大数据讲课笔记6.3 ZooKeeper两种重要机制
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据讲课笔记6.3 ZooKeeper两种重要机制相关的知识,希望对你有一定的参考价值。
文章目录
零、学习目标
- 掌握Watcher机制的通知状态和事件类型
- 掌握选举机制的类型
一、导入新课
- 上一节中,主要讲解了ZooKeeper的数据模型。ZooKeeper分布式协调服务提供了两种重要的机制,分别是Watcher机制和选举机制。其中,Watcher机制用于实现分布式的通知功能。ZooKeeper提供的选举机制是用于保证各节点的协同工作。因此,本节将针对ZooKeeper的Watcher机制和选举机制行详细讲解。
二、新课讲解
(一)Watcher机制
1、Watcher机制
- 在ZooKeeper中,引入了Watch机制来实现这种分布式的通知功能。ZooKeeper允许客户端向服务端注册一个Watch监听,当服务端的一些事件触发了这个Watch,那么就会向指定客户端发送一个事件通知,来实现分布式的通知功能。
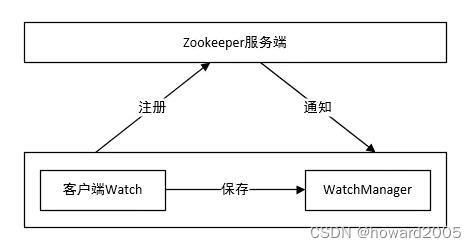
2、Watcher架构
- Watcher实现包含三个部分:Zookeeper服务端、Zookeeper客户端、客户端的ZKWatchManager对象
- 客户端首先将Watcher注册到服务端,同时将Watcher对象保存到客户端的Watch管理器中。当ZooKeeper服务端监听的数据状态发生变化时,服务端会主动通知客户端,接着客户端的Watch管理器会触发相关Watcher来回调相应处理逻辑,从而完成整体的数据发布/订阅流程。
3、Watcher特性
| 特性 | 说明 |
|---|
| 一次性 | Watcher是一次性的,一旦被触发就会移除,再次使用时需要重新注册 |
| 客户端顺序回调 | Watcher回调是顺序串行化执行的,只有回调后客户端才能看到最新的数据状态。一个Watcher回调逻辑不应该太多,以免影响别的watcher执行 |
| 轻量级 | WatchEvent是最小的通信单元,结构上只包含通知状态、事件类型和节点路径,并不会告诉数据节点变化前后的具体内容 |
| 时效性 | Watcher只有在当前session彻底失效时才会无效,若在session有效期内快速重连成功,则watcher依然存在,仍可接收到通知 |
4、Watcher接口设计
- Watcher是一个接口,任何实现了Watcher接口的类就是一个新的Watcher。Watcher内部包含了两个枚举类:KeeperState(通知状态)、EventType(事件类型)。
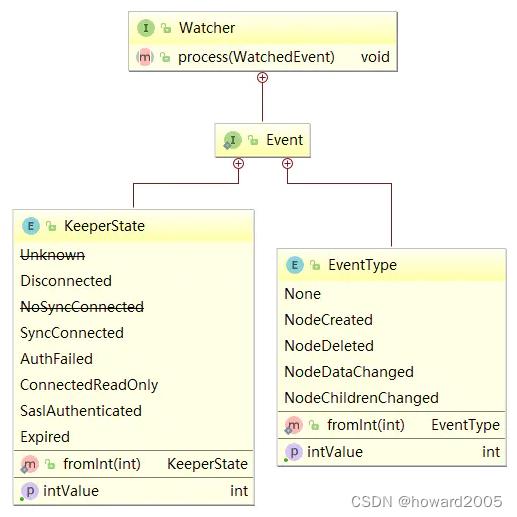
5、Watcher通知状态
- KeeperState是客户端与服务端连接状态发生变化时对应的通知类型。路径为
org.apache.zookeeper.Watcher.Event.KeeperState,是一个枚举类。
| 枚举属性 | 说明 |
|---|
| Unknown(-1) | 属性过期 |
| Disconnected(0) | 客户端与服务器断开连接时 |
| NoSyncConnected(1) | 属性过期 |
| SyncConnected(3) | 客户端与服务器正常连接时 |
| AuthFailed(4) | 身份认证失败时 |
| ConnectedReadOnly(5) | 3.3.0版本后支持只读模式,一般情况下ZK集群中半数以上服务器正常,zk集群才能正常对外提供服务。该属性的意义在于:若客户端设置了允许只读模式,则当zk集群中只有少于半数的服务器正常时,会返回这个状态给客户端,此时客户端只能处理读请求 |
| SaslAuthenticated(6) | 服务器采用SASL做校验时 |
| Expired(-112) | 会话session失效时 |
6、Watcher事件类型
- EventType是数据节点(znode)发生变化时对应的通知类型。EventType变化时KeeperState永远处于SyncConnected通知状态下;当KeeperState发生变化时,EventType永远为None。其路径为org.apache.zookeeper.Watcher.Event.EventType,是一个枚举类。
| 枚举属性 | 说明 |
|---|
| None (-1) | 无 |
| NodeCreated (1) | Watcher监听的数据节点被创建时 |
| NodeDeleted (2) | Watcher监听的数据节点被删除时 |
| NodeDataChanged (3) | Watcher监听的数据节点内容发生变更时(无论内容数据是否变化) |
| NodeChildrenChanged (4) | Watcher监听的数据节点的子节点列表发生变更时 |
- 说明:客户端接收到的相关事件通知中只包含状态及类型等信息,不包括节点变化前后的具体内容,变化前的数据需业务自身存储,变化后的数据需调用get等方法重新获取。
(二)选举机制
1、选举机制概述
- ZooKeeper为了保证各节点的协同工作,在工作时需要一个Leader角色,而ZooKeeper默认采用FastLeaderElection算法,且投票数大于半数则胜出的机制。
(1)服务器ID
- 设置集群myid参数时,参数分别为服务器1、服务器2、服务器3,编号越大FastLeaderElection算法中权重越大。
(2)选举ID
- 选举过程中,ZooKeeper服务器有四种状态,分别为
竞选状态、随从状态、观察状态、领导者状态。
(3)数据ID
- 数据ID是服务器中存放的最新数据版本号,该值越大则说明数据越新,在选举过程中数据越新权重越大。
(4)逻辑时钟
- 逻辑时钟被称为投票次数,同一轮投票过程中逻辑时钟值相同,逻辑时钟起始值为0,每投一次票,数据增加。与接收到其它服务器返回的投票信息中数值比较,根据不同值做出不同判断。
2、选举机制类型
- ZooKeeper选举机制有两种类型,分别为全新集群选举和非全新集群选举。全新集群选举是新搭建起来的,没有数据ID和逻辑时钟的数据影响集群的选举;非全新集群选举时是优中选优,保证Leader是ZooKeeper集群中数据最完整、最可靠的一台服务器。
(1)全新集群选举
- 假设有5台编号分别是1~5的服务器,全新集群选举过程如下:
| 步骤 | 操作 |
|---|
| 步骤1 | 服务器1启动,先给自己投票;其次,发投票信息,由于其它机器还没有启动所以它无法接收到投票的反馈信息,因此服务器1的状态一直属于竞选状态。 |
| 步骤2 | 服务器2启动,先给自己投票;其次,在集群中启动ZooKeeper服务的机器发起投票对比,它会与服务器1交换结果,由于服务器2编号大,服务器2胜出,服务器1会将票投给服务器2,此时服务器2的投票数并没有大于集群半数,两个服务器状态依旧是竞选状态。 |
| 步骤3 | 服务器3启动,先给自己投票;其次,与之前启动的服务器1、2交换信息,服务器3的编号最大,服务器3胜出,服务器1、2会将票投给服务器3,此时投票数正好大于半数,所以服务器3成为领导者状态,服务器1、2成为追随者状态。 |
| 步骤4 | 服务器4启动,先给自己投票;其次,与之前启动的服务器1、2、3交换信息,尽管服务器4的编号大,但是服务器3已经胜,所以服务器4只能成为追随者状态。 |
| 步骤5 | 服务器5启动,同服务器4一样,均成为追随者状态。 |
(2)非全新集群选举
| 步骤 | 操作 |
|---|
| 步骤1 | 统计逻辑时钟是否相同,逻辑时钟小,则说明途中可能存在宕机问题,因此数据不完整,那么该选举结果被忽略,重新投票选举。 |
| 步骤2 | 统一逻辑时钟后,对比数据ID值,数据ID反应数据的新旧程度,因此数据ID大的胜出。 |
| 步骤3 | 如果逻辑时钟和数据ID都相同的情况下,那么比较服务器ID(编号),值大则胜出。 |
三、归纳总结
- 回顾本节课所讲的内容,并通过提问的方式引导学生解答问题并给予指导。
四、上机操作
- 形式:单独完成
- 题目:深入了解ZooKeeper两种重要机制
- 要求:观看尚硅谷大数据视频涉及ZooKeeper两种重要机制这部分内容,然后撰写一篇学习报告。
以上是关于大数据讲课笔记6.3 ZooKeeper两种重要机制的主要内容,如果未能解决你的问题,请参考以下文章