统一Pearl与Rubin的因果图模型:Single-World Intervention Graphs
Posted Jie Qiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统一Pearl与Rubin的因果图模型:Single-World Intervention Graphs相关的知识,希望对你有一定的参考价值。
本文是Single World Intervention Graphs (SWIGs): Unifying the Counterfactual and Graphical Approaches to Causality论文的笔记
Single World Intervention Graphs
Rubin的potential outcome框架和 Juder peral 的DAG的模型,一直以来都处于割裂状态,这里用一个统一框架来统一两者。
我们知道在Rubin的potential outcome框架下,有很多必要的假设,比如ignorability
X ⊥ Y ( X = 0 ) ∣ L a n d X ⊥ Y ( X = 1 ) ∣ L X\\bot Y( X=0) |L\\ and\\ X\\bot Y( X=1) |L X⊥Y(X=0)∣L and X⊥Y(X=1)∣L
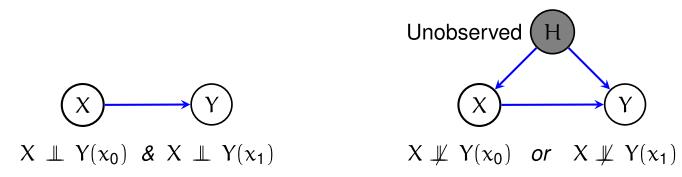
这个假设可以理解为,不管我的X的选择是什么,都不会对“潜在”的结果有任何影响,更直白点地说就是, Y ( 0 ) , Y ( 1 ) \\displaystyle Y( 0) ,Y( 1) Y(0),Y(1)是一个世界本来存在的值,X只是选择看哪个而已。然而这样的表述总是很不直观,而且 Y ( 0 ) , Y ( 1 ) \\displaystyle Y( 0) ,Y( 1) Y(0),Y(1)是没有出现在图上的。有没有可能用一个图结果来刻画这些“潜在”的假设呢?
当满足ignorability假设我们就可以从观测数据中识别出 Y ( 0 ) , Y ( 1 ) \\displaystyle Y( 0) ,Y( 1) Y(0),Y(1)。然而Pearl也考虑过类似的问题,但他是考虑 P ( Y , d o ( X ) ) \\displaystyle P( Y,do( X)) P(Y,do(X))这样的分布是否可识别。从某种程度上来讲,potential outcome这套框架其实能提供更多的信息,因为使用do操作是没有办法对counterfactual建模的,而potential outcome框架却可以。
但是potential outcome这一框架往往不直观 Y ( 0 ) , Y ( 1 ) \\displaystyle Y( 0) ,Y( 1) Y(0),Y(1)根本没有在图上出现,我们没有办法直观地看到,他跟X到底是否独立。这里介绍一种Single-World Intervention Graphs (SWIGs),他可以帮我们在图上“画出” Y ( 0 ) , Y ( 1 ) \\displaystyle Y( 0) ,Y( 1) Y(0),Y(1)这些本来在DAG上不存在的变量,然后用最基本的D-separated就可以一眼看出其所有的独立性!
SWIG的构造方法就是将干预变量X进行node splitting:
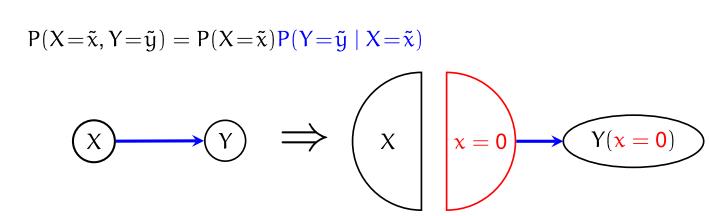
此时,从图上就能看出来, X ⊥ Y ( 0 ) \\displaystyle X\\bot Y( 0) X⊥Y(0),于是有
P ( X = x , Y ( 0 ) = y ) = P ( X = x ) P ( Y ( 0 ) = y ) P( X=x,Y( 0) =y) =P( X=x) P( Y( 0) =y) P(X=x,Y(0)=y)=P(X=x)P(Y(0)=y)
其中
P ( Y ( 0 ) = y ) = P ( Y = y ∣ X = 0 ) P( Y( 0) =y) =P( Y=y|X=0) P(Y(0)=y)=P(Y=y∣X=0)
类似的,X=1也能得到类似的图与结论。你可以发现,这个图每次只能表示一个x的状态(这也是被称为single-world的原因,每次只能观测到一个世界),我们可以引入模板来作为world的选择,
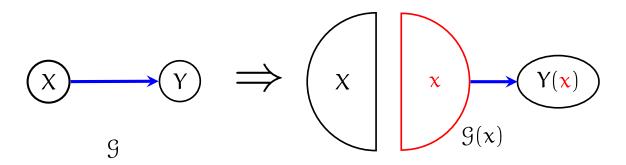
从而不同的 G ( x 0 ) , G ( x 1 ) \\displaystyle \\mathcalG( x_0) ,\\mathcalG( x_1) G(x0),G(x1)可以用来分别表达不同的 x \\displaystyle x x的取值。需要注意的是,这个图只是说明了 X ⊥ Y ( 0 ) \\displaystyle X\\bot Y( 0) X⊥Y(0)和 X ⊥ Y ( 1 ) \\displaystyle X\\bot Y( 1) X⊥Y(1)成立,并没有假设 X ⊥ Y ( 0 ) , Y ( 1 ) \\displaystyle X\\bot Y( 0) ,Y( 1) X⊥Y(0),Y(1),事实上,这样的写法是不对的,我们需要的就只是 X ⊥ Y ( 0 ) \\displaystyle X\\bot Y( 0) X⊥Y(0)和 X ⊥ Y ( 1 ) \\displaystyle X\\bot Y( 1) X⊥Y(1)。
用SWIG推导back-door formula
现在我们尝试用SWIG来推导出back-door准则,

从上图可以看到显然, X ⊥ Y ( x ) ∣ L \\displaystyle X\\bot Y( x) |L X⊥Y(x)∣L成立,因此
P ( Y ( x ) = y ) = ∑ l P ( Y ( x ) = y ∣ L = l ) P ( L = l ) = ∑ l P ( Y ( x ) = y ∣ L = l , X = x ) P ( L = l ) = ∑ l P ( Y = y ∣ L = l , X = x ) P ( L = l ) \\beginaligned P( Y( x) =y) & =\\sum _l P( Y( x) =y|L=l) P( L=l)\\\\ & =\\sum _l P( Y( x) =y|L=l,X=x) P( L=l)\\\\ & =\\sum _l P( Y=y|L=l,X=x) P( L=l) \\endaligned P(Y(x)=y)=l∑P(Y(x)=y∣L=l)P(L=l)=l∑P(Y(x)=y∣L=l,X=x)P(L=l)=l∑P(Y=y∣L=l,X=x)P(L=l)
这就推出来了。
这篇文章还提到Rubin这套模型与pearl的SEM模型的优势在于,SEM由于要假设噪声是相互独立的,而这一假设是无法通过随机试验检验的,而Rubin这一套模型是完全可检验的,因此更有优势。
g-formula
g-formula可以看做是一种更加一般化的back-door,它给出了更一般情况下,potential outcome的识别方法,即在干预后的分布中,如何从观测数据中计算出potential outcome。

举个例子,考虑一个sequence treatments的情况:
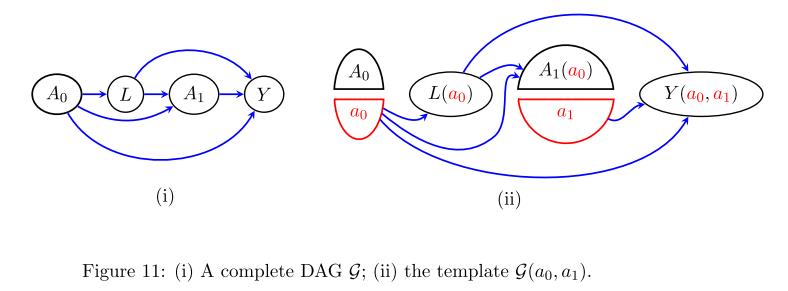
我们有
P ( Y ( a 0 , a 1 ) = y ) = ∑ l P ( L ( a 0 ) = l , Y ( a 0 , a 1 ) = y ) = ∑ l P ( L = l ∣ A 0 = a 0 ) P ( Y = y ∣ A 0 = a 0 , L = l , A 1 = a 1 ) \\beginaligned P( Y( a_0 ,a_1) =y) & =\\sum _l P( L( a_0) =l,Y( a_0 ,a_1) =y)\\\\ & =\\sum _l P( L=l\\mid A_0 =a_0) P( Y=y\\mid A_0 =a_0 ,L=l,A_1 =a_1) \\endaligned P(Y(a0,a1)=y)=l∑P(L(a0)=l,Y(a0,a1)=y)=l∑P(L=l∣A0=a0)P(Y=y∣A0=a0,L=l,A1=a1)
这里第二个等于号,其实就是相当于考虑上述推论18中,令 B = L , Y \\displaystyle B=\\L,Y\\ B=L,Y
事实上,在有隐变量的时候也仍然适用,比如
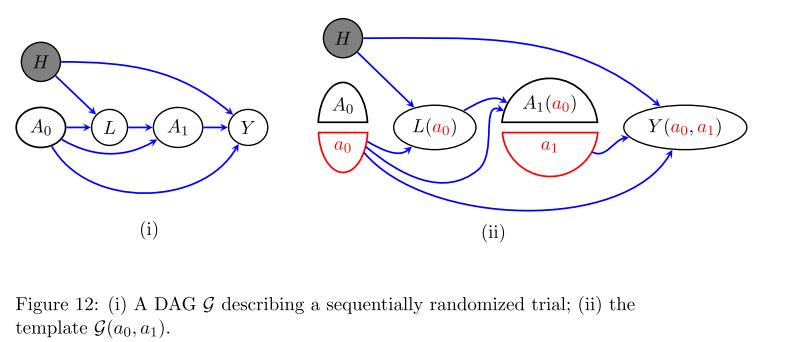
H是隐的,但此时该式子同样适用
P
(
Y
(
a
0
,
a
1
)
=
y
)
=
∑
l
,
h
p
(
l
∣
h
,
a
0
)
p
(
y
∣
a
1
,
l
,
a
0
,
h
)
p
(
h
)
(
H
⊥
A
0
)
=
∑
l
,
h
p
(
l
∣
h
,
a
0
)
p
(
y
∣
a
1
,
l
,
a
0
,
h
)
p
(
h
∣
a
0
以上是关于统一Pearl与Rubin的因果图模型:Single-World Intervention Graphs的主要内容,如果未能解决你的问题,请参考以下文章