25.Flink监控什么是MetricsMetrics分类Flink性能优化的方法合理调整并行度合理调整并行度Flink内存管理Spark VS Flink时间机制容错机制等
Posted 涂作权的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了25.Flink监控什么是MetricsMetrics分类Flink性能优化的方法合理调整并行度合理调整并行度Flink内存管理Spark VS Flink时间机制容错机制等相关的知识,希望对你有一定的参考价值。
25.Flink监控
25.1.什么是Metrics
25.2.Metrics分类
25.2.1.Metric Types
25.2.2.代码
25.2.3.操作
26.Flink性能优化
26.1.复用对象
26.2.数据倾斜
26.3.异步IO
26.4.合理调整并行度
27.Flink内存管理
28.Spark VS Flink
28.1.应用场景
28.2.API
28.3.核心角色/流程原理
28.3.1.spark
28.3.2.Flink
28.4.时间机制
28.5.容错机制
28.6.窗口
28.7.整合Kafka
28.8.其他的
28.9.单独补充:流式计算实现原理
28.10.单独补充:背压/反压
28.10.1.back pressure
25.Flink监控
https://blog.lovedata.net/8156c1e1.html
25.1.什么是Metrics
由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的Task日志,比如作业很大或者有很多作业的情况下,该如何处理?此时Metrics可以很好的帮助开发人员了解作业的当前状态。
Flink提供的Metrics可以在Flink内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。

25.2.Metrics分类
25.2.1.Metric Types
1.常用的如Counter, 写过mapreduce作业的开发人员就应该很熟悉Counter, 其实含义都是一样的,就是对一个计数器进行累加,即对于多条数据和多兆数据一直往上加的过程。
2.Gauga,Gauge是最简单的Metrics,它反映一个值。比如要看现在Java heap内存用了多少,就可以每次实时的暴露一个Gauge, Gauge当前的值就是heap使用的量。
3.Meter, Meter是指统计吞吐量和单位时间内发生”事件”的次数。它相当于求一种速率,即事件次数除以使用的时间。
4.Histogram,Histogram比较复杂,也并不常用,Histogram用于统计一些数据的分布,比如说Quantile、Mean、StdDev、Max、Min等。
Metric在Flink内部有多层结构,以Group的方式组织,它并不是一个扁平化的结构,Metric Group + Metric Name是Metrics的唯一标识。
25.2.2.代码
package day6;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.metrics.Counter;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author tuzuoquan
* @date 2022/6/22 9:26
*/
public class MetricsDemo
public static void main(String[] args) throws Exception
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>()
@Override
public void flatMap(String value, Collector<String> out) throws Exception
String[] arr = value.split(" ");
for (String word : arr)
out.collect(word);
);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words
.map(new RichMapFunction<String, Tuple2<String, Integer>>()
//用来记录map处理了多少个单词
Counter myCounter;
//对Counter进行初始化
@Override
public void open(Configuration parameters) throws Exception
myCounter = getRuntimeContext().getMetricGroup().addGroup("myGroup").counter("myCounter");
//处理单词,将单词记为(单词,1)
@Override
public Tuple2<String, Integer> map(String value) throws Exception
myCounter.inc();//计数器+1
return Tuple2.of(value, 1);
);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne.keyBy(t -> t.f0).sum(1);
//TODO 3.sink
result.print();
//TODO 4.execute
env.execute();
运行命令:
// /export/server/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
// /export/server/flink/bin/flink run --class cn.xxx.metrics.MetricsDemo /root/metrics.jar
// 查看WebUI
25.2.3.操作
1.打包
2.提交到Yarn上运行
3.查看监控指标

4.也可以通过浏览器f12的找到url发送请求获取监控信息

5.也可以通过代码发送请求获取监控信息
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class MetricsTest
public static void main(String[] args)
//String result = sendGet("http://node1:8088/proxy/application_1609508087977_0010/jobs/558a5a3016661f1d732228330ebfaad5/vertices/cbc357ccb763df2852fee8c4fc7d55f2/metrics?get=0.Map.myGroup.myCounter");
String result = sendGet("http://node1:8088/proxy/application_1609508087977_0010/jobs/558a5a3016661f1d732228330ebfaad5");
System.out.println(result);
public static String sendGet(String url)
String result = "";
BufferedReader in = null;
try
String urlNameString = url;
URL realUrl = new URL(urlNameString);
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String line;
while ((line = in.readLine()) != null)
result += line;
catch (Exception e)
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
// 使用finally块来关闭输入流
finally
try
if (in != null)
in.close();
catch (Exception e2)
e2.printStackTrace();
return result;
26.Flink性能优化
26.1.复用对象
stream.apply(new WindowFunction<WikipediaEditEvent, Tuple2<String, Long>, String, TimeWindow>()
@Override
public void apply(String userName, TimeWindow timeWindow, Iterable<WikipediaEditEvent> iterable, Collector<Tuple2<String, Long>> collector) throws Exception
long changesCount = ...
// A new Tuple instance is created on every execution
collector.collect(new Tuple2<>(userName, changesCount));
上面的代码可以优化为下面的代码:
可以避免Tuple2的重复创建
stream.apply(new WindowFunction<WikipediaEditEvent, Tuple2<String, Long>, String, TimeWindow>()
// Create an instance that we will reuse on every call
private Tuple2<String, Long> result = new Tuple<>();
@Override
public void apply(String userName, TimeWindow timeWindow, Iterable<WikipediaEditEvent> iterable, Collector<Tuple2<String, Long>> collector) throws Exception
long changesCount = ...
// Set fields on an existing object instead of creating a new one
result.f0 = userName;
// Auto-boxing!! A new Long value may be created
result.f1 = changesCount;
// Reuse the same Tuple2 object
collector.collect(result);
26.2.数据倾斜

rebalance
自定义分区器
key+随机前后缀
26.3.异步IO
26.4.合理调整并行度
数据过滤之后可以减少并行度
数据合并之后再处理之前可以增加并行度
大量小文件写入到HDFS可以减少并行度
1.ds.writeAsText(“data/output/result1”).setParallelism(1);
2.env.setParallelism(1);
3.提交任务时webUI或命令行参数 flink run -p 10
4.配置文件flink-conf.yaml parallelism.default: 1
更多的优化在后面的项目中结合业务来讲解
27.Flink内存管理
1.减少full gc时间:因为所有常用数据都在Memory Manager里,这部分内存的生命周期是伴随TaskManager管理的而不会被GC回收。其他的常用数据对象都是用户定义的数据对象,这部分会快速的被GC回收。
2.减少OOM:所有的运行的内存应用都从池化的内存中获取,而且运行时的算法可以在内存不足的时候将数据写到堆外内存。
3.节约空间:由于Flink自定序列化/反序列化的方法,所有的对象都以二进制的形式存储,降低消耗。
4.高效的二进制操作和缓存友好:二进制数据以定义好的格式存储,可以高效地比较与操作。另外,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中。这使得数据结构可以对CPU高效缓存更友好,可以从CPU的L1/L2/L3缓存获取性能的提升,也就是Flink的数据存储二进制格式符合CPU缓存的标准,非常方便被CPU的L1/L2/L3各级别缓存利用,比内存还要快!
28.Spark VS Flink
28.1.应用场景
Spark:主要用作离线批处理 , 对延迟要求不高的实时处理(微批) ,DataFrame和DataSetAPI 也支持 “流批一体”
Flink:主要用作实时处理 ,注意Flink1.12开始支持真正的流批一体
28.2.API
Spark : RDD(不推荐) /DSteam(不推荐)/DataFrame和DataSet
Flink : DataSet(1.12软弃用) 和 DataStream /Table&SQL(快速发展中)
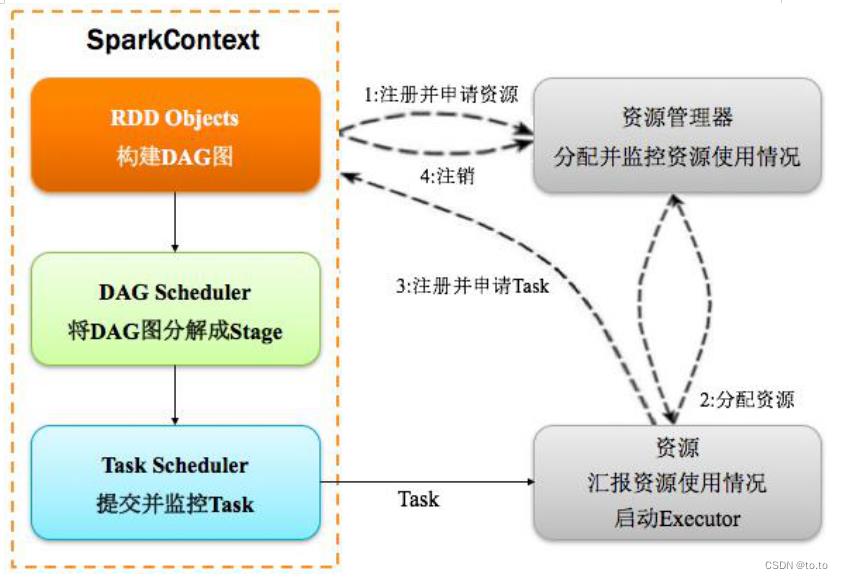
28.3.核心角色/流程原理
28.3.1.spark

28.3.2.Flink
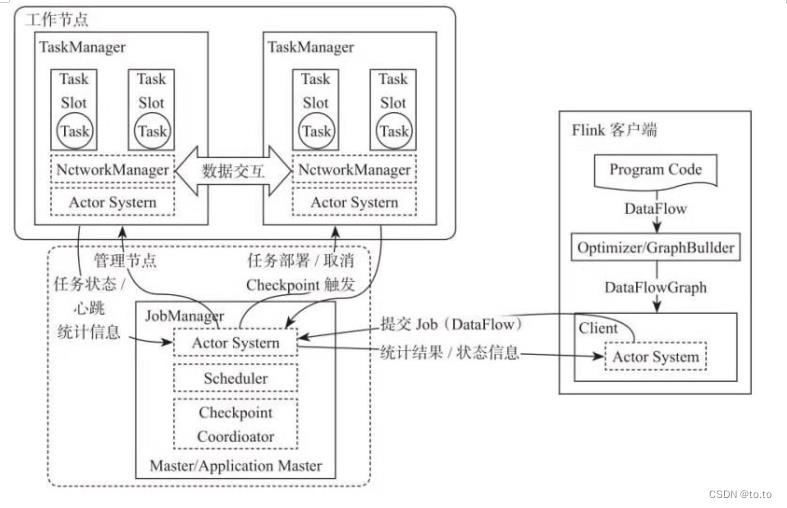


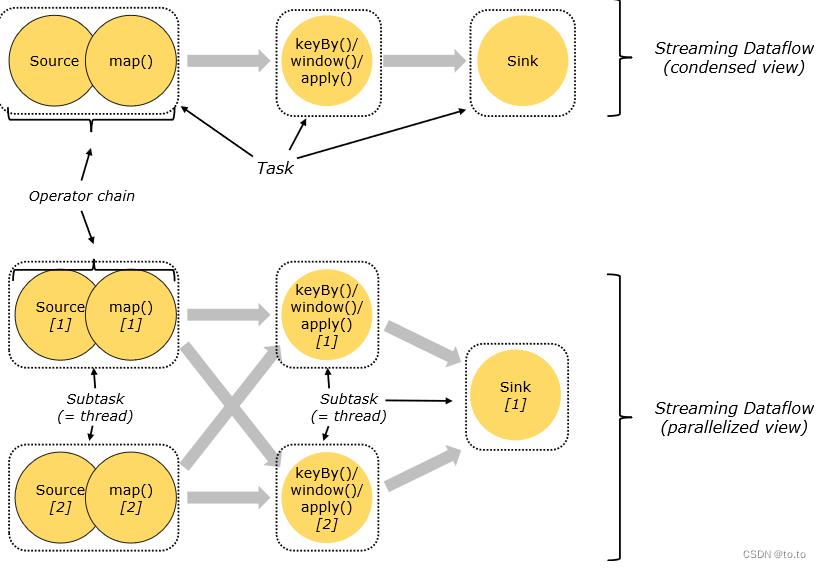

28.4.时间机制
Spark: SparkStreaming只支持处理时间 StructuredStreaming开始支持事件时间
Flink: 直接支持事件时间 / 处理时间 /摄入时间
28.5.容错机制
Spark : 缓存/持久化 +Checkpoint(应用级别) StructuredStreaming中的Checkpoint也开始借鉴Flink使用Chandy-Lamport algorithm分布式快照算法
Flink: State + Checkpoint(Operator级别) + 自动重启策略 + Savepoint
28.6.窗口
Spark中的支持基于时间/数量的滑动/滚动 要求windowDuration和slideDuration必须是batchDuration的倍数
Flink中的窗口机制更加灵活/功能更多
支持基于时间/数量的滑动/滚动 和 会话窗口
28.7.整合Kafka
SparkStreaming整合Kafka: 支持offset自动维护/手动维护 , 支持动态分区检测 无需配置

Flink整合Kafka: 支持offset自动维护/手动维护(一般自动由Checkpoint维护即可) , 支持动态分区检测 需要配置
//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis","5000");
28.8.其他的
源码编程语言
Flink的高级功能 : Flink CEP可以实现 实时风控…
28.9.单独补充:流式计算实现原理
Spark :
SparkStreaming: 微批
StructuredStreaming: 微批(连续处理在实验中)
Flink : 是真真正正的流式处理, 只不过对于低延迟和高吞吐做了平衡
早期就确定了后续的方向:基于事件的流式数据处理框架!
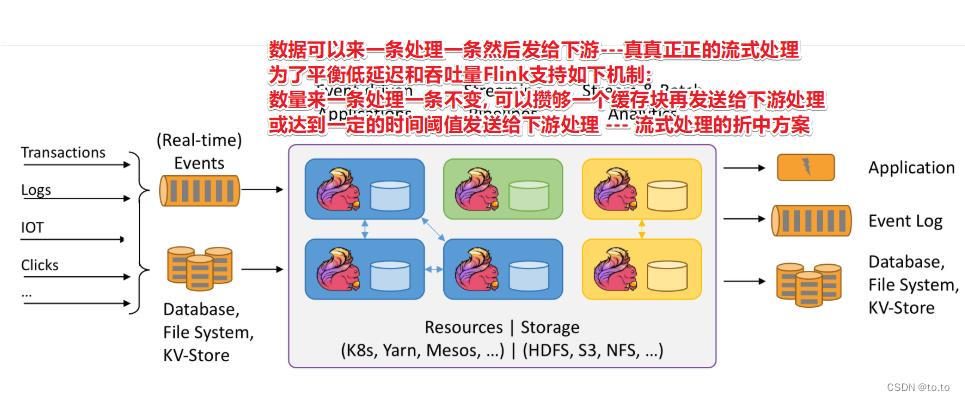
env.setBufferTimeout - 默认100ms
taskmanager.memory.segment-size - 默认32KB
28.10.单独补充:背压/反压
28.10.1.back pressure
Spark: PIDRateEsimator ,PID算法实现一个速率评估器(统计DAG调度时间,任务处理时间,数据条数等, 得出一个消息处理最大速率, 进而调整根据offset从kafka消费消息的速率)。
Flink: 基于credit – based 流控机制,在应用层模拟 TCP 的流控机制(上游发送数据给下游之前会先进行通信,告诉下游要发送的blockSize, 那么下游就可以准备相应的buffer来接收, 如果准备ok则返回一个credit凭证,上游收到凭证就发送数据, 如果没有准备ok,则不返回credit,上游等待下一次通信返回credit)

阻塞占比在 web 上划分了三个等级:
OK: 0 <= Ratio <= 0.10,表示状态良好;
LOW: 0.10 < Ratio <= 0.5,表示有待观察;
HIGH: 0.5 < Ratio <= 1,表示要处理了(增加并行度/subTask/检查是否有数据倾斜/增加内存…)。
例如,0.01,代表着100次中有一次阻塞在内部调用
以上是关于25.Flink监控什么是MetricsMetrics分类Flink性能优化的方法合理调整并行度合理调整并行度Flink内存管理Spark VS Flink时间机制容错机制等的主要内容,如果未能解决你的问题,请参考以下文章