推荐升级四部曲之 CDH 升级重头戏,收藏了!
Posted DataFlow范式
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐升级四部曲之 CDH 升级重头戏,收藏了!相关的知识,希望对你有一定的参考价值。

特别提醒
为了保证文章整体的阅读性,笔者并没有将升级过程中遇到的所有问题都记录在本篇文章中,比如 Phoenix 版本不兼容和数据迁移,Hive 集成 Atlas 等。
特别需要注意,HBase 等组件升级前要做一些操作,千万不要急着去激活 Parcel。
再次提醒,每个步骤操作前,先看完整了,看完整了,完整了。否则,完了。
在笔者文章中,所有标注:
未使用,忽略
未部署,忽略
类似如上的信息,大家要结合自己的实际情况进行处理。
CDH 信息收集

CDH 6.3.3 版本需要使用 license 申请用户名和密码,用于下载安装包。
https://username:password@archive.cloudera.com/p/cdh6/6.3.3/parcels/
收集集群信息
检查操作系统版本
lsb_release -a
登录 Cloudera Manager Admin Console
a. 查看目前 Cloudera Manager 版本和 JDK 版本
Support > About
b. 检查 HDFS HA 是否开启
c. 检查 CDH 版本的部署方式
在 CDH 集群名称下方可以看到(http://cm-host:7180/cmf/home)
重要提示
Enterprise 6.0.0 不再支持以下服务
Accumulo
Sqoop2
MapReduce 1
Spark 1.6
Record Service
在升级到 CDH 6 之前,必须停止和删除这些服务。
对于生产环境,要考虑 Sqoop2 以及 Spark 1.6 的使用,完成迁移的过程。
CDH 6.0.0 集群上运行 Apache Accumulo 目前不支持。如果升级到 CDH 6.0.0,则要求移除 Accumulo service。但是在 CDH 6 上运行 Accumulo 在以后的版本中会支持。
笔者未部署,不涉及,忽略。如果在集群中使用 Solr Search 服务,那么在升级前后,有一些需要手工操作的步骤。
笔者未部署,不涉及,忽略。CM minor 版本必须不小于 CDH minor 版本。
本地 repo 相关操作
需要配置 http 相关参数(/etc/httpd/conf/httpd.conf):
<IfModule mime_module>
TypesConfig /etc/mime.types
AddType application/x-compress .Z
# 解决 CM 6 以及以上版本 Hash verification failed 问题
AddType application/x-gzip .gz .tgz .parcel
AddType text/html .shtml
AddOutputFilter INCLUDES .shtml
</IfModule>
# 重启 http 服务
sudo systemctl start httpd
配置 CDH 6.3.3 repo 本地源:
sudo mkdir -p /var/www/html/cdh6
sudo wget --recursive --no-parent --no-host-directories https://USERNAME:PASSWORD@archive.cloudera.com/p/cdh6/6.3.3/parcels/ -P /var/www/html/cdh6
sudo chmod -R ugo+rX /var/www/html/cdh6
笔者实际环境中都是离线的,无法访问外网,因此需要从 https://username:password@archive.cloudera.com/p/cdh6/6.3.3/parcels/ 中下载对应的 Parcel 包,放到 /var/www/html/cdh6 目录下。
升级前准备
CM Server 节点可以通过 root 免密访问集群所有节点
查阅 CDH 5 和 6 Release Notes 以及 Cloudera Security Bulletins
预留升级的时间窗口
对于生产环境,建议预留足够时间来执行升级,但是也要根据集群规模的大小动态调整。Impala 升级后,一定要检查 Impala keywords 的兼容性
https://docs.cloudera.com/documentation/enterprise/6/latest/topics/impala_reserved_words.html#reserved_words
执行 Security Inspector,修复存在的问题
Administration > Security > Security Inspector
检查 hdfs block
hdfs fsck / -includeSnapshots
检查时间可能比较长,耐心等待。
hdfs dfsadmin -report
检查 hbase block
hbase hbck
HBase 升级到 CDH6 的迁移工作(见下面)
Kudu 检查
kudu cluster ksck <master_addresses>
比如:
kudu cluster ksck cdh1.dataflow.com:7051,cdh2.dataflow.com:7051,cdh3.dataflow.com:7051
如果 Hue 使用 PostgreSQL 数据库,必须手工安装 psycopg2
笔者测试和生产环境的所有组件都是使用 MariaDB 作为元数据库,忽略。CDH 升级之前备份 CM
对前面升级过的 Cloudera Manager 再次进行备份。针对 Sentry, Cloudera Search(未部署), Apache Spark, HBase, Hue, Key Trustee KMS(未部署), HSM KMS(未部署)组件进行升级前操作(见下面)
Enterprise 6.0.0 不再支持以下服务
在升级到 CDH 6 之前,必须停止和删除这些服务。
删除组件时,经常卡死,刷新即可(其实组件已经被删除了)。
Accumulo
Sqoop2
MapReduce 1
Spark 1.6
Record Service

备份 CDH
本操作不备份集群存储的业务数据(比如 HDFS、HBase),建议常规性地使用 BDR(Backup and Disaster Recovery)备份数据。
以下组件不需要备份:
MapReduce
YARN
Spark
Pig
Impala
1. 备份数据库
备份数据库需要停止一些服务,在备份期间服务不可用。
收集数据库信息用于备份需要,包括如下组件:
Sqoop、Oozie 和 Hue:
Cluster Name > Configuration > Database Settings
# 数据库 IP 地址/数据库/用户名/密码,端口默认为 3306
# Hue Database Hostname/Name/Username/Password
# Oozie Server Database Host/Name/User/Password
Hive Metastore
Hive service > Configuration > 在 CATEGORY 中选择 Hive Metastore Database
# Hive Metastore Database Host/Name/User/Password
Sentry
Sentry service -> Configuration -> 在 CATEGORY 中选择 Sentry Server Database
# Sentry Server Database Host/Name/User/Password
每个数据库备份时执行如下步骤:
停止服务,如果有依赖的服务,同时也要停止依赖的服务
备份数据库
# 示例
# mysqldump --databases database_name --host=database_hostname --port=database_port -u database_username -p > backup_directory_path/database_name-backup-`date +%F`-CDH5.16.sql
# 备份 hue、oozie、hive 和 sentry 数据库
mysqldump --databases hue -u root -p > hue-backup-`date +%F`-CDH5.16.sql
mysqldump --databases oozie -u root -p > oozie-backup-`date +%F`-CDH5.16.sql
mysqldump --databases hive -u root -p > hive-backup-`date +%F`-CDH5.16.sql
mysqldump --databases sentry -u root -p > sentry-backup-`date +%F`-CDH5.16.sql
启动服务
2. 备份 Zookeeper
在 Zookeeper 集群的所有节点,备份 Zookeeper 参数 dataDir 配置的数据存储路径,默认为 /var/lib/zookeeper
cp -rp /var/lib/zookeeper /var/lib/zookeeper-backup-`date +%F`CM6.3.3-CDH5.16
3. 备份 HDFS
定位到 JournalNodes、DataNodes 和 NameNodes 节点。
如果 HDFS 开启高可用,在 JournalNode 所有节点运行以下命令:
cp -rp /data/dfs/jn /data/dfs/jn-CM6.3.3-CDH5.16
在所有 NameNode 节点,备份 NameNode runtime 目录,运行下面的命令:
mkdir -p /etc/hadoop/conf.rollback.namenode
cd /var/run/cloudera-scm-agent/process/ && cd `ls -t1 | grep -e "-NAMENODE\\$" | head -1`
cp -rp * /etc/hadoop/conf.rollback.namenode/
rm -rf /etc/hadoop/conf.rollback.namenode/log4j.properties
# cp -rp /etc/hadoop/conf.cloudera.HDFS_service_name/log4j.properties /etc/hadoop/conf.rollback.namenode/
cp -rp /etc/hadoop/conf.cloudera.hdfs/log4j.properties /etc/hadoop/conf.rollback.namenode/
这些命令创建一个临时的回滚目录。如果以后需要回滚到 CDH 5.16.2,则回滚过程要求修改此目录中的文件。
备份所有 DataNode 节点的 runtime 目录,运行如下命令:
mkdir -p /etc/hadoop/conf.rollback.datanode/
cd /var/run/cloudera-scm-agent/process/ && cd `ls -t1 | grep -e "-DATANODE\\$" | head -1`
cp -rp * /etc/hadoop/conf.rollback.datanode/
rm -rf /etc/hadoop/conf.rollback.datanode/log4j.properties
# cp -rp /etc/hadoop/conf.cloudera.HDFS_service_name/log4j.properties /etc/hadoop/conf.rollback.datanode/
cp -rp /etc/hadoop/conf.cloudera.hdfs/log4j.properties /etc/hadoop/conf.rollback.datanode/
如果 HDFS 没有开启 HA,需要备份 Secondary NameNode runtime 目录
笔者 HDFS 服务开启了 HA,忽略。
在 Secondary NameNode 节点执行:
mkdir -p /etc/hadoop/conf.rollback.secondarynamenode/
cd /var/run/cloudera-scm-agent/process/ && cd `ls -t1 | grep -e "-SECONDARYNAMENODE\\$" | head -1`
cp -rp * /etc/hadoop/conf.rollback.secondarynamenode/
rm -rf /etc/hadoop/conf.rollback.secondarynamenode/log4j.properties
cp -rp /etc/hadoop/conf.cloudera.HDFS_service_name/log4j.properties /etc/hadoop/conf.rollback.secondarynamenode/
4. 备份 Key Trustee Server and Clients
未使用,忽略。
5. 备份 HSM KMS
未使用,忽略。
6. 备份 Navigator Encrypt
未使用,忽略。
7. 备份 HBase
由于回滚过程还会回滚 HDFS,因此 HBase 中的数据也会回滚。另外,存储在 ZooKeeper 中的 HBase 元数据将作为 ZooKeeper 回滚过程的一部分进行恢复。
如果集群使用了 HBase 复制功能,那么建议记录所有 replication peers。如有必要(例如,因为 HBase znode 已被删除),可以将回滚 HBase 作为 HDFS 回滚的一部分,而无需 ZooKeeper 元数据,这样就可以在全新的 ZooKeeper 安装中重建该元数据,但 replication peers 除外,必须将其添加回去。
8. 备份 Search
未使用,忽略。
9. 备份 Sqoop 2
未使用,忽略。
10. 备份 Hue
在 Hue Server 节点备份 app 注册文件:
mkdir -p /opt/cloudera/parcels_backup
cp -rp /opt/cloudera/parcels/CDH/lib/hue/app.reg /opt/cloudera/parcels_backup/app.reg-CM6.3.3-CDH5.16
升级前相关组件手动操作
请参考:
https://docs.cloudera.com/documentation/enterprise/upgrade/topics/ug_cdh6_pre_migration.html
具体细节下面说明。
1. Sentry
生产环境的 CDH 5 版本的 Sentry 未使用 Sentry policy file authorization,所以这一步忽略。
具体可以查看 Hive, Impala, or Solr services 是否开启 Enable Sentry Authorization using Policy Files。
2. Cloudera Search
基于 Solr 的搜索服务,未使用,忽略。
3. 迁移 Spark
3.1 停止 Spark (Standalone) 服务并移(未部署,忽略)
3.2 CDH 6 不支持使用多个版本的 Spark
如果升级到 CDH 6 将禁用 CDS 2 parcel(如果存在),并且所有 Spark 服务将使用内置的 Spark 版本(比如 CDH 6.0.0 中为 2.2)。例如,如果有两个 CDH 5 Spark(1.6)服务和两个 CDS 2 Spark(2.x)服务,则升级到 CDH 6后,将拥有四个 Spark 服务,全部使用内置的 CDH 6 Spark 版本。此外,在 CDH 6 中删除了用于在 CDH 5 中提交 Spark 2 作业的命令(spark2-submit),并替换为 spark-submit。
在同时具有内置 Spark 1.6 服务和 Spark 2 服务的 CDH 5 集群中,spark-submit 与 Spark 1.6 服务一起使用,spark2-submit 与 Spark 2 服务一起使用。升级到 CDH 6 之后,spark-submit 使用 CDH 内置的 Spark 2 服务,而 spark2-submit 不起作用。在升级到 CDH 6 之后,请确保使用这些命令更新提交 Spark 作业的所有工作流。
如果同时使用 CDH 5 中的内置 Spark 1.6 服务和 CDS 2 parcel,并且这两个服务在同一主机上都具有 gateway 角色,请增加要用作默认服务的服务的优先级。设置优先级的方法:
登录 Cloudera Manager Admin Console
选择需要在升级后默认运行的 Spark 服务
搜索 Alternatives Priority 属性
Alternatives Priority 设置比其他 Spark 服务高的值
比如把之前通过 Parcel 在 CDH 部署的 Spark 2.x 版本的 Alternatives Priority 设置为 88。
4. 迁移 HBase
该步操作需要到《步骤 6. 下载和分发 Parcels》时才可以操作,不要忘记了。
4.1 移除 PREFIX_TREE 数据块编码
在 CDH 6 版本中,PREFIX_TREE 的 DataBlock Encode 算法已经被移除,从 CDH 6 开始,启用 PREFIX_TREE 的 HBase 集群将失败。因此,在升级到 CDH 6 之前,必须确保所有数据都迁移到受支持的编码类型。
可以通过运行以下命令来确保没有任何表或快照使用 PREFIX_TREE 数据块编码:
# CDH 6.x 命令
hbase pre-upgrade validate-dbe
hbase pre-upgrade validate-hfile
如果下载并分发 CDH 6 parcel,则可以在升级集群之前使用给定的 CDH 6 parcel 运行此命令:
下载和分发 CDH 6 目标版本的 parcel
主要提醒:千万不要激活 CDH 6.x parcel
最好在 HMaster 主机上使用 CDH 6 parcel 运行 pre-upgrade 命令,例如:
$ kinit -kt hbase.keytab hbase
$ /opt/cloudera/parcels/CDH-6.3.3-1.cdh6.3.3.p0.1796617/bin/hbase pre-upgrade validate-dbe
$ /opt/cloudera/parcels/CDH-6.3.3-1.cdh6.3.3.p0.1796617/bin/hbase pre-upgrade validate-hfile
如果在运行命令时看到 “PREFIX_TREE not supported” 错误,则必须通过将源集群中的数据块编码类型更改为 Prefix、Diff 或 Fast Diff 来解决此错误。
注意:
如果在源集群中使用 HBase snapshots,则在开始升级之前必须执行以下操作:
1. 从现有 snapshots 中 clone 表,并更改数据块编码类型
2. 使用支持的编码类型运行 major 以重写文件
3. 一旦重写了 snapshots,就删除旧的 snapshots
4.2 升级 Co-Processor Classes
外部 co-processors 不会自动升级。处理 co-processor 升级有两种方法:
在继续升级之前,手动升级 co-processor jars。
暂时取消 co-processor 的设置并继续升级。一旦手动升级,它们就可以被重置。
试图升级 HBase 而不升级 co-processor jars 可能会导致不可预知的行为,如 HBase 角色启动失败、HBase 角色崩溃,甚至数据损坏。
通过运行 hbase pre-upgrade validate-cp 命令,可以确保 co-processors 协处理器与升级兼容。如果下载并分发 CDH 6 Parcel,则可以在升级集群之前使用给定的 CDH 6 Parcel 运行此命令:
下载和分发 CDH 6 目标版本的 parcel
主要提醒:千万不要激活 CDH 6.x parcel
最好在 HMaster 主机上使用 CDH 6 parcel 运行 pre-upgrade 命令,例如:
例如,你可以检查 master 上的协处理器兼容性:
$ /opt/cloudera/parcels/CDH-6.3.3-1.cdh6.3.3.p0.1796617/bin/hbase pre-upgrade validate-cp -jar /opt/cloudera/parcels/CDH-6.3.3-1.cdh6.3.3.p0.1796617/jars/ -config
或者,您可以验证每个表级的协同处理器,其中的表名与 .* 正则表达式匹配:
$ /opt/cloudera/parcels/CDH-6.3.3-1.cdh6.3.3.p0.1796617/bin/hbase pre-upgrade validate-cp -table .*
4.3 检查 HBase 相关的升级检查框
当尝试从 CDH 5 集群升级到 CDH 6 集群时,将出现复选框,以确保已经执行了所有与升级前迁移相关的 HBase 步骤。
只有在您同时检查以下两个语句时,升级才会继续:
Yes, I have run HBase pre-upgrade checks.
Yes, I have manually upgraded the HBase co-processor classes.

5. Hue
仅当升级到 CDH 6 或更高版本并且满足以下条件之一时,才需要执行操作:
Hue 已安装在 RHEL 6 或兼容主机上
使用 PostgresSQL
笔者 CDH 依赖的操作系统为 CentOS 7.4 以上版本,并且使用 MariaDB 数据库。
不满足条件,忽略。
6. Key Trustee KMS
未部署,忽略。
7. HSM KMS
未部署,忽略。
到此,大部分的准备工作已经做完了,接下来开始正式升级 CDH 集群。
开始升级 CDH 集群
前提
完成:
https://docs.cloudera.com/documentation/enterprise/upgrade/topics/ug_cdh_upgrade_before.html#cdh_before_you_begin
https://docs.cloudera.com/documentation/enterprise/upgrade/topics/ug_cdh_upgrade_backup.html#ug_cdh_upgrade_backup


笔者前面都有涉及,读者可以再大概回顾一下,不要有遗漏。
步骤 1. 备份 Cloudera Manager
尽管在升级 CM 之前已经备份过,但是在升级 CDH 之前,应该再次备份 Cloudera Manager 升级后的环境,具体参考上一篇文章《推荐升级四部曲之 CM 升级,收藏了!》的备份过程。
步骤 2. 进入 Maintenance Mode
完成升级后,请确保退出维护模式以重新启用 Cloudera Manager 警报。
步骤 3. 完成升级前迁移步骤
当从 CDH 5.x 升级到 CDH 6.x 时,完成下面的步骤:
3.1 Yarn
对 YARN NodeManagers 进行 Decommission 和 Recommission,但是不要启动 NodeManagers。之所以需要 Decommission,是因为在升级期间要让 NodeManagers 停止接受新的 containers,杀掉所有正在运行的 containers,然后关闭服务。操作过程如下:
确保新的 applications(比如 MapReduce 或 Spark applications)将不会提交到集群,直到升级完成
登录 Cloudera Manager Admin Console,进入要升级的 Yarn 服务
在 Instances 中,选择所有的 NodeManager roles(可以通过左侧的 ROLE Type 过滤出)
点击 Actions for Selected (number,为 NodeManager 数量) > Decommission
如果集群运行 CDH 5.9 或更高版本,由 Cloudera Manager 5.9 或更高版本管理,而且配置了 Graceful Decommission,则超时倒计时开始。
Graceful Decommission 可在开始 Decommission 过程之前提供超时,会创建一个时间窗口,以从系统中耗尽已经在运行的工作负载,并使其完全运行。
在 YARN 服务的 Configuration 选项卡上搜索 Node Manager Graceful Decommission Timeout 字段,然后将该属性设置为大于 0 的值以创建超时。等待 decommissioning 完成,此时 NodeManager State 为 Stopped,并且 Commission State 为 Decommissioned
仍然选中所有的 NodeManagers,点击 Actions for Selected (number) > Recommission
切记:不要启动 NodeManagers
3.2 Hive
查询语法、DDL 语法和 Hive API 有所更改。在升级之前,需要在应用程序工作负载中修改 HiveQL 代码。
https://www.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_600_incompatible_changes.html#hive_incompatible_changes_c6beta
3.3 Pig
未部署,忽略。
3.4 Sentry
未使用 Sentry policy file authorization 方式,忽略。
3.5 Cloudera Search
未部署,忽略。
3.6 Spark
如果使用 Spark 或 Spark Standalone(未部署,忽略),需要执行一些操作(见上面)。
3.7 Kafka
在 CDH 5.x 中,Kafka 是作为单独的 parcel 发布,可以使用 Cloudera Manager 与 CDH 5.x 一起安装。从 CDH 6.0 开始,Kafka 是 CDH 发行版的一部分,并作为 CDH 6.x parcel 的一部分进行部署。
操作步骤:
明确设置 Kafka protocol version 以匹配 brokers 和 clients 之间当前正在使用的协议版本。如下更新所有 brokres 上的 server.properties 配置参数:
a. 登录 Cloudera Manager Admin Console
b. 选择 Kafka service
c. 点击 Configuration
d. 搜索 Kafka Broker Advanced Configuration Snippet (Safety Valve) for kafka.properties
e. 添加如下参数
inter.broker.protocol.version = current_Kafka_version
log.message.format.version = current_Kafka_version
将 current_Kafka_version 替换为目前使用的 Apache Kafka 版本。请确保输入带有三个值的完整 Apache Kafka 版本号,例如 0.10.0。否则,将会看到类似于 Version0.10is not a valid version 的错误消息。
# 比如笔者的测试环境
inter.broker.protocol.version = 0.11.0
log.message.format.version = 0.11.0
保存修改,配置分发到每个 broker 节点。
步骤 4. 执行 Hue Document 清理操作
如果集群使用 Hue,请执行以下步骤(maintenance 版本不需要)。这些步骤清理了 Hue 使用的数据库表,并可以帮助升级后提高性能。
注:
maintenance 版本升级是指类似 5.16.1 升级到 5.16.2
minor 版本升级是指类似 5.13.x 升级到 5.16.x
major 版本升级是指类似 5.16.x 升级到 6.3.x
操作步骤如下详细讲解。
4.1 备份 Hue 数据库
mysqldump --databases hue -u root -p > hue-backup-`date +%F`-CDH5.16.sql
写到这里突然想起来,大家备份所有数据库或目录时,一定要规划好备份的目录,方便查找或执行操作。
4.2 连接到 Hue 数据库并检查表的大小
检查 desktop_document、desktop_document2、oozie_job、beeswax_session、beeswax_savedquery 和 beeswax_queryhistory 表的大小。如果其中任何一个有超过 100k 行,请运行清理操作。
select 'desktop_document' as table_name, count(*) from desktop_document
union
select 'desktop_document2' as table_name, count(*) from desktop_document2
union
select 'beeswax_session' as table_name, count(*) from beeswax_session
union
select 'beeswax_savedquery' as table_name, count(*) from beeswax_savedquery
union
select 'beeswax_queryhistory' as table_name, count(*) from beeswax_queryhistory
union
select 'oozie_job' as table_name, count(*) from oozie_job
order by 1;
4.3 下载 Hue script repo
选择一个运行的 Hue 实例的节点,该脚本要求 Hue 正在运行,并使用 Hue 的运行配置来运行。下载 hue_scripts 到任何 Hue 节点,这些脚本是一组库和命令:
wget https://github.com/cmconner156/hue_scripts/archive/master.zip
unzip master.zip
mv hue_scripts-master /opt/cloudera/hue_scripts
4.4 修改权限
增加脚本的可执行权限:
chmod 700 /opt/cloudera/hue_scripts/script_runner
4.5 执行脚本
在该节点上使用 root 执行这个脚本,DESKTOP_DEBUG=True 用来设置这个命令单次运行环境,因此不必再 tail 日志,日志会直接在 Console 上显示:
DESKTOP_DEBUG=True /opt/cloudera/hue_scripts/script_runner hue_desktop_document_cleanup --keep-days 90
如果没有设置 DESKTOP_DEBUG,则查看 /var/log/hue/hue_desktop_document_cleanup.log。
第一次运行时,每张表的 1000 entries 需要大约 1 minute。
4.6 再次检查大小
检查 desktop_document、desktop_document2、oozie_job、beeswax_session、beeswax_savedquery 和 beeswax_queryhistory 表的大小,并确认它们现在已经变得较小。
select count(*) from desktop_document; select count(*) from desktop_document2; select count(*) from beeswax_session; select count(*) from beeswax_savedquery; select count(*) from beeswax_queryhistory; select count(*) from oozie_job;
4.7
如果任何一个表的大小仍超过 100k,请再次运行该命令,以减少保留时间范围,减少数据量:
--keep-days 60 or --keep-days 30
步骤 5. 检查 Oracle 数据库初始化
未涉及,忽略。
步骤 6. 下载和分发 Parcels
配置和使用本地 CDH repo。
# http://repo.dataflow.com/cdh6/
# tree /var/www/html/cdh6
/var/www/html/cdh6
|-- CDH-6.3.3-1.cdh6.3.3.p0.1796617-el7.parcel
|-- CDH-6.3.3-1.cdh6.3.3.p0.1796617-el7.parcel.sha1
|-- CDH-6.3.3-1.cdh6.3.3.p0.1796617-el7.parcel.sha256
`-- manifest.json
0 directories, 4 files
如果集群安装了 Kudu 1.4.0 或更低版本,并且想升级到 CDH 5.13 或更高版本,请 deactivate 现有的 Kudu parcel
笔者测试环境 CDH 版本为 5.16.2,对应的 Kudu 版本为 1.7.0;
这里忽略操作。
下载和分发所有 parcels 后(回到前面对 HBase 进行升级前检查操作),单击所选 CDH 旁边的 Upgrade 按钮。
步骤 7. 运行升级 CDH 向导
从 parcels 页面选择 Upgrade,或从 Home > Status 中选择 Upgrade Cluster。选择之前下载/分发的 CDH 版本。

Cloudera Manager 5.14 和低版本(官方介绍,笔者未验证)
a. 在 Parcels 部分,选择想升级到的 CDH 版本
b. 点击 Continue(确定一些要求完成的额外步骤)
c. 点击 Yes, I have performed these steps
d. 点击 Continue
e. Cloudera Manager 验证 agents 是否响应并已安装正确的软件。当看到 No Errors Found 消息时,单击 Continue。
选定的 parcels 将被下载、分发和解压缩。
f. 点击 Continue
运行 Host Inspector,检查输出并修复任何报告出的错误。Cloudera Manager 5.15 和更高版本
a. 在 Parcel 部分,选择想要去升级的 CDH 版本。
升级向导会执行一些如下操作: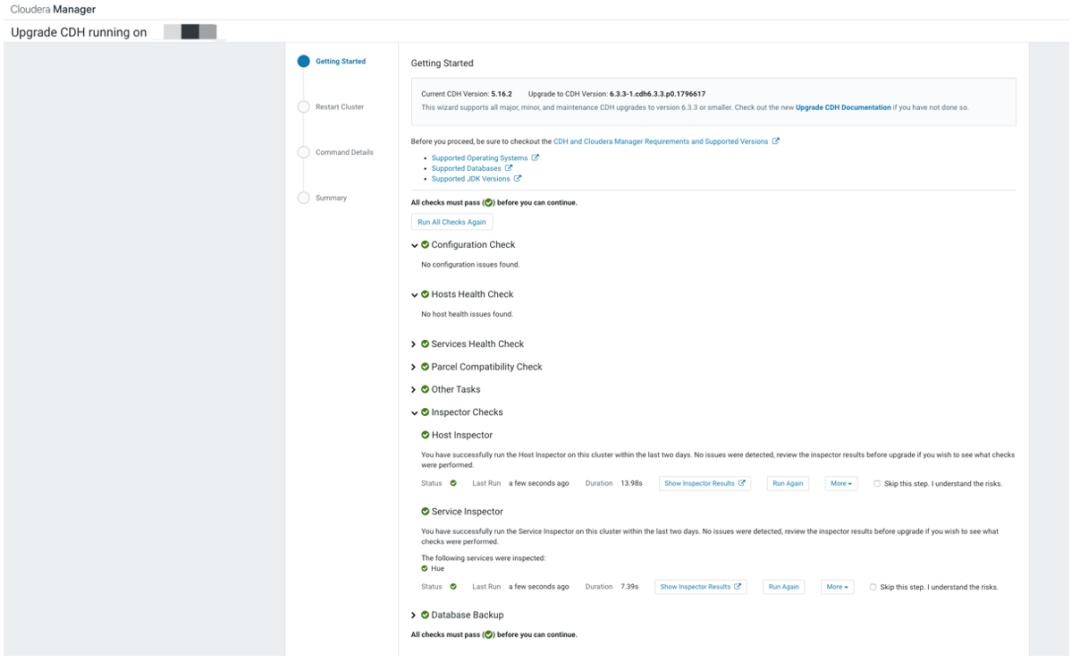
b. 点击运行 Host Inspector
运行 Host Inspector,点击 Show Inspector Results 查看 Host Inspector 的报告(浏览器打开一个新的页面)修复检查出来的问题。
c. 点击运行 Service Inspector
点击 Show Inspector Results 查看 Service Inspector 命令输出结果(浏览器打开一个新的页面),修复检查出来的问题。
d. 确定 Database Backup
e. 阅读升级之前必须注意要完成的步骤,然后选择 Yes, I have performed theses steps,然后点击 Continue
f. Restart Cluster
继续点击 Continue,将停止集群服务和开启升级进程。
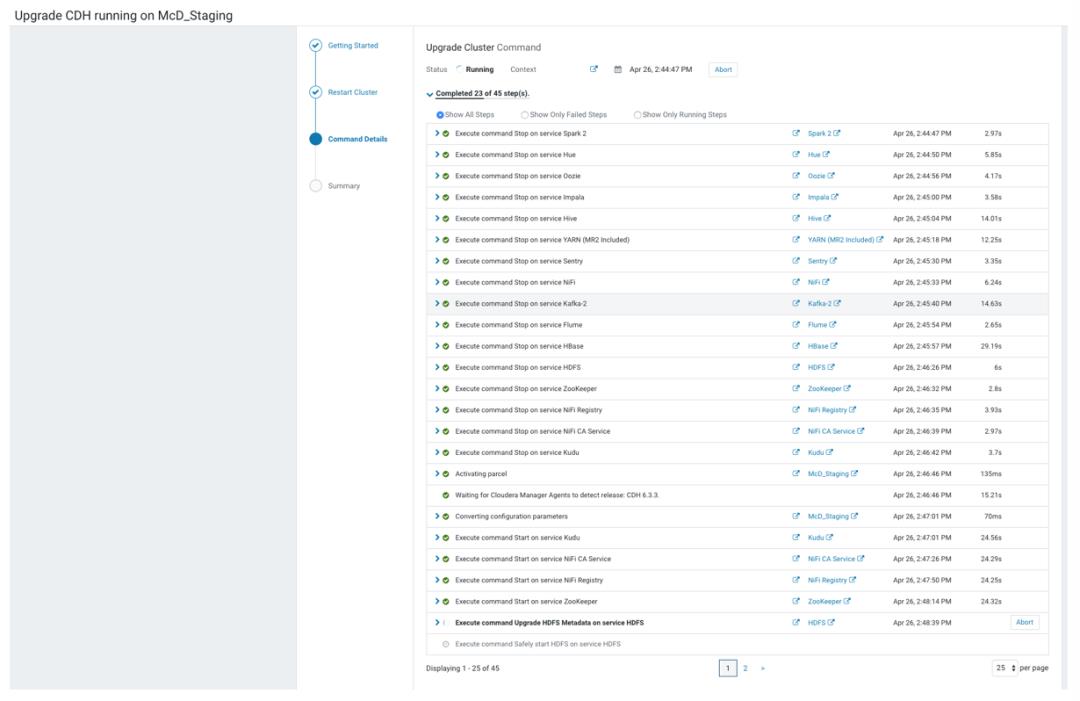
流程执行完成后,Continue 显示蓝色。
如果 parcels 与现有的 CDH 版本一起工作,则升级向导可能会显示一条消息,说明该 parcel 与新的 CDH 版本冲突。
a. 在继续处理之前,配置和下载这个 parcel 的最新版本。
a.1 从另一个浏览器打开 Cloudera Manager Admin Console,进入 parcels 页面,配置这个 parcel 的最新 parcel repo。
a.2 下载和分发这个最新 parcel
b. 点击 Run All Checks Again
c. 选择自动解决冲突的选项
d. Cloudera Manager deactivates 这个 parcel 老版本,activate 新版本,并且验证所有已经部署正确的软件版本。点击 Continue
在 Choose Upgrade Procedure 屏幕显示中,选择接下来的升级步骤:
Full Cluster Restart
Cloudera Manager 执行所有服务的升级和重启集群。Manual Upgrade
Cloudera Manager 将集群配置为指定的 CDH 版本,但不执行升级或服务重启。手动升级比较困难,并且仅适用于高级用户。手动升级可以有选择地停止和重新启动服务,以防止或减轻不支持滚动重启的服务或集群的停机时间。
为了执行手动升级,请参考 https://docs.cloudera.com/documentation/enterprise/upgrade/topics/ug_cm_wizard_actions.html#concept_wtk_rxw_ps。
如果自动升级失败后,就需要进入手动升级处理。关于手动升级的内容笔者下篇文章介绍。
点击 Continue
Upgrade Cluster Command 屏幕显示向导在关闭所有服务、激活新的 parcels、升级服务、部署客户端配置文件以及对支持该服务的服务进行滚动重新启动时运行的命令的结果。
如果任何步骤失败,请更正所有报告的错误,然后单击 Resume 按钮。Cloudera Manager 将跳过已成功重启的角色。或者,返回 Home > Status 选项卡,然后执行 Upgrading CDH Manually after an Upgrade Failure 中的步骤,进行手动升级。
如果 Cloudera Manager 在升级 CDH 时检测到故障,则 Cloudera Manager 将显示一个对话框,可以在其中创建诊断包以发送给 Cloudera 支持,以便他们可以帮助从故障中恢复。
点击 Finish,返回 Home 页面。
步骤 8. Finalize HDFS Upgrade
这一步一定要谨慎,finalize 会删除 HDFS 分布式文件系统的先前状态版本,本次升级会被持久化,rollback 不再可用。
确保在 finalize 之前,对升级后的 CDH 集群进行充分和完整的验证。
另外确保有足够的可用磁盘空间,在升级 finalize 之前,以下行为将继续:
删除文件不会释放磁盘空间。
使用 balancer 会导致所有移动的副本都被复制。
保留所有表示 NameNodes 元数据的磁盘上数据,这可能会使 NameNode 和 JournalNode 磁盘上所需的空间量增加一倍以上。
如果一切的一切都正常后,就可以 finalize 本次升级。
如果你开启了 HDFS 高可用,可以执行滚动升级:
进入 HDFS Service
选择 Actions > Finalize Rolling Upgrade,点击 Finalize Rolling Upgrade
如果你没有执行滚动升级:
进入 HDFS Service
点击 Instances tab
点击 NameNode instance 的链接。如果开启 HFDS 高可用,选择 NameNode(Active)
选择 Actions > Finalize Metadata Upgrade,并点击 Finalize Metadata Upgrade 确认
步骤 9. 对于使用 Oracle 数据库的 Sentry 执行相关操作
未使用 Oracle 数据库,忽略。
步骤 10. 自动升级完成
总结
自动升级相对来说还是比较省事的,但是升级过程中还会遇到不少问题,对于这些问题,笔者会放到下一篇文章中说明,也就是通过手动方式升级,解决升级过程中遇到的错误。
最后还得再补充两句,一是,备份一定要做好。二是,对于每一个步骤,要仔细阅读和认真操作。
你若喜欢,点个在看哦

以上是关于推荐升级四部曲之 CDH 升级重头戏,收藏了!的主要内容,如果未能解决你的问题,请参考以下文章