RetinexNet: Deep Retinex Decomposition for Low-Light Enhancement
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RetinexNet: Deep Retinex Decomposition for Low-Light Enhancement相关的知识,希望对你有一定的参考价值。
文章目录
摘要
链接:https://arxiv.org/pdf/1808.04560.pdf
Retinex模型是微光图像增强的有效工具。假设观测图像可以分解为反射率和照度。大多数现有的基于retina的方法都为这种高度病态分解精心设计了手工制作的约束和参数,在应用于各种场景时可能会受到模型容量的限制。在本文中,我们收集了一个包含低光/正常光图像对的low -light数据集(LOL),并提出了一个基于该数据集的深度视网膜网,包括一个用于分解的分解网(Decom-Net)和一个用于亮度调整的增强网(enhanced - net)。在Decom-Net的训练过程中,没有分解反射率和光照的ground truth。该网络的学习只有关键约束,包括由配对的低光/正常光图像共享的一致反射率,以及照明的平稳性。在此基础上,通过增强网络(Enhance-Net)对光照进行亮度增强,联合去噪则对反射率进行去噪。视网膜网是端到端可训练的,因此学习到的分解本质上有利于亮度调整。大量的实验证明,我们的方法不仅在弱光增强中获得了视觉上令人愉悦的质量,而且还提供了良好的图像分解表示。

1、简介
图像捕获时光线不足会显著降低图像的可见性。细节的丢失和低对比度不仅会给人带来不愉快的主观感受,而且会影响许多针对普通光图像设计的计算机视觉系统的性能。造成照明不足的原因有很多,比如光照环境不好,摄影设备性能有限,设备配置不当等。为了使隐藏的细节可见,提高当前计算机视觉系统的主观体验和可用性,需要对微光图像进行增强。
在过去的几十年里,许多研究者都致力于解决微光图像增强的问题。许多技术已经被开发来提高弱光图像的主客观质量。直方图均衡化(HE)[20]及其变体对输出图像的直方图进行约束,以满足一定的约束条件。基于去雾的方法[5]利用光照不足的图像与雾霾环境下的图像之间的逆连接。
另一类微光增强方法是基于Retinex理论[12]建立的,该方法假设观测到的彩色图像可以分解为反射率和照度。单尺度Retinex (SSR)[11]在早期尝试中使用高斯滤波对光照映射进行平滑约束。多尺度Retinex (MSRCR)[10]扩展了SSR与多尺度高斯滤波器和颜色恢复。[23]提出了一种利用亮度-顺序-误差测度来保持照明自然度的方法。Fu等人[7]提出融合初始照明图的多个派生。SRIE[7]使用加权变分模型同时估计反射率和照度。对光照进行操作后,可以恢复目标结果。另一方面,LIME[9]只使用结构先验估计照明,并使用反射作为最终增强结果。也有基于视网膜的联合微光增强和噪声去除方法[14,15]。
虽然这些方法在某些情况下可能会产生很好的结果,但它们仍然存在反射率和照度分解模型容量的限制。设计出适用于各种场景的有效的图像分解约束是一件很困难的事情。此外,照明图的操作也是手工制作的,这些方法的性能通常依赖于精心的参数调优。
随着深度神经网络的快速发展,CNN已广泛应用于低层次图像处理,包括超分辨率[6,24,26,27],去雨[16,21,25]等。Lore等。[17]使用堆叠稀疏去噪自编码器同时进行弱光增强和降噪(LLNet),但没有考虑到弱光图片的性质。
为了克服这些困难,我们提出了一种数据驱动的Retinex分解方法。一个被称为Retinex-Net的深度网络,集成了图像分解和连续增强操作。首先,利用子网络分解网(Decom-Net)将观测图像分解为与光照无关的反射率和结构感知的光滑光照;分解网是在两个约束条件下学习的。首先,低光/正常光图像具有相同的反射率。其次,通过结构感知的全变差损失获得光照图的平滑且保留主要结构;然后,另一个增强网调整光照图以保持大区域的一致性,同时通过多尺度拼接调整局部分布。由于噪声通常在黑暗区域更大,甚至被增强过程放大,对反射率降噪引入。为了训练这样的网络,我们从真实摄影和RAW数据集中合成图像构建了一个低光/正常光图像对数据集。大量的实验证明,我们的方法不仅在弱光增强中获得了令人满意的视觉质量,而且提供了良好的图像分解表示。我们的工作贡献如下:
-
我们建立了一个大规模的数据集与配对的低/正常光图像捕获的真实场景。据我们所知,这是在微光增强领域的第一次尝试。
-
构建了基于Retinex模型的深度学习图像分解。分解网络与连续弱光增强网络进行端到端训练,因此框架具有良好的光条件调整能力。
-
我们提出了一种结构感知的全变分约束用于深度图像分解。通过在梯度较强的地方减少总变化的影响,该约束成功地平滑了照明图并保留了主要结构。
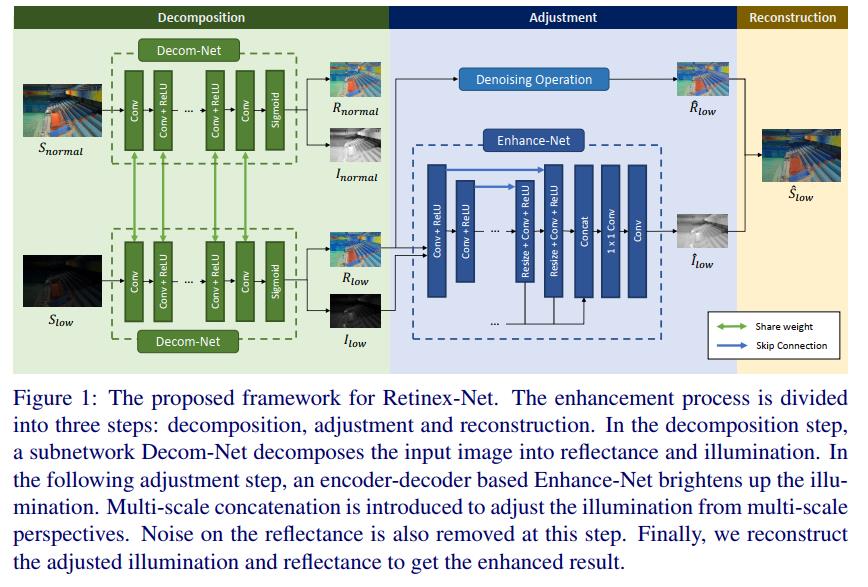
2、光增强RetinexNet
经典的Retinex理论模拟了人类的颜色感知。假设观测图像可以分解为反射率和照度两个分量。设S表示源图像,则可表示为
S
=
R
∘
I
(1)
S=R \\circ I \\tag1
S=R∘I(1)
其中R代表反射率,I代表照明, ∘ \\circ ∘代表元素明智的乘法。反射率描述了被捕获物体的内在特性,它被认为在任何亮度条件下都是一致的。照度表示物体上的各种明度。在低光图像上,它通常受到黑暗和照明分布不平衡的影响。
基于Retinex理论,我们设计了一个深度RetinexNet,实现了反射率/照度分解和弱光增强的结合。该网络由分解、调整和重构三个步骤组成。在分解步骤中,视网膜网通过decomx - net将输入图像分解为R和I。它在训练阶段接受成对的低光/正常光图像,而在测试阶段只接受低光图像作为输入。在低光/常光图像具有相同的反射率和光照平滑度的约束下,Decom-Net学会了以数据驱动的方式提取不同光照图像之间的一致R。调整步骤,一个Enhance-Net用于点亮照明地图。增强网采用了编码器-解码器的整体框架。该方法采用多尺度拼接方法,在保持大区域内光照与上下文信息的全局一致性的同时,集中注意力调整局部分布。此外,如果需要的话,通常发生在低光条件下的放大噪声可以从反射率中去除。然后,在重建阶段通过元素乘法将调整后的照度和反射率结合起来。
2.1 数据驱动的图像分解
分解观察到的图像的一种方法是直接估计在低光输入图像上的反射率和照明,使用手工精心制作的约束。由于式(1)是高度病态的,因此设计一个适合于各种场景的约束函数并不容易。因此,我们试图用数据驱动的方式来解决这个问题。
在训练阶段,Decom-Net每次接收成对的微光/常光图像,在微光图像和常光图像具有相同反射率的指导下,学习微光图像及其对应的常光图像的分解。注意,尽管分解是用成对数据训练的,但它可以在测试阶段单独分解低光输入。在训练过程中,不需要提供反射率和照度的ground truth。只有必要的知识,包括反射率的一致性和照明映射的平滑性嵌入到网络作为损失函数。因此,我们的网络分解是从成对的低光/正常光图像中自动学习的,本质上适合于描述不同光照条件下图像之间的光照变化。
需要注意的是,虽然这个问题可能在形式上类似于内在图像分解,但它们在本质上是不同的。在我们的任务中,我们不需要准确地获得实际的本征图像,而是一个很好的表示来进行光的调整。因此,我们让网络学会寻找微光图像与其对应增强结果之间的一致性分量。
如图1所示,Decom-Net以弱光图像 S low S_\\text low Slow和正常光图像 S normal S_\\text normal Snormal为输入,对 S low S_\\text low Slow分别估计反射率 R low R_\\text low Rlow和照度 I low I_\\text low Ilow,对 S normal S_\\text normal Snormal和 I normal I_\\text normal Inormal。它首先使用3 × 3卷积层从输入图像中提取特征。然后,通过若干个以整流线性单元(ReLU)为激活函数的3× 3卷积层,将RGB图像映射到反射率和照度。一个3× 3卷积层从特征空间投射R和I,使用sigmoid函数将R和I约束在[0,1]的范围内。
损失
L
\\mathcalL
L由三个项组成:重建损失
L
recon
\\mathcalL_\\text recon
Lrecon、不变反射率损失
L
ir
\\mathcalL_\\text ir
Lir和照明光洁度损失
L
i
s
\\mathcalL_i s
Lis:
L
=
L
recon
+
λ
i
r
L
i
r
+
λ
i
s
L
i
s
,
(2)
\\mathcalL=\\mathcalL_\\text recon +\\lambda_i r \\mathcalL_i r+\\lambda_i s \\mathcalL_i s, \\tag2
L=Lrecon +λirLir+λisLis,(2)
其中
λ
i
r
\\lambda_ir
λir和
λ
i
s
\\lambda_i s
λis表示平衡反射率的一致性和照明的平稳性的系数。
假设
R
low
和
R
high
R_\\text low和R_\\text high
Rlow和Rhigh都可以用对应的照明映射重建图像,重建损失
L
recon
\\mathcalL_\\text recon
Lrecon表示为:
L
recon
=
∑
i
=
low,normal
∑
j
=
low,normal
λ
i
j
∥
R
i
∘
I
j
−
S
j
∥
1
.
(3)
\\mathcalL_\\text recon =\\sum_i=\\text low,normal \\sum_j=\\text low,normal \\lambda_i j\\left\\|R_i \\circ I_j-S_j\\right\\|_1 \\text . \\tag3
Lrecon =i= low,normal ∑j= low,normal ∑λij∥Ri∘Ij−Sj∥1. (3)
引入不变反射率损失 L i r \\mathcalL_ir Lir来约束反射率的一致性:
L ir = ∥ R low − R normal ∥ 1 . \\mathcalL_\\text ir =\\left\\|R_\\text low -R_\\text normal \\right\\|_1 . Lir =∥Rlow −Rnormal ∥1.
照明平滑损失 L i s \\mathcalL_i s Lis将在下一节中详细描述。
2.2 结构感知平滑性损失
照明映射的一个基本假设是局部一致性和结构感知,如[9]所述。换句话说,一个好的光照贴图的解决方案应该是在纹理细节上平滑的同时还能保持整体的结构边界。
总变差最小化(Total variation minimization, TV)[2]是将整个图像的梯度最小化的算法,常用于各种图像恢复任务的平滑优先级。然而,直接使用TV作为损失函数,在图像结构较强或亮度变化较大的区域会失败。这是由于光照图的梯度一致的减少,无论区域是文本细节还是强边界。换句话说,电视损失是结构盲。光照被模糊化,反射率上留下了强黑边,如图2所示。
为了使损耗对图像结构的感知,对原始电视函数用反射率图梯度进行加权。最后的\\mathcalL_i s表示为:
L i s = ∑ i = low,normal ∥ ∇ I i ∘ exp ( − λ g ∇ R i ) ∥ , (5) \\mathcalL_i s=\\sum_i=\\text low,normal \\left\\|\\nabla I_i \\circ \\exp \\left(-\\lambda_g \\nabla R_i\\right)\\right\\|, \\tag5 Lis=i= low,normal ∑∥∇Ii∘exp(−λg∇Ri)∥,(5)
其中 ∇ \\nabla ∇表示梯度,包括 ∇ h ( h o r i z o n t a l ) \\nabla_h(horizontal) ∇h(horizontal)和 ∇ v ( v e r t i c a l ) \\nabla_v(vertical) ∇v(vertical), λ g \\lambda_g λg表示平衡结构感知强度的系数。随着权重 exp ( − λ g ∇ R i ) , L i s \\exp \\left(-\\lambda_g \\nabla R_i\\right), \\mathcalL_i s exp(−λg∇Ri),Lis在反射梯度陡峭的地方放松了平滑性的约束,
以上是关于RetinexNet: Deep Retinex Decomposition for Low-Light Enhancement的主要内容,如果未能解决你的问题,请参考以下文章