对比Java学Kotlin协程-异步流
Posted 陈蒙_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对比Java学Kotlin协程-异步流相关的知识,希望对你有一定的参考价值。
文章目录
异步流定义
我们知道有 RxJava、RxSwift、RxJs,那有 RxKotlin 吗?答案是没有。因为不需要,Kotlin 内置了 「RxKotlin」,天生拥有响应式编程能力,这就是 Kotlin 异步流。
类比 RxJava = 响应式编程+线程,有 Kotlin 异步流 = RxKotlin + 协程。
RxJava 支持切换线程,而Kotlin异步流切换的是协程。
既然是“异步”流,那有“同步”流吗?有的,Kotlin 中的同步流就是 Sequence。
跟 RxJava、Project Reactor 一样,Kotlin Flow 也是响应式编程规范(Reactive Streams Specification)的一种实现。
通过 launch()、async() 这些创建协程的方法可以获取单个异步执行的实例。那如果我们想同时获取多个呢?或者说获取一组异步执行的实例呢?这个时候异步流就派上用场了。
响应式编程与异步流
什么是响应式编程?
抛开具体编程语言,我们看一个赋值语句,涉及 a、b、c 三个变量:
var a = 1
var b = a + 1
a = 2
print(a, b)
试问,a 的值发生改变之后,b 的值会跟着变吗?根据我们的经验,一般 b 是不会变的。其实我们可以设计一门编程语言,让 b 跟着 a 变,这时这个编程语言就是天然支持响应式编程的。
从这个例子我们可以看出,响应式编程的精髓是「响应」,即一方随时「响应」另一方,二者之间可能是依赖关系。
这种响应关系就像水流(flow 或 stream)的上游和下游一样,上游发生变化,下游跟着变化。
操作符
异步流的操作符可以按不同的标准进行分类,比如按出现位置可以分为开头型、中间型和结尾型,比如构建异步流的操作符一般出现在流的开头,而启动型的操作符出现在流的结尾,其他的如转换型的操作符出现在流的中间位置。
构建型
Kotlin 提供了 flow()、flowOf()、asFlow() 构造异步流。后面两个方法本质上还是借助 flow() 完成的。Koltin 异步流中最基本的方法是 flow()、collect() 和 emit()。其中 emit() 方法类似 RxJava 种的 onNext(),每个操作符处理完上游传递给自己的数据然后发射/emit出去,就完成了向下游的传递。
- flow(),接收一个 FlowCollector emit() 类型的 lambda 表达式,返回一个 Flow collect() 的 lambda 表达式;
- collect(),相当于下游水龙头,调用 collect() 时触发上游开始执行;
- emit(),上游产生数据传递给下游;
使用这几个方法,我们就可构造简单的异步流了,举个例子:
fun main() = runBlocking
launch
for (i in 1..4)
println("i am not blocked $i")
delay(100)
simpleFlow().collect value ->
println(value)
fun simpleFlow(): Flow<Int> = flow
for (i in 1..4)
delay(1000)
emit(i)
上述代码输出结果为:
i am not blocked 1
i am not blocked 2
i am not blocked 3
i am not blocked 4
1
2
3
4
需要注意以下几点:
- simpleFlow() 方法没有 suspend 修饰,因为该方法本身并非一个耗时方法,而是直接返回的同步方法;
- 通过 emit() 方法发射数据到下游,作用跟普通方法中的 return 和 Sequence 中的 yield() 类似;
- 只有在调用 collect() 方法时数据流才会启动运行,而且每次调用都会从头执行一遍,否则其前面的其他操作符方法不会执行;
- collect() 方法是 suspend 的,必须在另一个 suspend 方法中被调用;
- 数据流可以看做是一组值,每个值的执行也就是流经操作符的顺序是串行的;
关于最后一点,我们看个例子:
fun main() = runBlocking
(1..5).asFlow().filter
println("filtering $it")
it % 2 == 0
.map
println("mapping $it")
"string $it"
.collect
println("collected $it")
结果输出为:
filtering 1
filtering 2
mapping 2
collected string 2
filtering 3
filtering 4
mapping 4
collected string 4
filtering 5
从结果可以看出,每个值都依次经过了 filter()、map() 和 collect()。奇数经过 filter() 时返回 false,就会被被拦下从而没有触发 emit() 方法往下一个操作符发射数据,filter() 和 map() 方法本质上是 inline 方法,最后都会被转换成 transform() 方法,当 filter 条件命中返回 true 时才会调用 emit() 方法,map() 则是无脑调用 emit()。
emit() 方法可以被调用多次:
fun main() = runBlocking
(1..4).asFlow()
.transform request ->
emit("making req $request")
emit(performReq(request))
.collect response -> println(response)
suspend fun performReq(req: Int): String
delay(1000)
return "response $req"
上述代码输出:
making req 1
response 1
making req 2
response 2
making req 3
response 3
making req 4
response 4
上下文型
flowOn()
异步流的上下文是指,异步流执行在哪个协程。我们可以粗略的将异步流分为上游和下游两部分,那么上下文要关注的是上游和下游分别运行在哪个协程中。
最常见的场景是,上游是数据生产者,是耗时操作,比如网络请求等,而下游是消费者,比如在主线程中更新UI等。
下游代码,即 collect() 对应的代码,如果没有特殊指定,默认运行在调用该方法的协程中。
我们可以使用 flowOn() 来改变上游代码运行所在的协程,一般是在构造协程的时候。
fun /*context_*/main() = runBlocking
simple().flowOn(Dispatchers.Default).collect value -> log("Collected $value")
fun simple() = flow
for (i in 1..3)
delay(100)
log("Emitting $i")
emit(i)
fun log(msg: String) = println("[$Thread.currentThread().name] $msg")
协作型
Flow的上游好比是泵,下游好比是水龙头。上游抽水的速度和水龙头放水的速度可能不一致,如果想让二者协同合作以达到最高效率或实现某种效果,就需要使用协作型操作符了。
buffer
一般情况下,只有下游完成处理后才会告诉上游继续发射下一个数据。但是如果上游的发射速度高于下游,是否可以不让上游等待呢?这时我们可以使用 buffer(),让上游实现并发。
可以简单的认为,有了buffer之后上游就放飞自我了,发射时机不再受下游限制了,反正提前发射的值可以被缓存(buffer)。
比如上游发射一个数据需要100ms,下游处理一个数据需要200ms:
import kotlinx.coroutines.delay
import kotlinx.coroutines.flow.buffer
import kotlinx.coroutines.flow.cancellable
import kotlinx.coroutines.flow.collect
import kotlinx.coroutines.flow.flow
import kotlinx.coroutines.runBlocking
import kotlin.time.ExperimentalTime
import kotlin.time.measureTime
@OptIn(ExperimentalTime::class)
fun main(): Unit = runBlocking
val elapse = measureTime
simpleFlow()/*.buffer()*/.collect
println("consuming $it")
delay(200)
println("consuming done")
println("all done")
println("elapse: $elapse")
fun simpleFlow() = flow
for (i in 1..3)
println("producing $i")
delay(100)
emit(i)
println("producing done")
使用buffer前后的耗时情况如下图:
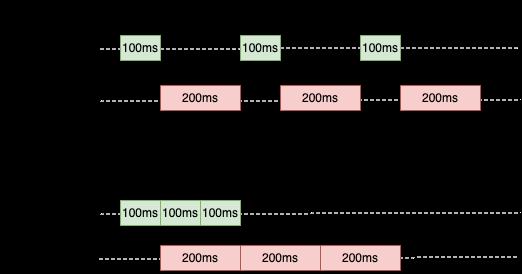
所以未使用buffer时耗时900ms左右,使用buffer之后耗时在700ms左右。
conflate
在上游发射速度快于下游处理速度时,conflate() 可以让我们丢弃中间值,而仅仅处理最新的值。被丢弃的前提是下游还没来得及处理,如果已经开始处理了,则不会被丢弃。当下游的处理耗时是300ms时中间值会被丢弃,而150ms时则会被正常处理:
import kotlinx.coroutines.delay
import kotlinx.coroutines.flow.*
import kotlinx.coroutines.runBlocking
import kotlin.time.ExperimentalTime
import kotlin.time.measureTime
@OptIn(ExperimentalTime::class)
fun main(): Unit = runBlocking
var delay = 150L // 300L
val elapse = measureTime
simpleFlow()/*.buffer()*/.conflate().collect
println("consuming $it")
delay(delay)
println("consuming $it done")
println("all done")
println("elapse: $elapse")
fun simpleFlow() = flow
for (i in 1..3)
println("producing $i")
delay(100)
emit(i)
println("producing $i done")
150 的输出:
producing 1
producing 1 done
producing 2
consuming 1
producing 2 done
producing 3
consuming 1 done
consuming 2
producing 3 done
consuming 2 done
consuming 3
consuming 3 done
all done
elapse: 616.934055ms
Process finished with exit code 0
300的输出:
producing 1
producing 1 done
producing 2
consuming 1
producing 2 done
producing 3
producing 3 done
consuming 1 done
consuming 3
consuming 3 done
all done
elapse: 767.395294ms
如果上游和下游速度都慢,我们可以使用 conflate 来提升处理速度,本质上是丢弃中间值。另一种方式是每当上游发射一个值时,下游都取消当前正在处理的任务,重新启动一个新任务处理最新值,这类操作符统称为 xxLatest。
import kotlinx.coroutines.delay
import kotlinx.coroutines.flow.*
import kotlinx.coroutines.runBlocking
import kotlin.time.ExperimentalTime
import kotlin.time.measureTime
@OptIn(ExperimentalTime::class)
fun main(): Unit = runBlocking
var delay = 150L
val elapse = measureTime
simpleFlow()/*.buffer().conflate()*/.collectLatest
println("consuming $it")
delay(delay)
println("consuming $it done")
println("all done")
println("elapse: $elapse")
fun simpleFlow() = flow
for (i in 1..3)
println("producing $i")
delay(100)
emit(i)
println("producing $i done")
从输出可以看出,虽然下游处理任务启动了,但是还没有完成的时候就被取消了(没有 consuming 2 done):
producing 1
consuming 1
producing 1 done
producing 2
consuming 2
producing 2 done
producing 3
consuming 3
producing 3 done
consuming 3 done
all done
elapse: 509.858319ms
转换型
- transform
- map
- filter
- take
- reduce
我们可以对流做一些转换操作,把发射出来的值转换成其他类型或值。比如最基本的 map()、filter() 操作符,这些操作符支持 suspend 方法,里面可以是耗时操作:
fun /*transformation_*/main() = runBlocking
(1..3).asFlow().map request -> performRequest(request)
.collect response -> println(response)
suspend fun performRequest(request: Int): String
delay(1000)
return "response $request"
输出为:
(delay 1 sec)
response 1
(delay 1 sec)
response 2
(delay 1 sec)
response 3
map()、filter()、transform() 都是 Flow 的扩展方法,map()和filter()本质上是调用 transform() 实现的,transform() 自己又构造了一个 flow:
public inline fun <T, R> Flow<T>.transform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = flow // Note: safe flow is used here, because collector is exposed to transform on each operation
collect value ->
// kludge, without it Unit will be returned and TCE won't kick in, KT-28938
return@collect transform(value)
数量型
我们可以使用 take() 操作符只取前几个发射的值,后续的值将会被cancel掉,同时抛出异常:
fun /*sizeLimiting_*/main() = runBlocking
numbers()
.take(2)
.collect value -> println(value)
fun numbers() = flow
try
emit(1)
emit(2)
println("this line will not be executed")
emit(3)
catch (e: Throwable)
println(e.message)
finally
println("finally in numbers")
输出:
1
2
Flow was aborted, no more elements needed
finally in numbers
启动型
collect() 也是一个操作符。除了 collect(),还有哪些操作符能启动一个异步流吗?有的,大概有如下几类:
- 转成集合,比如 toList、toSet;
- 获取第一个发射值以及保证只有一个发射值(无发射值或多于一个则会抛异常)的操作符,如 first()和single();
在这里插入代码片 - 将所有发射值缩减至一个值的操作符,如 reduce()、fold();
- 新启协程运行异步流,比如 launchIn();
这些操作符有如下特点:
- 只能出现在异步流的最后,不能与 collect() 同时出现;
- 都是 suspend 方法;
fun /*trigger_*/main() = runBlocking
val res = (1..5).asFlow()
.map it * it
// .single()
// .first()
.reduce a, b -> a + b
// .fold(1) acc: Int, value: Int -> acc + value
println(res)
输出:55
launchIn() 操作符比较特殊,使用它可以另外启动一个协程用于运行当前异步流。一般 collect() 方法启动的异步流会直接使用当前协程运行,但是就导致 collect() 方法后面的代码需要等待,等待异步流执行完成后才能开始执行。如果我们希望 collect() 方法立即执行,那么可以使用 launchIn()。比如使用 collect() 方法启动异步流时:
fun /*launch_*/main() = runBlocking
(1..3).asFlow().onEach delay(100) .onEach value -> println(value) /*.launchIn(this)*/.collect()
println("DONE")
输出为:
1
2
3
DONE
显然异步流后面的代码是等待异步流执行完成之后才执行的。如果我们使用 launchIn():
fun /*launch_*/main() = runBlocking
(1..3).asFlow().onEach delay(100) .onEach value -> println(value) .launchIn(this)/*.collect()*/
println("DONE")
输出为:
DONE
1
2
3
launchIn() 会另外开启一个新的协程运行异步流的代码,与 printlin("DONE")是同时运行。其效果相当于:
fun /*launch_*/main() = runBlocking
launch (1..3).asFlow().onEach delay(100) .onEach value -> println(value) .collect()
println("DONE")
组合型
- zip
- combine
- flatten
zip() 可以把两个flow组合起来:
import kotlinx.coroutines.flow.asFlow
import kotlinx.coroutines.flow.collect
import kotlinx.coroutines.flow.flowOf
import kotlinx.coroutines.flow.zip
import kotlinx.coroutines.runBlocking
fun /*compose_*/main() = runBlocking
val keys = flowOf("one", "two", "three", "four").onEach delay(300)
val values = (1..3).asFlow().onEach delay(400)
keys.zip(values) a, b -> "$a -> $b" .collect println(it)
输出:
one -> 1
two -> 2
three -> 3
执行流程示意图:

combine()
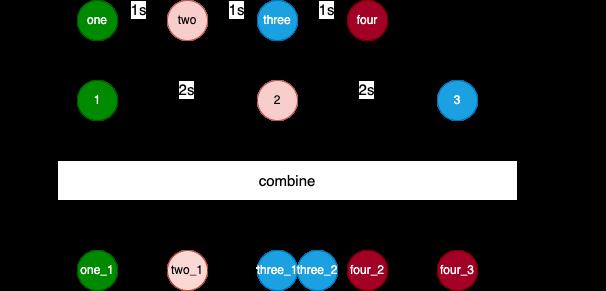
combine 的作用是,每当其中一个流有最新值时,该最新值都会与其他流的最新值重新执行一遍处理流程。
fun /*compose_*/main() = runBlocking
val keys = flowOf("one", "two", "three", "four").onEach delay(1000)
val values = (1..3).asFlow().onEach delay(2000)
keys/*.zip*/.combine(values) a, b -> "$a -> $b" .collect value -> println("$value")
每隔2000ms输出一行:
one -> 1
two -> 1
three -> 1
three -> 2
four -> 2
four -> 3
执行流程为:
flatten
在实际开发中,有一种场景是一个flow发射的每一个值会使用map()操作符产生一个新的flow,于是就有了一个流组成的流(a flow of flows):
fun /*flatten_*/main() = runBlocking
(1..3).asFlow()以上是关于对比Java学Kotlin协程-异步流的主要内容,如果未能解决你的问题,请参考以下文章