[架构之路-12]:目标系统 - 硬件平台 - 单核CPU的架构与基本工作原理
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[架构之路-12]:目标系统 - 硬件平台 - 单核CPU的架构与基本工作原理相关的知识,希望对你有一定的参考价值。
目录
前言:
X86架构的软件架构师是可以不用关心CPU的架构的,但对于嵌入式系统的架构师,熟悉CPU架构是必须的,他们会面对不同CPU架构的CPU的选型问题 。
第1章 CPU概述(静态组成)
1.1 什么是CPU
中央处理器(CPU),是电子计算机的主要设备之一,电脑中的核心配件。
中央处理器(central processing unit,简称CPU)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。CPU也称为通用处理器。
其功能主要是解释计算机指令以及处理计算机软件中的二进制数据。
1.2 CPU内部架构
电子计算机三大核心部件就是CPU、内部存储器、输入/输出设备。
CPU是计算机中负责读取指令,对指令译码并执行指令的核心部件。
中央处理器主要包括两个部分,即控制器、运算器,其中还包括高速缓冲存储器及实现它们之间联系的数据、控制的总线。

ALU:运算单元,是CPU的内核执行单元。
寄存器:暂时寸法指令或数据。
控制器:控制指令的执行流程。
PC:指令指针,存放要执行的下一条指令的地址。
AR:地址寄存器,存放数据的地址。
暂存器:暂时存放数据。
1.3 冯诺依曼计算机体系架构
冯诺依曼计算机体系结构是指基于数学家冯诺依曼提出的关于计算机制造的三个基本原则而构建的计算机。这种架构的计算机机将程序指令存储器和数据存储器合并在一起的存储器结构。
程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置,因此程序指令和数据的宽度相同。三种基本原则分别为:
(1)采用二进制逻辑结构(二进制计算机的来源)
(2)程序存储执行
(3)计算机由五部分组成(运算器,控制器,存储器,输入设备,输出设备)
如下图所示:

1.4 CPU指令集
计算机指令就是指挥机器工作的指示和命令,程序就是一系列按一定顺序排列的指令,执行程序的过程就是计算机的工作过程。
指令集,就是CPU中用来计算和控制计算机系统的一套指令的集合,而每一种新型的CPU在设计时就规定了一系列与其他硬件电路相配合的指令系统。

1.5 CPU总线
CPU总线是在计算机系统中最快的总线,同时也是芯片组与主板的核心。
人们通常把与CPU核直接相连(通常是内存)的局部总线叫做CPU总线或者称之为SOC内部总线,将SOC那些和各种通用的扩展槽相接的局部总线叫做系统总线或者是外部总线。

在内部结构比较单一的CPU中,往往只设置一组数据传送的总线即CPU内部总线,用来将CPU内部的寄存器和算数逻辑运算部件等连接起来,因此也可以将这一类的总线称之为ALU总线。
而部件内的总线,通过使用一组总线将各个芯片连接到一起,因此可以将其称为部件内总线,一般会包含地址线以及数据线这两组线路。
系统总线指的是将系统内部的各个组成部分连接在一起的线路,是将系统的整体连接到一起的基础;

而系统外的总线,是将计算机和其他的设备连接到一起的基础线路。

1.6 CPU的位宽
CPU出现于大规模集成电路时代,处理器架构设计的迭代更新以及集成电路工艺的不断提升促使其不断发展完善。
从最初专用于数学计算到广泛应用于通用计算,从4位到8位、16位、32位处理器,最后到64位处理器,
CPU的位宽是指数据/地址总线的宽度。
在数据和地址分离的系统,CPU的带宽,主要是数据总线的带宽。
1.7 CPU的端模式Endian
大端模式和小端模式指的是CPU存放变量的方式,即字节序:
对于小端模式的CPU:对操作数的存放方式是从低字节到高字节

1.8 CPU的主频
主频即CPU的时钟频率,计算机的操作是在时钟信号的统一步调控制下分步执行指令的,每个时钟信号周期完成一步操作,时钟频率的高低在很大程度上反映了CPU执行指令的速度的快慢。
CPU的频率越高,单位时间内执行的CPU的指令越多,信号之间的干扰就越强,对设计的要求越高。
第2章 CPU指令执行的五个阶段(动态执行)
2.1 CPU指令执行的5个阶段
中央处理器的功效主要为处理指令、执行操作、控制时间、处理数据。
CPU的工作分为以下 5 个阶段:
取指令阶段、指令译码阶段、执行指令阶段、访存取数和结果写回。

(1)取指令(IF,instruction fetch)
即将一条指令从主存储器中取到指令寄存器的过程。程序计数器中的数值,用来指示当前指令在主存中的位置。当 一条指令被取出后,程序计数器(PC)中的数值将根据指令字长度自动递增。 [1]
(2)指令译码阶段(ID,instruction decode)
取出指令后,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类 别以及各种获取操作数的方法。现代CISC处理器会将拆分已提高并行率和效率。 [1]
(3)执行指令阶段(EX,execute)
具体实现指令的功能。CPU的不同部分被连接起来,以执行所需的操作。
(4)访存取数阶段(MEM,memory)
根据指令需要访问主存、读取操作数,CPU得到操作数在主存中的地址,并从主存中读取该操作数用于运算。部分指令不需要访问主存,则可以跳过该阶段。 [1]
(5)结果写回阶段(WB,write back)
作为最后一个阶段,结果写回阶段把执行指令阶段的运行结果数据“写回”到某种存储形式。
结果数据一般会被写到CPU的内部寄存器中,以便被后续的指令快速地存取;许多指令还会改变程序状态字寄存器中标志位的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。 [1]
在指令执行完毕、结果数据写回之后,若无意外事件(如结果溢出等)发生,计算机就从程序计数器中取得下一条指令地址,开始新一轮的循环,下一个指令周期将顺序取出下一条指令。 [1] 许多复杂的CPU可以一次提取多个指令、解码,并且同时执行。
2.2 CPU指令流水线Pipline
cpu流水线技术是一种将指令分解为多步,并让不同指令的各步操作重叠,从而实现几条指令并行处理,以加速程序运行过程的技术。
指令的每步有各自独立的电路来处理,每完成一步,就进到下一步,而前一步则处理后续指令。

采用流水线技术后,并没有加速单条指令的执行,每条指令的操作步骤一个也不能少,只是多条指令的不同操作步骤同时执行,因而从总体上看加快了指令流速度,缩短了程序执行时间。
为了进一步满足普通流水线设计所不能适应的更高时钟频率的要求,高档位处理器中的流水线的深度(级数)在逐代增多。当流水线深度在5~6级以上时,通常称为超流水线结构(Super Pipeline)。显然,流水线级数越多,每级所花的时间越短,时钟周期就可以设计的越短,指令速度越快,指令平均执行时间也就越短。
流水线技术是通过增加计算机硬件来实现的。它要求各功能段能互相独立地工作,这就要增加硬件,相应地也加大了控制的复杂性。如果没有互相独立的操作部件,很可能会发生各种冲突。例如要能预取指令,就需增加指令的硬件电路,并把取来的指令存放到指令队列缓冲器中,使微处理器能同时进行取指令和分析、执行指令的操作。
2.3 CPU执行指令的性能指标FLOPS
是“每秒所执行的浮点运算次数”(floating-point operations per second)的缩写。
FLOPS,即每秒浮点运算次数, 是每秒所执行的浮点运算次数(Floating-point operations per second;缩写:FLOPS)的简称,被用来评估电脑效能.
常见的浮点计算值的单位:
一个MFLOPS(megaFLOPS)等於每秒一佰万(=10^6)次的浮点运算,
一个GFLOPS(gigaFLOPS)等於每秒拾亿(=10^9)次的浮点运算,
一个TFLOPS(teraFLOPS)等於每秒万亿(=10^12)次的浮点运算,
一个PFLOPS(petaFLOPS)等於每秒千万亿(=10^15)次的浮点运算,
一个EFLOPS(exaFLOPS)等於每秒百亿亿(=10^18)次的浮点运算
一个ZFLOPS(zettaFLOPS)等于每秒十万京(=10^21)次的浮点运算。
这是因为,几乎所有的科学运算,都是浮点运算。
cpu算力计算公式
FLOAS=核数*单核主频*CPU单个周期浮点计算值
核数:cpu参数中有表明
单核主频:cpu参数中有表明
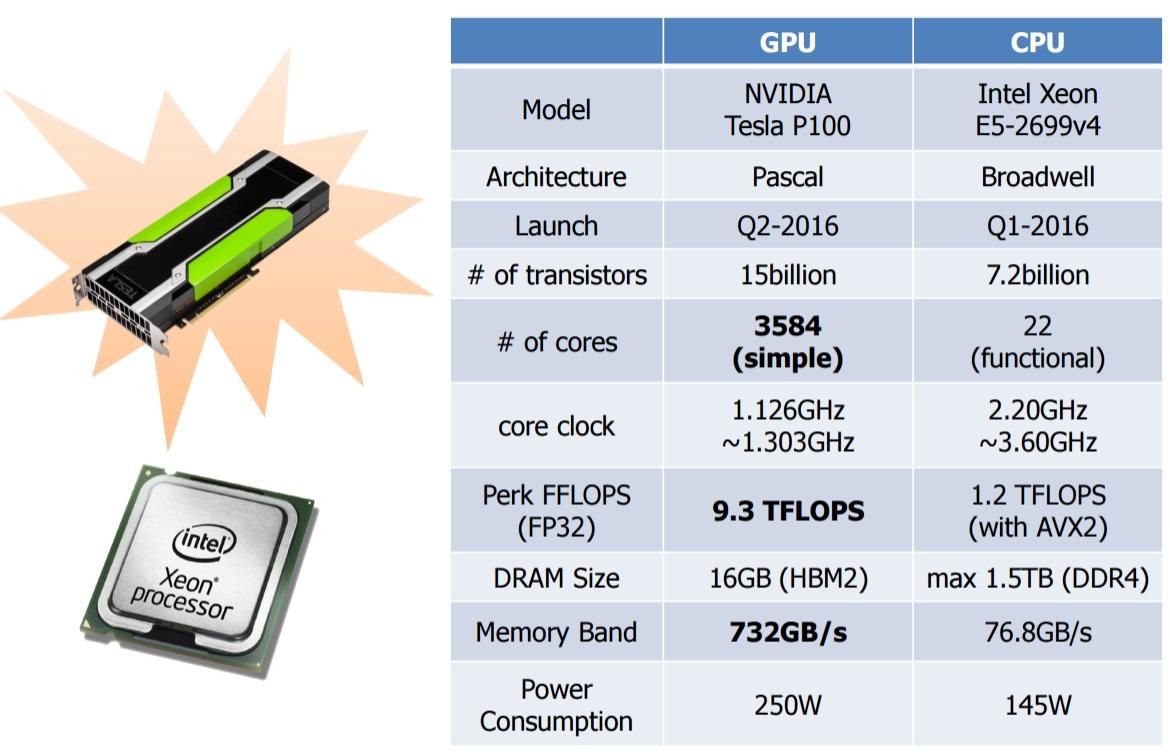
在上图中, CPU是1.2TFLOPS, GPU是9.3TFLOPS, GPU的浮点处理能力是CPU的8倍。
以上是关于[架构之路-12]:目标系统 - 硬件平台 - 单核CPU的架构与基本工作原理的主要内容,如果未能解决你的问题,请参考以下文章