搭建Ceph集群
Posted 爱敲代码的三毛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搭建Ceph集群相关的知识,希望对你有一定的参考价值。
文章目录
认识Ceph
Ceph是一个能提供的文件存储,块存储和对象存储的分布式存储系统。它提供了一个可无限伸缩的Ceph存储集群。
官方文档
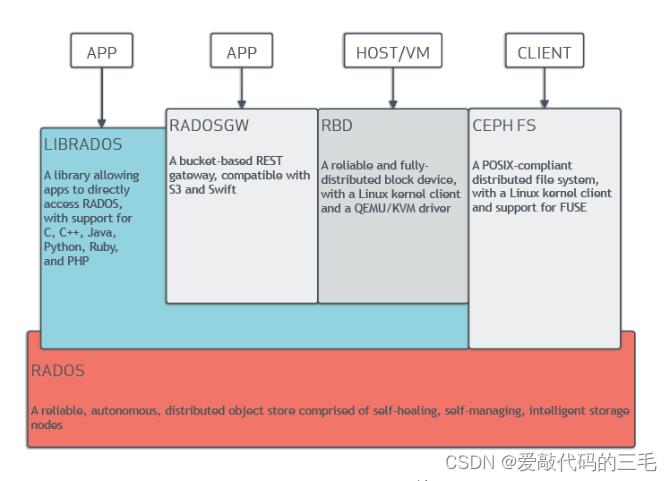
RADOS: Ceph的高可靠,高可拓展,高性能,高自动化都是由这一层来提供的, 用户数据的存储最终也都是通过这一层来进行存储的。
可以说RADOS就是ceph底层原生的数据引擎, 但实际应用时却不直接使用它,而是分为如下4种方式来使用:
- LIBRADOS是一个库, 它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言。如Python,C,C++等. 简单来说,就是给开发人员使用的接口。
- CEPH FS通过Linux内核客户端和FUSE来提供文件系统。(文件存储)
- RBD通过Linux内核客户端和QEMU/KVM驱动来提供一个分布式的块设备。(块存储)
- RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。(对象存储)
拓展名词
RESTFUL: RESTFUL是一种架构风格,提供了一组设计原则和约束条件,http就属于这种风格的典型应用。REST最大的几个特点为:资源、统一接口、URI和无状态。
- 资源: 网络上一个具体的信息: 一个文件,一张图片,一段视频都算是一种资源。
- 统一接口: 数据的元操作,即CRUD(create, read, update和delete)操作,分别对应于HTTP方法
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供完整资源数据)。
- PATCH(UPDATE):在服务器更新资源(客户端提供需要修改的资源数据)。
- DELETE(DELETE):从服务器删除资源。
- URI(统一资源定位符): 每个URI都对应一个特定的资源。要获取这个资源,访问它的URI就可以。最典型的URI即URL
- 无状态: 一个资源的定位与其它资源无关,不受其它资源的影响。
S3 (Simple Storage Service 简单存储服务): 可以把S3看作是一个超大的硬盘, 里面存放数据资源(文件,图片,视频等),这些资源统称为对象.这些对象存放在存储段里,在S3叫做bucket.
和硬盘做类比, 存储段(bucket)就相当于目录,对象就相当于文件。
硬盘路径类似/root/file1.txt
S3的URI类似s3://bucket_name/object_name
swift: 最初是由Rackspace公司开发的高可用分布式对象存储服务,并于2010年贡献给OpenStack开源社区作为其最初的核心子项目之
一、Ceph集群
1. 环境准备
准备四台服务器,需要能上外网,IP静态固定 (除client外每台最少加1个磁盘,最小1G,不用分区);
| 主机名 | ip |
|---|---|
| client | 192.168.44.10 |
| node1 | 192.168.44.20 |
| node2 | 192.168.44.30 |
| node3 | 192.168.44.40 |
1.给所有主机配置主机名和主机名绑定
# hostnamectl set-hostname
# vim /etc/hosts
192.168.44.10 client
192.168.44.20 node1
192.168.44.30 node2
192.168.44.40 node3
2.关闭防火墙和selinux
[root@client ~]# systemctl stop firewalld
[root@client ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@client ~]# setenforce 0
[root@client ~]# vim /etc/selinux/config
3.所有服务器时间同步
安装 yum install -y ntp
# systemctl restart ntpd
# systemctl enable ntpd
4.所有机器配置yum源
# yum install epel-release -y
# vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/x86_64/
enabled=1
gpgcheck=0
priority=1
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=0
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS
enabled=1
gpgcheck=0
priority=1
2. 集群部署过程
1) 配置ssh免密
以node1为部署配置节点,在node1上配置ssh等效性(也就是 node1、node2、node3、client都要配置免密,实现相互免密登录)
当然此步骤不是必要的
- 如果使用ceph-deploy来安装集群,密钥会方便安装
- 如果不使用ceph-deploy安装,也可以方便后续的同步配置文件操作
在node1操作
[root@node1 ~]# ssh-keygen
[root@node1 ~]# ssh-copy-id -i node1
[root@node1 ~]# ssh-copy-id -i node2
[root@node1 ~]# ssh-copy-id -i node3
[root@node1 ~]# ssh-copy-id -i client
2) 在node1上安装部署工具
[root@node1 ~]# yum install ceph-deploy -y
# 安装依赖包
# yum install -y python-setuptools
3) 在node1上创建集群
创建一个集群配置目录(后面大部分操作都会涉及到这个目录)
# ceph-deploy new node1
[root@localhost ceph]# ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
说明:
ceph.conf 集群配置文件
ceph-deploy-ceph.log 使用ceph-deploy部署的日志记录
ceph.mon.keyring mon的验证key文件
4) ceph集群节点安装ceph
在所有节点安装ceph(不包括client)
# yum install ceph ceph-radosgw -y
# ceph -v
ceph version 13.2.10 (564bdc4ae87418a232fc901524470e1a0f76d641) mimic (stable)
5) 客户端(client)安装ceph-common
# yum install ceph-common -y
6) 创建mon(监控)
增加public网络用于监控(在node1节点上操作)
在[global]配置段里添加下面一句(直接放到最后一行)
[root@node1 ceph]# vim /etc/ceph/ceph.conf
public network = 192.168.44.0/24 # 监控网络
监控节点初始化,并同步配置到所有节点(node1,node2,node3,不包括client)
[root@node1 ceph]# ceph-deploy mon create-initial
[root@node1 ceph]# ceph health
HEALTH_OK
将配置文件同步到所有节点
[root@node1 ceph]# ceph-deploy admin node1 node2 node3
[root@node1 ceph]# ceph -s
cluster:
id: 81a0b141-49a6-4780-b76b-f54d8d012aa1
health: HEALTH_OK # 健康状态为OK
services:
mon: 1 daemons, quorum node1 # 一个监控
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
为了防止mon单点故障,你可以加多个mon节点(建议奇数个,因为有quorum仲裁投票),在node1节点上操作
[root@node1 ceph]# ceph-deploy mon add node2
[root@node1 ceph]# ceph-deploy mon add node3
[root@node1 ceph]# ceph -s
cluster:
id: 81a0b141-49a6-4780-b76b-f54d8d012aa1
health: HEALTH_OK # 健康状态为OK
services:
mon: 3 daemons, quorum node1,node2,node3 # 三个监控
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
监控到时间不同步的解决方法
ceph集群对时间同步要求非常高, 即使你已经将ntpd服务开启,但仍然可能有clock skew deteted相关警告
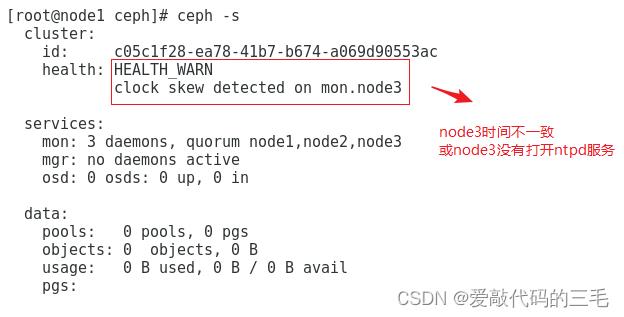
1.在ceph集群所有节点上(node1,node2,node3)不使用ntpd服务,直接使用crontab同步
# systemctl stop ntpd
# systemctl disable ntpd
# crontab -e
*/10 * * * * ntpdate ntp1.aliyun.com 每5或10分钟同步1次公网的任意时间服务器
2.调大时间警告的阈值
[root@node1 ceph]# vim ceph.conf
[global] 在global参数组里添加以下两行
......
mon clock drift allowed = 2 # monitor间的时钟滴答数(默认0.5秒)
mon clock drift warn backoff = 30 # 调大时钟允许的偏移量(默认为5)
3.同步到所有节点
[root@node1 ceph]# ceph-deploy --overwrite-conf admin node1 node2 node3
前面第1次同步不需要加--overwrite-conf参数
这次修改ceph.conf再同步就需要加--overwrite-conf参数覆盖
4.所有ceph集群节点**上重启ceph-mon.target服务
# systemctl restart ceph-mon.target
7) 创建mgr(管理)
ceph luminous版本中新增加了一个组件:Ceph Manager Daemon,简称ceph-mgr。
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。
创建一个mgr
[root@node1 ceph]# ceph-deploy mgr create node1
[root@node1 ceph]# ceph -s
cluster:
id: 81a0b141-49a6-4780-b76b-f54d8d012aa1
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active) # node1为mgr
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
添加多个mgr可以实现HA
[root@node1 ceph]# ceph-deploy mgr create node2
[root@node1 ceph]# ceph-deploy mgr create node3
[root@node1 ceph]# ceph -s
cluster:
id: 81a0b141-49a6-4780-b76b-f54d8d012aa1
health: HEALTH_WARN 健康状态为,有警告
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum node1,node2,node3 3个监控
mgr: node1(active), standbys: node2, node3 # 看到node1为主,node2,node3为备
osd: 0 osds: 0 up, 0 in #看到为0个磁盘
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
8)创建osd(存储盘)
帮助
[root@node1 ceph]# ceph-deploy disk --help
[root@node1 ceph]# ceph-deploy osd --help
列表所有节点的磁盘,都有sda和sdb两个盘,sdb为我们要加入分布式存储的盘
列表查看节点上的磁盘
[root@node1 ceph]# ceph-deploy disk list node1
[root@node1 ceph]# ceph-deploy disk list node2
[root@node1 ceph]# ceph-deploy disk list node3
zap表示干掉磁盘上的数据,相当于格式化(就是最开始新增的磁盘)
[root@node1 ceph]# ceph-deploy disk zap node1 /dev/sdb
[root@node1 ceph]# ceph-deploy disk zap node2 /dev/sdb
[root@node1 ceph]# ceph-deploy disk zap node3 /dev/sdb
将磁盘创建为osd
[root@node1 ceph]# ceph-deploy osd create --data /dev/sdb node1
[root@node1 ceph]# ceph-deploy osd create --data /dev/sdb node2
[root@node1 ceph]# ceph-deploy osd create --data /dev/sdb node3
[root@node1 ceph]# ceph -s
cluster:
id: 81a0b141-49a6-4780-b76b-f54d8d012aa1
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active), standbys: node2, node3
osd: 3 osds: 3 up, 3 in # 看到这里有3个osd
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 27 GiB / 30 GiB avail # 大小为3个磁盘的总和
pgs:
集群节点的扩容方
假设再加一个新的集群节点node4
1, 主机名配置和绑定
2, 在node4上yum install ceph ceph-radosgw -y安装软件
3, 在部署节点node1上同步配置文件给node4. ceph-deploy admin node4
4, 按需求选择在node4上添加mon或mgr或osd等
二、RADOS原生数据存取演示
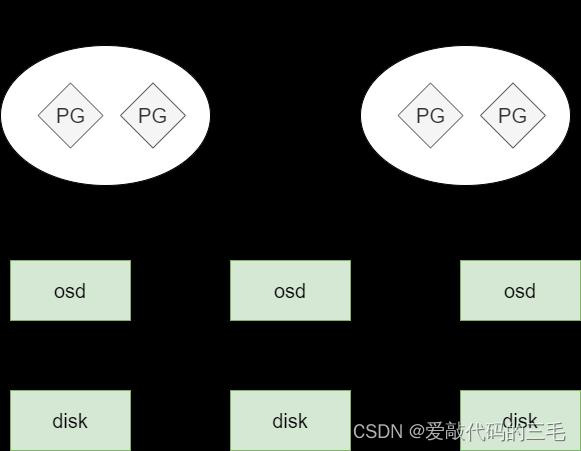
要实现数据存取需要创建一个pool,创建pool要先分配PG。
- 物理上多个disk(osd)组成一个1个大硬盘,数据要分成多个小单位,称为对象
- 多个对象组成一个PG,多个PG组成一个pool,pool是大硬盘上创建的,客户端对pool进行操作
- 客户端直接对pool操作(但文件存储,块存储,对象存储我们不这么做)
- pool里要分配PG
- PG里可以存放多个对象
- 对象就是由客户端写入的数据分离的单位
1. 创建pool
创建test_pool,指定pg数为128
[root@node1 ceph]# ceph osd pool create test_pool 128
pool 'test_pool' created
You have new mail in /var/spool/mail/root
查看pg数量,可以使用ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
[root@node1 ceph]# ceph osd pool get test_pool pg_num
pg_num: 128
说明: pg数与ods数量有关系
- pg数为2的倍数,一般5个以下osd,分128个PG或以下即可(分多了PG会报错的,可按报错适当调低)
- 可以使用
ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
2. 存储测试
1, 我这里把本机的/etc/fstab文件上传到test_pool,并取名为newfstab
[root@node1 ceph]# rados put newfstab /etc/fstab --pool=test_pool
2.查看
[root@node1 ceph]# rados -p test_pool ls
newfstab
3.删除
[root@node1 ceph]# rados rm newfstab --pool=test_pool
3.删除pool
1, 在部署节点node1上增加参数允许ceph删除pool
[root@node1 ceph]# vim /etc/ceph/ceph.conf
mon_allow_pool_delete = true
2, 修改了配置, 要同步到其它集群节点
[root@node1 ceph]# ceph-deploy --overwrite-conf admin node1 node2 node3
3, 重启监控服务
[root@node1 ceph]# systemctl restart ceph-mon.target
4, 删除时pool名输两次,后再接--yes-i-really-really-mean-it参数就可以删除了
[root@node1 ceph]# ceph osd pool delete test_pool test_pool --yes-i-really-really-mean-it
pool 'test_pool' removed
三、创建Ceph文件存储
要运行Ceph文件系统, 你必须先创建至少带一个mds的Ceph存储集群.
(Ceph块设备和Ceph对象存储不使用MDS)。
Ceph MDS: Ceph文件存储类型存放与管理元数据metadata的服务
1. 创建文件存储并使用
第1步: 在node1部署节点上同步配置文件,并创建mds服务(也可以做多个mds实现HA)
[root@node1 ceph]# ceph-deploy mds create node1 node2 node3
我这里做三个mds
第2步: 一个Ceph文件系统需要至少两个RADOS存储池,一个用于数据,一个用于元数据。所以我们创建它们。
[root@node1 ceph]# ceph osd pool create cephfs_pool 128
pool 'cephfs_pool' created
[root@node1 ceph]# ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created
[root@node1 ceph]# ceph osd pool ls |grep cephfs
cephfs_pool
cephfs_metadata
第3步: 创建Ceph文件系统,并确认客户端访问的节点
[root@node1 ceph]# ceph fs new cephfs cephfs_metadata cephfs_pool
[root@node1 ceph]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_pool ]
[root@node1 ceph]# ceph mds stat
cephfs-1/1/1 up 0=ceph_node3=up:active, 2 up:standby 这里看到node3为up状态
第4步: 客户端准备验证key文件
- 说明: ceph默认启用了cephx认证, 所以客户端的挂载必须要验证
在集群节点(node1,node2,node3)上任意一台查看密钥字符串
[root@node1 ceph]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQDjNCVjXodCEBAACMVxNazjo5qVNC1ZmKgcKQ== 后面的字符串就是验证需要的
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
在客户端上创建一个文件记录密钥字符串
[root@client ~]# vim admin.key # 创建一个密钥文件,复制粘贴上面得到的字符串
AQDjNCVjXodCEBAACMVxNazjo5qVNC1ZmKgcKQ==
第5步: 客户端挂载(挂载ceph集群中跑了mon监控的节点, mon监控为6789端口)
[root@client ~]# mount -t ceph node1:6789:/ /mnt -o name=admin,secretfile=/root/admin.key
第6步: 验证
[root@client ~]# df -h | tail -1
192.168.44.20:6789:/ 8.5G 0 8.5G 0% /mnt # # 大小不用在意,场景不一样,pg数,副本数都会影响
2. 删除文件存储方法
如果需要删除文件存储,请按下面操作过程来操作
第1步: 在客户端上删除数据,并umount所有挂载
[root@client ~]# rm /mnt/* -rf
[root@client ~]# umount /mnt/
第2步: 停掉所有节点的mds(只有停掉mds才能删除文件存储)
[root@node1 ~]# systemctl stop ceph-mds.target
[root@node2 ~]# systemctl stop ceph-mds.target
[root@node3 ~]# systemctl stop ceph-mds.target
第3步: 回到集群任意一个节点上(node1,node2,node3其中之一)删除
如果要客户端删除,需要在node1上ceph-deploy admin client同步配置才可以
[root@node1 ceph]# ceph-deploy admin client
[root@client ceph]# ceph fs rm cephfs --yes-i-really-mean-it
[root@client ceph]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
pool 'cephfs_metadata' removed
[root@client ceph]# ceph osd pool delete cephfs_pool cephfs_pool --yes-i-really-really-mean-it
pool 'cephfs_pool' removed
第4步: 再次mds服务再次启动
[root@node1 ~]# systemctl start ceph-mds.target
[root@node2 ~]# systemctl start ceph-mds.target
[root@node3 ~]# systemctl start ceph-mds.target
四、创建Ceph块存储
1. 创建块存储并使用
第1步: 在node1上同步配置文件到client
[root@node1 ceph]# ceph-deploy --overwrite-conf admin client
第2步:建立存储池,并初始化
注意:在客户端操作
[root@client ~]# ceph osd pool create rbd_pool 128
pool 'rbd_pool' created
[root@client ~]# rbd pool init rbd_pool
第3步:创建一个存储卷(我这里卷名为volume1,大小为5000M)
注意: volume1的专业术语为image, 这里叫存储卷方便理解
[root@client ceph]# rbd create volume1 --pool rbd_pool --size 5000
[root@client ceph]# rbd ls rbd_pool
volume1
[root@client ceph]# rbd info volume1 -p rbd_pool
rbd image 'volume1': # 可以看到volume1为rbd image
size 4.9 GiB in 1250 objects
order 22 (4 MiB objects)
id: 5ead6b8b4567
block_name_prefix: rbd_data.5ead6b8b4567
format: 2 # 格式有1和2两种,现在是2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten # 特性
op_features:
flags:
create_timestamp: Sat Sep 17 12:06:19 2022
第4步: 将创建的卷映射成块设备
因为rbd镜像的一些特性,OS kernel并不支持,所以映射报错
[root@client ceph]# rbd map rbd_pool/volume1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbd_pool/volume1 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
解决方法: disable掉相关特性
rbd feature disable rbd_pool/volume1 exclusive-lock object-map fast-diff deep-flatten
再次映射
[root@client ceph]# rbd map rbd_pool/volume1
/dev/rbd0
第5步: 查看映射(如果要取消映射, 可以使用rbd unmap /dev/rbd0)
[root@client ceph]# rbd showmapped
id pool image snap device
0 rbd_pool volume1 - /dev/rbd0
第6步: 格式化,挂载
[root@client ceph]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=160768 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=1280000, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@client ceph]# mount /dev/rbd0 /mnt/
[root@client ceph]# df -h | tail -1
/dev/rbd0 4.9G 33M 4.9G 1% /mnt
注意: 块存储是不能实现同读同写的,请不要两个客户端同时挂载进行读写
2. 块存储扩容与裁减
在线扩容
经测试,分区后/dev/rbd0p1不能在线扩容,直接使用/dev/rbd0才可以
扩容成8000M
[root@client mnt]# rbd resize --size 8000 rbd_pool/volume1
Resizing image: 100% complete...done.
[root@client mnt]# rbd info rbd_pool/volume1 |grep size
size 7.8 GiB in 2000 objects
查看大小,并没有变化
[root@client mnt]# df -h | tail -1
/dev/rbd0 4.9G 33M 4.9G 1% /mnt
[root@client ~]# xfs_growfs -d /mnt/
再次查看大小,在线扩容成功
[root@client mnt]# df -h |tail -1
/dev/rbd0 7.9G 33M 7.8G 1% /mnt
块存储裁减
不能在线裁减.裁减后需重新格式化再挂载,所以请提前备份好数据.
再裁减回5000M
[root@client ~]# rbd resize --size 5000 rbd_pool/volume1 --allow-shrink
重新格式化挂载
[root@client ~]# umount /mnt/
[root@client ~]# mkfs.xfs -f /dev/rbd0
[root@client ~]# mount /dev/rbd0 /mnt/
再次查看,确认裁减成功
[root@client ~]# df -h | tail -1
/dev/rbd0 4.9G 33M 4.9G 1% /mnt
3. 删除块存储方法
[root@client ~]# umount /mnt/
[root@client ~]# rbd unmap /dev/rbd0
[root@client ~]# ceph osd pool delete rbd_pool rbd_pool --yes-i-really-really-mean-it
pool 'rbd_pool' removed
五、Ceph对象存储
1. 测试ceph对象网关的连接
第1步: 在node1上创建rgw
[root@node1 ceph]# ceph-deploy rgw create node1
[root@node1 ceph]# lsof -i:7480
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
radosgw 21294 ceph 40u IPv4 71808 0t0 TCP *:7480 (LISTEN)
通过浏览器访问,node1
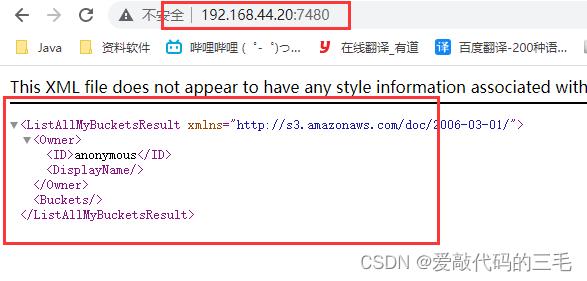
第2步: 在客户端测试连接对象网关
[root@client ~]# radosgw-admin user create --uid="testuser" --display-name="First User"
"user_id": "testuser",
"display_name": "First User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
"user": "testuser",
"access_key": "H52QG1579ZE544955Z3E",
"secret_key": "lhDZI0QfbOXaqeOUR5QDdDCR3khy9etXWh9JkNY3"
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota":
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
,
"user_quota":
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
,
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
上面一大段主要有用的为access_key与secret_key,用于连接对象存储网关
"access_key": "H52QG1579ZE544955Z3E",
"secret_key": "lhDZI0QfbOXaqeOUR5QDdDCR3khy9etXWh9JkNY3"
2. S3连接ceph对象网关
AmazonS3是一种面向Internet的对象存储服务.我们这里可以使用s3工具连接ceph的对象存储进行操作
第1步: 客户端安装s3cmd工具,并编写ceph连接配置文件
[root@client ~]# yum install s3cmd -y
创建并编写下面的文件,key文件对应前面创建测试用户的key
[root@client ~]# vim /root/.s3cfg
access_key = H52QG1579ZE544955Z3E
secret_key = lhDZI0QfbOXaqeOUR5QDdDCR3khy9etXWh9JkNY3
host_base = 192.168.44.20:7480
host_bucket = 192.168.44.20:7480/%(bucket)
cloudfront_host = 192.168.44.20:7480
use_https = False
第二步:命令测试
列出bucket,可以查看到先前测试创建的my-new-bucket
[root@client ~]# s3cmd ls
2019-01-05 23:01 s3://my-new-bucket
再建一个桶
[root@client ~]# s3cmd mb s3://test_bucket
上传文件到桶
[root@client ~]# s3cmd put /etc/fstab s3://test_bucket
upload: '/etc/fstab' -> 's3://test_bucket/fstab' [1 of 1]
465 of 465 100% in 1s 362.72 B/s done
下载到当前目录
[root@client ~]# s3cmd get s3://test_bucket/fstab
download: 's3://test_bucket/fstab' -> './fstab' [1 of 1]
465 of 465 100% in 0s 10.50 KB/s done
更多命令请见参考命令帮助
[root@client ~]# s3cmd --help
以上是关于搭建Ceph集群的主要内容,如果未能解决你的问题,请参考以下文章