Netflix Conductor源码分析--Client层源码分析
Posted 小程故事多_80
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netflix Conductor源码分析--Client层源码分析相关的知识,希望对你有一定的参考价值。
一、Client层总体介绍
在正式介绍Client层源码前,我们先来看一下如何在client端与server端通信,demo代码如下:
TaskClient taskClient = new TaskClient();
taskClient.setRootURI("http://localhost:8080/api/"); //Point this to the server API
int threadCount = 2; //number of threads used to execute workers. To avoid starvation, should be same or more than number of workers
Worker worker1 = new OrderWorker("order");
Worker worker2 = new PaymentWorker("payment");
//Create WorkflowTaskCoordinator
WorkflowTaskCoordinator.Builder builder = new WorkflowTaskCoordinator.Builder();
WorkflowTaskCoordinator coordinator = builder.withWorkers(worker1, worker2).withThreadCount(threadCount).withTaskClient(taskClient).build();
//Start for polling and execution of the tasks
coordinator.init();
代码说明:
1、第一步需要创建TaskClient类并设置server端的API URL路径以便客户端能够与服务端通信。
2、创建任务工作者Worker对象,具体的任务是由Worker来执行。
3、将Worker对象传入WorkerflowTaskCoordinator对象中,WorkerflowTaskCoordinator负责启动线程池来执行Worker任务,同时维护与server端的心跳以及最新任务数据的拉取操作。
通过阅读上述代码引出了几个类名称的解释:
- WorkerflowTaskCoordinator:工作流的协调者,负责管理Task Worker的线程池以及和服务端的通信。
- TaskClient:conductor的任务管理客户端类,负责从server端轮询任务以及更新任务状态等。
- Builder:用于创建WorkerflowTaskCoordinator实例的建造类。
这三个类的类图如图1-1所示,从图中可以看到类的依赖、组合等关系。
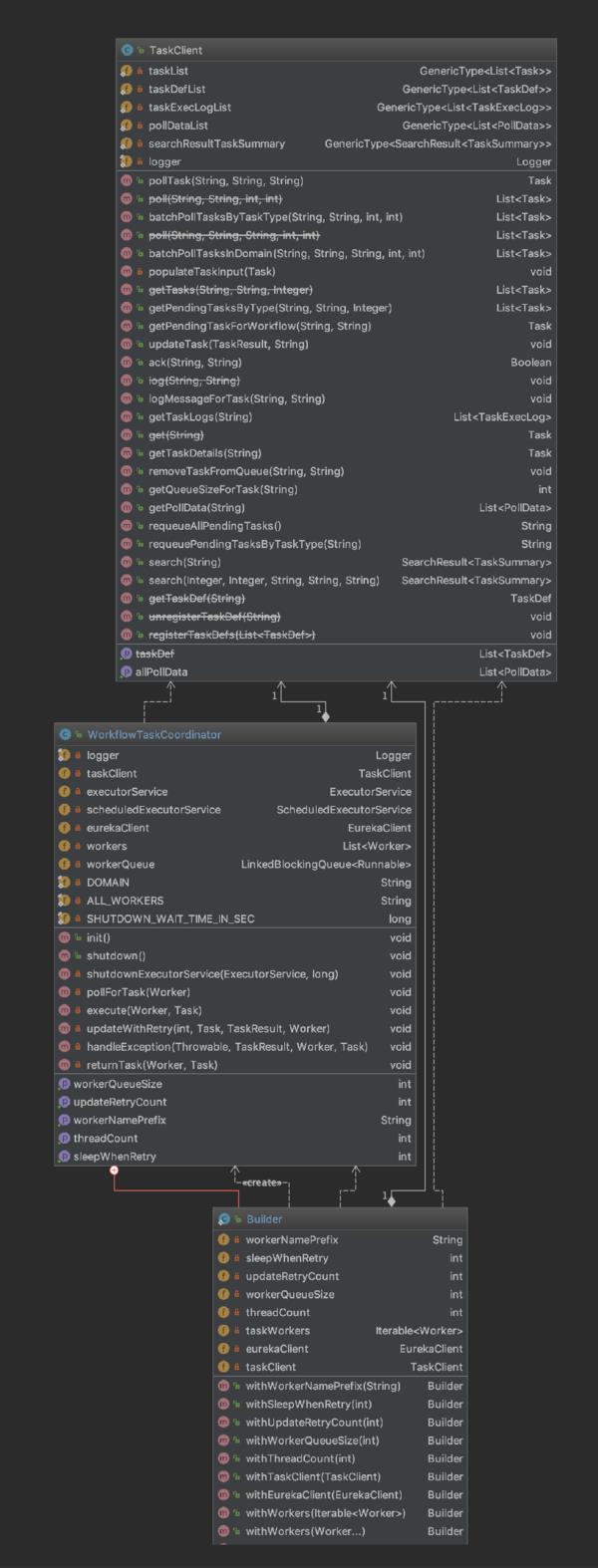
图1-1展示是Client层最核心的三个类的依赖关系,我们接下来的源码解析就是围绕这三个类来展开。
整个Client模块的包结构和关键类如图1-2所示:
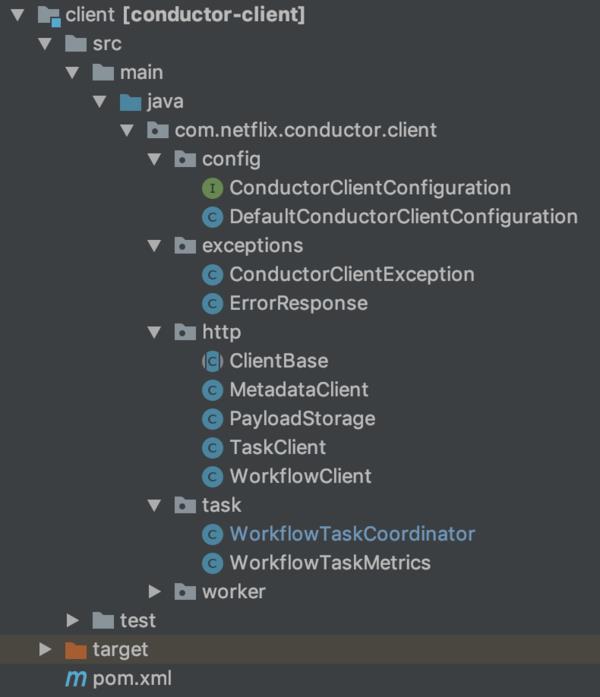
其中:
- config包是关于Client的一些配置类
- exceptions包是自定义的client异常类
- http包是与服务端通信的基础类,包括基础基类ClientBase,还有元数据、负载、客户端任务,工作流等通信类
- task包主要包括工作流协调者和工作流任务统计类
- worker包主要包括Worker工作者接口类
二、Client层源码执行的全流程解析
我们拿文章 深入浅出Netflix Conductor使用 中介绍的案例来讲解源码流程(文章中包括了任务、工作流的DSL定义以及如何使用),流程图形表示如图1-3所示:
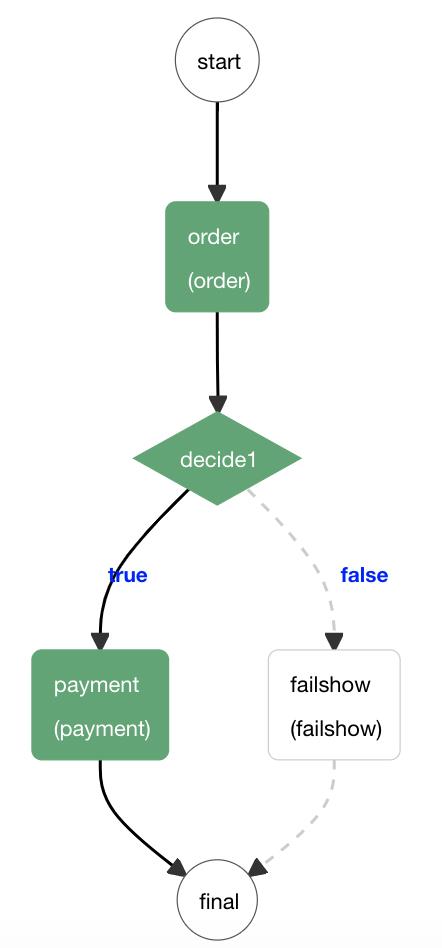
这张图的含义非常简单,用户走下单流程到order模块,如果下单成功则走payment支付模块进行支付,如果下单失败则走失败模块进行重试等操作。
在Swagger界面上输入如下参数启动工作流,如图1-4
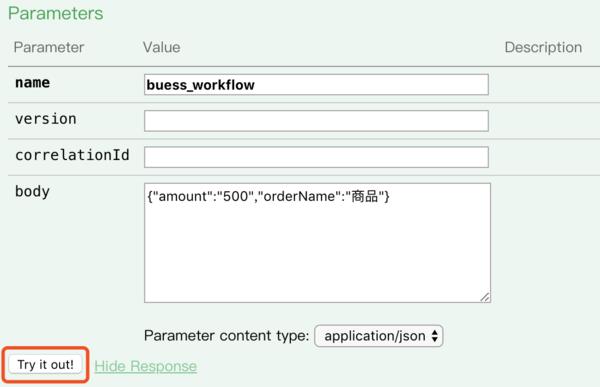
启动的过程实际上是通过Swagger API接口调用server端的相关类,而client端则是通过拉取的方式来得到需要自己执行任务的通知和输入参数。
启动完工作流之后Client端的代码进入WorkerflowTaskCoordinator中的init方法,代码如下所示:
public synchronized void init()
if(threadCount == -1)
threadCount = workers.size();
logger.info("Initialized the worker with threads", threadCount);
this.workerQueue = new LinkedBlockingQueue<Runnable>(workerQueueSize);
AtomicInteger count = new AtomicInteger(0);
this.executorService = new ThreadPoolExecutor(threadCount, threadCount,
0L, TimeUnit.MILLISECONDS,
workerQueue,
(runnable) ->
Thread thread = new Thread(runnable);
thread.setName(workerNamePrefix + count.getAndIncrement());
return thread;
);
this.scheduledExecutorService = Executors.newScheduledThreadPool(workers.size());
//定时轮询server状态策略,默认每隔1秒进行轮询,根据任务名获取当前任务信息
workers.forEach(worker ->
scheduledExecutorService.scheduleWithFixedDelay(()->pollForTask(worker), worker.getPollingInterval(), worker.getPollingInterval(), TimeUnit.MILLISECONDS);
);
代码说明:
这段代码通过JDK中的scheduledExecutorService.scheduleWithFixedDelay方法每隔一秒对server端进行轮询,轮询任务的方法是pollForTask,代码如下:
private void pollForTask(Worker worker)
if(eurekaClient != null && !eurekaClient.getInstanceRemoteStatus().equals(InstanceStatus.UP))
logger.debug("Instance is NOT UP in discovery - will not poll");
return;
if(worker.paused())
WorkflowTaskMetrics.incrementTaskPausedCount(worker.getTaskDefName());
logger.debug("Worker has been paused. Not polling anymore!", worker.getClass());
return;
String domain = Optional.ofNullable(PropertyFactory.getString(worker.getTaskDefName(), DOMAIN, null))
.orElse(PropertyFactory.getString(ALL_WORKERS, DOMAIN, null));
logger.debug("Polling , domain=, count = timeout = ms", worker.getTaskDefName(), domain, worker.getPollCount(), worker.getLongPollTimeoutInMS());
List<Task> tasks = Collections.emptyList();
try
// get the remaining capacity of worker queue to prevent queue full exception
int realPollCount = Math.min(workerQueue.remainingCapacity(), worker.getPollCount());
if (realPollCount <= 0)
logger.warn("All workers are busy, not polling. queue size = , max = ", workerQueue.size(), workerQueueSize);
return;
//获取当前客户端的任务名称
String taskType = worker.getTaskDefName();
//根据当前客户端的任务名称从server端的状态机获取是否有自己要执行的任务,如果有任务则获取执行,只能获取一次。
tasks = getPollTimer(taskType)
.record(() -> taskClient.batchPollTasksInDomain(taskType, domain, worker.getIdentity(), realPollCount, worker.getLongPollTimeoutInMS()));
incrementTaskPollCount(taskType, tasks.size());
logger.debug("Polled , domain , received tasks in worker - ", worker.getTaskDefName(), domain, tasks.size(), worker.getIdentity());
catch (Exception e)
WorkflowTaskMetrics.incrementTaskPollErrorCount(worker.getTaskDefName(), e);
logger.error("Error when polling for tasks", e);
//根据获取的任务列表,以线程的方式启动执行任务
for (Task task : tasks)
try
executorService.submit(() ->
try
logger.debug("Executing task , taskId - in worker - ", task.getTaskDefName(), task.getTaskId(), worker.getIdentity());
//这步就是执行用户自定义的任务逻辑
execute(worker, task);
catch (Throwable t)
//执行失败,置任务状态为失败,并将失败结果返回到server端
task.setStatus(Task.Status.FAILED);
TaskResult result = new TaskResult(task);
handleException(t, result, worker, task);
);
catch (RejectedExecutionException e)
WorkflowTaskMetrics.incrementTaskExecutionQueueFullCount(worker.getTaskDefName());
logger.error("Execution queue is full, returning task: ", task.getTaskId(), e);
returnTask(worker, task);
代码说明:
每隔一秒从服务端的(tasks/poll/batch/taskType)获取当前需要执行的任务列表,任务只能获取一次不能重新获取。然后将任务通过异步线程的方式启动执行,每一个任务都是由用户自定义的逻辑实现,任务的返回值被封装到了TaskResult类中,execute方法的内容如下所示:
private void execute(Worker worker, Task task)
String taskType = task.getTaskDefName();
try
if(!worker.preAck(task))
logger.debug("Worker decided not to ack the task , taskId = ", taskType, task.getTaskId());
return;
if (!taskClient.ack(task.getTaskId(), worker.getIdentity()))
WorkflowTaskMetrics.incrementTaskAckFailedCount(worker.getTaskDefName());
logger.error("Ack failed for , taskId = ", taskType, task.getTaskId());
returnTask(worker, task);
return;
catch (Exception e)
logger.error(String.format("ack exception for task %s, taskId = %s in worker - %s", task.getTaskDefName(), task.getTaskId(), worker.getIdentity()), e);
WorkflowTaskMetrics.incrementTaskAckErrorCount(worker.getTaskDefName(), e);
returnTask(worker, task);
return;
com.google.common.base.Stopwatch stopwatch = com.google.common.base.Stopwatch.createStarted();
TaskResult result = null;
try
//前面大部分都是做监控和统计功能的,在这里不细说
//这段代码是真正执行用户Task任务的代码,执行完后返回值被封装为TaskResult对象
logger.debug("Executing task in worker at ", task, worker.getClass().getSimpleName(), worker.getIdentity());
result = worker.execute(task);
result.setWorkflowInstanceId(task.getWorkflowInstanceId());
result.setTaskId(task.getTaskId());
result.setWorkerId(worker.getIdentity());
catch (Exception e)
logger.error("Unable to execute task ", task, e);
if (result == null)
task.setStatus(Task.Status.FAILED);
result = new TaskResult(task);
handleException(e, result, worker, task);
finally
stopwatch.stop();
WorkflowTaskMetrics.getExecutionTimer(worker.getTaskDefName())
.record(stopwatch.elapsed(TimeUnit.MILLISECONDS), TimeUnit.MILLISECONDS);
logger.debug("Task executed by worker at with status ", task.getTaskId(), worker.getClass().getSimpleName(), worker.getIdentity(), task.getStatus());
//更新任务状态,成功或者失败
updateWithRetry(updateRetryCount, task, result, worker);
代码说明:
通过worker.execute方法执行用户定义的任务逻辑,不管是否成功都执行updatewithRetry方法更新server端的任务状态和任务执行返回结果。
访问的URL是/api/tasks。
三、完整流程时序图
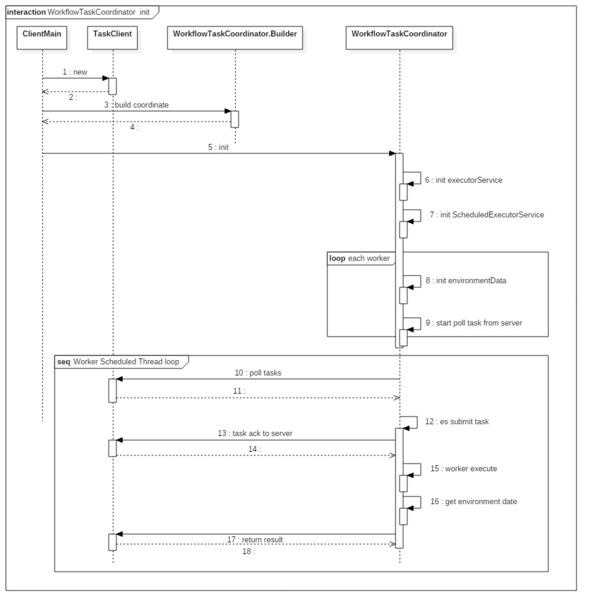
以上是关于Netflix Conductor源码分析--Client层源码分析的主要内容,如果未能解决你的问题,请参考以下文章