的音序器软件,后来整合的功能越来越多。音乐工作站的未来发展方向是MIDI、音频、音源(合成器)一体化制作。最先实现这个方式的是著名的Cubase软件
- Cakewalk公司推出了新一代的音乐工作站Sonar。Sonar在Cakewalk的基础上,增加了针对软件合成器的全面支持,并且增强了音频功能,使之成为新一代全能型超级音乐工作站。
MIDI键盘
- MIDI键盘是用于MIDI乐曲演奏的,MIDI键盘本身并不发出声音,当作曲人员触动键盘上的按键时,就发出按键信息,所产生的仅仅是MIDI音乐消息,从而由音序器录制生成MIDI文件。
- 有键盘式的(合成器、主控键盘)、弦控式的(MIDI吉他)、敲击式的(鼓机)、吹奏式的(呼吸控制器)

合成器:解释MIDI文件中的指令符号或者MIDI消息,生成所需要的声音波形,经放大后由扬声器输出,声音的效果比较丰富。
- 调频合成(FM):运用声音振荡的原理对MIDI进行合成处理,由于技术本身的局限,效果很难令人满意。
- 波形表合成(Wave Table):首先将各种真实乐器所能发出的所有声音(包括各个音域、声调)进行取样,存储为一个波表文件。在播放时,根据MIDI文件记录的乐曲信息向波表发出指令,从“表格”中逐一找出对应的声音信息,经过合成、加工后回放出来。
MIDI通道:标准一共16个逻辑通道,每个通道访问一个独立的能产生特定声音的逻辑合成器。最多可以连接16个外部音源设备。
MIDI接口:
- MIDI In:接收来自其它MIDI设备的MIDI信息。
- MIDI Out:发送本设备生成的MIDI信息到其它设备。
- MIDI Thru:将从MIDI In端口传来的信息转发到相连的另一台MIDI设备上。
- 用于连接各种MIDI设备所用的电缆为5芯电缆,通常人们也把它称为MIDI电缆

效果与后期:
- MIDI效果器(如Style Enhancer,Guitar Pro ):为MIDI信号添加逼真、富于变化的人性化的真实效果
- 音频效果器(如Waves):作用于音频Wav事件的效果设置,优化音频效果
- 后期处理软件(如T-Racks):利用自身配备的EQ均衡器、电子管压缩器和限制器起到最好的暖声效果,改变“数码之声”的冰冷、机械化
如果有兴趣了解更多相关信息,欢迎来我的个人网站看看:瞳孔的个人网站
以上是关于数字媒体概论——声音的主要内容,如果未能解决你的问题,请参考以下文章