整库入湖方案设计方法
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了整库入湖方案设计方法相关的知识,希望对你有一定的参考价值。
整库入湖,顾名思义就是将整个库中的表入湖,为甚强调整库?先来看看如何进行单表入湖。
单表入湖有三种实现方式:
1. 全量入湖
一次性将整个表的数据入湖,实现单表整库入湖有很多工具可以完成,类似的工具有Datax、Sqoop、Kettle等,说类似是因为这些工具暂时还不支持最新数据湖,比如Iceberg、Hudi、Deltlake,但是经过开发修改是能够满足这类入湖需求的。Datax、Sqoop、Kettle之所以存在,是因为它们面向Hadoop生态,且表现不错,特别是面向高延时(T-1)数据同步场景,即使采用周期性全量替换数据湖数据已有数据也是可接受的,毕竟这种方式不存在数据错乱、丢失、重复、Schema不兼容等问题,但数据同步数据量较大,时效性太差。
2. 历史全量入湖+离线增量入湖
历史数据先通过上述全量一次性入湖后,再通过离线增量入湖,减轻了每次全量入湖的数据总量,且时效性大大提高。类似的工具仍然可以采用Datax、Sqoop、Kettle等,因为这些工具支持增量查询数据源,前提是数据源本身存在自增属性、带有能标识增量更新的时间戳属性等。这种方式能解决80%以上的数据同步需求,但是对实时性要求较高的场景无能为力。
3. 历史全量入湖+实时增量入湖
将上述离线增量入湖换成实时入湖就能解决余下20%的实时需求。实现实时入湖的工具有Debezium、Canal等,Debezium、Canal不仅支持通过API方式直接读取并入湖,还提供了现成服务,允许用户自定义配置将binlog数据发送到Kafka,然后再入湖。
这三种方式,后面两种增量入湖方式都存在数据重复或更新问题,但是处理方式不同,前者要求用户主动将增量部分跟全量部分合并生成新的全量数据,后者通过数据湖的核心能力(支持去重与更新)自动完成数据合并(这是我们对数据湖的期许,但是现实可能没那么美好)。本文重点关注实时增量入湖。
既然Debezium、Canal支持通过API方式直接读取并入湖,为什么要用Kafka呢?主要有几个原因:
1. binlog的产生速率可能会高于数据入湖速率,且binlog存储有存储时长约束,Kafka可以作为数据缓冲;
2. binlog数据可能被下游多次读取,用于不同作用的消费,Kafka存储binlog可以一数多用;
3. binlog一般不支持并行读取,用kafka存储可以实现并行消费;
基于Kafka实现的实时增量数据入湖的典型架构:

数据库的一张表,映射到kafka的一个Topic,Topic包含多个分区,同一份数据可以按照主键均衡分布多个分区。下游通过不同类型的算子并行执行Kafka分区读取数据、写入临时文件和提交文件最终入湖的操作。
一张表是这样,多张表是不是上述架构的简单叠加呢?显然不是!
为了节省资源,可以将多张表投递到同一个Kafka Topic,如分库分表的情形。实际上,投递规则可以更一般化,这方面Canal做得比较完善,它支持正则表达式定义投递规则,有以下几种常见方式,比如:
例子1:test\\\\.test 指定匹配的单表,发送到以test_test为名字的topic上
例子2:.*\\\\..* 匹配所有表,则每个表都会发送到各自表名的topic上
例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
例子4:test\\\\..* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
例子5:test,test1\\\\.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1\\\\.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
确定了对Kafka的投递规则后,接下来需要确定如何划分Topic内部分区?不可能将所有表的数据都发到只有一个分区的Topic里面,Canal支持用户设置表名或者主键后自动根据Topic的分区数动态散列数据到不同的分区,它支持以下规则,比如:
例子1:test\\\\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
例子2:.*\\\\..*:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
例子3:.*\\\\..*:$pk$ 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
例子4: 匹配规则啥都不写,则默认发到0这个partition上
例子5:.*\\\\..* ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
例子6: test\\\\.test:id,.\\\\..* , 针对test的表按照id散列,其余的表按照table散列
在实现整库或多表入湖实现上,可能会存在两个极端路线:
1. 全部库表都投递到同一个Topic上的一个或多个分区上,然后下游使用同一个作业消费入湖(简称方案一)
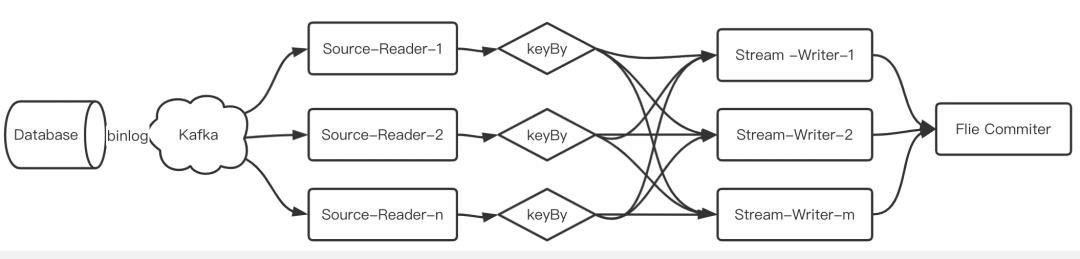
该方案首先要解决Topic内分区规则,前面介绍Canal支持按照表分区,也可以按照PK分区,而通过表名+PK分区的方式能够保证数据均衡分布,但是对PK要求存在且不可修改,否则容易造成数据顺便错乱。
然后对各分区的数据在进入下游消费的时候再次将相同表名+PK的数据路由到同一个Stream Writer任务中,如果表不支持PK分区,会造成算子级“数据倾斜”。
2. 每个表独立投递到不同的Topic,且独立分区,每个Topic使用独立的作业消费入湖(简称方案二)
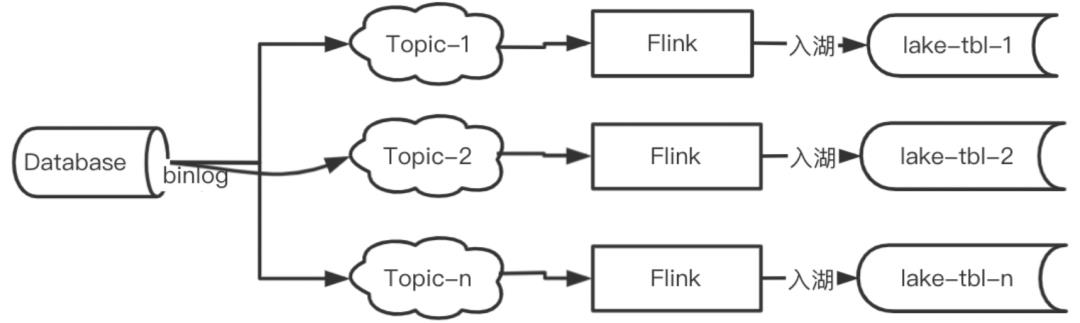
两种方式理论上都可行,且都有存在的理由。先比较下优缺点吧:
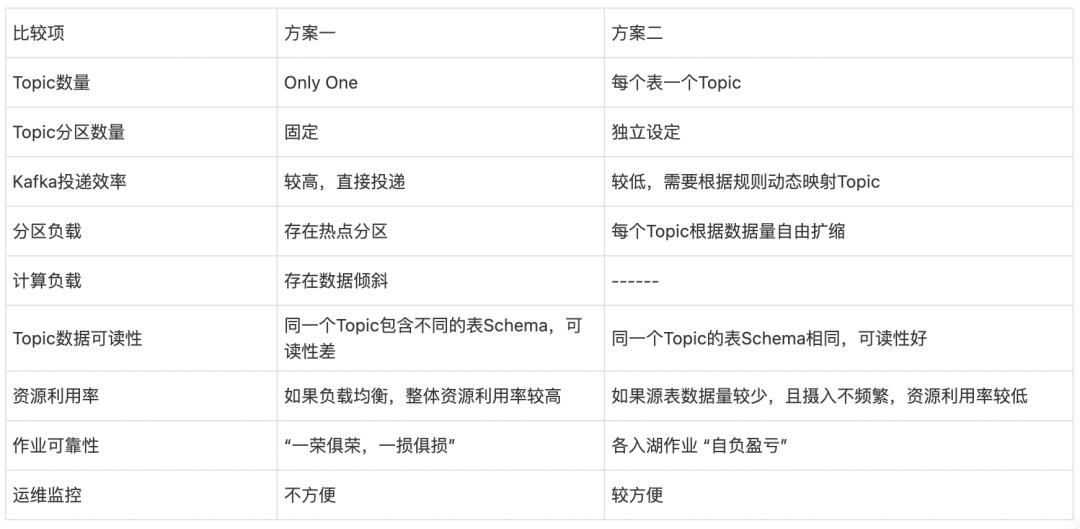
可见,两种方案的折中不失为一种不错的策略。
最后一个问题:两种方案都涉及到相同的问题,如何解决Schema动态变更?
最简单的办法是binlog要带上Schema信息,或者采用类似Schema Registry的方式。
综上,整库入湖就是通过自动化、资源最优的方式实现可靠地所有表入湖。
以上是关于整库入湖方案设计方法的主要内容,如果未能解决你的问题,请参考以下文章