12W字;2022最新Android11位大厂面试专题腾讯篇
Posted 初一十五啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了12W字;2022最新Android11位大厂面试专题腾讯篇相关的知识,希望对你有一定的参考价值。
由于近期很多小伙伴开始面试了,所以在大量的刷题,也有很多问到我有没有一些大厂面试题或者常见的面试题,字节参考一下,于是乎花了一周时间整理出这份 《2022android十一位大厂面试真题》 结合之前的 《腾讯Android开发笔记》 也算是双管齐下了!😃
字数限制,分几篇更。可以关注公众号:初一十五a提前解锁
三丶腾讯篇
1.MVVM, MVP,MVC
①MVC
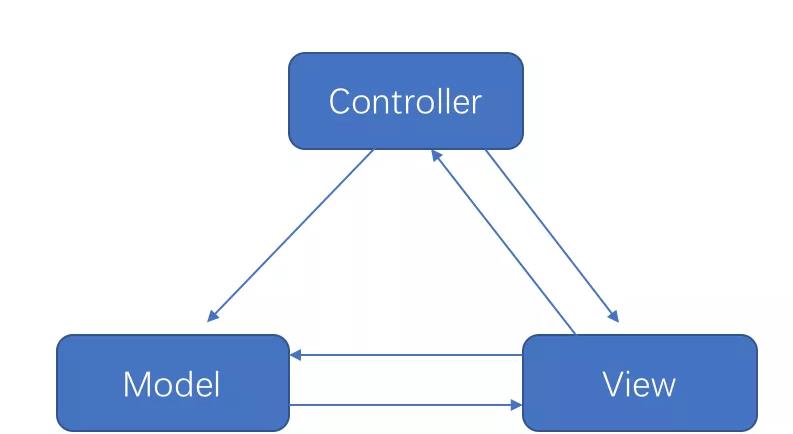
在 Android 中,三者的关系如下:
!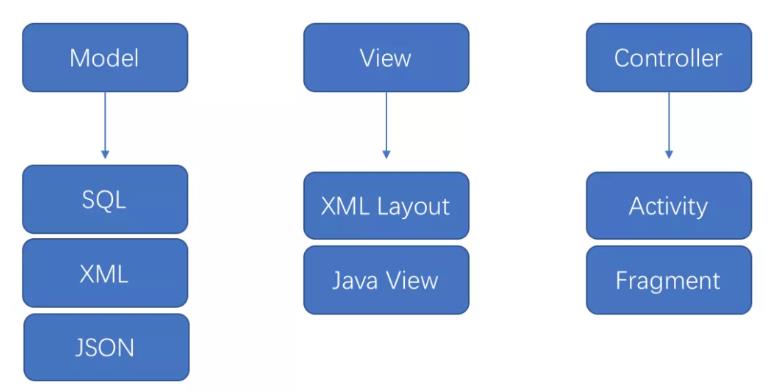
由于在 Android 中 xml 布局的功能性太弱,所以 Activity 承担了绝大部分的工作,所以在 Android 中 mvc 更像:

总结:
- 具有一定的分层,model 解耦,controller 和 view 并没有解耦
- controller 和 view 在 Android 中无法做到彻底分离,Controller 变得臃肿不堪
- 易于理解、开发速度快、可维护性高
②MVP
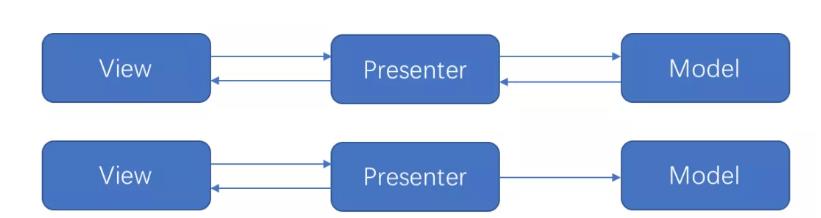
通过引入接口 BaseView,让相应的视图组件如 Activity,Fragment去实现 BaseView,把业务逻辑放在 presenter 层中,弱化 Model 只有跟 view 相关的操作都由 View 层去完成。
总结:
- 彻底解决了 MVC 中 View 和 Controller 傻傻分不清楚的问题
- 但是随着业务逻辑的增加,一个页面可能会非常复杂,UI 的改变是非常多,会有非常多的 case,这样就会造成 View 的接口会很庞大
- 更容易单元测试
③MVVM
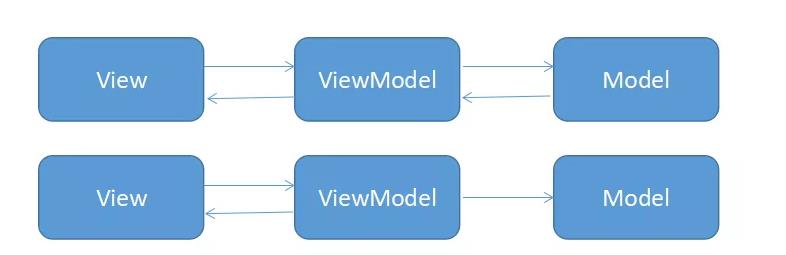
在 MVP 中 View 和 Presenter 要相互持有,方便调用对方,而在 MVP 中 View 和 ViewModel 通过 Binding 进行关联,他们之前的关联处理通过 DataBinding 完成。
总结:
- 很好的解决了 MVC 和 MVP 的问题
- 视图状态较多,ViewModel 的构建和维护的成本都会比较高
- 但是由于数据和视图的双向绑定,导致出现问题时不太好定位来源
2.LiveData 处理事件最佳实践
前言
在 使用 Jetpack 组件的 MVVM 架构项目开发中,View (Activity / Fragement) 通常使用 LiveData 这种可观察数据来 跟 ViewMdoel 通讯。这种机制通常对于用来做数据「展示」非常有效(例如展示用户姓名、头像等)
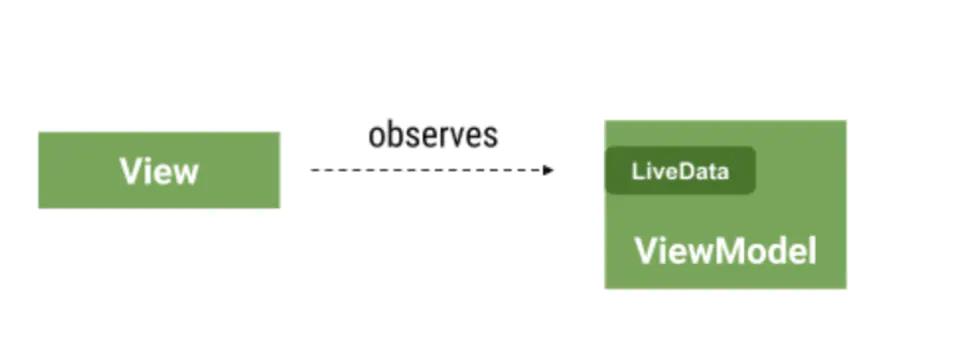
但是有些数据是只应该被 「消费一次」,例如展示一次 toast,一次界面跳转或者 Dialog 展示。这种数据准确来说是属于 「事件」
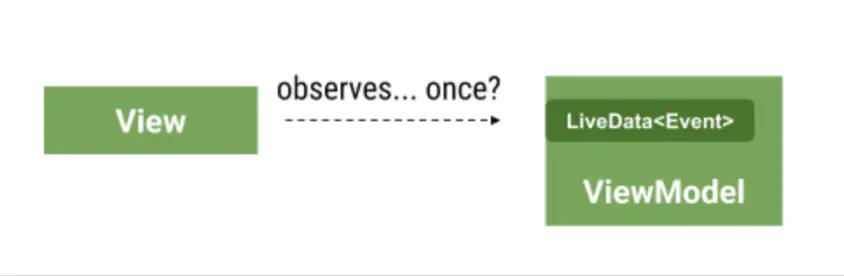
我们建议把 Event(事件) 当作 Status(状态) 一部分。在本文中,我们将介绍一些常见的错误和推荐的方法。
技术方案分析 & 对比
以用户登陆场景为例, 在登陆界面 LoginActivity 点击登录按钮, 执行 ViewModel 中的 doLoginRequest, 然后将登陆结果存在 LiveData 中, LoginActivity 监听 这个 LiveData 做界面跳转。
❌ BAD 用法 1
class LoginModel : ViewModel
private val _loginResult = MutableLiveData<Boolean>()
val loginResult : LiveData<Boolean>
get() = _loginResult
fun doLoginRequest()
//do login networl request
_loginResult.value = true
//In the View (activity or fragment):
loginModel.navigateToDetails.observe(this, Observer
//login success, jump to HomeActivity
if (it)
startActivity(HomeActivity...)
)
问题: _ loginResult 中的值在很长时间内保持为 true ,导致不可能再返回到登录页面。我们一步一步来复现这个问题:
1、 用户在 LoginActivity 点击登录按钮跳转到 HomeActivity
2、 用户按返回键回到LoginActivity
3、 此时旋转屏幕
4、 观察者变为可见状态,但是由于ViewModel的 loginResult 仍为 true,LoginActivity又会启动 HomeActivity
❌ Better 做法 2 在观察者中重置 LiveData 值
class LoginModel : ViewModel
private val _loginResult = MutableLiveData<Boolean>()
val loginResult : LiveData<Boolean>
get() = _loginResult
fun doLoginRequest()
//do login networl request
_loginResult.value = true
fun navigateToHomeHandled()
_loginResult.value = false
//In the View (activity or fragment):
loginModel.navigateToHome.observe(this, Observer
//login success, jump to HomeActivity
if (it)
//跳转之前重置 LiveData的值
loginModel.navigateToHomeHandled()
startActivity(HomeActivity...)
)
问题:这种方法的问题在于有一些样板文件(ViewModel 中对于每个Event 都添加了一个新方法) ,并且容易出错, 观察者很容易忘记对 ViewModel 的调用。
✔️ OK: 使用 SingleLiveEvent
SingleLiveEvent 作为适用于该特定场景的解决方案。这是一个只会发送一次更新的 LiveData。
class SingleLiveEvent<T> : MutableLiveData<T>()
private val mPending = AtomicBoolean(false)
override fun observe(owner: LifecycleOwner, observer: Observer<in T>)
super.observe(owner) t ->
if (mPending.compareAndSet(true, false))
observer.onChanged(t)
@MainThread
override fun setValue(t: T?)
mPending.set(true)
super.setValue(t)
/**
* Used for cases where T is Void, to make calls cleaner.
*/
@MainThread
fun call()
value = null
class LoginModel : ViewModel
private val _loginResult = SingleLiveEvent<Any>()
val loginResult : LiveData<Any>
get() = _loginResult
fun doLoginRequest()
//do login network request
...
_loginResult.call()
//In the View (activity or fragment):
loginModel.navigateToHome.observe(this, Observer
//login success, do something
)
loginModel.navigateToHome.observe(this, Observer
//由于上面其他observer观察了数据,导致这里可能不会被执行
startActivity(HomeActivity...)
)
问题:
SingleLiveEvent 的问题在于它只限于一个观察者。如果无意中添加了多个观察者,那么只会调用一个,并且不能保证是哪一个观察者得到调用。
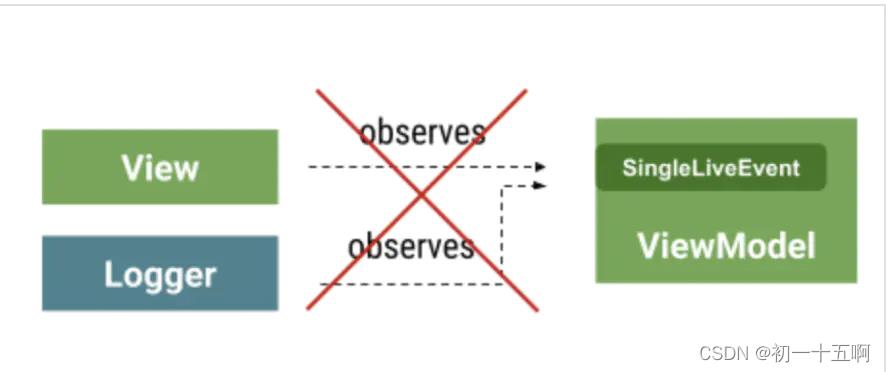
✔️ 推荐: 使用 Event Wrapper
在这种方法中,我们可以明确地管理事件是否已被处理,从而减少错误
open class Event<out T>(private val content: T)
var hasBeenHandled = false
private set // Allow external read but not write
fun getContentIfNotHandled(): T?
return if (hasBeenHandled)
null
else
hasBeenHandled = true
content
fun peekContent(): T = content
class LoginModel : ViewModel
private val _loginResult = MutableLiveData<Event<Boolean>>()
val loginResult : LiveData<Any>
get() = _loginResult
fun doLoginRequest()
//do login network request
...
_loginResult.value = Event(true)
//In the View (activity or fragment):
loginModel.navigateToHome.observe(this, Observer
//login success, jump to HomeActivity
//只有事件从未被处理时才会有值
it.getContentIfNotHandled()?.let
startActivity(DetailsActivity...)
)
特点: 这个方法将事件作为状态的一部分进行建模: 它们现在只是一条消息,不管是否已经被使用。允许多个观察者观察,用户可以使用 getContentIfNotHandled ()或 peekContent ()来决定做什么样的业务处理。
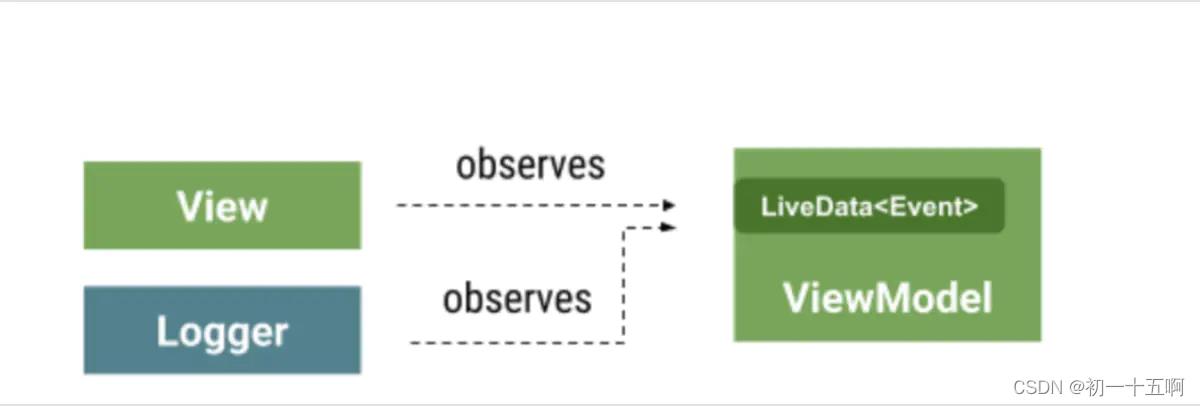
总结
本文从代码设计、易用性、功能支持 等角度分析了LiveData 用于处理 「事件」时的一些技术方案的对比, 推荐使用 EventWrapper 这种 最佳实践 的方式来对 LiveData 的 事件做处理。

3.Handler,messageQueue懂多少说多少,越详细越好
参考第二章第三模块
4.View绘制的三个流程;
参考前面
5.内存泄漏常见场景以及解决方案?
参考第二章第八题
6.项目里的webView是如何优化加载速度的的
WebView性能优化问题:
导致WebView加载页面慢的原因:加载的过程中都会有较多的网络请求,除了 web 页面自身的 URL 请求,还会有 web 页面外部引用的JS、CSS、字体、图片等等都是个独立的 http 请求。这些请求都是串行的,这些请求加上浏览器的解析、渲染时间就会导致 WebView 整体加载时间变长。
解决方案:
-
首次加载优化:直接将常用的 JS 脚本本地化,放入 asserts 文件夹,在 WebView 调用了onPageFinished() 方法后进行加载。
-
二次加载优化:
合理使用缓存机制,打开 DomStorage 开关;Application Cache 存储机制;Indexed Database 存储机制;File System API -
延迟JS脚本载入,待到显现完页面后再出发脚本执行
-
使用第三方 WebView 内核,如微信的X5内核。
关于WebView内存泄漏的问题:由于webview的OOMM主要来自其宿主Activity,所以让WebView 开启另外一个进程,通过 AIDL 与主进程进行通信,WebView 所在的进程可以根据业务的需要选择合适的时机进行销毁,从而达到内存的完整释放。
7.RecyclerView和ScrollView为什么不能一起使用
在我们日常开发中经常会用到ScrollView与RecyclerView的组合,但是这种组合有时会出现滑动不流畅的问题,也就是卡顿现象
布局如下 :
<ScrollView
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent">
<LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical">
<android.support.v7.widget.RecyclerView
android:layout_width="match_parent"
android:layout_height="match_parent"
android:id="@+id/recyclerView">
</android.support.v7.widget.RecyclerView>
</LinearLayout>
</ScrollView>
我们只需要给RecyclerView设置下面两个属性就可以了
注意:(如果是多个RecyclerView,每个都需要设置,并不是设置一个就行了)
//解决滑动冲突、滑动不流畅
recyclerView.setHasFixedSize(true);
recyclerView.setNestedScrollingEnabled(false);
8.Synchronized锁升级原理与过程深入剖析
①工具准备
在正式谈synchronized的原理之前我们先谈一下自旋锁,因为在synchronized的优化当中自旋锁发挥了很大的作用。而需要了解自旋锁,我们首先需要了解什么是原子性。
所谓原子性简单说来就是一个一个操作要么不做要么全做,全做的意思就是在操作的过程当中不能够被中断,比如说对变量data进行加一操作,有以下三个步骤:
- 将
data从内存加载到寄存器。 - 将
data这个值加一。 - 将得到的结果写回内存。
原子性就表示一个线程在进行加一操作的时候,不能够被其他线程中断,只有这个线程执行完这三个过程的时候其他线程才能够操作数据data。
我们现在用代码体验一下,在Java当中我们可以使用AtomicInteger进行对整型数据的原子操作:
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicDemo
public static void main(String[] args) throws InterruptedException
AtomicInteger data = new AtomicInteger();
data.set(0); // 将数据初始化位0
Thread t1 = new Thread(() ->
for (int i = 0; i < 100000; i++)
data.addAndGet(1); // 对数据 data 进行原子加1操作
);
Thread t2 = new Thread(() ->
for (int i = 0; i < 100000; i++)
data.addAndGet(1);// 对数据 data 进行原子加1操作
);
// 启动两个线程
t1.start();
t2.start();
// 等待两个线程执行完成
t1.join();
t2.join();
// 打印最终的结果
System.out.println(data); // 200000
从上面的代码分析可以知道,如果是一般的整型变量如果两个线程同时进行操作的时候,最终的结果是会小于200000。
我们现在来模拟一下一般的整型变量出现问题的过程:
- 主内存data的初始值等于0,两个线程得到的data初始值都等于0。

- 现在线程一将data加一,然后线程一将data的值同步回主内存,整个内存的数据变化如下:

- 现在线程二data加一,然后将data的值同步回主内存(将原来主内存的值覆盖掉了):
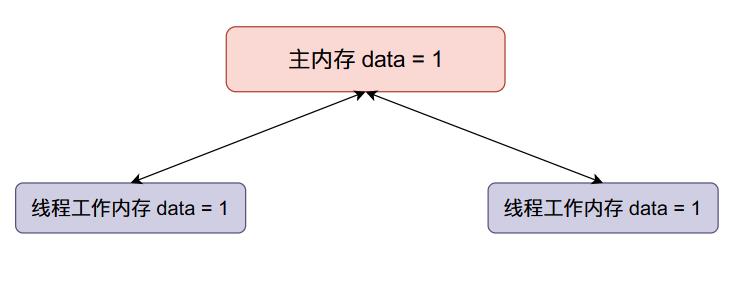
我们本来希望data的值在经过上面的变化之后变成2,但是线程二覆盖了我们的值,因此在多线程情况下,会使得我们最终的结果变小。
但是在上面的程序当中我们最终的输出结果是等于20000的,这是因为给data进行+1的操作是原子的不可分的,在操作的过程当中其他线程是不能对data进行操作的。这就是原子性带来的优势。
事实上上面的+1原子操作就是通过自旋锁实现的,我们可以看一下AtomicInteger的源代码:
public final int addAndGet(int delta)
// 在 AtomicInteger 内部有一个整型数据 value 用于存储具体的数值的
// 这个 valueOffset 表示这个数据 value 在对象 this (也就是 AtomicInteger一个具体的对象)
// 当中的内存偏移地址
// delta 就是我们需要往 value 上加的值 在这里我们加上的是 1
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
上面的代码最终是调用UnSafe类的方法进行实现的,我们再看一下他的源代码:
public final int getAndAddInt(Object o, long offset, int delta)
int v;
do
v = getIntVolatile(o, offset); // 从对象 o 偏移地址为 offset 的位置取出数据 value ,也就是前面提到的存储整型数据的变量
while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
上面的代码主要流程是不断的从内存当中取对象内偏移地址为offset的数据,然后执行语句!compareAndSwapInt(o, offset, v, v + delta)
这条语句的主要作用是:比较对象o内存偏移地址为offset的数据是否等于v,如果等于v则将偏移地址为offset的数据设置为v + delta,如果这条语句执行成功返回 true否则返回false,这就是我们常说的Java当中的CAS。
看到这里你应该就发现了当上面的那条语句执行不成功的话就会一直进行while循环操作,直到操作成功之后才退出while循环,假如没有操作成功就会一直“旋”在这里,像这种操作就是自旋,通过这种自旋方式所构成的锁🔒就叫做自旋锁。
②对象的内存布局
在JVM当中,一个Java对象的内存主要有三块:
- 对象头,对象头包含两部分数据,分别是Mark word和类型指针(Kclass pointer)。
- 实例数据,就是我们在类当中定义的各种数据。
- 对齐填充,JVM在实现的时候要求每一个对象所占有的内存大小都需要是8字节的整数倍,如果一个对象的数据所占有的内存大小不够8字节的整数倍,那就需要进行填充,补齐到8字节,比如说如果一个对象站60字节,那么最终会填充到64字节。
而与我们要谈到的synchronized锁升级原理密切相关的是Mark word,这个字段主要是存储对象运行时的数据,比如说对象的Hashcode、GC的分代年龄、持有锁的线程等等。而Kclass pointer主要是用于指向对象的类,主要是表示这个对象是属于哪一个类,主要是寻找类的元数据。
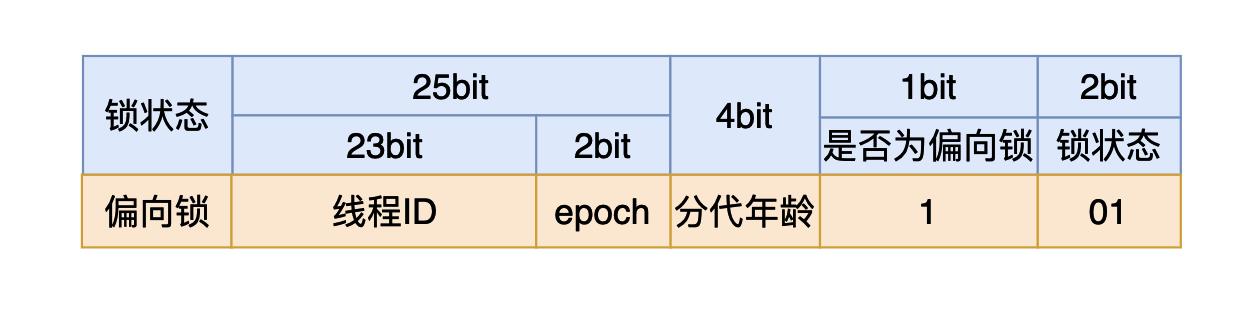
在32位Java虚拟机当中Mark word有4个字节一共32个比特位,其内容如下:

我们在使用synchronized时,如果我们是将synchronized用在同步代码块,我们需要一个锁对象。对于这个锁对象来说一开始还没有线程执行到同步代码块时,这个4个字节的内容如上图所示,其中有25个比特用来存储哈希值,4个比特用来存储垃圾回收的分代年龄(如果不了解可以跳过),剩下三个比特其中第一个用来表示当前的锁状态是否为偏向锁,最后的两个比特表示当前的锁是哪一种状态:
- 如果最后三个比特是:001,则说明锁状态是没有锁。
- 如果最后三个比特是:101,则说明锁状态是偏向锁。
- 如果最后两个比特是:00, 则说明锁状态是轻量级锁。
- 如果最后两个比特是:10, 则说明锁状态是重量级锁。
而synchronized锁升级的顺序是:无🔒->偏向🔒->轻量级🔒->重量级🔒。
在Java当中有一个JVM参数用于设置在JVM启动多少秒之后开启偏向锁(JDK6之后默认开启偏向锁,JVM默认启动4秒之后开启对象偏向锁,这个延迟时间叫做偏向延迟,你可以通过下面的参数进行控制):
//设置偏向延迟时间 只有经过这个时间只有对象锁才会有偏向锁这个状态
-XX:BiasedLockingStartupDelay=4
//禁止偏向锁
-XX:-UseBiasedLocking
//开启偏向锁
-XX:+UseBiasedLocking
我们可以用代码验证一下在无锁状态下,MarkWord的内容是什么:
import org.openjdk.jol.info.ClassLayout;
import java.util.concurrent.TimeUnit;
public class MarkWord
public Object o = new Object();
public synchronized void demo()
synchronized (o)
System.out.println("synchronized代码块内");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
public static void main(String[] args) throws InterruptedException
System.out.println("等待4s前");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
TimeUnit.SECONDS.sleep(4);
MarkWord markWord = new MarkWord();
System.out.println("等待4s后");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
Thread thread = new Thread(markWord::demo);
thread.start();
thread.join();
System.out.println(ClassLayout.parseInstance(markWord.o).toPrintable());
上面代码输出结果,下面的红框框住的表示是否是偏向锁和锁标志位(可能你会有疑问为什么是这个位置,不应该是最后3个比特位表示锁相关的状态吗,这个其实是数据表示的大小端问题,大家感兴趣可以去查一下,在这你只需知道红框三个比特就是用于表示是否为偏向锁和锁的标志位):
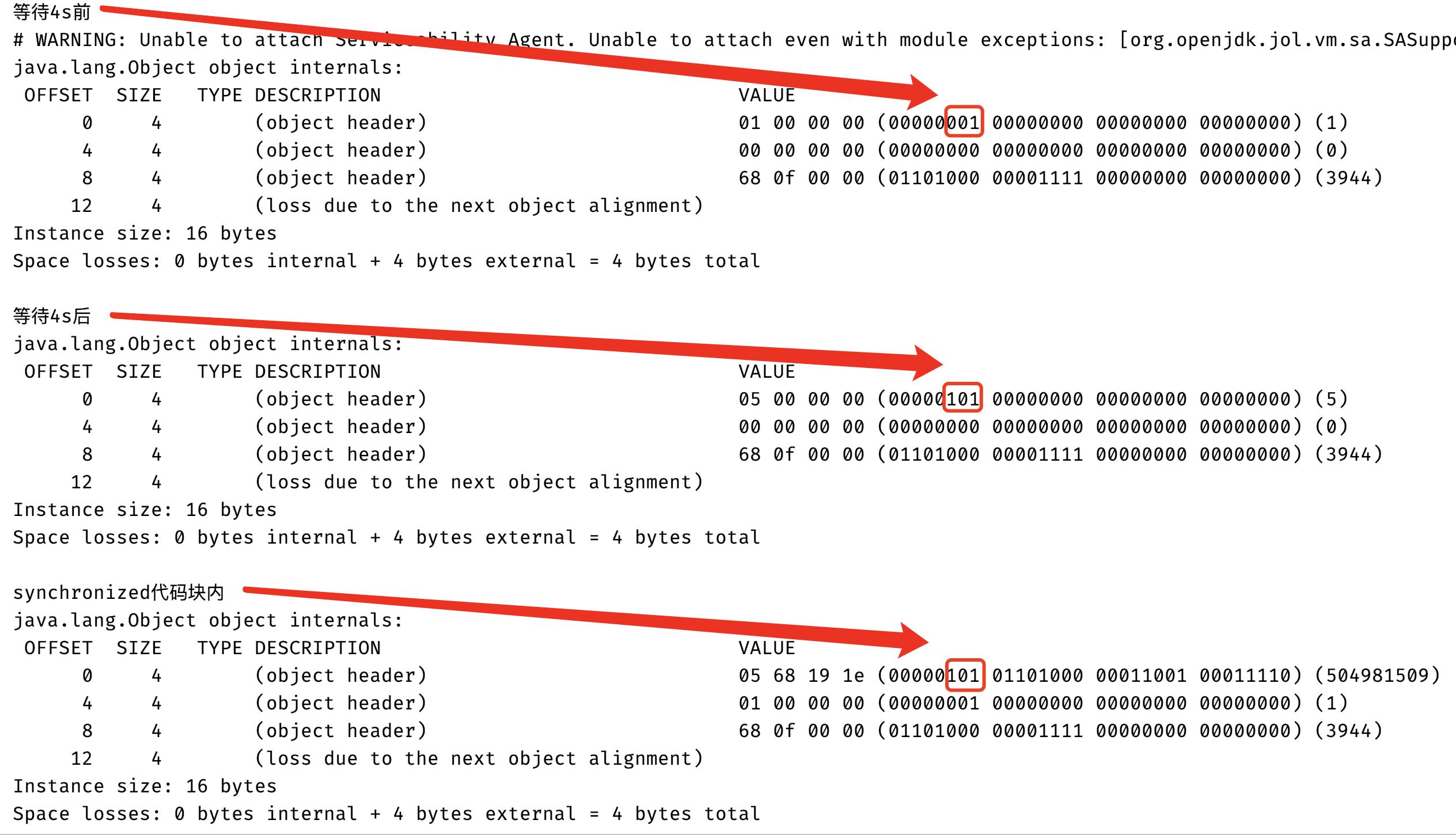
从上面的图当中我们可以分析得知在偏向延迟的时间之前,对象锁的状态还不会有偏向锁,因此对象头中的Markword当中锁状态是01,同时偏向锁状态是0,表示这个时候是无锁状态,但是在4秒之后偏向锁的状态已经变成1了,因此当前的锁状态是偏向锁,但是还没有线程占有他,这种状态也被称作匿名偏向,因为在上面的代码当中只有一个线程进入了synchronized同步代码块,因此可以使用偏向锁,因此在synchronized代码块当中打印的对象的锁状态也是偏向锁。
上面的代码当中使用到了jol包,你需要在你的pom文件当中引入对应的包:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
上图当中我们显示的结果是在64位机器下面显示的结果,在64位机器当中在Java对象头当中的MarkWord和Klcass Pointer内存布局如下:

其中MarkWord占8个字节,Kclass Pointer占4个字节。JVM在64位和32位机器上的MarkWord内容基本一致,64位机器上和32位机器上的MarkWord内容和表示意义是一样的,因此最后三位的意义你可以参考32位JVM的MarkWord。
③锁升级过程
偏向锁
假如你写的synchronized代码块没有多个线程执行,而只有一个线程执行的时候这种锁对程序性能的提高还是非常大的。他的具体做法是JVM会将对象头当中的第三个用于表示是否为偏向锁的比特位设置为1,同时会使用CAS操作将线程的ID记录到Mark Word当中,如果操作成功就相当于获得🔒了,那么下次这个线程想进入临界区就只需要比较一下线程ID是否相同了,而不需要进行CAS或者加锁这样花费比较大的操作了,只需要进行一个简单的比较即可,这种情况下加锁的开销非常小。
可能你会有一个疑问在无锁的状态下Mark Word存储的是哈希值,而在偏向锁的状态下存储的是线程的ID,那么之前存储的Hash Code不就没有了嘛!你可能会想没有就没有吧,再算一遍不就行了!事实上不是这样,如果我们计算过哈希值之后我们需要尽量保持哈希值不变(但是这个在Java当中并没有强制,因为在Java当中可以重写hashCode方法),因此在Java当中为了能够保持哈希值的不变性就会在第一次计算一致性哈希值(Mark Word里面存储的是一致性哈希值,并不是指重写的hashCode返回值,在Java当中可以通过 Object.hashCode()或者System.identityHashCode(Object)方法计算一致性哈希值)的时候就将计算出来的一致性哈希值存储到Mark Word当中,下一次再有一致性哈希值的请求的时候就将存储下来的一致性哈希值返回,这样就可以保证每次计算的一致性哈希值相同。但是在变成偏向锁的时候会使用线程ID覆盖哈希值,因此当一个对象计算过一致性哈希值之后,他就再也不能进行偏向锁状态,而且当一个对象正处于偏向锁状态的时候,收到了一致性哈希值的请求的时候,也就是调用上面提到的两个方法,偏向锁就会立马膨胀为重量级锁,然后将Mark Word 储在重量级锁里。
下面的代码就是验证当在偏向锁的状态调用System.identityHashCode函数锁的状态就会升级为重量级锁:
import org.openjdk.jol.info.ClassLayout;
import java.util.concurrent.TimeUnit;
public class MarkWord
public Object o = new Object();
public synchronized void demo()
System.out.println("System.identityHashCode(o) 函数之前");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
synchronized (o)
System.identityHashCode(o);
System.out.println("System.identityHashCode(o) 函数之后");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
public static void main(String[] args) throws InterruptedException
TimeUnit.SECONDS.sleep(5);
MarkWord markWord = new MarkWord();
Thread thread = new Thread(markWord::demo);
thread.start();
thread.join();
TimeUnit.SECONDS.sleep(2);
System.out.println(ClassLayout.parseInstance(markWord.o).toPrintable());
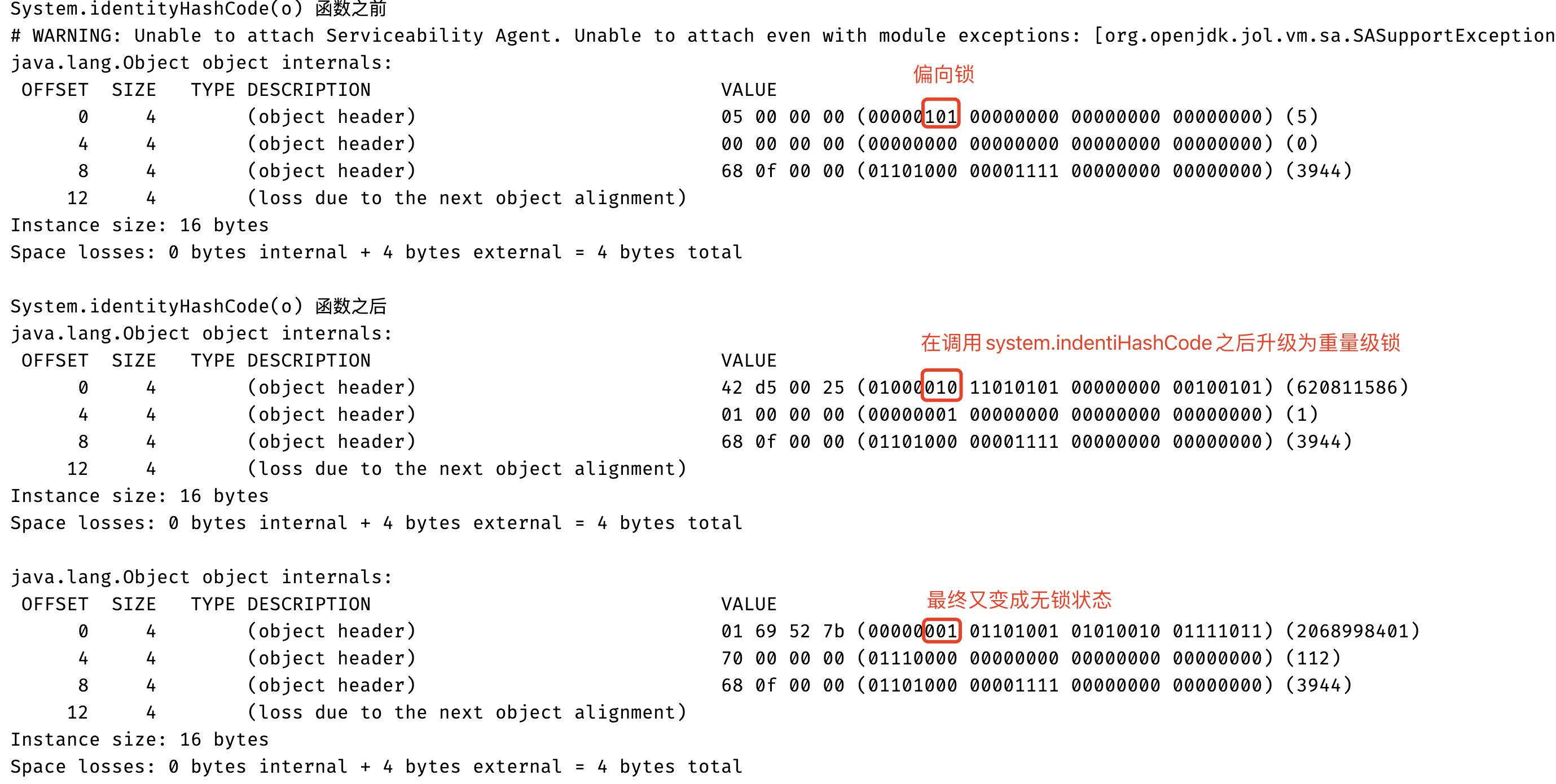
轻量级锁
轻量级锁也是在JDK1.6加入的,当一个线程获取偏向锁的时候,有另外的线程加入锁的竞争时,这个时候就会从偏向锁升级为轻量级锁。
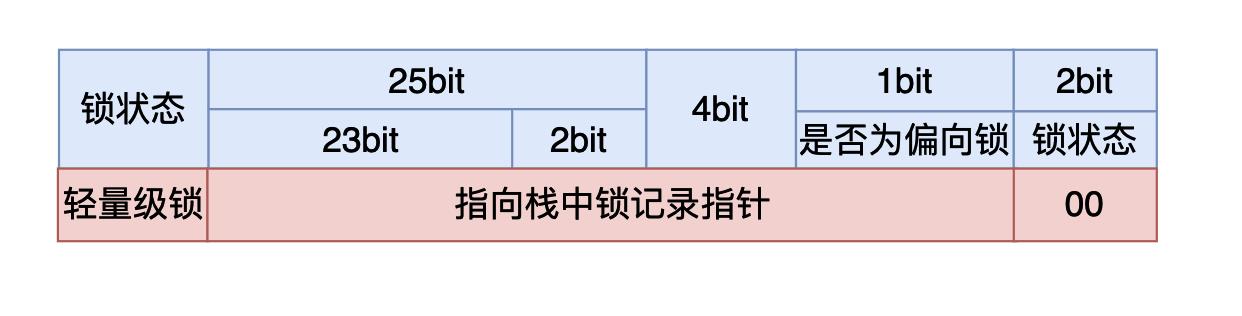
在轻量级锁的状态时,虚拟机首先会在当前线程的栈帧当中建立一个锁记录(Lock Record),用于存储对象MarkWord的拷贝,官方称这个为Displaced Mark Word。然后虚拟机会使用CAS操作尝试将对象的MarkWord指向栈中的Lock Record,如果操作成功说明这个线程获取到了锁,能够进入同步代码块执行,否则说明这个锁对象已经被其他线程占用了,线程就需要使用CAS不断的进行获取锁的操作,当然你可能会有疑问,难道就让线程一直死循环了吗?这对CPU的花费那不是太大了吗,确实是这样的因此在CAS满足一定条件的时候轻量级锁就会升级为重量级锁,具体过程在重量级锁章节中分析。
当线程需要从同步代码块出来的时候,线程同样的需要使用CAS将Displaced Mark Word替换回对象的MarkWord,如果替换成功,那么同步过程就完成了,如果替换失败就说明有其他线程尝试获取该锁,而且锁已经升级为重量级锁,此前竞争锁的线程已经被挂起,因此线程在释放锁的同时还需要将挂起的线程唤醒。
重量级锁
所谓重量级锁就是一种开销最大的锁机制,在这种情况下需要操作系统将没有进入同步代码块的线程挂起,JVM(Linux操作系统下)底层是使用pthread_mutex_lock、pthread_mutex_unlock、pthread_cond_wait、pthread_cond_signal和pthread_cond_broadcast这几个库函数实现的,而这些函数依赖于futex系统调用,因此在使用重量级锁的时候因为进行了系统调用,进程需要从用户态转为内核态将线程挂起,然后从内核态转为用户态,当解锁的时候又需要从用户态转为内核态将线程唤醒,这一来二去的花费就比较大了(和CAS自旋锁相比)。

在有两个以上的线程竞争同一个轻量级锁的情况下,轻量级锁不再有效(轻量级锁升级的一个条件),这个时候锁为膨胀成重量级锁,锁的标志状态变成10,MarkWord当中存储的就是指向重量级锁的指针,后面等待锁的线程就会被挂起。
因为这个时候MarkWord当中存储的已经是指向重量级锁的指针,因此在轻量级锁的情况下进入到同步代码块在出同步代码块的时候使用CAS将Displaced Mark Word替换回对象的MarkWord的时候就会替换失败,在前文已经提到,在失败的情况下,线程在释放锁的同时还需要将被挂起的线程唤醒。
④总结
在本篇文章当中我们主要介绍了synchronized内部锁升级的原理,具体的锁升级的过程是:无🔒->偏向🔒->轻量级🔒->重量级🔒。
- 无锁:这是没有开启偏向锁的时候的状态,在JDK1.6之后偏向锁的默认开启的,但是有一个偏向延迟,需要在JVM启动之后的多少秒之后才能开启,这个可以通过JVM参数进行设置,同时是否开启偏向锁也可以通过JVM参数设置。
- 偏向锁:这个是在偏向锁开启之后的锁的状态,如果还没有一个线程拿到这个锁的话,这个状态叫做匿名偏向,当一个线程拿到偏向锁的时候,下次想要竞争锁只需要拿线程ID跟MarkWord当中存储的线程ID进行比较,如果线程ID相同则直接获取锁(相当于锁偏向于这个线程),不需要进行CAS操作和将线程挂起的操作。
- 轻量级锁:在这个状态下线程主要是通过CAS操作实现的。将对象的MarkWord存储到线程的虚拟机栈上,然后通过CAS将对象的MarkWord的内容设置为指向Displaced Mark Word的指针,如果设置成功则获取锁。在线程出临界区的时候,也需要使用CAS,如果使用CAS替换成功则同步成功,如果失败表示有其他线程在获取锁,那么就需要在释放锁之后将被挂起的线程唤醒。
- 重量级锁:当有两个以上的线程获取锁的时候轻量级锁就会升级为重量级锁,因为CAS如果没有成功的话始终都在自旋,进行while循环操作,这是非常消耗CPU的,但是在升级为重量级锁之后,线程会被操作系统调度然后挂起,这可以节约CPU资源。
9.HashMap的实现原理
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出现在各类的面试题中,重要性可见一斑。
本文会对java集合框架中的对应实现HashMap的实现原理进行讲解,然后会对JDK7的HashMap源码进行分析(JDK8会有所不同,需要了解的可自行阅读JDK8的HashMap源码)。
JDK7和JDK8中HashMap的大致变化是(这其实也是一个常被问道的面试题~):
1.7中采用数组+链表,1.8采用的是数组+链表/红黑树,即在1.7中链表长度超过一定长度后就改成红黑树存储。
1.7扩容时需要重新计算哈希值和索引位置,1.8并不重新计算哈希值,巧妙地采用和扩容后容量进行&操作来计算新的索引位置。
1.7是采用表头插入法插入链表,1.8采用的是尾部插入法。
在1.7中采用表头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题;在1.8中采用尾部插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
目录
- 什么是哈希表
- HashMap实现原理
- 为何HashMap的数组长度一定是2的次幂?
- 重写equals方法需同时重写hashCode方法
- 总结
①什么是哈希表
在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
数组: 采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表: 对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树: 对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表: 相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
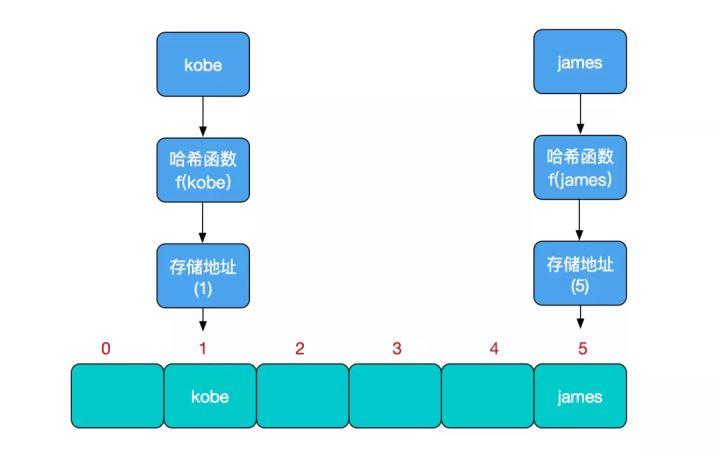
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。
前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。
那么哈希冲突如何解决呢? 哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式,
②HashMap实现原理
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
//HashMap的主干数组,可以看到就是一个Entry数组,初始值为空数组,主干数组的长度一定是2的次幂,至于为什么这么做,后面会有详细分析。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry是HashMap中的一个静态内部类。代码如下
static class Entry<K,V> implements Map.Entry<K,V>
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n)
value = v;
next = n;
key = k;
hash = h;
所以,HashMap的整体结构如下
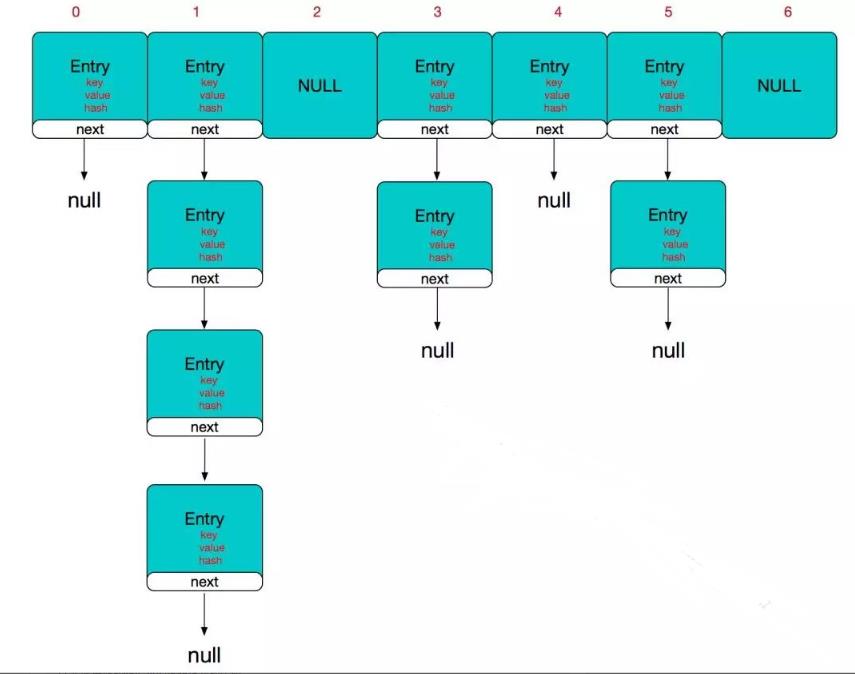
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
其他几个重要字段
//实际存储的key-value键值对的个数
transient int size;
//阈值,当table == 时,该值为初始容量(初始容量默认为16);当table被填充了,也就是为table分配内存空间后,threshold一般为 capacity*loadFactory。HashMap在进行扩容时需要参考threshold,后面会详细谈到
int threshold;
//负载因子,代表了table的填充度有多少,默认是0.75
final float loadFactor;
//用于快速失败,由于HashMap非线程安全,在对HashMap进行迭代时,如果期间其他线程的参与导致HashMap的结构发生变化了(比如put,remove等操作),需要抛出异常ConcurrentModificationException
transient int modCount;
HashMap有4个构造器,其他构造器如果用户没有传入initialCapacity 和loadFactor这两个参数,会使用默认值
initialCapacity默认为16,loadFactory默认为0.75
我们看下其中一个
public HashMap(int initialCapacity, float loadFactor)
//此处对传入的初始容量进行校验,最大不能超过MAXIMUM_CAPACITY = 1<<30(230)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//init方法在HashMap中没有实际实现,不过在其子类如 linkedHashMap中就会有对应实现
从上面这段代码我们可以看出,在常规构造器中,没有为数组table分配内存空间(有一个入参为指定Map的构造器例外),而是在执行put操作的时候才真正构建table数组
OK,接下来我们来看看put操作的实现吧
public V put(K key, V value)
//如果table数组为空数组,进行数组填充(为table分配实际内存空间),入参为threshold,此时threshold为initialCapacity 默认是1<<4(24=16)
if (table == EMPTY_TABLE)
inflateTable(threshold);
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置
for (Entry<K,V> e = table[i]; e != null; e = e.next)
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);//新增一个entry
return null;
先来看看inflateTable这个方法
private void inflateTable(int toSize)
int capacity = roundUpToPowerOf2(toSize);//capacity一定是2的次幂
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//此处为threshold赋值,取capacity*loadFactor和MAXIMUM_CAPACITY+1的最小值,capaticy一定不会超过MAXIMUM_CAPACITY,除非loadFactor大于1
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
inflateTable这个方法用于为主干数组table在内存中分配存储空间,通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于toSize的最接近toSize的二次幂,比如toSize=13,capacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
private static int roundUpToPowerOf2(int number)
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
roundUpToPowerOf2中的这段处理使得数组长度一定为2的次幂,Integer.highestOneBit是用来获取最左边的bit(其他bit位为0)所代表的数值.
hash函数
//这是一个神奇的函数,用了很多的异或,移位等运算,对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀
final int hash(Object k)
int h = hashSeed;
if (0 != h && k instanceof String)
return sun.misc.Hashing.stringHash32((String) k);
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
以上hash函数计算出的值,通过indexFor进一步处理来获取实际的存储位置
/**
* 返回数组下标
*/
static int indexFor(int h, int length)
return h & (length-1);
h&(length-1)保证获取的index一定在数组范围内,举个例子,默认容量16,length-1=15,h=18,转换成二进制计算为
1 0 0 1 0
& 0 1 1 1 1
__________________
0 0 0 1 0 = 2
最终计算出的index=2。有些版本的对于此处的计算会使用 取模运算,也能保证index一定在数组范围内,不过位运算对计算机来说,性能更高一些(HashMap中有大量位运算)
所以最终存储位置的确定流程是这样的:

再来看看addEntry的实现:
void addEntry(int hash, K key, V value, int bucketIndex)
if ((size >= threshold) && (null != table[bucketIndex]))
resize(2 * table.length);//当size超过临界阈值threshold,并且即将发生哈希冲突时进行扩容
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
createEntry(hash, key, value, bucketIndex);
通过以上代码能够得知,当发生哈希冲突并且size大于阈值的时候,需要进行数组扩容,扩容时,需要新建一个长度为之前数组2倍的新的数组,然后将当前的Entry数组中的元素全部传输过去,扩容后的新数组长度为之前的2倍,所以扩容相对来说是个耗资源的操作。
③为何HashMap的数组长度一定是2的次幂?
我们来继续看上面提到的resize方法
void resize(int newCapacity)
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY)
threshold = Integer.MAX_VALUE;
return;
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
如果数组进行扩容,数组长度发生变化,而存储位置 index = h&(length-1),index也可能会发生变化,需要重新计算index,我们先来看看transfer这个方法
void transfer(Entry[] newTable, boolean rehash)
int newCapacity = newTable.length;
//for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已)
for (Entry<K,V> e : table)
while(null != e)
Entry<K,V> next = e.next;
if (rehash)
e.hash = null == e.key ? 0 : hash(e.key);
int i = indexFor(e.hash, newCapacity);
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
e.next = newTable[i];
newTable[i] = e;
e = next;
这个方法将老数组中的数据逐个链表地遍历,扔到新的扩容后的数组中,我们的数组索引位置的计算是通过 对key值的hashcode进行hash扰乱运算后,再通过和 length-1进行位运算得到最终数组索引位置。
hashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。
从下图可以我们也能看到这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了之前已经散列良好的老数组的数据位置重新调换),个人理解。
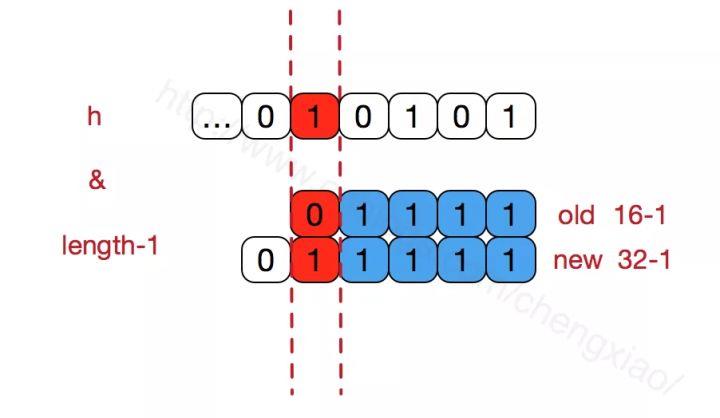
还有,数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀,比如
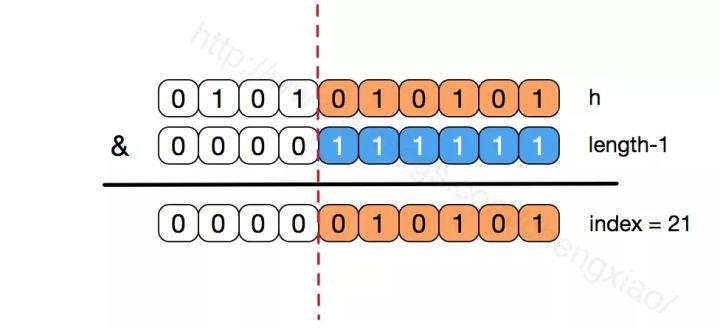
我们看到,上面的&运算,高位是不会对结果产生影响的(hash函数采用各种位运算可能也是为了使得低位更加散列),我们只关注低位bit,如果低位全部为1,那么对于h低位部分来说,任何一位的变化都会对结果产生影响,也就是说,要得到index=21这个存储位置,h的低位只有这一种组合。这也是数组长度设计为必须为2的次幂的原因。
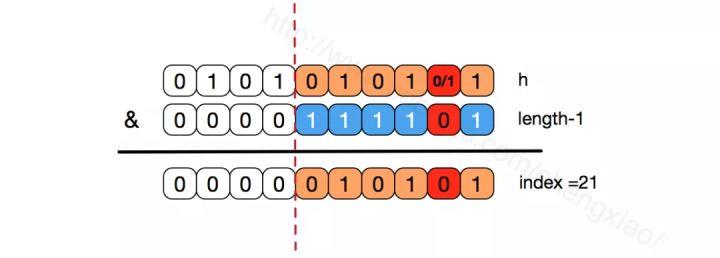
如果不是2的次幂,也就是低位不是全为1此时,要使得index=21,h的低位部分不再具有唯一性了,哈希冲突的几率会变的更大,同时,index对应的这个bit位无论如何不会等于1了,而对应的那些数组位置也就被白白浪费了。
get方法
public V get(Object key)
//如果key为null,则直接去table[0]处去检索即可。
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
get方法通过key值返回对应value,如果key为null,直接去table[0]处检索。我们再看一下getEntry这个方法
final Entry<K,V> getEntry(Object key)
if (size == 0)
return null;
//通过key的hashcode值计算hash值
int hash = (key == null) ? 0 : hash(key);
//indexFor (hash&length-1) 获取最终数组索引,然后遍历链表,通过equals方法比对找出对应记录
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next)
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
return null;
可以看出,get方法的实现相对简单,key(hashcode)–>hash–>indexFor–>最终索引位置,找到对应位置table[i],再查看是否有链表,遍历链表,通过key的equals方法比对查找对应的记录。要注意的是,有人觉得上面在定位到数组位置之后然后遍历链表的时候,e.hash == hash这个判断没必要,仅通过equals判断就可以。
其实不然,试想一下,如果传入的key对象重写了equals方法却没有重写hashCode,而恰巧此对象定位到这个数组位置,如果仅仅用equals判断可能是相等的,但其hashCode和当前对象不一致,这种情况,根据Object的hashCode的约定,不能返回当前对象,而应该返回null,后面的例子会做出进一步解释。
④重写equals方法需同时重写hashCode方法
关于HashMap的源码分析就介绍到这儿了,最后我们再聊聊老生常谈的一个问题,各种资料上都会提到,“重写equals时也要同时覆盖hashcode”,我们举个小例子来看看,如果重写了equals而不重写hashcode会发生什么样的问题
/**
* Created by chengxiao on 2016/11/15.
*/
public class MyTest
private static class Person
int idCard;
String name;
public Person(int idCard, String name)
this.idCard = idCard;
this.name = name;
@Override
public boolean equals(Object o)
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Person person = (Person) o;
//两个对象是否等值,通过idCard来确定
return this.idCard == person.idCard;
public static void main(String []args)
HashMap<Person,String> map = new HashMap<Person, String>();
Person person = new Person(1234,"乔峰");
//put到hashmap中去
map.put(person,"天龙八部");
//get取出,从逻辑上讲应该能输出“天龙八部”
System.out.println("结果:"+map.get(new Person(1234,"萧峰")));
实际输出结果:
结果:null
如果我们已经对HashMap的原理有了一定了解,这个结果就不难理解了。尽管我们在进行get和put操作的时候,使用的key从逻辑上讲是等值的(通过equals比较是相等的),但由于没有重写hashCode方法,所以put操作时,key(hashcode1)–>hash–>indexFor–>最终索引位置 ,而通过key取出value的时候 key(hashcode1)–>hash–>indexFor–>最终索引位置,由于hashcode1不等于hashcode2,导致没有定位到一个数组位置而返回逻辑上错误的值null(也有可能碰巧定位到一个数组位置,但是也会判断其entry的hash值是否相等,上面get方法中有提到。)
所以,在重写equals的方法的时候,必须注意重写hashCode方法,同时还要保证通过equals判断相等的两个对象,调用hashCode方法要返回同样的整数值。而如果equals判断不相等的两个对象,其hashCode可以相同(只不过会发生哈希冲突,应尽量避免)。
⑤总结
本文描述了HashMap的实现原理,并结合源码做了进一步的分析,也涉及到一些源码细节设计缘由,最后简单介绍了为什么重写equals的时候需要重写hashCode方法。希望本篇文章能帮助到大家,同时也欢迎讨论指正,谢谢支持
10.进程间通信方式有哪些,Binder讲一下,和共享内存的区别是什么
参考第二章前面
11.动态代理和静态代理区别
静态代理和动态代理的区别:
静态代理:由程序员创建或工具生成代理类的源码,再编译代理类。所谓静态也就是在程序运行前就已经存在代理类的字节码文件,代理类和委托类的关系在运行前就确定了。
动态代理:动态代理类的源码是在程序运行期间由JVM根据反射等机制动态的生成,所以不存在代理类的字节码文件。代理类和委托类的关系是在程序运行时确定。
12.数据结构和23种设计模式
腾讯Android开发笔记中有23种设计模式的详细介绍
13.RecyclerView的性能优化分析
概述
RecyclerView有着极高的灵活性,能实现ListView、GridView的所有功能。在日常开发中,使用非常广泛,如果使用不当将会影响到应用的整体性能,所以有必要了解一下如何更高效的使用。
数据处理与视图绑定分离
RecyclerView的 bindViewHolder方法是在UI线程进行的,如果在该方法进行耗时操作,将会影响滑动的流畅性。
优化前:
class Task
Date dateDue;
String title;
String description;
// getters and setters here
class MyRecyclerView.Adapter extends RecyclerView.Adapter
static final TODAYS_DATE = new Date();
static final DATE_FORMAT = new SimpleDateFormat("MM dd, yyyy");
public onBindViewHolder(Task.ViewHolder tvh, int position)
Task task = getItem(position);
if (TODAYS_DATE.compareTo(task.dateDue) > 0)
tvh.backgroundView.setColor(Color.GREEN);
else
tvh.backgroundView.setColor(Color.RED);
String dueDateFormatted = DATE_FORMAT.format(task.getDateDue());
tvh.dateTextView.setDate(dueDateFormatted);
上面的 onBindViewHolder方法中进行了日期的比较和日期的格式化,这个是很耗时的,在 onBindViewHolder方法中,应该只是将数据 set到视图中,而不应进行业务的处理。
优化后:
public class TaskViewModel
int overdueColor;
String dateDue;
public onBindViewHolder(Task.ViewHolder tvh, int position)
TaskViewModel taskViewModel = getItem(position);
tvh.backgroundView.setColor(taskViewModel.getOverdueColor());
tvh.dateTextView.setDate(taskViewModel.getDateDue());
数据优化
1.分页加载远端数据,对拉取的远端数据进行缓存,提高二次加载速度;
2.对于新增或删除数据通过 DiffUtil,来进行局部数据刷新,而不是一味的全局刷新数据。
DiffUtil是support包下新增的一个工具类,用来判断新数据和旧数据的差别,从而进行局部刷新。
DiffUtil的使用,在原来调用 mAdapter.notifyDataSetChanged()的地方:
// mAdapter.notifyDataSetChanged()
DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(new DiffCallBack(oldDatas, newDatas), true);
diffResult.dispatchUpdatesTo(mAdapter);
DiffUtil最终是调用Adapter的下面几个方法来进行局部刷新:
mAdapter.notifyItemRangeInserted(position, count);
mAdapter.notifyItemRangeRemoved(position, count);
mAdapter.notifyItemMoved(fromPosition, toPosition);
mAdapter.notifyItemRangeChanged(position, count, payload);
布局优化
减少过度绘制
减少布局层级,可以考虑使用自定义View来减少层级,或者更合理的设置布局来减少层级。
Note: 目前不推荐在RecyclerView中使用 ConstraintLayout,在ConstraintLayout1.1.2版中,性能还是表现不佳,后续的版本可能这个问题就解决了,需要持续关注。
减少xml文件inflate时间
xml文件包括:layout、drawable的xml,xml文件inflate出ItemView是通过耗时的IO操作。可以使用代码去生成布局,即 newView()的方式。这种方式是比较麻烦,但是在布局太过复杂,或对性能要求比较高的时候可以使用。
减少View对象的创建
一个稍微复杂的 Item 会包含大量的 View,而大量的 View 的创建也会消耗大量时间,所以要尽可能简化 ItemView;设计 ItemType 时,对多 ViewType 能够共用的部分尽量设计成自定义 View,减少 View 的构造和嵌套。
设置高度固定
如果item高度是固定的话,可以使用 RecyclerView.setHasFixedSize(true);来避免requestLayout浪费资源。
共用RecycledViewPool
在嵌套RecyclerView中,如果子RecyclerView具有相同的adapter,那么可以设置 RecyclerView.setRecycledViewPool(pool)来共用一个RecycledViewPool。
Note: 如果LayoutManager是LinearLayoutManager或其子类,需要手动开启这个特性: layout.setRecycleChildrenOnDetach(true)
class OuterAdapter extends RecyclerView.Adapter<OuterAdapter.ViewHolder>
RecyclerView.RecycledViewPool mSharedPool = new RecyclerView.RecycledViewPool();
...
@Override
public OuterAdapter.ViewHolder onCreateViewHolder(ViewGroup parent, int viewType)
RecyclerView innerLLM = new RecyclerView(inflater.getContext());
LinearLayoutManager innerLLM = new LinearLayoutManager(parent.getContext(), LinearLayoutManager.HORIZONTAL);
innerLLM.setRecycleChildrenOnDetach(true);
innerRv.setLayoutManager(innerLLM);
innerRv.setRecycledViewPool(mSharedPool);
return new OuterAdapter.ViewHolder(innerRv);
RecyclerView数据预取
RecyclerView25.1.0及以上版本增加了 Prefetch功能。 用于嵌套RecyclerView获取最佳性能。
Note: 只适合横向嵌套
// 在嵌套内部的LayoutManager中调用LinearLayoutManger的设置方法
// num的取值:如果列表刚刚展示4个半item,则设置为5
innerLLM.setInitialItemsPrefetchCount(num);
加大RecyclerView的缓存
用空间换时间,来提高滚动的流畅性。
recyclerView.setItemViewCacheSize(20);
recyclerView.setDrawingCa以上是关于12W字;2022最新Android11位大厂面试专题腾讯篇的主要内容,如果未能解决你的问题,请参考以下文章