java如何实现定时从数据库查询新增的数据,?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java如何实现定时从数据库查询新增的数据,?相关的知识,希望对你有一定的参考价值。
主要是数据库新增的数据怎么样查询出来,定时查询所有数据我会,查询新增的数据该怎么实现呢?
有几种方法,我觉得第二种,触发器是个好主意,见下。第一种,开个线程,定式扫描,比如每一分钟查询一次数据库,将前后数据做比对(比对方法可以在java端先把第一次的数据存到一个集合中,然后每次查询集合之后,将两次的内容在java端作比较)
第二种,在数据库端,比如oracle数据库,对这个要监控的表A建个触发器,这个表中如果有数据改变,包括楼主要的新增,修改,删除,都可以被触发,然后把改变的内容存到另一个表B中,然后java就直接从这个B表中查询就可以了,省去了比对的工作。
第三种,如果你是用的类似spring这种框架,spring自带有类似crontab的功能,可以写个一般的java类,这个类中仅仅干查询数据,比对数据的工作,然后调度的工作交给spring框架来做,基本来说这个方法与第一种相比,只是调度者不同而已
第四种,可以随便写个java类,进行查询比对,然后在跑这个java程序的主机上,比如linux主机,配置一个crontab,来定时调度。追问
第一种能详细说说么?
追答第一种,这么说吧,就是你随便写个类,继承与thread类。
在这个类的run方法中,定义两个list,用第一个list保存你每次查询数据库中的结果集,
然后用第二个list保存之前一次的数据。
醉消耗内存的一步来了,因为要比较,你肯定需要逐个对比,看当前记录是否与之前的有重复的地方。如果不是重复的,那么肯定是新增的,如果是重复的,,,也未必就不是新增,因为有可能是以下的场景
你第一查询,查到了一条新增的记录,然后在第一和第二次查询的间隙中,这条记录被删除,然后又新增回来,这样,在一定情况下也算新增,所以这个情况的处理要根据你的业务逻辑来做处理,我不能给你个适合你的答案啦
基本思路就是这样,有问题问我哈
例如表中flag字段,默认为0,处理过之后就为1
这样,你才能判断哪条数据是新的,哪条数据是老的了
或者用时间判断来自:求助得到的回答 参考技术A 在表上新增一个字段,比如INSERT_TIMESTAMP,要求insert数据的时候必须插入当时的时间。
你select的时候就检查当前时间和上次查询的时间(可以在页面或者内存里记录这个上次查询的时间,或者根据你的定时策略,反推到你上次查询的时间)内的数据可以OK追问
上次查询的时间怎么保存?保存到哪里?
参考技术B 多线程还是单线程?如果是多线程来处理这个问题的话要注意可能一条数据可能会被多个线程捞到,这个时候你要考虑用同步块,而识别新旧数据只需要用一个字段来标识即可追问这个?能详细说说么 ??
参考技术C 给数据加入time字段(入库时间)查询大于你上次查询时间的数据,ok追问
上次查询的时间怎么保存?
追答可以放到static 变量里,也可以写进txt
追问额 感觉好深奥,还是不太懂啊
一次性集中处理大量数据的定时任务,如何缩短执行时间?
作者:58沈剑问题抽象:
(1)用户会员系统;
(2)用户会有分数流水,每个月要做一次分数统计,对不同分数等级的会员做不同业务处理;
数据假设: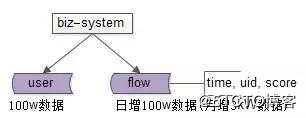
(1)假设用户在100w级别;
(2)假设用户日均1条流水,也就是说日增流水数据量在100W级别,月新增流水在3kW级别,3个月流水数据量在亿级别;
常见解决方案:
用一个定时任务,每个月的第一天计算一次。
//(1)查询出所有用户
uids[] = select uid from t_user;
//(2)遍历每个用户
foreach $uid in uids[]
//(3)查询用户3个月内分数流水
scores[]= select score from t_flow
where uid=$uid and time=[3个月内];
//(4)遍历分数流水
foreach $score in scores[]
//(5)计算总分数
sum+= $score;
//(6)根据分数做业务处理
switch(sum)
升级降级,发优惠券,发奖励;
一个月执行一次的定时任务,会存在什么问题?
计算量很大,处理的数据量很大,耗时很久,按照水友的说法,需要1-2天。
画外音:外层循环100W级别用户;内层循环9kW级别流水;业务处理需要10几次数据库交互。
可不可以多线程并行处理?
可以,每个用户的流水处理不耦合。
改为多线程并行处理,例如按照用户拆分,会存在什么问题?
每个线程都要访问数据库做业务处理,数据库有可能扛不住。
这类问题的优化方向是:
(1)同一份数据,减少重复计算次数;
(2)分摊CPU计算时间,尽量分散处理,而不是集中处理;
(3)减少单次计算数据量;
如何减少同一份数据,重复计算次数?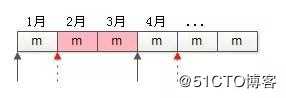
如上图,假设每一个方格是1个月的分数流水数据(约3kW)。
3月底计算时,要查询并计算1月,2月,3月三个月的9kW数据;
4月底计算时,要查询并计算2月,3月,4月三个月的9kW数据;
…
会发现,2月和3月的数据(粉色部分),被重复查询和计算了多次。
画外音:该业务,每个月的数据会被计算3次。
新增月积分流水汇总表,每次只计算当月增量:
flow_month_sum(month, uid, flow_sum)
(1)每到月底,只计算当月分数,数据量减少到1/3,耗时也减少到1/3;
(2)同时,把前2个月流水加和,就能得到最近3个月总分数(这个动作几乎不花时间);
画外音:该表的数量级和用户表数据量一致,100w级别。
这样一来,每条分数流水只会被计算一次。
如何分摊CPU计算时间,减少单次计算数据量呢?
业务需求是一个月重新计算一次分数,但一个月集中计算,数据量太大,耗时太久,可以将计算分摊到每天。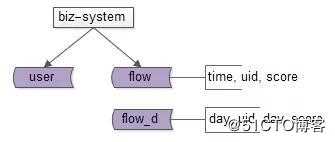
如上图,月积分流水汇总表,升级为,日积分流水汇总表。
把每月1次集中计算,分摊为30次分散计算,每次计算数据量减少到1/30,就只需要花几十分钟处理了。
甚至,每一个小时计算一次,每次计算数据量又能减少到1/24,每次就只需要花几分钟处理了。
虽然时间缩短了,但毕竟是定时任务,能不能实时计算分数流水呢?
每天只新增100w分数流水,完全可以实时累加计算“日积分流水汇总”。
使用DTS(或者canal)增加一个分数流水表的监听,当用户的分数变化时,实时进行日分数流水累加,将1小时一次的定时任务计算,均匀分摊到“每时每刻”,每天新增100w流水,数据库写压力每秒钟10多次,完全扛得住。
画外音:如果不能使用DTS/canal,可以使用MQ。
总结,对于这类一次性集中处理大量数据的定时任务,优化思路是:
(1)同一份数据,减少重复计算次数;
(2)分摊CPU计算时间,尽量分散处理(甚至可以实时),而不是集中处理;
(3)减少单次计算数据量;
希望大家有所启示,思路比结论重要。
最后
欢迎大家一起交流,喜欢文章记得点个赞哟,感谢支持!
以上是关于java如何实现定时从数据库查询新增的数据,?的主要内容,如果未能解决你的问题,请参考以下文章