Keras深度学习实战(28)——利用单词向量构建情感分析模型
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战(28)——利用单词向量构建情感分析模型相关的知识,希望对你有一定的参考价值。
Keras深度学习实战(28)——利用单词向量构建情感分析模型
0. 前言
在获取单词向量的相关博文中,我们学习了多种不同的神经网络模型用于生成单词向量。在本节中,我们将进一步利用获取到的单词向量,学习如何构建情感分类器分析给定的文本。
1. 模型与数据集分析
1.1 模型分析
使用在《使用 CBOW 模型构建单词向量》一节中介绍的单词向量构建模型 CBOW 获取单词向量,并利用得到的单词向量构建情感分类模型,预测用户的评论属于正面评价、负面评价或者中立评价。
1.2 数据集分析
下一小节,我们将实现 CBOW 模型生成单词向量,然后利用获得的单词向量构建情感分析模型,所用的数据集与在《从零开始构建单词向量》一节中使用的数据集相同,即航空公司 Twitter 数据集,模型的目标是预测用户对于航空公司的评价属于正面、负面或者中立。
2. 情感分析模型
2.1 使用 CBOW 模型获取单词向量
(1) 导入相关库,并导入所需数据集:
from glove import Corpus, Glove
import pandas as pd
data = pd.read_csv('archive/Tweets.csv')
print(data.head())
(2) 预处理输入文本:
import re
import nltk
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
def preprocess(text):
text=text.lower()
text=re.sub('[^0-9a-zA-Z]+',' ',text)
words = text.split()
words2 = [i for i in words if i not in stop]
words3=' '.join(words2)
return(words3)
data['text'] = data['text'].apply(preprocess)
(3) 提取数据集中所有句子的单词列表,并对输出进行独热编码:
list_words=[]
for i in range(len(data)):
list_words.append(data['text'][i].split())
y = data['airline_sentiment'].values
y = np.array(pd.get_dummies(y))
(4) 构建一个 CBOW 模型,上下文窗口大小为 5,单词向量维度为 100:
from gensim.models import Word2Vec
model = Word2Vec(vector_size=100, window=5, min_count=30, sg=0)
(5) 指定要建模的词汇表,然后对其进行训练:
model.build_vocab(list_words)
model.train(list_words, total_examples=model.corpus_count, epochs=100)
(6) 提取给定推文文本的平均向量:
import numpy as np
features= []
for i in range(len(list_words)):
t2 = list_words[i]
z = np.zeros((1,100))
k=0
for j in range(len(t2)):
try:
z = z + np.array(model.wv.get_vector(t2[j]))
k = k + 1
except KeyError:
continue
features.append(z/k)
在以上代码中,我们对输入句子中存在的单词提取单词向量,并计算它们的平均值。此外,由于某些频率较低的单词不在词汇表中,如果我们提取其向量,则会导致异常,因此,我们使用 try...except 捕获错误。
2.2 构建并训练情感分析模型
(1) 将输入特征转换为 numpy 数组,拆分数据集为训练和测试数据集,并对输入数据集进行整形,以便可以将它们输入到情感分类模型中:
features = np.array(features)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(features, y, test_size=0.20)
x_train = x_train.reshape(x_train.shape[0], 100)
x_test = x_test.reshape(x_test.shape[0], 100)
(2) 构建并编译神经网络以预测推文的情感:
from keras.layers import Dense, Activation, Dropout
from keras.models import Sequential
from keras.utils import to_categorical
from keras.layers.embeddings import Embedding
model = Sequential()
model.add(Dense(1024, input_dim=100, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
model.summary()
定义的模型简要信息输出如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1024) 103424
_________________________________________________________________
dropout (Dropout) (None, 1024) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 524800
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 65664
_________________________________________________________________
dense_3 (Dense) (None, 3) 387
_________________________________________________________________
activation (Activation) (None, 3) 0
=================================================================
Total params: 694,275
Trainable params: 694,275
Non-trainable params: 0
_________________________________________________________________
在以上模型中,我们使用了多个隐藏层,输出层中有三个单元,分别表示正面、负面或中立评价,由于是多分类问题,因此使用 softmax 激活函数,且使用多分类交叉熵损失。接下来,训练神经网络模型:
history = model.fit(x_train, y_train,
batch_size=64,
epochs=20,
validation_data=(x_test, y_test),
verbose = 1)
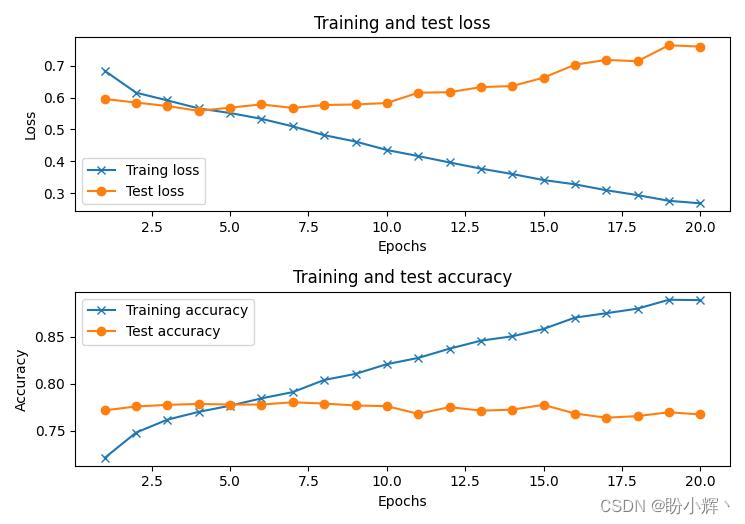
可以看到,在预测推文情感时,模型的测试准确率约为 75%。
(3) 计算模型关于测试数据集的混淆矩阵:
pred = model.predict(x_test)
y_test = np.argmax(y_test, axis=1)
pred = np.argmax(pred, axis=1)
# pred2 = np.where(pred>0.5,1,0)
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, pred))
测试数据集混淆矩阵的输出如下:
[[1617 134 99]
[ 198 322 77]
[ 104 66 311]]
本节我们使用 CBOW 模型和推文中出现的所有单词向量的平均值来实现情感分类,我们也可以使用其他模型完成情感分析任务:
- 使用基于 skip-gram 模型得到的单词向量
- 使用基于 doc2vec 模型得到的文档和单词向量
- 使用基于 fastText 模型得到的单词向量
- 使用基于 GloVe 模型得到的单词向量
- 使用基于预训练模型得到的单词向量
尽管这些方法都可以完成情感分析任务,但这些模型的局限之一是它们都没有考虑单词顺序。有更复杂的算法可以解决单词顺序问题,我们将在之后的学习对其进行讨论。
小结
分析隐藏在文本数据背后的情感是自然语言处理的一个基本研究领域,情感分析在推荐系统、语音助手等应用中有着十分重要的作用。本文通过使用 CBOW 模型获取用户评论数据的平均单词向量,然后利用平均单词向量训练情感分类模型,预测用户对于航空公司的评价是正面、负面或者中立的,相比直接使用单词独热编码进行预测,使用单词向量进行预测的模型准确率更高。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础详解
Keras深度学习实战(14)——从零开始实现R-CNN目标检测
Keras深度学习实战(15)——从零开始实现YOLO目标检测
Keras深度学习实战(16)——自编码器详解
Keras深度学习实战(17)——使用U-Net架构进行图像分割
Keras深度学习实战(18)——语义分割详解
Keras深度学习实战(19)——使用对抗攻击生成可欺骗神经网络的图像
Keras深度学习实战(20)——DeepDream模型详解
Keras深度学习实战(21)——神经风格迁移详解
Keras深度学习实战(22)——生成对抗网络详解与实现
Keras深度学习实战(23)——DCGAN详解与实现
Keras深度学习实战(24)——从零开始构建单词向量
Keras深度学习实战(25)——使用skip-gram和CBOW模型构建单词向量
Keras深度学习实战(26)——文档向量详解
Keras深度学习实战(27)——循环神经详解与实现
以上是关于Keras深度学习实战(28)——利用单词向量构建情感分析模型的主要内容,如果未能解决你的问题,请参考以下文章