神经网络学习小记录72——Parameters参数量FLOPs浮点运算次数FPS每秒传输帧数等计算量衡量指标解析
Posted Bubbliiiing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络学习小记录72——Parameters参数量FLOPs浮点运算次数FPS每秒传输帧数等计算量衡量指标解析相关的知识,希望对你有一定的参考价值。
神经网络学习小记录72——Parameters参数量、FLOPs浮点运算次数、FPS每秒传输帧数等计算量衡量指标解析
学习前言
很多同学在学习时想到轻量化这一优化方案,但常常面对到一个困境是为什么参数量减少了,速度反而变慢了?在这个博客中,我会对网络中常用的计算量衡量指标进行解析。

网络的运算时组成
目前大部分的轻量级模型在对比模型速度时用的指标是FLOPs,这个指标主要衡量的就是卷积层的乘法操作。
但是实际运用中会发现,同一个FLOPS的网络运算速度却不同,只用FLOPS去进行衡量的话并不能完全代表模型速度。
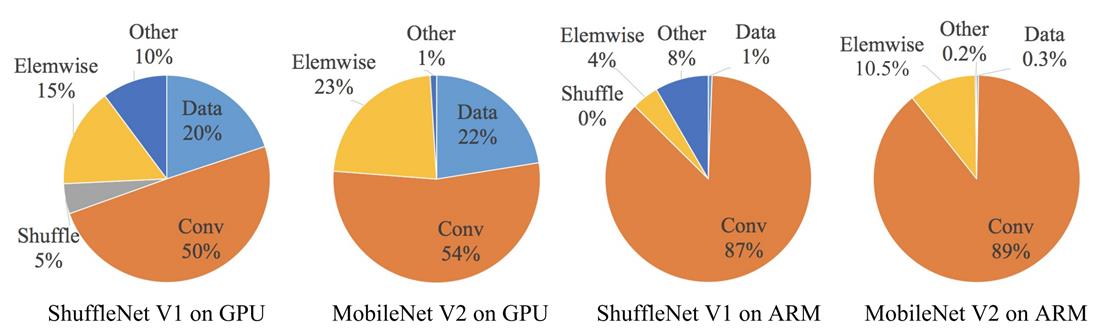
这是ShuffleNetV2论文里的一张图,网络的运行时间分解不同的组成部分。由图可以得出虽然卷积占用了大部分时间,但其他操作,包括数据I/O和Element-wise(AddTensor、ReLU等)也占用了大量时间。
因此,单单优化网络在执行卷积时所花费的时间有一定的效果,但仍然要关注运行时间的其它组成部分。
我们要关注网络的什么指标
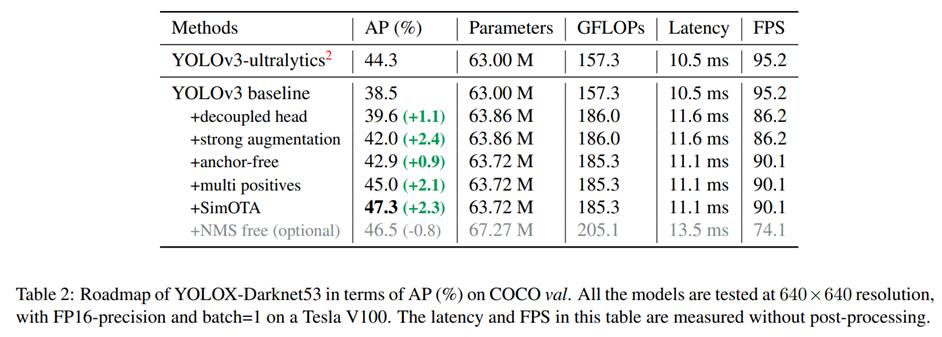
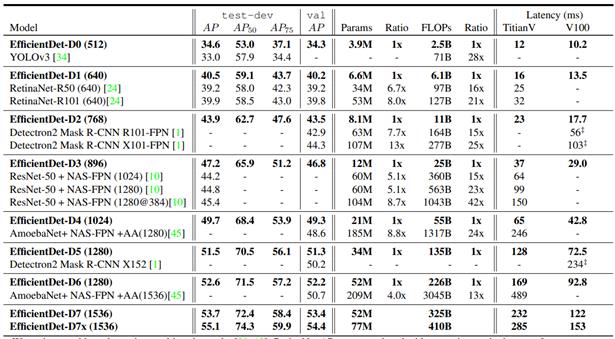
来看一下这幅图,这是YoloX中的消融实验图,它给出了五个指标,各位同学自己在写论文的时候,一般这么多指标就够了。毕竟YOLOX这样的SOTA论文才这么多指标。
该图里包含了几个指标:
| 指标 | 含义 |
|---|---|
| AP(%) | 这个代表了目标检测算法的检测精度。 |
| Parameters | 参数量,指模型含有多少参数。 |
| GFLOPs | FLOPs 是浮点运算次数,可以用来衡量算法/模型复杂度GFLOPs。为十亿(1e9)次的浮点运算。 |
| Latency | 网络前向传播的时间,1 ms=1e-3 s,10.5ms=0.0105s |
| FPS | 每秒传输帧数,FPS=1/Latency,1/0.0105=95.2 |
1、Parameters参数量
Parameters 参数量。参数量指的是模型所包含的参数的数量,比如我们模型中使用到的卷积、全连接里面的权值矩阵对应的每一个数字,都是参数量的组成。以YoloV3算法为例,其参数量为62,001,757。一般被缩写为62.00M。
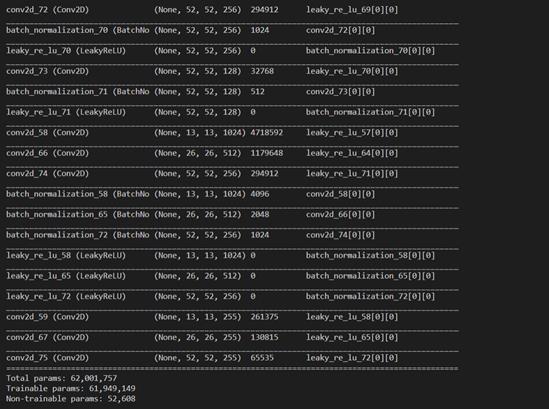
以YoloV3算法为例,其参数量为62,001,757。一般被缩写为62.00M。需要注意的是,模型的参数量并不等于存储空间大小,存储空间的单位是MB(或者KB)而不是M。
2、FLOPs 浮点运算次数
再来看一下FLOPs参数,需要注意的是FLOPS和FLOPs是不一样的。
FLOPS是处理器性能的衡量指标,是“每秒所执行的浮点运算次数”的缩写。
FLOPs是算法复杂度的衡量指标,是“浮点运算次数”的缩写,s代表的是复数。
在很多论文里面呢,FLOPs是用来衡量算法复杂度的指标,但算法复杂度往往不等同于算法的运算速度。Efficientdet就是非常典型的例子,FLOPs很小,但速度慢,占用显存大。
3、Latency 延迟
Latency指一般是网络预测一张图片所用的时间,按照上图YoloX所示,应该是不包括后处理(without post processing)的。也就是单单包含了网络前传部分的时间。
4、FPS 每秒传输帧数
FPS指的是每秒传输帧数。FPS=1/Latency。在求得上述的Latency 延迟后可以很容易的求出FPS,求个倒数即可。
指标间的关系
- Parameters低 ≈ FLOPs低。( FLOPs基本和Parameters成正关系,不过FLOPs还和输入进来的图片大小有关,输入图片越大,FLOPs 越大)
- FLOPs低 ≠ Latency低。( FLOPs低 ≠ FPS高,最典型的例子就是EfficientNet,EfficientNet使用了大量的低FLOPs、高数据读写量的操作,即深度可分离卷积操作。这些具有高数据读写量的操作,受到了GPU带宽的限制,算法浪费了大量时间在读写数据上,GPU算力也自然没有得到良好的应用)
- Parameters低 ≠ Latency低。( Parameters低 ≠ FPS高,同FLOPs,最典型的例子就是EfficientNet。)
网络的运算速度与什么有关?
网络的运算速度和各种各样的因素有关。主要有关于以下几点:
- 显卡:大多数SOTA算法用的都是V100或者A100。
- 网络结构:不是参数量越低速度越快,不是加两个深度可分离卷积,网络的速度就越快。有一个MAC的概念( Memory Access Cost ),在ShuffleNet V2的论文里提到了。深度可分离卷积便是一个高MAC,低参数量的操作。深度可分离卷积在CPU中表现更好。在一些特别高端的GPU上,深度可分离卷积甚至不如普通卷积。
- 网络的并行度:Inception是一个不断增加网络宽度的模型,它使用不同卷积核大小的卷积进行特征提取。但它的工作速度不是特别快。分多次就要算多次。
- 网络的层数:额外的操作如Relu,ADD都是没有参数量,但需要运算时间的操作。
- CUDA、CUDNN、深度学习算法框架版本影响:在1660ti显卡的机子上,YOLOX-S的FPS在torch1.7里为50多,在torch1.2里为20多。
以上是关于神经网络学习小记录72——Parameters参数量FLOPs浮点运算次数FPS每秒传输帧数等计算量衡量指标解析的主要内容,如果未能解决你的问题,请参考以下文章
神经网络学习小记录61——Tensorflow2 搭建常见分类网络平台(VGG16MobileNetResNet50)
java学习中,DVD管理系统纯代码(java 学习中的小记录)
Java 需要记得了解的关键词 (Java 学习中的小记录)
java学习中,成员内部类匿名内部类(java 学习中的小记录)