无状态 — 你使用 Elasticsearch 找到的新状态
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无状态 — 你使用 Elasticsearch 找到的新状态相关的知识,希望对你有一定的参考价值。
作者:Leaf Lin,Tim Brooks,Quin Hoxie

我们从何开始
Elasticsearch 的第一个版本于 2010 年作为分布式可扩展搜索引擎发布,允许用户快速搜索并显示关键见解。十二年和超过 65,000 次提交后,Elasticsearch 继续为用户提供久经考验的解决方案,以解决各种搜索问题。得益于 1,500 多名贡献者(包括数百名 Elastic 全职员工)的努力,Elasticsearch 不断发展以应对搜索领域出现的新挑战。
在 Elasticsearch 生命周期的早期,当有人提出数据丢失问题时,Elastic 团队经历了多年的努力来重写集群协调系统,以确保确认的数据得到安全存储。当发现在大型集群中管理索引很麻烦时,该团队致力于实施广泛的 ILM 解决方案,通过允许用户预定义索引模式和生命周期操作来自动化这项工作。由于用户发现需要存储大量指标和时间序列数据,因此添加了更好的压缩等各种功能以减少数据大小。随着搜索大量冷数据的存储成本不断增长,我们投资创建可搜索快照(Searchable Snapshots)作为直接在低成本对象存储上搜索用户数据的一种方式。
这些投资为 Elasticsearch 的下一次演进奠定了基础。随着云原生服务和新编排系统的增长,我们决定是时候发展 Elasticsearch 以改善使用云原生系统时的体验了。我们相信,这些变化为在 Elastic Cloud 上运行 Elasticsearch 提供了运营、性能和成本改进的机会。
我们要去哪里——未来是无状态的
操作或编排 Elasticsearch 时的主要挑战之一是它依赖于许多持久状态,因此它是一个有状态的系统。三个主要部分是事务日志(translog)、索引存储(index store)和集群元数据(cluster metadata)。这种状态意味着存储必须是持久的,并且在节点重新启动或替换期间不能丢失。
Elastic Cloud 上现有的 Elasticsearch 架构必须跨多个可用区复制索引,以在中断的情况下提供冗余。我们打算将这些数据的持久性从本地磁盘转移到对象存储,例如 AWS S3。通过依赖外部服务来存储这些数据,我们将不再需要索引复制,从而显着减少与摄取相关的硬件。由于 AWS S3、GCP 云存储和 Azure Blob 存储等云对象存储跨可用区复制数据的方式,此架构还提供了非常高的持久性保证。
将索引存储卸载到外部服务中还将允许我们通过分离索引和搜索职责来重新构建 Elasticsearch。我们打算拥有一个索引层和一个搜索层,而不是让主(primary)实例和副本(replica)实例同时处理这两种工作负载。分离这些工作负载将使它们能够独立扩展,并且硬件选择更适合各自的用例。它还有助于解决搜索和索引负载可能相互影响的长期挑战。
在进行了数月的概念验证和实验阶段之后,我们确信这些对象存储服务能够满足我们对索引存储和集群元数据的设想。我们的测试和基准表明,这些存储服务可以满足我们在 Elastic Cloud 中看到的最大集群的高索引需求。此外,支持对象存储中的数据降低了索引成本,并允许简单地调整搜索性能。为了搜索数据,Elasticsearch 将使用久经考验的可搜索快照(Searchable Sanpshots)模型,其中数据永久保存在云原生对象存储中,本地磁盘用作频繁访问数据的缓存。
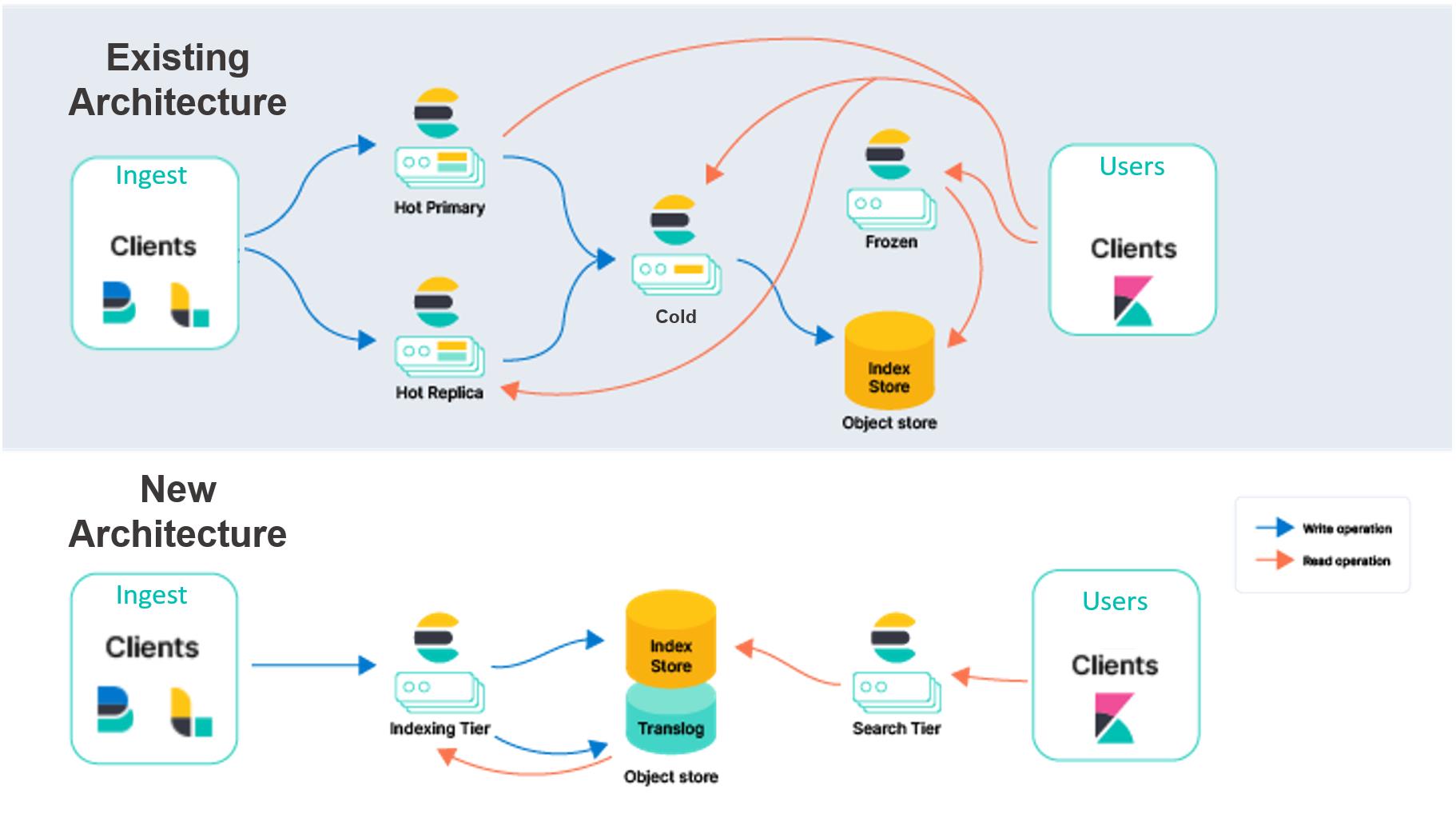
为了帮助区分,我们将现有模型描述为 “节点到节点” 复制。在此模型的热层中,主分片和副本分片都执行相同的繁重工作来处理摄取和服务搜索请求。这些节点是 “有状态的”,因为它们依靠本地磁盘来安全地保存它们托管的分片的数据。此外,主分片和副本分片不断通信以保持同步。他们通过将在主分片上执行的操作复制到副本分片来做到这一点,这意味着这些操作(主要是 CPU)的成本是针对每个指定的副本产生的。为摄取执行这项工作的相同分片和节点也为搜索请求提供服务,因此必须在考虑到这两种工作负载的情况下进行配置和扩展。
除了搜索和摄取之外,节点到节点复制模型中的分片还处理其他密集的职责,例如合并 Lucene 段。虽然这种设计有其优点,但根据我们多年来从客户那里学到的知识以及更广泛的云生态系统的发展,我们看到了很多机会。
新架构可实现许多即时和未来的改进,包括:
- 你可以显着提高相同硬件上的摄取吞吐量,或者以另一种方式看待它,显着提高相同摄取工作负载的效率。这种增加来自为每个副本删除了重复的索引操作。 CPU 密集型索引操作只需在索引层上发生一次,然后将生成的段发送到对象存储。从那里,数据已准备好由搜索层按原样使用。
- 你可以将计算与存储分开以简化集群拓扑。如今,Elasticsearch 拥有多个数据层(内容、热、温、冷和冻结)来匹配数据与硬件配置文件。 Hot tier 用于近乎实时的搜索,frozen 用于不太频繁搜索的数据。虽然这些层级提供了价值,但它们也增加了复杂性。在新架构中,将不再需要数据层,从而简化了 Elasticsearch 的配置和操作。我们还将索引与搜索分开,这进一步降低了复杂性并允许我们独立扩展这两个工作负载。
- 通过减少必须存储在本地磁盘上的数据量,你可以体验到索引层存储成本的降低。目前,Elasticsearch 必须在热节点(主节点和副本)上存储完整的分片副本以用于索引目的。使用直接索引到对象存储的无状态(stateless)方法,只需要该本地数据的一部分。对于只有添加(append)用例来说,仅需要存储某些元数据以进行索引。这将显着减少索引所需的本地存储。
- 你可以降低与搜索查询相关的存储成本。通过使可搜索快照模型成为搜索数据的本机模式,与搜索查询相关的存储成本将显着降低。根据用户对搜索延迟的需求,Elasticsearch 将允许调整以增加对频繁请求数据的本地缓存。
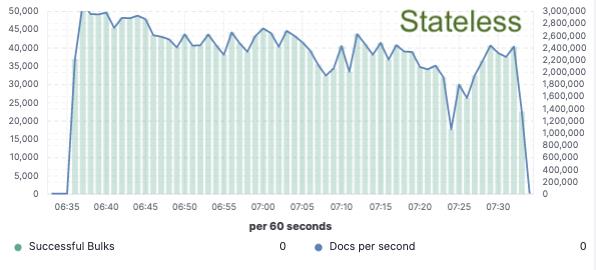
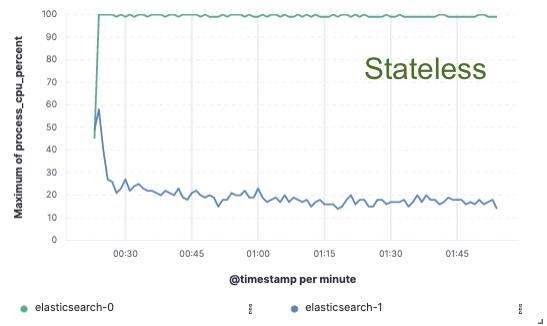
基准测试 — 75% 的索引吞吐量提高
为了验证这种方法,我们实施了广泛的概念证明,其中数据仅在单个节点上建立索引,并且通过云对象存储实现复制。 我们发现,通过消除将硬件用于索引复制的需要,我们可以将索引吞吐量提高 75%。 此外,与简单地从对象存储中提取数据相关的 CPU 成本远低于索引数据并在本地写入数据,这对于当今的热层来说是必要的。 这意味着搜索节点将能够完全将其 CPU 用于搜索。
这些性能测试是在一个两节点集群上针对所有三个主要公共云提供商(AWS、GCP 和 Azure)进行的。 随着我们追求生产无状态实施,我们打算继续建立更大的基准。
索引吞吐量

CPU使用率

在我们看来无状态,为你省钱
Elastic Cloud 上的无状态架构将允许你减少索引开销、独立扩展摄取和搜索、简化数据层管理并加速操作,例如扩展或升级。 这是 Elastic Cloud 平台实现重大现代化的第一个里程碑。
成为我们无状态愿景的一部分
有兴趣在其他人之前尝试此解决方案吗? 你可以通过讨论或我们的社区 Slack 频道与我们联系。 我们希望你的反馈有助于塑造我们新架构的方向。
原文:Stateless — your new state of find with Elasticsearch | Elastic Blog
以上是关于无状态 — 你使用 Elasticsearch 找到的新状态的主要内容,如果未能解决你的问题,请参考以下文章