NLP实践用预训练的词向量处理词的相似性和类比任务
Posted nefu-ljw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP实践用预训练的词向量处理词的相似性和类比任务相关的知识,希望对你有一定的参考价值。
文章目录
原理
具体原理请参考:《动手学深度学习》14. 自然语言处理:预训练 -> 14.7. 词的相似性和类比任务
环境配置
本文运行环境:win10,python3.8,pytorch1.11.0。
使用pycharm和Anaconda,可以在pycharm中新建一个项目,选项“python解释器”选择用Anaconda创建一个python3.8的环境。然后安装:
pip install torch==1.11.0
pip install torchvision==0.12.0
pip install d2l==0.17.5
准备数据集
请事先下载数据集,https://nlp.stanford.edu/projects/glove 下载glove.6B.zip文件并解压。
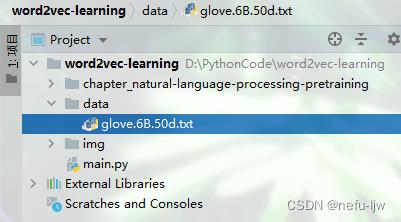
本文使用数据集为glove.6B.50d.txt,其必须保存到项目路径的./data子目录下,如下图:
代码
以下是跑通glove.6B.50d.txt数据集的python代码(对于书中的原代码有改动,并加上了自己对代码逻辑理解的注释)。
import os
import torch
from d2l import torch as d2l
# @save
class TokenEmbedding:
"""
为了加载GloVe模型预训练好的词向量数据集,我们定义了以下TokenEmbedding类
"""
def __init__(self, embedding_name):
self.idx_to_token, self.idx_to_vec = self._load_embedding(embedding_name)
self.unknown_idx = 0
self.token_to_idx = token: idx for idx, token in enumerate(self.idx_to_token)
def _load_embedding(self, embedding_name):
idx_to_token, idx_to_vec = ['<unk>'], []
# data_dir = d2l.download_extract(embedding_name) # 原代码的网址失效,请手动下载
data_dir = "./data"
# GloVe⽹站:https://nlp.stanford.edu/projects/glove/
with open(os.path.join(data_dir, embedding_name), 'r', encoding='UTF-8') as f:
for line in f:
# rstrip() 删除 string 字符串末尾的指定字符,默认为空白符,包括空格、换行符、回车符、制表符
elems = line.rstrip().split(' ')
# token是单词,后面的elems是50个分量组成的向量(50维)
token, elems = elems[0], [float(elem) for elem in elems[1:]]
idx_to_token.append(token)
idx_to_vec.append(elems)
# 在第一行前面再加上一行全为0组成的向量
idx_to_vec = [[0] * len(idx_to_vec[0])] + idx_to_vec
return idx_to_token, torch.tensor(idx_to_vec)
# 根据token得到其对应的向量vec,上层调用形式为[tokens],用 [] 来取
def __getitem__(self, tokens):
indices = [self.token_to_idx.get(token, self.unknown_idx)
for token in tokens]
vecs = self.idx_to_vec[torch.tensor(indices)]
return vecs
def __len__(self):
return len(self.idx_to_token)
def knn(W, x, k):
"""
为了根据词向量之间的余弦相似性为输⼊词查找语义相似的词,我们实现了以下knn(k近邻)函数。
:param W: 矩阵
:param x: 要查找的向量
:param k: 取k个
:return topk_idx: 最高k个余弦值对应的idx
topk_cos: topk中的idx对应的余弦值
"""
# torch.mv()适用于 矩阵 和 向量或矩阵 相乘
# cos = W*x / (|W|*|x|)
# W大小:400001*50
# x大小:1*50
# x逆置即x.reshape(-1, ),大小变为50*1
# 增加1e-9以获得数值稳定性
# 得到的cos向量大小是400001*1,其第i个分量值表示矩阵X的第i行向量与向量x作余弦计算得到的值
cos = torch.mv(W, x.reshape(-1, )) / (
torch.sqrt(torch.sum(W * W, axis=1) + 1e-9) *
torch.sqrt((x * x).sum()))
# torch.topk()返回Tensor中的前k个元素以及元素对应的索引值
topk_cos, topk_idx = torch.topk(cos, k=k)
return topk_cos, topk_idx
# 然后,我们使⽤TokenEmbedding的实例embed中预训练好的词向量来搜索相似的词。
def get_similar_tokens(query_token, k, embed):
topk_cos, topk_idx = knn(embed.idx_to_vec, embed[[query_token]], k + 1) # 使用[[query_token]]是为了和vec保持同维度数
print(f'词相似任务 当前要查找的词为query_token 最相似的前k个词如下:')
for idx, cos in zip(topk_idx[1:], topk_cos[1:]): # 排除输入词
print(f'embed.idx_to_token[int(idx)]:cosine相似度=float(cos):.3f')
print()
# 词类比,根据token_a:token_b找到token_c:[analogy_token]中的[analogy_token]
# 例如,“man” : “woman” :: “son” : “daughter”是一个词的类比
def get_analogy(token_a, token_b, token_c, embed):
print(f'词类比任务 token_a:token_b :: token_c:[analogy_token]')
vecs = embed[[token_a, token_b, token_c]]
x = vecs[1] + vecs[2] - vecs[0] # 要找的词相似于token_b+token_c-token_a
_, topk_idx = knn(embed.idx_to_vec, x, 1)
analogy_token = embed.idx_to_token[int(topk_idx[0])]
print(f'查询[analogy_token]=analogy_token\\n')
if __name__ == '__main__':
# 下⾯我们加载50维GloVe嵌⼊(在维基百科的⼦集上预训练好的词向量)。
# 50维表示每个词用一个含有50个分量的向量来表示
# glove.6B.50d.txt 文件格式:
# 每行:token x1 x2 ... x50(token表示单词,xi表示词向量的第i个分量)
# 总共400000行
# 创建TokenEmbedding实例时,如果尚未下载指定的嵌入文件,则必须下载该文件。
glove_6b50d = TokenEmbedding('glove.6B.50d.txt')
# 输出词表大小。词表包含400000个词元和⼀个特殊的未知词元(unknown)。
print(f'词表大小=len(glove_6b50d)\\n')
# 我们可以得到词表中⼀个单词的索引,反之亦然。
# print(glove_6b50d.token_to_idx['beautiful'])
# print(glove_6b50d.idx_to_token[3367])
# 排除输入词和未知词元后,我们在词表中找到与“chip”一词语义最相似的三个词。
get_similar_tokens('chip', 3, glove_6b50d)
get_similar_tokens('beautiful', 3, glove_6b50d)
get_similar_tokens('love', 5, glove_6b50d)
get_analogy('man', 'woman', 'son', glove_6b50d)
get_analogy('beijing', 'china', 'tokyo', glove_6b50d)
get_analogy('do', 'did', 'go', glove_6b50d)
实验结果
词表大小=400001
词相似任务 当前要查找的词为chip 最相似的前3个词如下:
chips:cosine相似度=0.856
intel:cosine相似度=0.749
electronics:cosine相似度=0.749
词相似任务 当前要查找的词为beautiful 最相似的前3个词如下:
lovely:cosine相似度=0.921
gorgeous:cosine相似度=0.893
wonderful:cosine相似度=0.830
词相似任务 当前要查找的词为love 最相似的前5个词如下:
dream:cosine相似度=0.843
life:cosine相似度=0.840
dreams:cosine相似度=0.840
loves:cosine相似度=0.836
me:cosine相似度=0.835
词类比任务 man:woman :: son:[analogy_token]
查询[analogy_token]=daughter
词类比任务 beijing:china :: tokyo:[analogy_token]
查询[analogy_token]=japan
词类比任务 do:did :: go:[analogy_token]
查询[analogy_token]=went
以上是关于NLP实践用预训练的词向量处理词的相似性和类比任务的主要内容,如果未能解决你的问题,请参考以下文章