[kaldi] alignment 对齐 (音素级和词级)
Posted 栋次大次
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[kaldi] alignment 对齐 (音素级和词级)相关的知识,希望对你有一定的参考价值。
kaldi天然支持aligment,MFA在kaldi基础上做了封装,提供alignment的接口,如果没有kaldi基础,建议优先考虑MFA 😀
音素级
基于GMM-HMM模型,很容易得到音素级的对齐。主要使用ali-to-phones
-
首先使用
step/align_si.sh得到对齐文件steps/align_si.sh --cmd "$train_cmd" --nj 10 \\ data/test data/lang exp/tri3a exp/tri3a_ali_test || exit 1;用法:
"steps/align_si.sh <data-dir> <lang-dir> <src-dir> <align-dir>" "e.g.: steps/align_si.sh data/train data/lang exp/tri1 exp/tri1_ali" "main options (for others, see top of script file)" " --config <config-file> # config containing options" " --nj <nj> # number of parallel jobs" " --use-graphs true # use graphs in src-dir" " --cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs." -
利用
ali-to-phones从上步得到的对齐文件中输出音素级的对齐ali-to-phones --per-frame $ali/final.mdl ark:"gunzip -c $ali/ali.*.gz|" ark,t:- \\ | utils/int2sym.pl -f 2- data/lang/phones.txt > $ali/ali_phones.txt # ali_phones.txt 最终的输出
词级对齐
需要理解lattice,核心思想是再lattice上做音频的预测对齐。
方法如下:
-
lattice-align-words-lexicon / lattice-align-words 结合 nbest-to-ctm
和ali.gz不同的是,lattice对齐到lexicon。如果在
prepare_lang.sh将position-dependent-phones设置为false,不能使用lattice-align-words命令。# 得到lat.*.gz对齐文件 steps/align_fmllr_lats.sh --cmd "$train_cmd" --nj 10 \\ data/test data/lang exp/tri3a exp/tri3a_ali_lats_test lattice-1best --lm-scale=10 --word-ins-penalty=0.0 \\ ark:"gunzip -c exp/tri3a_ali_lats_test/lat.*.gz|" ark,t:- |\\ lattice-align-words-lexicon data/lang/phones/align_lexicon.int \\ exp/tri3a_ali_lats_test/final.mdl ark:- ark:- |\\ lattice-1best ark:- ark:-|\\ nbest-to-ctm --frame-shift=0.01 --print-silence=true ark:- - |\\ utils/int2sym.pl -f 5 data/lang/words.txt > exp/tri3a_ali_lats_test/1.word.ctm -
lattice-align-words 结合 lattice-to-ctm-conf
若开启了音素位置开关,替换部分为:
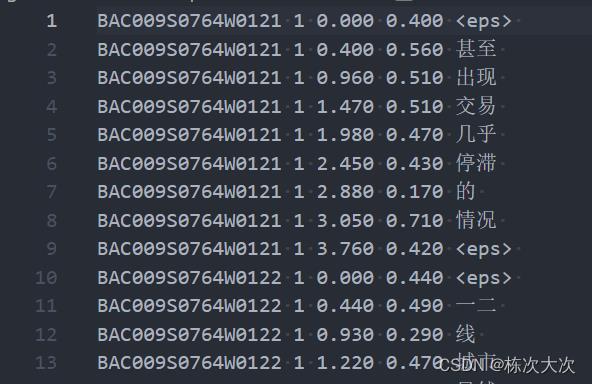
lattice-align-words data/lang/phones/word_boundary.intgunzip -c 20200921.lat.bin.gz |\\ lattice-align-words data/lang/phones/word_boundary.int \\ exp/chain/tdnn_1a_sp/final.mdl ark:- ark:-|\\ lattice-to-ctm-conf --acoustic-scale=1.0 --frame-shift=0.03 --print-silence=true ark:- -|\\ int2sym.pl -f 5 data/lang/words.txt > 1.word.ctm- 【1】输出的内容解释:
[音频id 通道(1或2) 开始时间位置秒 持续时间秒 词(word) 置信度] - 【2】nbest-to-ctm输出的是没有置信度的,多条路径的才有
- 【3】由于是使用了chain模型,
frame-shift应该设置为0.03(这个是由steps/nnet3/chain/build_tree.sh --frame-subsampling-factor 3决定的,其值是表示输入帧进行t个移位并将输出的帧进行偏移),GMM的话是0.01,可参考Word timings of nnet3 decoding - 【4】
lattice-to-ctm-conf后面的是ark:- -,后面的-如果不int2sym.pl可直接为1.word.ctm,这时候第5列的词就只能看到id
- 【1】输出的内容解释:
word.ctm文件:
以上是关于[kaldi] alignment 对齐 (音素级和词级)的主要内容,如果未能解决你的问题,请参考以下文章