scrapy爬下来的数据是乱序的,如何排序?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy爬下来的数据是乱序的,如何排序?相关的知识,希望对你有一定的参考价值。
爬下来第一行,第二行,第三行的数据,导出时候有时是213,有时是132这样导出,如何才能调整为123顺序导出?
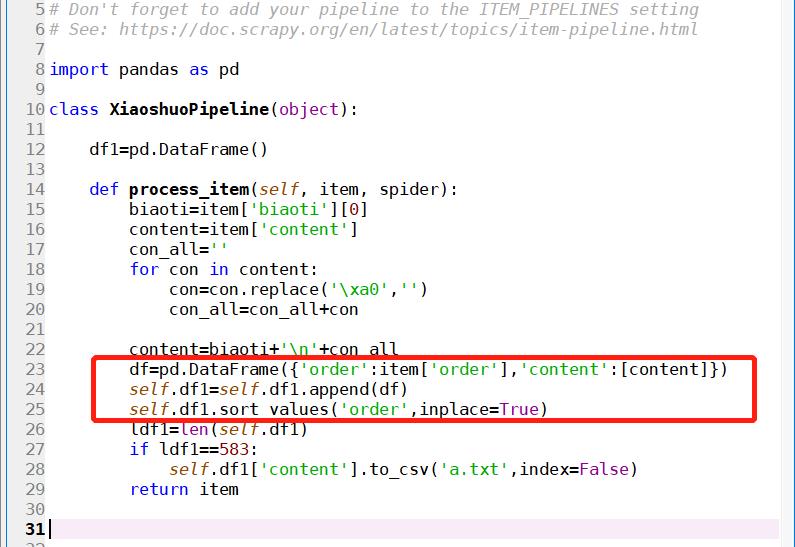
感谢各位。我爬的小说,我想的是排序之后再保存。新手,代码有点简陋,凑合看哈。我开始理解的是爬完一条,返回一条,爬完的和后续的不会存在一起。不过,用df保存看来,都存在一起了,排序之后正常。
快速排序
首先普及一下关于初赛的一些知识吧。
希望能用到。
快速排序具有最好的平均性能,但最坏性能就成了O(n^2)。
比如一个序列5,4,3,2,1,要排为1,2,3,4,5。按照快速排序方法,每次只会有一个数据进入正确顺序,不能把数据分成大小相当的两份,很明显,排序的过程就成了一棵树树的深度为n,那时间复杂度就成了O(n^2)。
尽管如此,需要排序的情况几乎都是乱序的,自然性能就保证了。通过查资料来看,在数据量小于20的时候,插入排序具有最好的性能。当大于20时,快速排序具有最好的性能,归并排序和堆排序也不如快速排序,尽管复杂度都为nlog2(n)。
1.算法思想
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法。
(1) 分治法的基本思想
分治法的基本思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。
(2)快速排序的基本思想
设当前待排序的无序区为s[left..right],利用分治法可将快速排序的基本思想描述为:
①分解: 说简单点就是分治,不断分成两部分,进行递归排序。
注意:
划分的关键是要求出基准记录所在的位置。划分的结果可以简单地表示为(注:最后不要忘了把基准放回去):
②求解:
通过递归调用快速排序对左、右子区间s[left...mid - 1]和s[mid + 1...right]快速排序。
然后让我们看一下板子:
void quicksort(int left,int right){ int temp; if(left > right) return ; temp = s[left]; int i = left , j = right ; int t; while(i != j){ while(s[j] >= temp && i < j) j--;//找到第一个比基准元素小的元素 while(s[i] <= temp && i < j) i++;//找到第一个大的 if(i < j){ //交换 t = s[i]; s[i] = s[j]; s[j] = t; } } //将基准数放回数组(有人叫归位) s[left] = s[i]; s[i] = temp; quicksort(left , i - 1);//处理左边的 quicksort(i + 1 , right);//处理右边的 //递归不用说吧 }
以上是关于scrapy爬下来的数据是乱序的,如何排序?的主要内容,如果未能解决你的问题,请参考以下文章