论文解读:Deep High Dynamic Range Imaging of Dynamic Scenes
Posted Matrix_11
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读:Deep High Dynamic Range Imaging of Dynamic Scenes相关的知识,希望对你有一定的参考价值。
Deep High Dynamic Range Imaging of Dynamic Scenes
Abstract
这篇文章介绍了一种在动态场景中,如何将不同曝光的图像进行融合从而得到高动态图像的方法,我们知道,在动态场景中,将不同曝光的图像进行融合是非常挑战的,现有方法的一种就是先对多帧不同曝光的图像进行配准对齐,都对齐到某一参考帧上,然后再讲对齐后的图像进行融合。但是有的时候,这种配准对齐会引入 artifact,而这些 artifact 在最终融合的图像上会有 ghost 残留,也就是我们说的鬼影残留,这篇文章提出了一种基于学习的方法来解决动态场景的这些问题,这篇文章利用 CNN 作为学习模型,并且对比了三种不同的学习策略的融合效果,而且,这篇文章还构建了一个超大的数据集,以及对应的 groundtruth。
Introduction
我们都知道,人眼可以感受的动态范围其实很大,而一般的数码相机能够感受的动态范围是有限的,所以一般的数码相机容易拍出过曝或者欠曝的图像,最常见的获得高动态图像的方法就是用相机拍摄几张不同曝光的图像,然后将这几张图像进行融合,这种方法对于静态场景加上用三脚架固定相机,可以获得较好的效果,但是如果场景里面有运动的物体,或者用手持的方法拍摄多张图像,可能就会导致融合的图像产生鬼影残留。
一般来说,这类问题可以分为两步来处理,第一步就是将多帧图像进行配准,第二步就是将配准后的多帧图像进行融合。图像的配准问题已经有很多的相关研究了,基于光流的一些方法也已经发展出来了,基于光流的配准方法可以很好地处理一些非刚性的运动配准,但是对于遮挡区域容易引起 artifacts,这些 artifacts 在多帧融合阶段会产生。
这篇文章观察到,配准产生的 artifacts 可以在融合的时候有效的减少,但是这个处理比较复杂,因为需要对有 artifact 的区域进行检测并且对这些区域进行去除,这篇文章提出基于学习的方法来学习这个融合过程。具体来说,就是给定一组不同曝光的图像,其中包含低曝光,中曝光,高曝光,首先,将低曝光,高曝光的图像向中曝光对齐,然后这三帧对齐的图像送入卷积神经网络(CNN),去合成最终的高动态图像,这篇文章用了三种不同的方式来设计这个模型从而进行多帧图像的融合。
基于学习的方法,最大的问题就是训练数据的构建,这篇文章想办法构建了一个较大的数据集,包括三帧不同曝光的输入图像以及对应的高动态图像。具体来说,就是通过固定三脚架,对静态场景拍摄三张不同曝光的图像,这三张图像将合成一张高动态图像,这张高动态图像就是 groundtruth,然后对同一个场景,再拍摄三张不同曝光的动态图像,这三张图像中的中曝光图像将被替换成静态场景中的中曝光图像,通过这种方法,这篇文章一共拍摄了 74 个场景的高动态图像,用来构建训练数据。
Algorithm
给定一组动态场景中的多曝光图像, ( Z 1 , Z 2 , Z 3 ) (Z_1, Z_2, Z_3) (Z1,Z2,Z3),我们的目标是合成一个高动态图像 H H H,这个过程可以分成两个步骤,第一步,配准;第二步融合。在配准阶段,一般会选择中间曝光的图像 Z 2 Z_2 Z2 作为参考,其它两张短曝光和长曝光的图像像 Z 2 Z_2 Z2 对齐,这些对齐的图像在第二步进行多帧融合,得到最终的高动态图像。在图像配准这块,过去十几年已经有很多的相关研究了,目前一些主流的配准算法都能较好地处理多帧之间的非刚性偏移,但是对于其中的运动区域以及遮挡区域,还是无法处理地很好,这些区域在融合的时候容易产生 artifact,这篇文章发现这些 artifact 可以在融合阶段解决。
Overview

接下来,我们介绍整体的流程,
- Preprocessing the Input LDR Images
如果拍摄的 LDR 图像不是 RAW 图,那么首先需要对这些图像进行线性化操作,这可以通过相机响应曲线来实现,然后再做一个 gamma 变换 ( g a m m a = 2.2 gamma=2.2 gamma=2.2)。
- Alignment
接下来,就是配准,一般来说就是将 Z 1 , Z 3 Z_1, Z_3 Z1,Z3 配准到 Z 2 Z_2 Z2 上,这里以 Z 3 Z_3 Z3 向 Z 2 Z_2 Z2 的对齐为例, Z 1 Z_1 Z1 向 Z 2 Z_2 Z2 的对齐是类似的流程,首先需要做一个亮度对齐,文章中是把 Z 2 Z_2 Z2 向 Z 3 Z_3 Z3 的亮度对齐,亮度对齐遵循下面的表达式:
Z 2 , 3 = c l i p ( Z 2 Δ 2 , 3 1 / γ ) Z_2, 3 = clip(Z_2 \\Delta_2, 3^1/\\gamma) Z2,3=clip(Z2Δ2,31/γ)
上面的表达式中, c l i p clip clip 表示截断,保证值的有效范围在 [0, 1] 之间, Δ 2 , 3 \\Delta_2, 3 Δ2,3 表示两张图像的曝光比, Δ 2 , 3 = t 3 / t 2 \\Delta_2,3 = t_3 / t_2 Δ2,3=t3/t2,亮度对齐之后,利用光流的方法,计算两帧图像之间的位移场,然后将 Z 3 Z_3 Z3 图像进行 warp,这样就得到了对齐的图像。
- HDR Merge
对齐之后,就是多帧融合,多帧融合的难点在于融合避免检测出存在 artifact 的区域,并且避免这些区域对最终的融合产生影响,这篇文章利用卷积神经网络来解决这个问题。这篇文章在设计 loss 的时候,没有用 g a m m a gamma gamma 函数,而是用了一种对数函数, 这个函数的定义如下所示:
T = log ( 1 + μ H ) log ( 1 + μ ) T = \\frac\\log(1 + \\mu H)\\log(1 + \\mu) T=log(1+μ)log(1+μH)
μ \\mu μ 表示整体压缩的程度,上面这个表达式是连续可导的,所以对于梯度反传更加方便,最终的 loss 用 l 2 l_2 l2 表示:
E = ∑ 1 3 ( T ˉ − T ) 2 E = \\sum_1^3(\\barT - T)^2 E=1∑3(Tˉ−T)2
Learning-Based HDR Merge
我们都知道,多帧融合最重要的就是估计每一帧输入图像的质量,然后基于图像的质量决定融合的权重,这个过程是需要通过学习的方式训练一个模型,让模型自己去判断,模型需要排除容易产生 artifact 的图像区域,以及有噪声的区域和过暗或者过曝的区域。
一般来说,我们需要对 LDR 图像以及 HDR 图像进行图像质量的衡量,比如说我们需要把噪声及过曝区域排除掉,总的来说,这个融合过程可以表示为:
H = g ( I , H ) H = g(\\mathcalI, \\mathcalH) H=g(I,H)
其中, H \\mathcalH H 表示对齐后的一组在 HDR domain 的 LDR 图像, H 图像是 LDR 图像通过如下的变换得到的, H i = I i γ / t i H_i = I_i^\\gamma/t_i Hi=Iiγ/ti, t i t_i ti 表示曝光时间。
这篇文章用了三种不同的学习模式来做多帧融合,第一种是直接融合,第二种是估计融合的权重,然后再融合,第三种是对图像进行对齐的微调同时估计出融合权重,最后将微调后的对齐图像进行融合。这三种方式的 target 都是 HDR 图像,而输入也是一样的,三帧 LDR 域的图像以及三帧转换后的 HDR 域的图像。最后模型的输出再经过一个 tonemapping 的变换与 target 进行 loss 的计算。
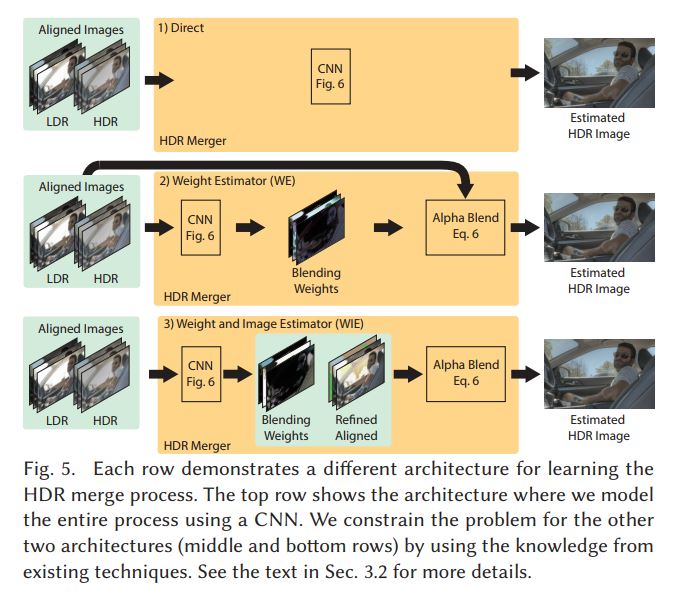
Direct
第一种方式就是直接映射,通过端到端的学习,将多帧输入图像最后融合得到一帧 HDR 图像,利用链式法则,可以得到如下的导数形式:
∂ E ∂ w = ∂ E ∂ T ^ ∂ T ^ ∂ H ^ ∂ H ^ ∂ w \\frac\\partial E\\partial w = \\frac\\partial E\\partial \\hatT \\frac\\partial \\hatT\\partial \\hatH \\frac\\partial \\hatH\\partial w ∂w∂E=∂T^∂E∂H^∂T^∂w∂H^
∂ T ^ ∂ H ^ = μ log ( 1 + μ ) 1 1 + μ H ^ \\frac\\partial \\hatT\\partial \\hatH = \\frac\\mu\\log(1+\\mu) \\frac11 + \\mu \\hatH ∂H^∂T^=log(1+μ)μ1+μH^1
这种形式对应的网络输出是 3 个通道
Weight Estimator (WE)
第二种形式是学习融合的权重,通过学习得到的融合权重再进行融合,网络的输出不再是 HDR 图像,而是三个通道的融合权重,这种方式所对应的导数形式如下所示:
H ^ ( p ) = ∑ j = 1 3 a j ( p ) H j ( p ) ∑ j = 1 3 a j ( p ) , H j ( p ) = I j γ t j \\hatH(p) = \\frac\\sum_j=1^3a_j(p)H_j(p)\\sum_j=1^3a_j(p) , \\quad H_j(p) = \\fracI_j^\\gammat_j H^(p)=∑j=13