【数学之美笔记】自然语言处理部分(一).md
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了【数学之美笔记】自然语言处理部分(一).md相关的知识,希望对你有一定的参考价值。
参考技术A数字、文字和自然语言一样,都是信息的载体,他们的产生都是为了 记录和传播信息 。
但是貌似数学与语言学的关系不大,在很长一段时间内,数学主要用于天文学、力学。
本章,我们将回顾一下信息时代的发展,看语言学如何慢慢与数学联系起来的。
最开始的时候,人类会用 声音 来传播信息。
这里面的信息的产生、传播、接收、反馈,与现在最先进的通信在原理上没有任何差别。
因为早期人类需要传播的信息量不多,所以不需要语言文字。
但是当人类进步到一定的程度的时候,就需要语言了。
所以我们的祖先将语言描述的共同因素,比如物体、数量、动作便抽象出来,形成了今天的词汇。
随着人类的发展,语言和词汇多到一定的程度,大脑已经无法完全记住了。此时就需要一种 文字 ,将信息记录下来。
使用文字的好处在于,信息的传输可以跨越时间、空间了,两个人不需要在同一时间,同一地点碰面就可以进行信息的交流。
那么如何创造文字呢?最直接的方式就是模仿要描述对象的形状,这就是所谓的象形文字。
早期,象形文字的数量和记录一个文明的信息量是相关的,也就是说象形文字多,代表着这个文明的信息量大。
但是随着信息量的增加,没有人能学会和记住这么多的文字,这样就需要进行 概括和归类 了。也就是使用一个词来表达相同和相似的一类意思。
比如说“日”本来是说太阳,但是它又同时可以是我们讲的一天。
这种概念的聚类,和现在自然语言处理或者机器学习的 聚类 很相似,只是在远古,可能需要上千年,而现在只需要几小时。
但是文字按照意思来聚类,总会有 歧义性 ,也就是弄不清楚一个 多义字 在特定环境下表示其中哪一个含义。
要解决这个问题,都是 依靠上下文 ,大多数Disambiguation可以做到,但总有个别做不到的时候。 对上下文建立的概率模型再好,也会有失灵的时候。
不同的文明因为地域的原因,文字和语言一般来说是不同的,当两个文明碰在一起的时候,翻译的需求就有了。
翻译能达成的原因:不同的文字系统在记录信息的能力上是等价的 ,文字只是信息的载体,而不是信息的本身,甚至可以用数字进行搭载。
今天,我们对埃及的了解比玛雅文明多,要归功于埃及人通过文字记录了生活中最重要的信息,对我们的指导意义在于:
文字是在头脑里面已经装不下信息的时候才出现,而数字则是在财产需要数一数才能搞清楚的时候才产生。
早期的数字没有书写的形式 ,只是说掰指头,这也是我们使用 十进制 的原因。
渐渐地,祖先发现十个指头也不够用了,最简单的方法是把脚趾头也算上,但是不能解决根本问题。于是他们发明了 进位制 ,也就是逢十进一。
那为什么现有的文明多用十进制,而不是二十进制呢?
相比十进制,20进制多有不便,比如说十进制只需要背诵九九乘法表,如果是20进制的话,就需要背19*19的围棋盘了。
对于不同位数的数字表示,中国人和罗马人都用明确的单位来表示不同的量级。
中国人是用十百千万亿兆,罗马人用I表示个,V表示5等等。
这两种表示法都不自觉的引入了朴素的编码的概念。
描述数字最有效的是古印度人,他们发明了10个阿拉伯数字,比中国和罗马的都抽象,这也标志着数字和文字的分离。客观上让自然语言与数学在几千年没有重复的轨迹。
从象形文字到拼音文字是一个飞跃,因为人类在描述物体的方式上,从物体的外表到抽象的概念,同时不自觉的采用了对信息的编码。
不仅如此,在罗马体系的文字中,常用字短,生僻字长,在意型文字中,也是一样,常用字笔画少,而生僻字笔画多,这符合信息论中的 最短编码原理。
罗马语言体系:
在纸发明之前,书写文字并不容易。所以需要惜墨如金,所以古文这种书面文字非常简洁,但是非常难懂。而口语却与现在差别不大。这就和现在的信息科学的一些原理类似
这点就是现在的互联网与移动互联网的网页设计完全一致。
使用宽带的话,页面得设计得比较大,而手机终端上的由于受空中频道带宽的限制,传输速度慢,分辨率低。
《圣经》记录了创世纪以来,犹太人祖先的故事,《圣经》的写作持续了很多世纪,有若干人来完成,抄写的错误在所难免,
为了避免抄错,犹太人发明了一种类似 校验码 的方法,他们把希伯来字母对应于一个数字,每行加起来就是一个特殊的数字,这个数字即为 校验码 。
当抄完一页以后,需要把每一行的文字加起来,看看校验码与原文是否相同。
从字母到词的构词法是词的编码规则,那么语法则是语言的编码和解码规则。
相比较而言, 词是有限且封闭的集合, 语言则是无限和开放的集合。 从数学上来讲,前者有完备的编解码规则,而语言则没有,也就是说语言有语法规则覆盖不到的地方,这就是“病句”
那么到底是语言对,还是语法对呢?有人坚持从真实的语料中出发,有人坚持从规则出发。
本章讲述了文字、数字、语言的历史,帮助读者感受语言和数学内在的联系。提到了如下的概念
上一章我们说到,语言出现的目的就是为了人类的通信,而字母、文字、数字实际上是 信息编码 的不同单位。
任何一种语言都是一种编码方式,而语言的语法规则是编解码的算法。比如,我们把想要表达的东西通过语言组织起来,这就是进行了一次编码,如果对方能懂这个语言,它就可以使用这门语言的解码方式进行解码。
那么机器是否可以读懂自然语言呢?当然可以
自然语言处理发展过程可以分为两个阶段:
50年代,学术界对人工智能和自然语言理解的认识是这样的:要让机器完成语音识别,必须让计算机理解自然语言。因为人类就这么做的。这种方法论就称为“鸟飞派”,也就是看鸟怎么飞的来造出飞机。事实上,人们发明飞机靠的是空气动力学,而不是仿生学。
那么如何才能理解自然语言呢?
一般需要:
我们可以看一个简单的句子
这个句子可以分为主、谓、句号三部分,可以对每个部分进一步分析,得到如下的语法分析树(Parse Tree)
分析它采用的文法规则称为 重写规则
但是这种方法很快遇到了麻烦。从上图可以看出 一个短短的句子居然分析出这么一个复杂的二维树结构 ,如果要处理一个真实的句子就非常的麻烦了。
主要有两个坎儿:
那么其实从语法这条路来分析句子,并不靠谱。
上面我们讲到了基于规则的句法分析对于语义处理比较麻烦,因为 自然语言中的词的多义性难用规则来描述,而是依赖于 上下文 。
比如 “The box is in the pen.” 因为这里pen是围栏的意思。整句话翻译成中文就是“ 盒子在围栏里” 。这 里 面 pen是指钢笔还是围栏 ,通过上下文已经不能解决,需要常识
1970年以后统计语言学让自然语言处理重获新生,里面的关键任务是贾里尼和他领导的IBM华生实验室。最开始的时候,他们使用统计的方法,将当时的语音识别率从70%提升到90%,同时语音识别规模从几百单词上升到几万单词
基于统计的自然语言处理方法,在数学模型与通信是相通的,因此在数学意义上,自然语言处理又和语言的初衷—— 通信 联系在一起了。
前面的章节,我们一直强调,自然语言从产生开始,逐渐演变成一种上下文相关的信息表达和传递方式。
所以要让机器能处理自然语音, 关键在于 为自然语音这种 上下文相关的 特性建立数学模型,这就是 统计语言模型(Statistical Language Model)
这个模型广泛应用于机器翻译、语音识别、印刷体识别、拼写纠错、汉字输入、文献查询
语音识别需要解决的一个重要的问题就是计算机给出来的一个文字序列,是否能被人类所理解。70年代以前,人们使用语义分析来解决。
而贾里克从另一个角度来看待这个问题,一个简单的统计模型就搞定了。
也就是说要看一个句子是否合理,就看看它的 可能性 大小如何 。
比如说一个通顺的语句出现的概率为$10 -20$,而一个乱七八糟的语句出现的概率为$10 -70$,所以通顺的语句更有可能。
假定$S$表示一个有意义的句子,由一串特定顺序的词$\\omega _1,\\omega _2, \\cdots ,\\omega _n$组成,这里$n$是句子的长度。现在需要知道这个句子出现的概率
$$P\\left( S \\right) = P\\left( w_1,w_2, \\cdots ,w_n \\right)$$
利用条件概率的公式,$S$这个序列出现的概率等于每个词出现概率相乘
$$P\\left( w_1,w_2, \\cdots ,w_n \\right) = P\\left( w_1 \\right)P\\left( w_2|w_1 \\right) \\cdots P\\left( w_n|w_1,w_2, \\cdots ,w_n - 1 \\right)$$
问题就来了,这种条件概率怎么计算呢?
20世纪初,俄国的数学家马尔科夫给出了一个有效的方法,当遇到这种情况的时候,假设任意一个词$w_i$出现的概率只与前面的词$w_i-1$有关,与其他词无关,这就叫 马尔科夫假设
所以公式又变成了
$$P\\left( w_1,w_2, \\cdots ,w_n \\right) = P\\left( w_1 \\right)P\\left( w_2|w_1 \\right) \\cdots P\\left( w_n|w_n - 1 \\right)$$
这就叫 二元模型(Bigram Model)
如果假设一个词由前面$N-1$个词决定,对应的模型就叫$N
$元模型,会更复杂。
同样那么如何估算条件概率$P\\left( w_i|w_i - 1 \\right)$,可以先看一下它的定义
$$P\\left( w_i|w_i - 1 \\right) = \\fracP\\left( w_i - 1,w_i \\right)P\\left( w_i - 1 \\right)$$
需要做的是估计
那么这两种概率如何得到?
有了大量的语料库(Corpus)以后,只要数一下$w_i - 1,w_i$在统计的文本前后相邻出现了多少次$# \\left( w_i - 1,w_i \\right)$即可。然后除以语料库的大小#,这样就可以使用 频度 来估计概率了。
根据 大数定理 ,只要统计量足够,相对频度就等于概率。
$$P\\left( w_i|w_i - 1 \\right) = \\frac# \\left( w_i - 1,w_i \\right)# \\left( w_i - 1 \\right)$$
居然用这么复杂的模型就可以解决复杂的语音识别、机器翻译的问题。
二元模型最大的特点在于,每个词只与前面一个词有关,太简化了,更普遍的是某个词与前面若干词都有关。
所以$N$元模型指的就是当前词$w_i$只取决于前$N-1$个词,这就是 N-1阶马尔科夫假设
实际中,三元模型用得多更多,所以$N=3$,而更高阶的就比较少用了,因为
使用语言模型需要知道模型中所有的 条件概率 ,我们称之为 模型的参数 。
通过对语料的统计,得到这些参数的过程称作 模型的训练 。
之前我们讲过,只需要统计出相邻两个字符同时出现的次数以及$w_i - 1$单独出现的次数,然后计算一下比值即可。
但是有一种情况我们没有考虑,如果相邻两个词并没有同时出现过,也就是$# \\left( w_i - 1,w_i \\right) = 0$怎么办,是否就说明概率为0。
当然不是,这就涉及到统计的 可靠性 了。
在数理统计中,我们之所以敢用采用数据来预测概率,是因为 大数定理 ,它的要求是有足够的观测值。也就是如果样本太小,则使用次数来预测概率当然不靠谱。
那么如何正确的训练一个语言模型呢?
下面以统计词典中每个词的概率来具体讲讲。
假定在语料库中出现$r$次的词有$N_r$个,$N$表示语料库的大小。
$$N = \\sum\\limits_r = 1^\\infty rN_r $$
也就是说每个词出现的$r$词的词的个数与出现了多少次相乘。
当$r$比较小,说明出现的次数不够多,那么在计算它们的概率的时候要使用一个更小一点的次数,比如$d_r$
$$d_r = \\left( r + 1 \\right)\\fracN_r + 1N_r$$
而且
$$\\sum\\limits_r d_rN_r = N$$
一般来说, 出现1次的词的数量比出现两次的多,同样出现两次比出现三次的多。
也就是出现的次数$r$越大,词的数量$N_r$越小,所以$N_r + 1 < N_r$,可以看出$d_r < r$,这样估算是因为$d_r$是我们要找的那个比$r$更小的数,而当只出现0次的时候$d_0>0$
这样,
对于二元模型,
其中
这种平滑的方法最早是由IBM的卡茨提出来的,所以称为 卡茨退避法
还有一种方法是 删除差值 法,也就是用低阶模型和高阶模型进行线性插值的方法来平滑处理,但是因为效果差于卡茨退避发,所以很少使用了。
模型训练中另一个重要问题是 训练数据 ,或者说是语料库的选取,如果训练预料和模型应用的领域相脱节,模型的效果也要大打折扣。
比如对于建立一个语言模型,如果应用是网页搜索,它的训练数据就应该是 杂乱的网页数据 和用户输入的搜索串,而不是传统的、规范的新闻稿 ,即使前者夹杂着噪音和错误。因为训练数据和应用一致,搜索质量反而更好。
训练数据通常是越多越好,高阶模型因为参数多,需要的训练数据也相应会多很多,遗憾的是,并非所有的应用都能有足够的训练数据,比如机器翻译的双语语料,这个时候,追求高阶的大模型没有任何意义。
如果训练数据和应用数据一致了,而且训练量足够大了以后,训练预料的噪音高低也会对模型产生影响。所以训练之前需要进行预处理,对于可以找到规律的而且还比较多的噪音需要进行处理,比如制表符
对于西方拼音来说,词之间有明确的分界符(Delimit)。但是对于中文来讲,词之间没有明确的分界符。所以需要先对句子进行分词。
最容易想到的方法就是 查字典 也就是说,从左到右扫描一遍,遇到字典里面有的词就标识出。
但是这种方法遇到复杂的问题就不行了。比如说遇到 二义性 的分割时。像“发展中国家”,正确的分割是“发展-中-国家”,而从左向右查字典会分割为“发展-中国-家”
同样我们可以使用 统计语言模型 来解决分词二义性的问题。
假定一个句子$S$有几种分词方法:
$$\\beginarrayl
A_1,A_2,A_3, \\cdots ,A_k\\
B_1,B_2,B_3, \\cdots ,B_m\\
C_1,C_2,C_3, \\cdots ,C_n
\\endarray$$
最好的分词方法 就是分完词以后,这个句子出现的概率最大。
当然如果穷举所有的分词方法,并计算每种可能性下的句子的概率,那么计算量是相当大的。
可以看作是一个 动态规划(Dynamic Programming) 问题,并利用 维特比(Viterbi)算法 快速的找到最佳分词
语言学家对词语的定义不完全相同,比如说“北京大学”,有人认为是一个词,有人认为是两个词。折中的方法就是先当做一个四字词,然后再进一步找到细分词“北京”和“大学”
人工分词产生不一致性的主要原因在于人们对词的 颗粒度 的认识问题。
比如说“清华大学”,有人认为是一个整体,有人认为“清华”是修饰“大学”的。这里不需要去强调谁的观点正确,而是应该知道,在不同的应用里面,会有一种颗粒度比另一种更好的情况。
比如说在机器翻译中,颗粒度大翻译效果好,比如“联想公司”如果拆分为开,很难翻译为“Lenovo”。但是在网页搜索里面,小的颗粒度会比大的要好,比如用户查询“清华”而不是“清华大学”一样可以查询到清华大学的主页。
如果为不同的应用构建不同的分词器,太过浪费。可 以让一个分词器同时支持不同层次的词的切分。
也就是说先把句子按照基本词进行分割,再把基本词串按照复合词模型再分割。
《数学之美》——第二章 个人笔记
第二章 自然语言处理——从规则到统计
这一章开头这句话:字母,文字,数字是信息编码的不同单位。任何一种语言都是一种编码的方式,而语言的语法规则是编解码的算法。我们表达一个意思要通过语言表达出来,就是用这种语言的编码方式表示出来,结果就输出一串文字。别人懂这门语言的编码方式,就会理解。这里说的输出一串文字,可以是字母,数字(计算机理解),和开头说的信息编码的不同单位是符合的,就很好理解了。这就是语言的数学本质。
?①计算机能处理自然语言
?②它处理自然语言的方法和人类一样
1 机器智能
有意思的词:‘鸟飞派’:看看鸟是怎么飞的,就能模仿鸟造出飞机,而不需要了解空气动力学。
下图是前人对自然语言处理的想法(走的弯路)
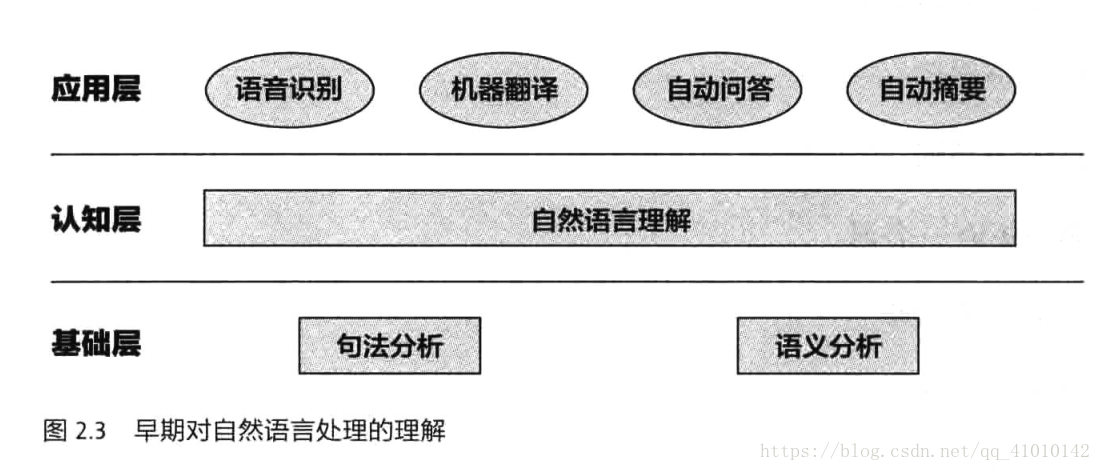
单纯基于文法规则的分析器是处理不了复杂的语句的,里面有两个不可逾越的坎儿:
①文法规则的数量太庞大,无法构建;写到后面还会出现矛盾
②描述自然语言的文法和计算机高级程序语言的文法是不同的,计算机难以解析。作者在这里提到了自然语言在演变过程中产生了词义和上下文相关的特性;对于上下文无关文法,算法的复杂度是语句长度的二次方,而对于有关文法,则是六次方。
2 从规则到统计
有趣的例子:The pan is in the box ,The box is in the pen 。这个栗子说明了语义的难处理。再有统计语言学的出现,不久后NLP从规则到统计。
PS:文中有一段讲斯伯格特对未来研究方向的判断,总让我觉得大牛都是开挂的。还有传统捍卫者的武器就是基于统计的方法只能处理浅层的NLP问题。
3 小结
基于统计的NLP方法,在数学模型上和通信是相通的,甚至就是相同的。因此,在数学意义上NLP又和语言的初衷——通信联系在一起了。(这里基于统计的方法是让计算机能够处理NL)
以上是关于【数学之美笔记】自然语言处理部分(一).md的主要内容,如果未能解决你的问题,请参考以下文章