python读取文件由于编码问题失败汇总
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python读取文件由于编码问题失败汇总相关的知识,希望对你有一定的参考价值。
背景
在日常工作中常常涉及用Python读取文件,但是经常遇到各种失败,比如:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xed in position 6342: invalid continuation byte
问题1
分析和排查
本次实验使用 pandas 读取文本并展示前5条数据:
import pandas as pd
raw_file = "/share/jiepeng.liu/public_data/ner/weiboNER/weiboNER.conll.dev"
df = pd.read_csv(raw_file, sep='\\t')
print(df.head())
读取文件的时候报错:
df = pd.read_csv(raw_file, sep='\\t')
File "/opt/conda/lib/python3.8/site-packages/pandas/util/_decorators.py", line 311, in wrapper
return func(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/pandas/io/parsers/readers.py", line 680, in read_csv
return _read(filepath_or_buffer, kwds)
File "/opt/conda/lib/python3.8/site-packages/pandas/io/parsers/readers.py", line 575, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File "/opt/conda/lib/python3.8/site-packages/pandas/io/parsers/readers.py", line 934, in __init__
self._engine = self._make_engine(f, self.engine)
File "/opt/conda/lib/python3.8/site-packages/pandas/io/parsers/readers.py", line 1236, in _make_engine
return mapping[engine](f, **self.options)
File "/opt/conda/lib/python3.8/site-packages/pandas/io/parsers/c_parser_wrapper.py", line 75, in __init__
self._reader = parsers.TextReader(src, **kwds)
File "pandas/_libs/parsers.pyx", line 544, in pandas._libs.parsers.TextReader.__cinit__
File "pandas/_libs/parsers.pyx", line 633, in pandas._libs.parsers.TextReader._get_header
File "pandas/_libs/parsers.pyx", line 847, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1952, in pandas._libs.parsers.raise_parser_error
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xed in position 6342: invalid continuation byte
该问题是由于出现了无法进行转换的二进制数据造成的,可以写一个脚本来判断,是整体的字符集参数选择上出现了问题,还是出现了部分的无法转换的二进制块:
raw_file = "/share/jiepeng.liu/public_data/ner/weiboNER/weiboNER.conll.dev"
def check_pd_read_utf8():
#以读入文件为例:
f = open(raw_file, "rb")#二进制格式读文件
print("file_name=", raw_file)
line_num = 0
while True:
line = f.readline()
line_num +=1
if not line:
break
else:
try:
#print(line.decode('utf8'))
line.decode('utf8')
#为了暴露出错误,最好此处不print
except:
print("line num=, text=".format(line_num, str(line)))
具体有几种可能:
- 如果输出的代码都是hex形式的,可能就是选择的解码字符集出现了错误。 对于python2.7版本的来说,网上有使用这样一种方式处理:
#coding=utf8
import sys
reload(sys)
sys.setdefaultencoding("UTF-8")
但是,上述这种方法在python3版本中,已经取消了。
- 如果是字符集出现错误,可以使用特定方式判断其字符集编码方式。这部分脚本代码会在后面补充贴出来。也可以使用notepad++打开目标文件,查看右下角的部位,会指示该文件是那种编码。
- 有的情况,是这样的,整个文件是好的,如果用notepad++打开后,能够看到文件是可以打开的,似乎什么问题都没有发生过,但是,用python进行解码的时候,却会出现错误(上述实验代码就是这种情况)。
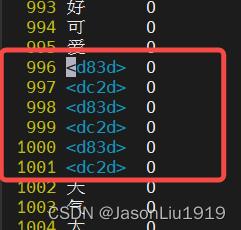
check_pd_read_utf8 函数运行结果如下:
line num=996, text=b'\\xed\\xa0\\xbd\\tO\\n'
line num=997, text=b'\\xed\\xb0\\xad\\tO\\n'
line num=998, text=b'\\xed\\xa0\\xbd\\tO\\n'
line num=999, text=b'\\xed\\xb0\\xad\\tO\\n'
line num=1000, text=b'\\xed\\xa0\\xbd\\tO\\n'
line num=1001, text=b'\\xed\\xb0\\xad\\tO\\n'
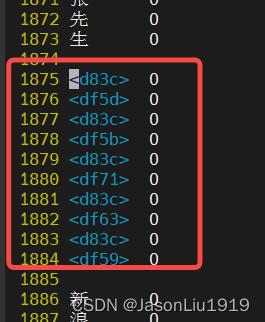
line num=1875, text=b'\\xed\\xa0\\xbc\\tO\\n'
line num=1876, text=b'\\xed\\xbd\\x9d\\tO\\n'
line num=1877, text=b'\\xed\\xa0\\xbc\\tO\\n'
line num=1878, text=b'\\xed\\xbd\\x9b\\tO\\n'
line num=1879, text=b'\\xed\\xa0\\xbc\\tO\\n'
line num=1880, text=b'\\xed\\xbd\\xb1\\tO\\n'
line num=1881, text=b'\\xed\\xa0\\xbc\\tO\\n'
line num=1882, text=b'\\xed\\xbd\\xa3\\tO\\n'
line num=1883, text=b'\\xed\\xa0\\xbc\\tO\\n'
line num=1884, text=b'\\xed\\xbd\\x99\\tO\\n'
进一步查看原始文件:
解决方法
确实在特定行数据上存在不属于编码字符集中的内容,从而导致’utf-8’解码失败。有两种处理方式,
- 在原始数据中将对应的行删除
- 在pandas读取文件时,设置
encoding_errors='ignore',将错误行直接忽略
import pandas as pd
raw_file = "/share/jiepeng.liu/public_data/ner/weiboNER/weiboNER.conll.dev"
df = pd.read_csv(raw_file, sep='\\t', encoding_errors='ignore')
print(df.head())
问题2
分析和排查
在用 pandas.read_csv 读取文件后报错:
pandas.errors.ParserError: Error tokenizing data. C error: EOF inside string starting at row 39252
出现上述问题,说明在特定行存在错误字符,这种错误字符的存在使得 pandas csv 解析器无法读取整个文件。
pandas.errors.ParserError: Error tokenizing data. C error: EOF 报错是因为pandas读取csv文件时,会默认把csv文件中两个双引号之间的内容解析为一个string,作为一个字段域读入,并且忽略两个双引号之间的分隔符。所以,在默认方式下,一旦文件中出现了奇数个双引号,那么最后一个引号从所在的行开始,直到文件结束也没有对应的结束引号形成单个字段域,就会报这个异常,即文件结束符(EOF)出现在了字符串中。
统计原始文件中双引号的个数:

解决方法
- 直接删除一个双引号的行数据,从而确保双引号的数量为偶数
- 读取文件时,增加参数
quoting=csv.QUOTE_NONE
较为优雅的解决方式是设置参数quoting的值,从而改变pandas在读取csv的上述默认行为。在pandas的read_csv函数中,有两个参数和这个行为有关,分别是quotechar引用符和quoting引用行为,如下所示,摘自pandas的官方文档。
quotechar : str (length 1), optional
The character used to denote the start and end of a quoted item. Quoted items can include the delimiter and it will be ignored.
quoting : int or csv.QUOTE_* instance, default 0
Control field quoting behavior per csv.QUOTE_* constants. Use one of QUOTE_MINIMAL (0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3).
quotechar 引用符参数是表示在读取解析时,将指定的符号认为是引用符,不仅仅限制于双引号,默认情况下是双引号。被设为引用符之后,就会按照上面所述的那样,在引用符之间的内容会被解析为单个域读入,包括换行符和分隔符。而quoting表示引用行为,即如何对待引用符的解析。这里具有四种情况,分别是csv.QUOTE_MINIMAL, csv.QUOTE_ALL, csv.QUOTE_NONNUMERIC, csv.QUOTE_NONE默认是csv.QUOTE_MINIMAL。这4个参数的解释如下:
-
csv.QUOTE_MINIMAL:只有当遇到引用符时,才会将引用符之间的内容解析为一个字符域读入,并且读取之后的域是没有引用符的,即引用符本身只作为一个域的边界界定,不会显示出来;在写入时,也只有具有引用符的域会在文件中加上引用符。 -
csv.QUOTE_ALL:在写入文件时,将所有的域都加上引用符。 -
csv.QUOTE_NONNUMERIC:写入文件时,将非数字域加上引用符。 -
csv.QUOTE_NONE:读取文件时,不解析引用符,即把引用符当做普通字符对待并且读入,不做特殊的对待;在写入文件时,也不对任何域加上引用符。
所以,要解决本次实验过程遇到的异常,只需要将quoting参数设为3,或者导入python的内置模块csv,设为csv.QUOTE_NONE,这样pandas在读取时,就只会把引用符当做普通字符,从而不会一直寻找对应的结束引用符直至文件结束都没找到,从而报错。当然,由于这行是乱码,分隔符数量很可能也不正常,即分隔后和前面的行的域的个数不一致,还会报错,所以只需要将error_bad_lines参数设为False,这样pandas就会自动删除这种不正常的bad lines,从而文件剩下的正常的内容就可以正常的读入了。pandas 1.3版本之后推荐使用on_bad_lines这个参数,可以将其on_bad_lines='skip'实现等同功能。当然,根据quotechar的功能,也可以通过将quotechar设为其他的单个字符,从而pandas会把双引号当做普通字符,但是这样做的风险在于可能会触发其他引用符带来的异常,所以不推荐这样做。
附录
检查文件编码类型代码如下:
import chardet
# 使用 chardet 检查文件编码类型
def check_file_encoding_type_chardet(file):
# 二进制方式读取,获取字节数据,检测类型
with open(file, 'rb') as f:
encoding = chardet.detect(f.read())['encoding']
#这种方式把整个文件读取进去,如果存在异常编码异常的字符(比如问题1中的数据),会返回None
#encoding = chardet.detect(f.read()[0:1024])['encoding']# 只读取部分数据,更快
print("chardet check file encoding type=", encoding)
file_name = "/share/jiepeng.liu/public_data/ner/weiboNER/weiboNER.conll.train"
check_file_encoding_type_chardet(file_name)
# 使用 magic 来检查文件编码类型
def check_file_encoding_type_magic():
# pip install python-magic
import magic
blob = open(file_name, 'rb').read()
m = magic.Magic(mime_encoding=True)
encoding = m.from_buffer(blob)
print("magic check file encoding type=", encoding)
check_file_encoding_type_magic()
# 检查哪一行出现编码异常
def check_pd_read_utf8():
#以读入文件为例:
f = open(file_name, "rb")#二进制格式读文件
print("file_name=", file_name)
line_num = 0
while True:
line = f.readline()
line_num +=1
if not line:
break
else:
try:
#print(line.decode('utf8'))
line.decode('utf8')
#为了暴露出错误,最好此处不print
except:
print("line num=, text=".format(line_num, str(line)))
check_pd_read_utf8()
以上是关于python读取文件由于编码问题失败汇总的主要内容,如果未能解决你的问题,请参考以下文章