ElasticSearch_07_SpringBoot集成ES
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch_07_SpringBoot集成ES相关的知识,希望对你有一定的参考价值。
系列文章目录
文章目录
前言
一、新建项目
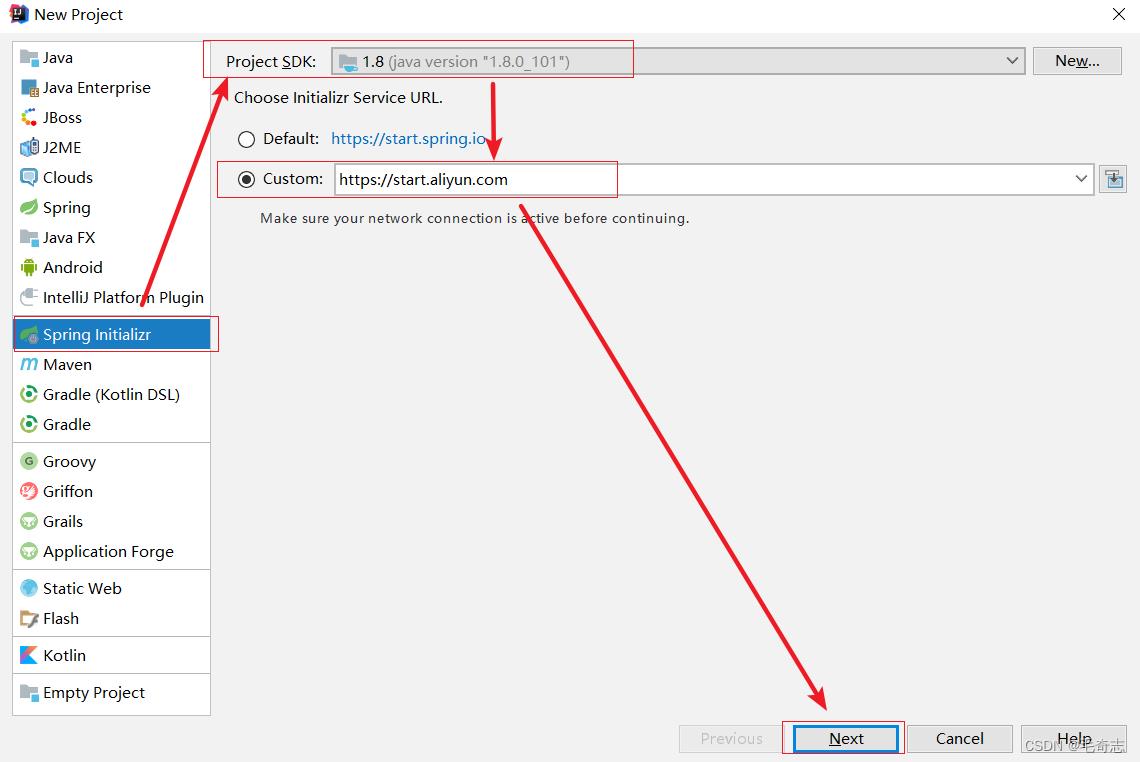
选择springboot项目,这里可以选择 custom 表示自定义,然后输入阿里的地址,这个是国内的,比较快
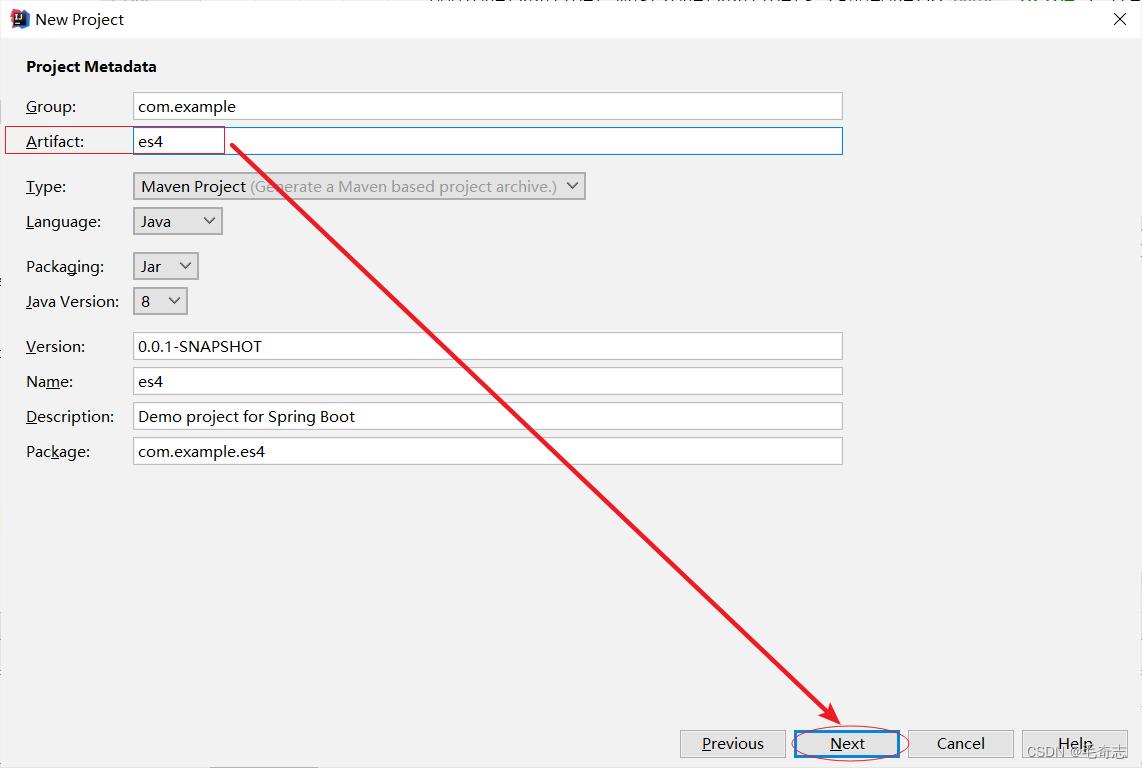
输入项目名称,可以随便输入,这里选择es4
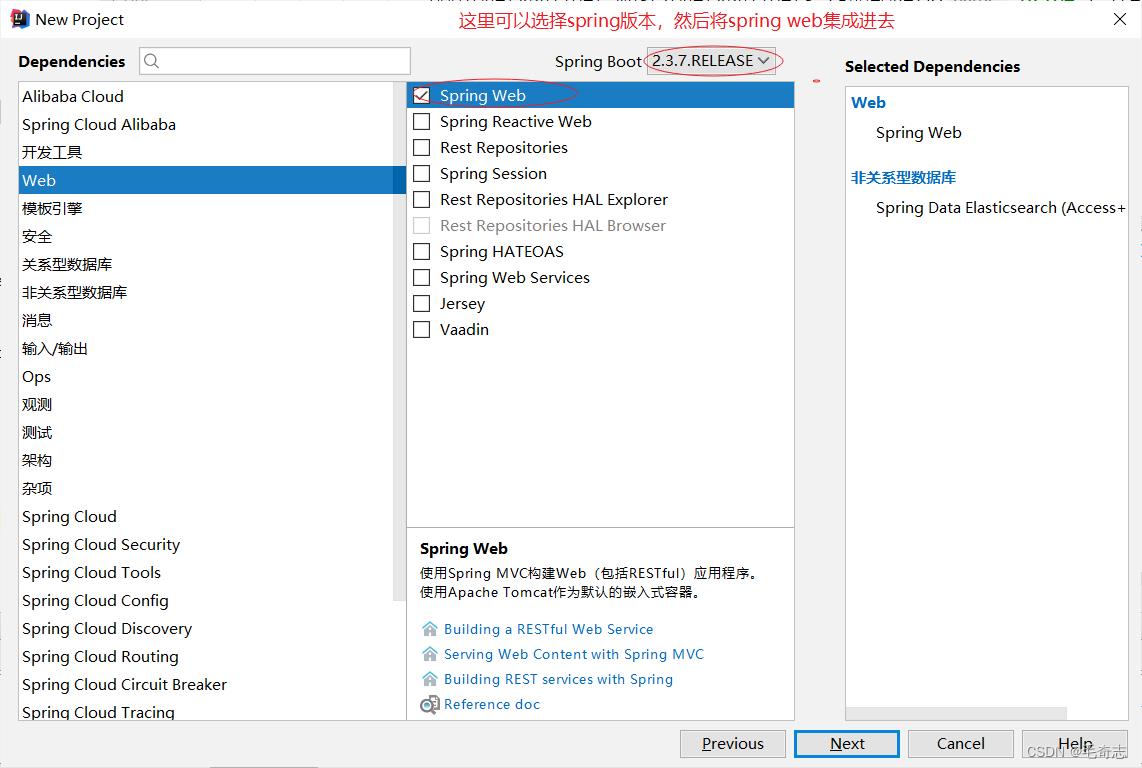
先选择一个spring web依赖
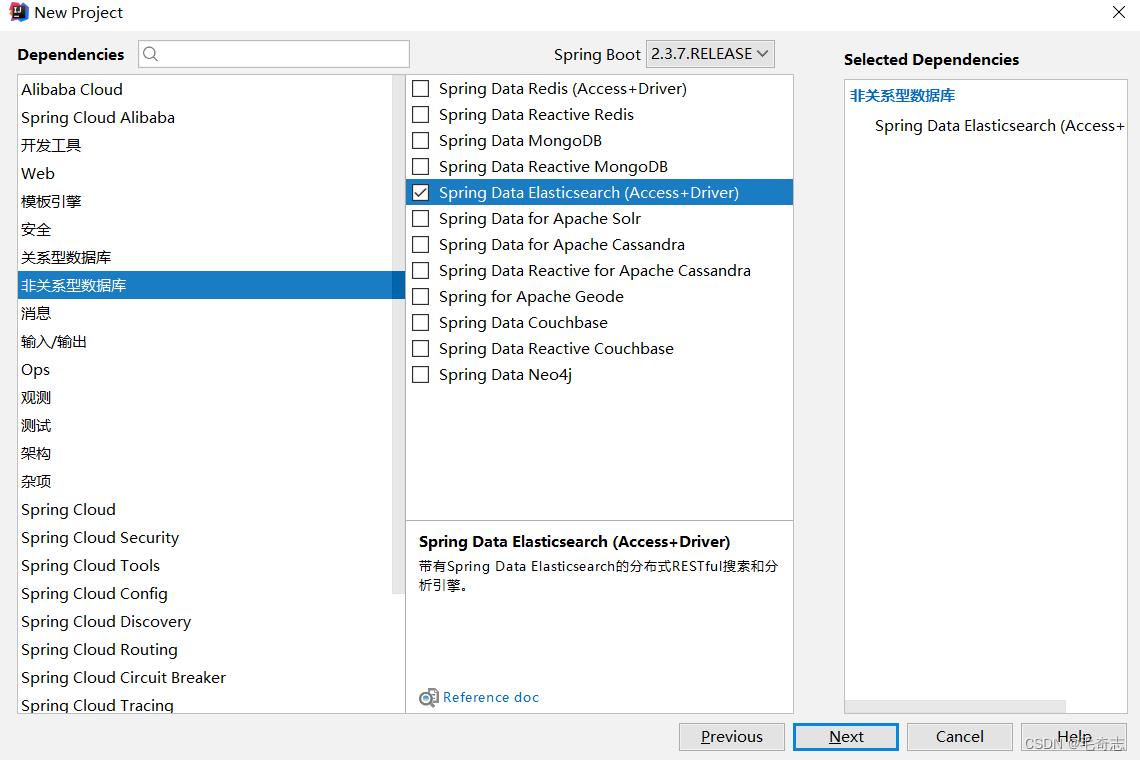
再选择一个es依赖
然后写好 controller - service - mapper
二、文档操作
2.1 阶段一(直接查询)
// 查询document阶段1开始(没有拼装搜索条件,没有拼装返回结果)
@Override
public Map<String, Object> search(Map<String, Object> searchMap)
//条件封装
NativeSearchQueryBuilder queryBuilder = queryBuilder(searchMap);
//执行搜索
Page<User> result = skuSearchMapper.search(queryBuilder.build());
//结果集
List<User> list = result.getContent();
//记录数
long totalElements = result.getTotalElements();
Map<String,Object> resultMap = new HashMap<String,Object>();
resultMap.put("list",list);
resultMap.put("totalElements",totalElements);
return resultMap;
/***
* 搜索条件组装
*/
public NativeSearchQueryBuilder queryBuilder(Map<String,Object> searchMap)
//QueryBuilder构建
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//条件判断
if(searchMap!=null && searchMap.size()>0)
//关键词
Object keywords =searchMap.get("keywords");
if(!StringUtils.isEmpty(keywords))
queryBuilder.withQuery(QueryBuilders.termQuery("name",keywords.toString()));
return queryBuilder;
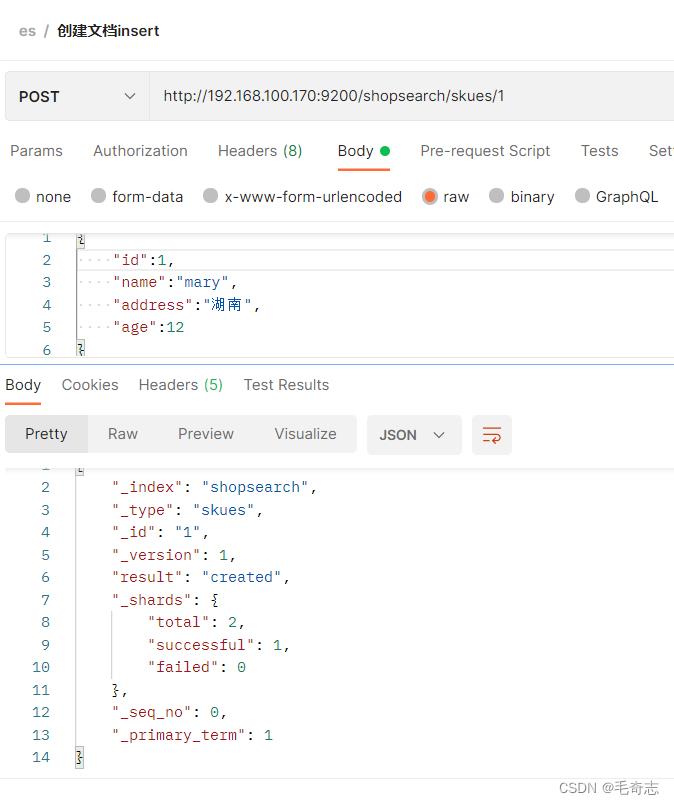
2.1.1 直接调用es的接口插入文档
插入document()
http://192.168.100.170:9200/shopsearch/skues/1
"id":1,
"name":"mary",
"address":"湖南",
"age":12
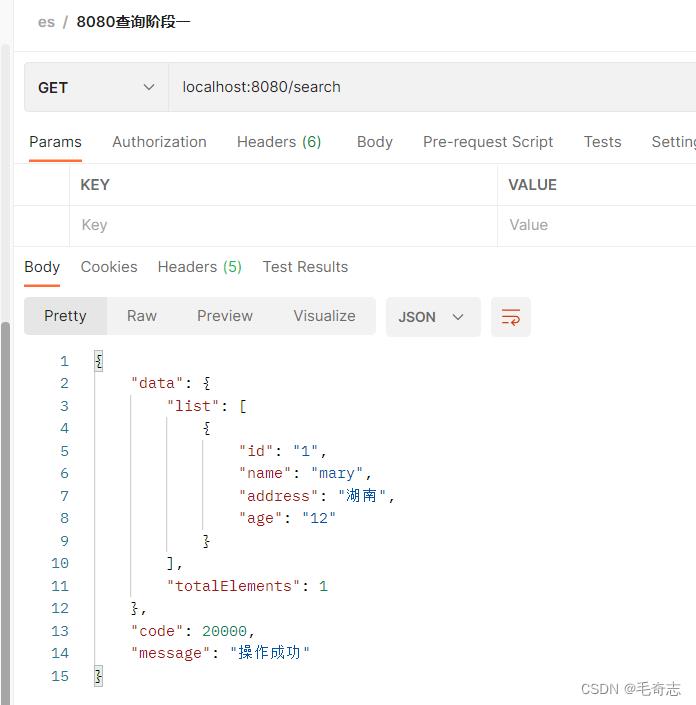
查询指定index-type
localhost:8080/search
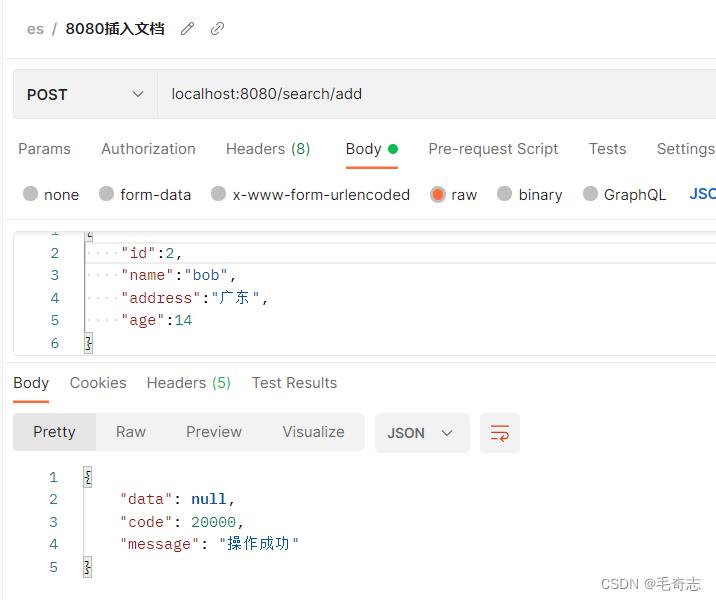
2.1.2 使用springboot接口插入文档
使用接口创建document
localhost:8080/search/add
"id":2,
"name":"bob",
"address":"广东",
"age":14
再次查找,多了一个document
localhost:8080/search
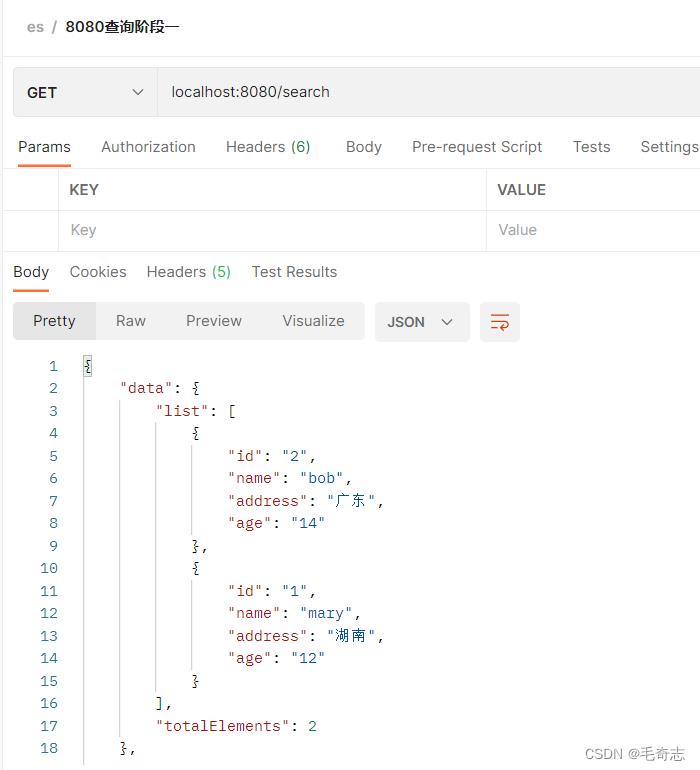
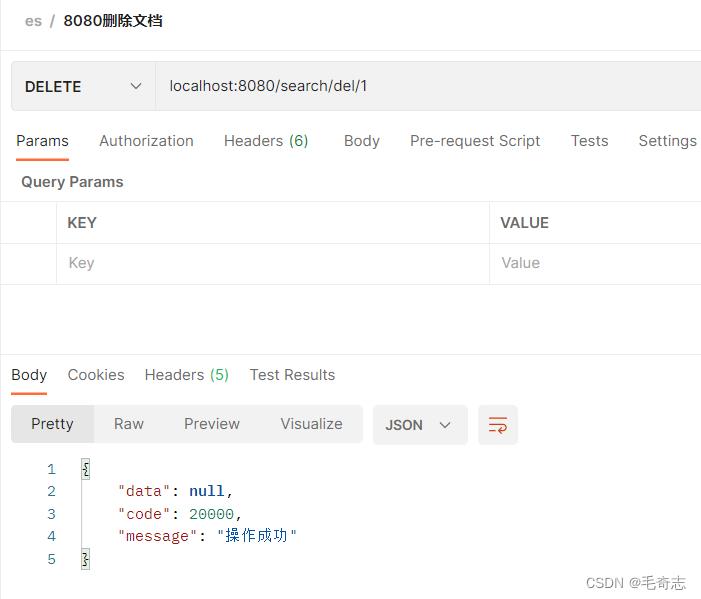
2.1.3 使用springboot接口删除文档
8080删除document
localhost:8080/search/del/1
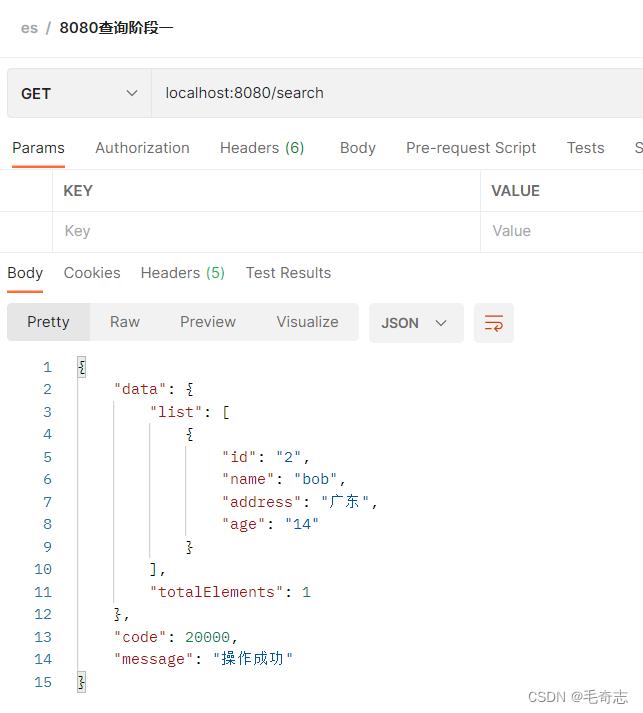
第三次查询,id 为 1的湖南被删除掉了
localhost:8080/search
2.2 阶段二(添加上分组)
// 查询document阶段2开始(搜索条件中添加分组,返回结果中添加分组)
@Override
public Map<String, Object> search(Map<String, Object> searchMap)
//QueryBuilder->构建搜索条件
NativeSearchQueryBuilder queryBuilder =queryBuilder(searchMap);
//分组搜索调用
group(queryBuilder,searchMap);
//2.将非高亮数据替换成高亮数据
AggregatedPage<User> result = (AggregatedPage<User>) skuSearchMapper.search(queryBuilder.build());
//分组数据解析 将json变为map 返回给前端
Map<String,Object> groups = parseGroup(result.getAggregations());
//获取结果集:集合列表、总记录数
Map<String,Object> resultMap = new HashMap<String,Object>();
List<User> list = result.getContent();
resultMap.put("list",list);
resultMap.put("totalElements",result.getTotalElements());
resultMap.putAll(groups);
return resultMap;
public NativeSearchQueryBuilder queryBuilder(Map<String,Object> searchMap)
//QueryBuilder构建
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//条件判断
if(searchMap!=null && searchMap.size()>0)
//关键词
Object keywords =searchMap.get("keywords");
if(!StringUtils.isEmpty(keywords))
queryBuilder.withQuery(QueryBuilders.termQuery("name",keywords.toString()));
return queryBuilder;
public void group(NativeSearchQueryBuilder builder,Map<String,Object> searchMap)
//前端没有传入分类参数的时候查询分类集合作为搜索条件
if(searchMap ==null || StringUtils.isEmpty(searchMap.get("address")))
//分类分组
builder.addAggregation(AggregationBuilders
.terms("addressList") //查询的数据对应别名
.field("address.keyword") //根据categoryName分组
.size(100)); //分组查询100条
//前端没有传入品牌参数的时候查询品牌集合作为搜索条件
if(searchMap ==null || StringUtils.isEmpty(searchMap.get("age")))
//品牌分组
builder.addAggregation(AggregationBuilders
.terms("ageList") //查询的数据对应别名
.field("age.keyword") //根据brandName分组
.size(100)); //分组查询100条
public Map<String,Object> parseGroup(Aggregations aggregations)
//所有分组数据
Map<String,Object> groups = new HashMap<String,Object>();
for (Aggregation aggregation : aggregations)
//强转成ParsedStringTerms
ParsedStringTerms pst= (ParsedStringTerms) aggregation;
//定义一个集合存储
List<String> values = new ArrayList<String>();
for (Terms.Bucket bucket : pst.getBuckets())
//单个对象值
values.add(bucket.getKeyAsString());
//存入到Map中
groups.put(pst.getName(),values);
return groups;
//----- 阶段二完成
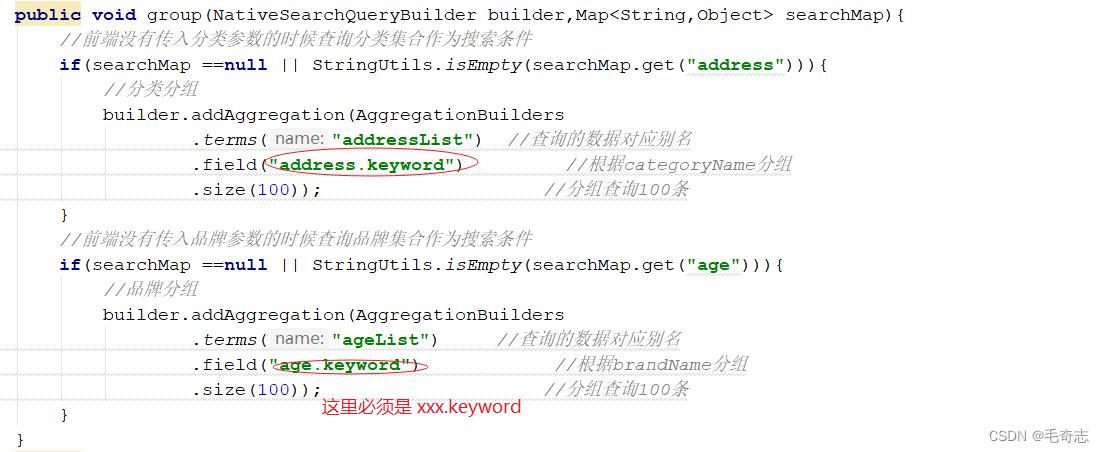
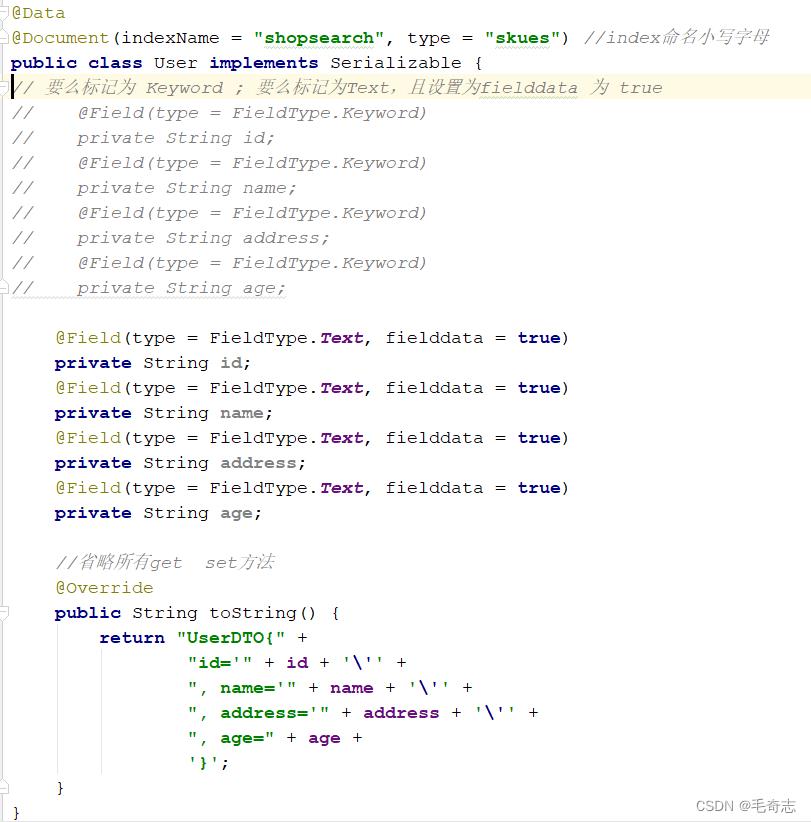
需要设置一下User类(文档类),要么标记为 Keyword ; 要么标记为Text,且设置为fielddata 为 true
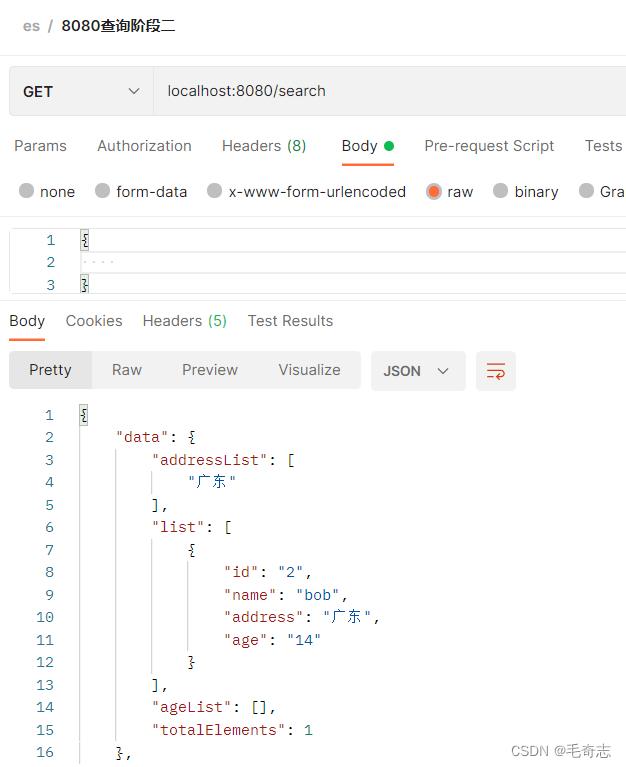
执行分组查询
2.3 阶段三
总结
以上是关于ElasticSearch_07_SpringBoot集成ES的主要内容,如果未能解决你的问题,请参考以下文章