实验2:Numpy手写多层神经网络
Posted 大气层煮月亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验2:Numpy手写多层神经网络相关的知识,希望对你有一定的参考价值。
引言
这个作业的目的是给你们介绍建立,训练和测试神经系统网络模型。您不仅将接触到使用Python包构建神经系统网络从无到有,还有数学方面的反向传播和梯度下降。但在实际情况下,你不一定要实现神经网络从零开始(你们将在以后的实验和作业中看到),这个作业旨在给你们对像TensorFlow和Keras这样的包的底层运行情况有一个初步的了解。在本作业中,您将使用MNIST手写数字数据集来训练一个简单的分类神经网络使用批量学习和评估你的模型。
English(英文):http://t.csdn.cn/p8KTX
Link to this article .pdf file
---------------------------------------------------------------------------------------------------------------------------------
提取码:v6zc
https://pan.baidu.com/s/1_qFbN0Nhc8MNYCHEyTbkLg%C2%A0
实验2:Numpy手写多层神经网络
实验所需文件
文件获取:
链接:https://pan.baidu.com/s/1JQnPdOJQXqQ43W74NuYqwg
提取码:2wlg
文件结构:
| - hw2
| - code
| - Beras
| - 8个.py文件用于实现实验要求函数
| - assignment.py
| - preprocess.py
| - visualize.py
| - data
| - mnist
| - 四个数据集文件
概念上的问题
请提交关于Gradescope的概念问题在hw2-mlp概念性下。您必须输入您提交的内容并上传PDF文件。我们建议使用LaTeX。
获得模板
Github Classroom Link with Stencil Code!
Guide on GitHub and GitHub Classroom
获得数据
可使用download.sh下载数据。方法可以运行bash脚本命令。
/script_name.sh(例如:bash ./download.sh)。
这与HW1类似。使用除去所提供的模板代码,但除非指定,否则不要更改模板。
这样做可能会导致与自动分级程序不兼容。不要更改任何方法签名!
这个作业需要NumPy和Matplotlib。你应该已经从HW1得到这个了。也可以查看虚拟环境指南,在本地机器上设置TensorFlow 2.5。请随意
如果必须使用colab,请参考本指南。
作业概述:
在这个作业中,你将构建一个Keras模仿,Beras(哈哈有趣的名字),并将制定一个模仿Tensorflow/Keras API的顺序模型规范。
Python与本作业相关的笔记本是为了让您探索一个示例实现这样你就可以自己动手了!笔记本上没有什么待办事项需要你去做;
相反,测试是通过运行assign .py的主要方法来完成的。
我们的模板提供了一个模型类,其中包含您需要使用的几个方法和超参数你的网络。
你还将回答与作业和课程相关的概念性问题材料(如果你是2470专业的学生,
别忘了回答2470专业的问题!)你应该包括一个简短的自述文件,
说明你的模型的准确性和任何已知的bug。
实验开始之前:
这份家庭作业在发布两周后到期。实验室1-3提供了很好的练习这个任务,
所以如果你卡住了,你可以等他们一会儿。具体地说:
☆ -
实现可调用/可扩散组件:实现此目标所需的技能
可以通过实验室1找到。这包括对数学的精通
符号、矩阵运算以及调用和梯度方法背后的逻辑。
☆ -
实现优化器:您可以通过以下方法实现BasicOptimizer类
按照实验室1中gradient - descent方法的逻辑。其他的优化
(例如Adam, RMSProp)将在实验室2:优化器中讨论。
☆ -
使用batch_step和GradientTape:您可以了解如何使用它们来训练您的基于赋值指令和这些指令的实现进行建模。与也就是说,他们确实模仿了Keras API。你将在实验3:介绍中了解所有这些Tensorflow。如果你的实验在截止日期之后,应该没问题;浏览一下与实验室相关的补充笔记本。你可以先做你能做的,然后在学习更多关于深度的知识时再添加。学习并意识到你在课堂上学到的概念实际上可以在这里使用!不要气馁,试着玩得开心点!
路线图:在这个作业中,我们会带你走过神经网络训练的流程,包括模型类的结构和您必须填写的方法。
1. 预处理的数据
在训练网络之前,需要清理数据。这包括检索、更改数据并将其格式化为网络的输入。对于这个任务,您将处理MNIST数据集。它可以通过下载.sh脚本,但它也链接在这里(忽略它所说的hw1;我们使用这个这次是hw2的数据集!)。原始数据源在这里。您应该只使用训练数据训练网络,然后测试网络测试数据的准确性。你的程序应该在测试中打印出它的准确性数据集完成后。
注:预处理代码需要从HW1中拉入。
2. 独热编码
在训练或测试模型之前,您需要对类标签进行“one-hot”编码因此,该模型可以优化到预测任何期望的类。注意,类标签本身就是简单的类别,在数字上没有任何意义。在如果没有单热编码,您的模型可能会学习之间的一些自然排序基于标签的不同类标签(标签是任意的)。例如,假设有一个数据点a对应标签“2”和一个数据点B对应于标签' 7 '。我们不想让模型知道B比a的权重高,因为从数字上讲,7 > 2。要一次性编码你的类标签,你需要必须转换你的一维标签向量吗到大小为num_classes的向量中(其中中的类的总数你的数据集)。对于MNIST数据集,它是这样的类似于右边的矩阵:
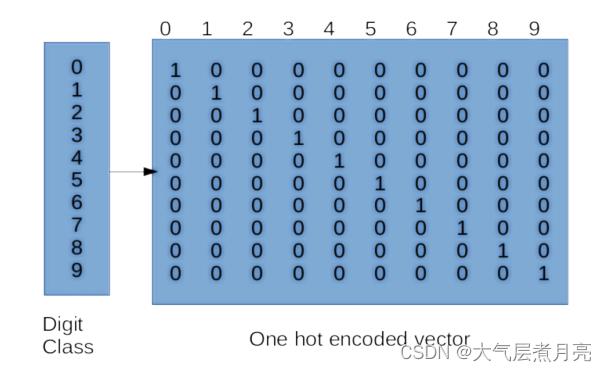
您必须在Beras/onehot.py中填写以下方法:
●fit(): [TODO] 在这个函数中,你需要在Data(将其存储在self.uniq中)并创建一个以标签作为键的字典和它们对应的一个热编码作为值。提示:你可能想这么做查看np.eye()以获得单热编码。最终,您将存储它在self.uniq2oh字典。
●forward(): 在这个函数中,我们传递一个向量,包含对象中所有实际的标签训练集并调用fit()来用unique填充uniq2oh字典标签及其对应的one-hot编码,然后使用它返回一个针对训练集中每个标签的单热编码标签数组。
这个函数已经为您填好了!
●inverse(): 在函数中,我们将one-hot编码反转为实际编码标签。
这已经为你做过了。
例如,如果我们有标签X和Y,其单热编码为[1,0]和[0,1],我们将
X: [1,0], Y:[0,1]。如上图所示,
对于MNIST,你将有10个标签,所以你的字典应该有10个条目!
您可能会注意到,有些类继承自Callable或Diffable。更多关于这
在下一节!
3.核心抽象
考虑以下模块的抽象类。一定要玩一下与此相关的Python笔记本作业,可以很好地掌握核心在Beras/core.py中为您定义的抽象模块!笔记本是探索性的(它不是必需的,所有的代码都给出了),并将为您提供许多深入理解和使用这些类抽象!注意以下模块与Tensorflow/Keras API非常相似。
可调用的:具有定义良好的前向函数的函数。这些是你需要的实现:
● CategoricalAccuracy (./metrics.py):计算预测的精度概率与基本事实标签列表的对比。由于精度没有优化,没有必要计算它的梯度。此外,类别准确性是分段不连续,所以梯度在技术上是0或无定义的。
● OneHotEncoder (./onehot.py):你可以将一个类实例one-hot编码到一个优化概率分布,分类为离散的选项:
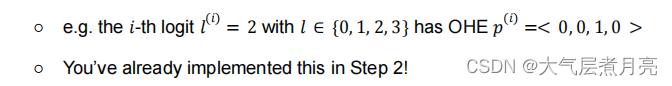
可分化的:也可分化的可调用对象。我们可以把这些用在我们的生产线上并通过它们进行优化!因此,大多数这些类都是为在您的神经系统中使用而创建的网络层。这些是你需要实现的:

示例:考虑一个致密层实例。让s表示输入大小(源),d表示输出大小(目标),b表示批处理大小。然后:

GradientTape:这个类的功能完全类似于tf.GradientTape()(参见实验3)。你可以把GradientTape看作记录器。每次操作在梯度磁带的作用域,它记录了发生的操作。然后,在
Backprop,我们可以计算所有操作的梯度。这允许我们对任意中间步骤求最终输出的微分。当操作计算在GradientTape的范围之外,他们不会被记录,所以你的代码会没有它们的记录,不能计算梯度。您可以查看这是如何在核心实现的!当然,Tensorflow的梯度磁带的实现要复杂得多,需要构建一个图表。
●[TODO]实现梯度方法,它返回一个梯度列表,对应于网络中可训练的权重列表。代码中的详细信息。
4. 网络层
在本文中,您将实现在您的在Beras/layers.py中的顺序模型。你必须填写下列方法:
● forward() : [TODO] 实现向前传递和返回输出。
● weight_gradients() : [TODO] 计算关于的梯度权重和偏差。这将用于优化图层。
● input_gradients() : [TODO] 计算关于的梯度层的输入。这将用于将渐变传播到前面的层。
● _initialize_weight() : [TODO] 初始化致密层的权重值默认情况下,将所有权重初始化为零(顺便说一下,这通常是个坏主意)。你也需要允许更复杂的选项(当初始化式为设置为normal, xavier和kaiing)。遵循Keras的数学假设!
〇 Normal:不言自明,单位正态分布。
〇 Xavier Normal:基于keras.GlorotNormal。
〇 Kaiing He Normal:基于Keras.HeNormal。
在实现这些时,你可能会发现np.random.normal很有帮助。的行动计划说明为什么这些不同的初始化方法是必要的,但是欲了解更多细节,请查看这个网站!请随意添加更多初始化器选项!
5. 激活函数
在这次作业中,你将实现两个主要的激活功能,即:Beras/activation .py中的LeakyReLU和Softmax。因为ReLU是一个特例的LeakyReLU,我们已经提供了它的代码。
● LeakyReLU ()
〇 forward() : [TODO]给定输入x,计算并返回LeakyReLU(x)。
〇 input_gradients() : [TODO]计算并返回与通过对LeakyReLU求导得到输入。
● Softmax():(2470 ONLY)
forward(): [TODO]给定输入x,计算并返回Softmax(x)。确保使用的是稳定的softmax,即减去所有项的最大值防止溢出/undvim erflow问题。
〇 input_gradients(): [TODO] Softmax()的部分w.r.t输入。
6. 填充模型
有了这些抽象概念,让我们为顺序深度学习创建一个序列模型。你可以在assignment.py中找到SequentialModel类初始化你的神经网络的层,参数(权重和偏差),和超参数(优化器、损失函数、学习率、精度函数等)。的SequentialModel类继承自Beras/model.py,在那里您可以找到许多有用的方法。这还将包含适合您的数据和模型的函数评估你的模型的性能:
● compile() : 初始化模型优化器,损失函数和精度函数,它们作为参数输入,供SequentialModel实例使用。
● fit() : 训练模型将输入和输出关联起来。重复训练每个时代,数据是基于参数的批处理。它还计算Batch_metrics、epoch_metrics和聚合的agg_metrics可以用来跟踪模型的训练进度。
● evaluate() : [TODO] 评估最终模型的性能使用测试阶段中提到的指标。它几乎和符合()函数;想想培训和测试之间会发生什么变化)。
● call() : [TODO] 提示:调用顺序模型意味着什么?还记得顺序模型是一堆层,每一层只有一个输入向量和一个输出向量。你可以在在assignment.py中的SequentialModel类。
● batch_step() : [TODO] 您将看到fit()为每一个都调用了这个函数批处理。您将首先计算输入批处理的模型预测。在训练阶段,你需要计算梯度和更新你的权重根据您正在使用的优化器。对于训练过程中的反向传播,你将使用GradientTape从核心抽象(core.py)来记录操作和中间值。然后您将使用模型的优化器来将梯度应用到模型的可训练变量上。最后,计算和
返回该批次的损耗和精度。你可以在在assignment.py中的SequentialModel类。
我们鼓励你去看看keras。在介绍笔记本中的SequentialModel(在探索一个可能的模块化实现:TensorFlow/Keras)和参考来到实验室3,感受一下我们如何在深度学习中使用梯度磁带。
7、损失函数
这是模型训练中最关键的方面之一。在这次作业中,我们会实现MSE或均方误差损失函数。你可以找到损失函数在Beras/ losses.py。
● forward() : [TODO] 编写一个计算并返回平均值的函数给出预测和实际标签的平方误差。
提示:什么是MSE?在给出预测和实际标签的情况下,均方误差是预测值与实际值之间的差异。
● input_gradients() : [TODO] 计算并返回梯度。使用用微分法推导出这些梯度的公式。
8.优化器
在Beras/optimizer .py文件中,确保为每个不同类型的优化器。实验二应该能帮上忙,祝你好运!
● BasicOptimizer : [TODO] 一个简单的优化器策略,如实验1所示。
● RMSProp : [TODO] 误差传播的均方根。
● Adam : [TODO] 一个常见的基于自适应运动估计的优化器。
9. 精度指标
最后,为了评估模型的性能,您需要使用适当的精度指标。在这项作业中,你将在Beras/ metrics.py实现评估分类的准确性:
● forward() : [TODO] 返回模型的分类精度预测概率和真标签。你应该返回的比例预测标签等于真实标签,其中图像的预测标签为与最高概率对应的标签。参考网络或讲座幻灯片的分类精度数学!
10. 训练和测试
最后,使用上述所有原语,您需要在其中构建两个模型assignment.py:
● get_simple_model()中的一个简单模型,最多只有一个扩散层(例如:density - ./layers.py)和一个激活函数(在/ activation.py)。虽然可以这样做,但默认情况下为您提供了这个选项。如果你愿意,可以改一下。自动评分器将评估原始的一个!
● get_advanced_model()中稍微复杂一点的模型,有两个或更多扩散层和两个或两个以上的激活函数。我们推荐使用Adam该模型的优化器具有相当低的学习率。
对于您使用的任何超参数(层大小,学习率,历元大小,批处理大小,等),请硬编码这些值在get_simple_model()和get_advanced_model()函数。不要将它们存储在主处理程序下。一旦一切都实现了,就可以使用python3 assignment.py来运行你的建模,看看损失/精度!
11. 可视化的结果
我们为您提供了visualize_metrics方法来可视化您的损失和每次使用matplotlib后,精确度都会发生变化。不要编辑此函数。在存储了损失和精度之后,应该在主方法中调用这个函数数组中的每个批处理,将传递给此函数。这应该是一条线横轴是第i批,纵轴是批量损失/精度值。调用这个是可选的!我们还提供了visualize_images方法来可视化您的使用matplotlib对真实标签的预测。此方法目前使用形状为[图像数量,1]的标签。不要编辑此函数。在训练模型之后,您应该使用所有的输入和标签调用这个函数。的函数会从你的输入中随机选择500个样本,并画出10个正确的和10个错误的分类帮助您直观地解释模型的预测!你在您达到测试准确度的基准之后,应该最后执行此操作。
CS1470 Students
- 完成并提交HW2概念
- 根据规范实现Beras,并在assignment.py中创建一个SequentialModel
- 在main内部测试模型
- 使用默认的get_simple_model_components在MNIST上获得测试精度>=85%。
- 完成Exploration notebook.ipny,并将其导出为PDF格式。
- “HW2 Intro to Beras” jupyter notebook 供您参考。
CS2470 Students
- 除了和1470一样的任务之外还要完成:
- 实现Softmax激活函数(forward pass和input_gradient)
- 从get_advanced_model_components获得MNIST模型的测试精度>95%。
- 你将需要指定一个多层模型,将不得不探索超参数选项,并可能希望添加其他功能。
- 其他功能可能包括正则化,其他权重初始化方案、聚合层、退出、速率调度或跳过连接。如果如果你有其他想法,请随时公开询问Ed,我们会告诉你的,好吧。
- 在实现这些特性时,尽量模仿Keras API可能的。这对你的探索笔记本有很大帮助。
- 完成探索笔记本和概念性问题的2470个组件。
分级和自动分级兼容性
概念: 你的评分标准主要是正确、深思熟虑和清晰。
代码: 你将主要根据功能来评分。你的模型应该有一个精度至少大于测试数据上的阈值。对于1470,这可以通过提供简单的模型参数化。对于2470,您可能需要试验超参数或开发一些自定义组件。虽然你不会根据代码风格打分,但你不应该有过多的在最终提交中打印声明。
重要的: 请尽可能使用向量化操作,并限制for循环的数量你使用。虽然运行这个作业没有严格的时间限制,但通常应该少一些超过3分钟。自动评分器将在10分钟后自动超时。你将不会收到使用Tensorflow或Keras函数的方法。
笔记本: 探险笔记本将手动评分,并应以pdf格式提交文件。请随意使用“从笔记本到乳胶pdf”。ipynb“笔记本!交你应该通过Gradescope在相应的项目作业下提交作业通过压缩你的hw2文件夹(Gradescope上的路径必须是hw2/code/filename.py)或通过GitHub(推荐)。通过GitHub提交,提交并推送所有更改到你的存储库到GitHub。您可以通过运行以下三个命令(这是一个这是了解它们的好资源):
1. git add file1 file2 file3 (or -A)
2. git commit -m “commit message”
3. git push
在提交和推送你的更改到你的回购(如果你不确定它是否有效,你可以在网上检查)之后,你现在可以上传回购到Gradescope!如果您在多个分支上测试代码,您可以选择您想要的任何一个分支。
重要的!
1. 请确保所有文件都在hw2/code中。否则,自动评分器将失败!
2. 在压缩代码之前删除data文件夹。
3. 在hw2/code目录中添加一个名为2470student的空白文件!该文件不应该有扩展名,并且用作标记来对特定于2470的需求进行分级。如果如果你不这样做,你就会丢分!
谢谢!
参考答案:http://t.csdn.cn/9sdBN
以上是关于实验2:Numpy手写多层神经网络的主要内容,如果未能解决你的问题,请参考以下文章