借助余弦相似度辅助背单词
Posted 泰 戈 尔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了借助余弦相似度辅助背单词相关的知识,希望对你有一定的参考价值。
文章目录
0 背景
无他,唯背单词而已。
1 余弦相似度
提到余弦相似度,不得不先说下欧几里得距离,这两个容易搞混淆。
1.1 欧几里得距离

距离度量衡量的是空间各点间的绝对距离,跟各个点所在的位置坐标(即个体特征维度的数值)直接相关;而余弦相似度衡量的是空间向量的夹角,更加的是体现在方向上的差异,而不是位置。如果保持A点的位置不变,B点朝原方向远离坐标轴原点,那么这个时候余弦相似度cosθ是保持不变的,因为夹角不变,而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。
参考自 余弦相似度与欧几里得距离1
1.2 余弦相似度计算公式
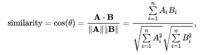
1.3 图例理解


1.4 简单示意
# coding: utf8
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import math
"""
arr1 = [[1, 2]]
arr2 = [[4, 5]]
"""
arr1 = np.arange(2).reshape(1, 2)
arr1[0] = [100 * 1 / math.sqrt(5), 100 * 2 / math.sqrt(5)]
arr2 = np.arange(2).reshape(1, 2)
arr2[0] = [100 * 4 / math.sqrt(41), 100 * 5 / math.sqrt(41)]
print(arr1)
print(arr2)
ret = cosine_similarity(arr1, arr2)
print(ret)
"""
[[44 89]]
[[62 78]]
[[0.97751451]]
"""
在 sklearn 中,有如下代码
def cosine_similarity(X, Y=None, dense_output=True):
"""Compute cosine similarity between samples in X and Y.
Cosine similarity, or the cosine kernel, computes similarity as the
normalized dot product of X and Y:
K(X, Y) = <X, Y> / (||X||*||Y||)
On L2-normalized data, this function is equivalent to linear_kernel.
Read more in the :ref:`User Guide <cosine_similarity>`.
Parameters
----------
X : ndarray, sparse matrix of shape (n_samples_X, n_features)
Input data.
Y : ndarray, sparse matrix of shape (n_samples_Y, n_features), \\
default=None
Input data. If ``None``, the output will be the pairwise
similarities between all samples in ``X``.
dense_output : bool, default=True
Whether to return dense output even when the input is sparse. If
``False``, the output is sparse if both input arrays are sparse.
.. versionadded:: 0.17
parameter ``dense_output`` for dense output.
Returns
-------
kernel matrix : ndarray of shape (n_samples_X, n_samples_Y)
"""
# to avoid recursive import
X, Y = check_pairwise_arrays(X, Y)
X_normalized = normalize(X, copy=True)
if X is Y:
Y_normalized = X_normalized
else:
Y_normalized = normalize(Y, copy=True)
K = safe_sparse_dot(X_normalized, Y_normalized.T,
dense_output=dense_output)
return K
2 word2vec
关于 word2vec 的定义就不过多描述了,我对于 word2vec 的认知也不是很深,但是给我的第一印象就是,它能用来背单词。
2.1 经典示意图

The resulting vector from “king-man+woman” doesn’t exactly equal “queen”, but “queen” is the closest word to it from the 400,000 word embeddings we have in this collection.
2.2 方案选择
不管是中文和英文,都是有一定的语义相关性的。可能我提到张三,你就能想到李四。提到狮子就能想到老虎一样。而 word2vec 恰恰是能将此特性通过词向量的形式进行具象化的一种技术手段。因此,在语义相关的众多候选单词中,通过 word2vec 的牵引,往往能起到“举一反三”的功效,不仅背单词的效率更高了,速度也会有提升。
2.3 了解更多
想了解更多关于 word2vec 的内容,可以点击下面两篇文章,个人感觉降得很好。
神级解读3
word2Vec 是如何得到词向量的4
3 vocabulary
写了这么多,都是铺垫,下面进入正题,怎么样把它应用到“背单词”这个应用上,才是本次需求的目的。
3.1 收集物料
物料的选取,从根本上决定了后期模型的准确度。

我这里选取的不是很好,需求的目的是背单词,但是哈利波特更多的是稍偏情景化的内容,因此不太适合用来做目标物料。
相对来讲,较为合适的就是维基百科、英语 46 级、雅思等内容相关的文本。这样的内容天生就是适合的。收集物料的过程很繁琐,需要针对性的写一些爬虫脚本,我这里目前还不需要做到如此精准,就先用哈利波特英文剧本代替了。
3.2 清洗数据
清洗数据是为了下一步训练模型使用,收集到的物料全部粘连在一起了。而训练模型时用的是行分隔模式,因此需要先将文本转换为行式结构。
sentences = word2vec.LineSentence("haripoter.txt")
3.3 训练模型
这里借助 gensim 库进行模型的训练与构建,方便快捷。
from gensim.models import word2vec
sentences = word2vec.LineSentence("haripoter.txt")
model = word2vec.Word2Vec(
sentences,
sg=0,
# size=100,
# window=2,
# negative=3,
# sample=0,
# hs=1,
# workers=4,
size=250,
)
model.save("haripoter.model")
3.4 模型应用
from gensim.models import word2vec
model = word2vec.Word2Vec.load("haripoter.model")
print(model.most_similar("kitchen", topn=3))
"""
[('hall', 0.9646997451782227), ('corridor,', 0.9580787420272827), ('hole', 0.9575302600860596)]
"""
将此模型应用到单词抽取阶段,来代替现有的随机抽取算法,定能起到画龙点睛的功效。

半成品背单词应用 https://github.com/guoruibiao/vocabulary
3.5 后期规划
1 爬取更多物料,构筑更精准的模型
2 针对错误单词的“组词成句”需求跟进,在我看来,这也是一个 NLP 的热点。
4 总结
本文主要从一个数学公式(余弦相似度)说起,再到 word2vec 算法,再应用到具体的工具中(物料不全,暂未使用)。整体思路还是蛮清晰的,后续其实可以投入精力去好好优化下,时间有限,就写到这里了。
参考链接:
以上是关于借助余弦相似度辅助背单词的主要内容,如果未能解决你的问题,请参考以下文章