数据挖掘百度机器学习-数据挖掘-自然语言处理工程师 历史笔试详解
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘百度机器学习-数据挖掘-自然语言处理工程师 历史笔试详解相关的知识,希望对你有一定的参考价值。
百度:机器学习/数据挖掘工程师/自然语言处理 历史笔试题
为了准备2023届毕业生的秋招汇总的网上分享的题目,自己进行的解析整理
1、用于多分类任务的激活函数
Softmax
2、TCP首部的确认号字段
ACK
3、GMM-HMM模型
相关的算法,EM算法和维特比算法
4、朴素贝叶斯模型
优点:
(1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
(2)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
(3)分类准确度高,速度快。
(4)对小规模的数据表现很好,能处理多分类任务,适合增量式训练,当数据量超出内存时,我们可以一批批的去增量训练(朴素贝叶斯在训练过程中只需要计算各个类的概率和各个属性的类条件概率,这些概率值可以快速地根据增量数据进行更新,无需重新全量计算)。
缺点:
(1)对训练数据的依赖性很强,如果训练数据误差较大,那么预测出来的效果就会不佳。
(2)实际中,当属性个数比较多或者属性之间相关性较大时,分类效果不好。
(3)需要知道先验概率,且先验概率很多时候是基于假设或者已有的训练数据所得的,这在某些时候可能会因为假设先验概率的原因出现分类决策上的错误。
5、SGD随机梯度下降法
随机梯度下降算法通常还有三种不同的应用方式,它们分别是SGD、Batch-SGD、Mini-Batch SGD
1.SGD是最基本的随机梯度下降,它是指每次参数更新只使用一个样本,这样可能导致更新较慢;
2.Batch-SGD是批随机梯度下降,它是指每次参数更新使用所有样本,即把所有样本都代入计算一遍,然后取它们的参数更新均值,来对参数进行一次性更新,这种更新方式较为粗糙;
3.Mini-Batch-SGD是小批量随机梯度下降,它是指每次参数更新使用一小批样本,这批样本的数量通常可以采取trial-and-error的方法来确定,这种方法被证明可以有效加快训练速度优点:
(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据 上的损失函数,这样每一轮参数的更新速度大大加快。缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
6、随机森林算法
随机森林 = Bagging+决策树
同时训练多个决策树,预测试综合考虑多个结果进行预测,例如取多个节点的均值(回归问题),或者众数(分类)。
优点:
(1)它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
(2)它可以判断特征的重要程度
(3)可以判断出不同特征之间的相互影响
(4)消除了决策树容易过拟合的缺点
(5)减小了预测的方差,预测值不会因训练数据的小变化而剧烈变化
(6)训练速度比较快,容易做成并行方法
(7)实现起来比较简单
(8)对于不平衡的数据集来说,它可以平衡误差。
(9)如果有很大一部分的特征遗失,仍可以维持准确度。
缺点:(1)随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
(2)对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
(3)随机性体现在两点从原来是训练数据集随机(带放回Boostrap)取一个子集,作为森林中某一个决策树的训练数据集
每一次选择分叉的特征时,限定为在随机选择的特征的子集中寻找一个特征
7、强连通图
n个顶点,最多有n*(n-1)条边;最少有n条边
8、红黑树的高度
对于一棵具有 n 个结点的红黑树,树的高度至多为:2lg (n+1)。
9、完全二叉树的高度
高度为h的满二叉树,有 ( 2 h ) − 1 (2^h)-1 (2h)−1个结点
具有n个结点的完全二叉树的高度为log(n+1)向上取整,或者(logn)向下取整+1
第k层至多有 2 ( k − 1 ) 2^(k-1) 2(k−1)个结点
10、最长公共前后缀
11、冒泡排序的比较次数
冒泡排序涉及相邻两两数据的比较,故需要嵌套两层 for 循环来控制; 外层循环 n 次,内层最多时循环 n – 1次、最少循环 0 次,平均循环 (n-1)/2; 所以循环体内总的比较交换次数为:n× (n-1) / 2
12、C4.5使用的属性划分标准:信息增益率
不同决策树的节点分裂准则:
原始决策树节点分裂准则:节点内特征数量阈值,小于阈值,停止分裂
基于ID3算法的决策树节点分裂准则:信息增益,越大越好
基于C4.5算法的决策树节点分裂标准:信息增益比(信息增益率),越大越好
基于CART算法的决策树节点分裂标准:回归树,采用平方根误差最小化准则,分类树,采用基尼指数。越小越好
13、下列关于语言模型的说法错误的是() B
A 基于知识的语言模型通过非歧义的规则解释歧义过程
B 基于知识的语言模型是经验主义方法
C 基于语料库的统计分析模型需要从大规模的真实文本中发现知识
D 基于语料库的统计模型更加注重用数学的方法
解析:
基于知识的语言模型是理性主义方法。
经验主义方法:主张通过建立特定的数学模型来学习复杂的、广泛的语言结构,然后利用统计学、模式识别和机器学习等方法来训练模型的参数,以扩大语言使用的规模。因此,经验主义的自然语言处理方法是建立在统计方法基础之上的。
基于规则的理性主义方法:主张建立符号处理系统,由人工整理和编写初始的语言知识表示体系(通常为规则),构造相应的推理程序,系统根据规则和程序,将自然语言理解为符号结构——该结构的意义可以从结构中的符号的意义推导出来。基于规则的理性主义方法通常都是明白易懂的,表达得很清晰,描述的很明确,很多语言事实都可以使用语言模型得结构和组成部分直接的、明显的表示出来。基于规则的理性主义方法在本质上是没有方向性的,使用这种方法研制出来的语言模型,既可以用于分析,也可以用于生成。也就是说,同一个语言模型可以双向使用。
14、下列关于现有的分词算法说法错误的是() A
A 基于统计的分词方法是总控部分的协调下,分词子系统获得有关词、句子等的句法和语义信息来对分词歧义进行判断
B 由于在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词,统计语料中的频度可以判断是否构成一个词
C 统计分词系统将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点
D 中文分词的准确度,对搜索引擎结果相关性和准确性有相当大的关系
解析:
基于字符串的匹配方法是总控部分的协调下,分词子系统获得有关词、句子等的句法和语义信息来对分词歧义进行判断。并不是统计的分词方法。
15、有一家医院为了研究癌症的诊断,对一大批人作了一次普查,给每人打了试验针,然后进行统计,得到如下统计数字:
① 这批人中,每1000人有5个癌症病人;
② 这批人中,每100个正常人有1人对试验的反应为阳性,
③ 这批人中,每100个癌症病人有95人对试验的反应为阳性。
通过普查统计,该医院可开展癌症诊断。
现在某人试验结果为阳性,根据最小风险贝叶斯决策理论,将此患者预测为患癌症的风险概率为( )。C
假设将正常人预测为正常人和将癌症患者预测为癌症患者的损失函数均为0,将癌症患者预测为正常人的损失函数为3,将正常人预测为癌症患者的损失函数为1.
A 75.5%
B 32.3%
C 67.7%
D 96.9%
16、如当前样本集合D中第K类样本所占的比列为P(k)(k= 1,2,3,…,y),则样本的信息熵最大值为( ) C
A 1
B 0.5
C Log2(y)
D log2(P(y))
解析:
题目有问题,应该不完整。应该是问答案中最大值的是,P(y)<=1,y>3,则答案C是最大的。
信息熵时用来衡量信息不确定性的指标,不确定性时一个时间出现不同结果的可能性。
H ( x ) = − ∑ k = 1 n P ( k ) l o g 2 P ( k ) H(x) = -\\sum_k=1^n P(k)log_2P(k) H(x)=−k=1∑nP(k)log2P(k)
17、下列关于数据降维方法说法正确的是(ABCD)
A. MDS要求原始空间样本之间的距离在降维后的低维空间中得以保持
B. PCA采用一组新的基来表示样本点,每个基向量都是原来基向量的线性组合,通过使用尽可能少的新基向量来表出样本,从而实现降维
C. 核化主成分分析为先将样本映射到高维空间,再在高维空间中使用线性降维
D. 流形学习是一种借助拓扑流形概念的降维方法,采用的思想是"邻域保持"
18、下列属于常用的分箱方法的是(ABC)
A 统一权重法
B 统一区间法
C 自定义区间法
D 平均值法
解析:
等深分箱法(统一权重法)、等宽分箱法(统一区间法)、最小熵法和用户自定义区间法。
(1)统一权重,也成等深分箱法,将数据集按记录行数分箱,每箱具有相同的记录数,每箱记录数称为箱子的深度。这是最简单的一种分箱方法。
(2)统一区间,也称等宽分箱法,使数据集在整个属性值的区间上平均分布,即每个箱的区间范围是一个常量,称为箱子宽度。
(3)用户自定义区间,用户可以根据需要自定义区间,当用户明确希望观察某些区间范围内的数据分布时,使用这种方法可以方便地帮助用户达到目的。
20、某数据存放在DS=2000H和DI=1234H的数据段的存储单元中,则该存储单元的物理地址为(A )
A 21234H
B 14340H
C 3234H
D 其他几项都不对
解析:
21、在分时系统中,时间片设置Q=3,以下关于响应时间的分析,正确的是(AD )
A 用户数量越多响应时间越长
B 内存空间越大响应时间越长
C 时间片越小响应时间越长
D 进程数量越多响应时间越长
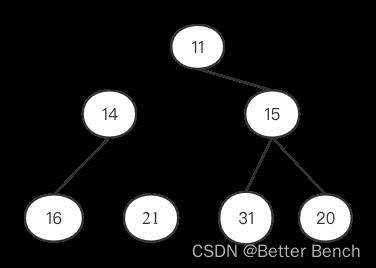
22、序列[9,14,11,16,21,15,20,31]为小顶堆,在删除堆顶元素9之后,调整后的结果是( C)
A [14,11,16,21,15,20,31]
B [11,14,16,21,15,20,31]
C [11,14,15,16,21,31,20]
D [11,14,15,16,20,21,31]
对于删除操作,将二叉树的最后一个节点替换到根节点,然后自顶向下,递归调整。
原始小顶堆为

删除11后,调整右子树,得到的结果为
以上是关于数据挖掘百度机器学习-数据挖掘-自然语言处理工程师 历史笔试详解的主要内容,如果未能解决你的问题,请参考以下文章